
前回は、Azure Data Factoryを使用した簡単なデータコピー処理の実装方法を紹介しました。本記事では、前回作成したパイプラインをパラメーター化し、環境に応じて使い分け出来るようにしていきます。
前回の記事:Data Factoryを使用してAzure Blob StorageからAzure SQL Databaseにデータをコピーする - JBS Tech Blog
実施概要
前回実装したパイプラインでもデータのコピーは出来ますが、1つの環境(ディレクトリやテーブル名)に依存した構成となっています。
そのため、同じパイプライン構成で別のディレクトリからのコピーや別のテーブルへのコピーを実装したい場合に使いまわすことが難しく時間もかかることになります。
そこで、データパイプラインをパラメーター化します。これによって、パイプラインパラメーターの規定値を変更するだけで、簡単にパイプラインを横展開していくことが可能となります。
このように、パラメーターはデータセットの接続詳細や処理するファイルのパスを渡し、パイプラインとそのアクティビティの動作を制御することが出来ます。
コピー処理の構成については前回と同じものを使用します。
※詳細なコピー方法については前回の記事をご参照ください。

事前準備
- データソース(Blob)
- CSVファイルを置くためのディレクトリを作成
例:container02/test/test.CSV(コンテナ/ディレクトリ/CSVファイル)
- CSVファイルを置くためのディレクトリを作成
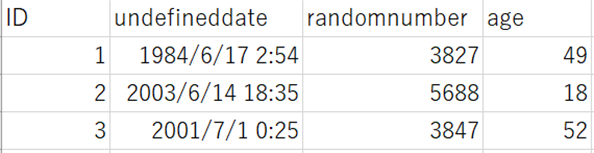
↑今回使用したCSVファイルの中身(前回と同様)
実施手順
データセットパラメーターの作成
Blob
1-1.Data Factoryの左側ウィンドウのDatasetsからBlobDatasetを開き、パラメーター欄で「新規」をクリックします。
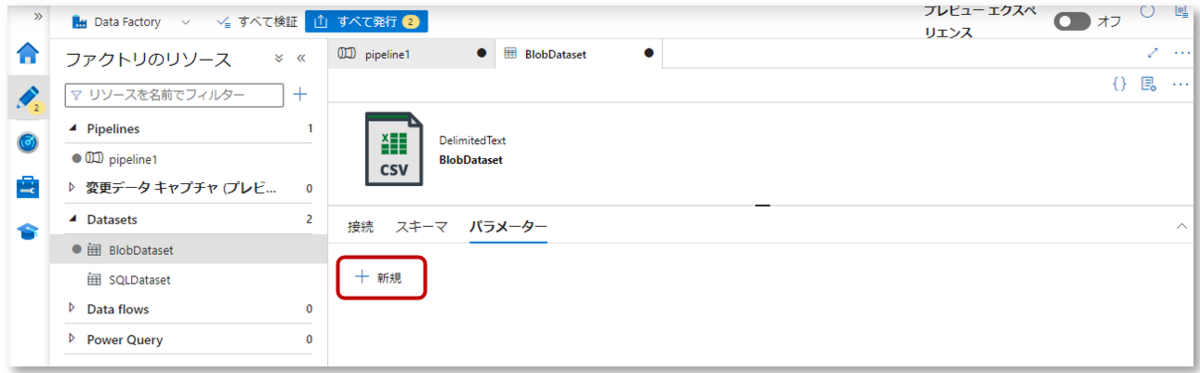
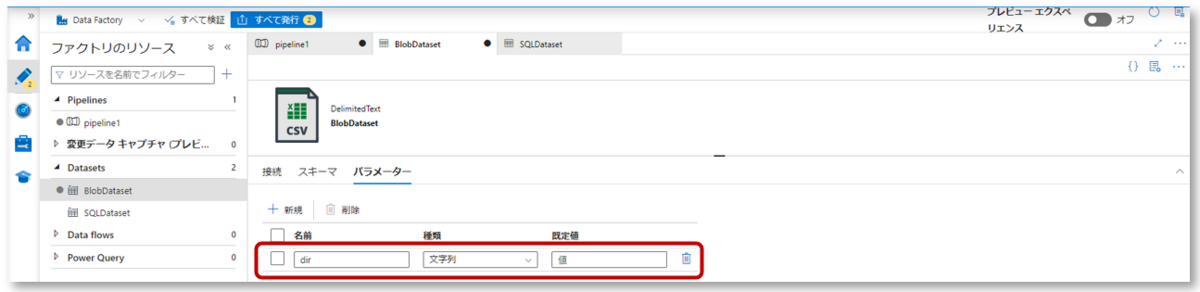
1-2.「dir」パラメーターを作成します。
「dir」は、データセットプロパティとしてAzure Blob Storage内のコンテナ内のディレクトリを定義するためのものです。
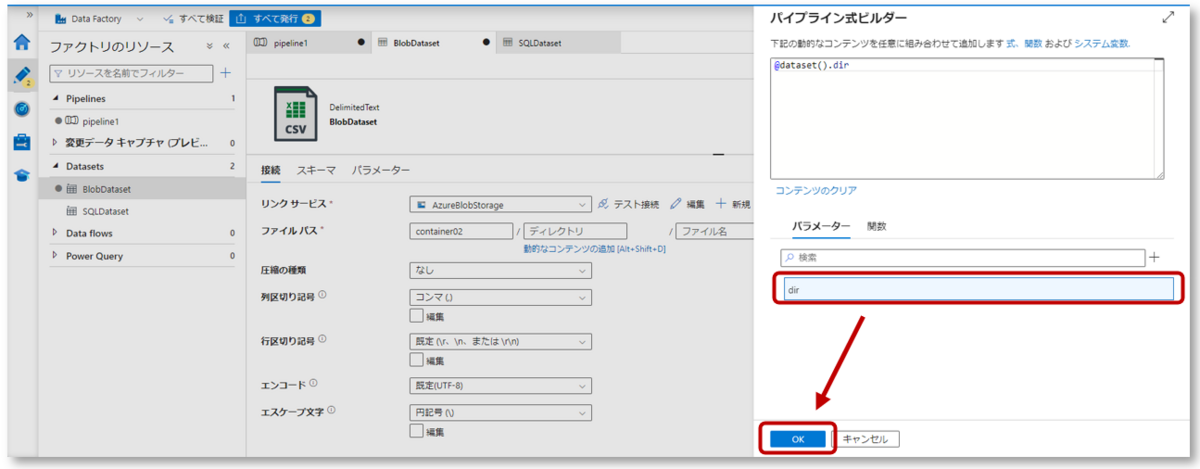
1-3.接続タブのファイルパスで、ディレクトリ下の「動的なコンテンツの追加」をクリックし、パイプライン式ビルダーを開きます。
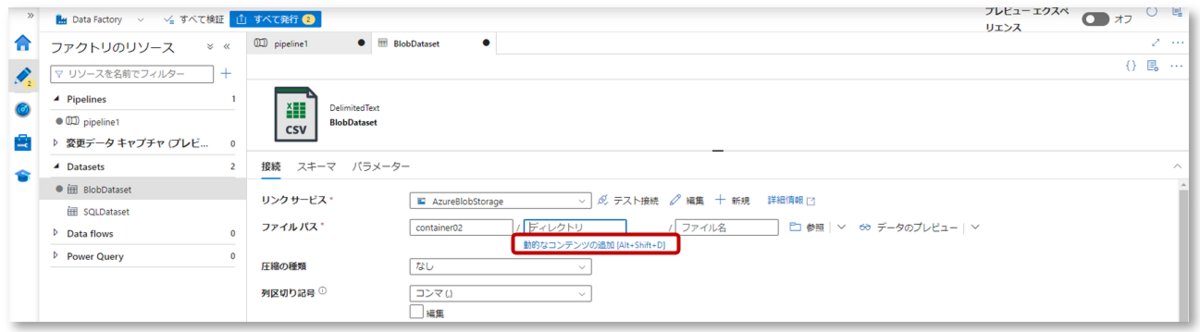
パイプライン式ビルダーのパラメータータブにある先程作成したパラメーター「dir」をクリックし、「OK」をクリックします。
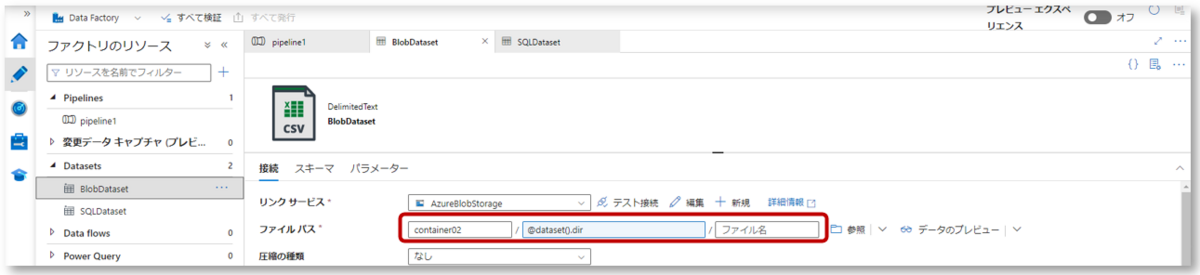
ファイルパスのディレクトリに、パラメーター「dir」が定義されたことを確認します。
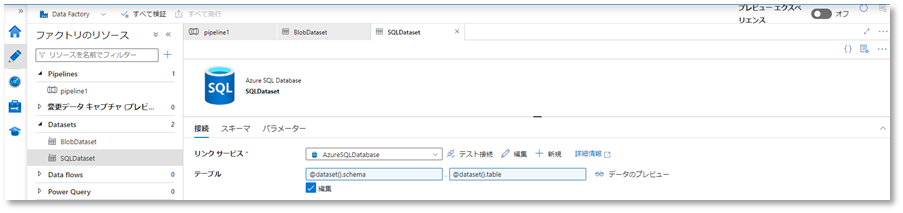
SQL
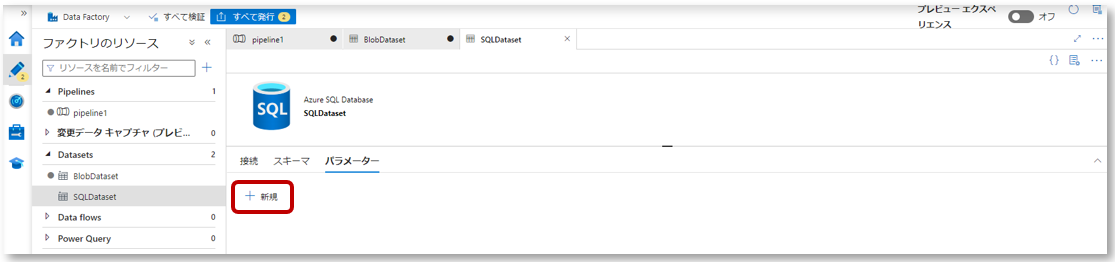
1-1.Data Factoryの左側ウィンドウのDatasetsからSQLDatasetを開き、パラメーター欄で「新規」をクリックします。
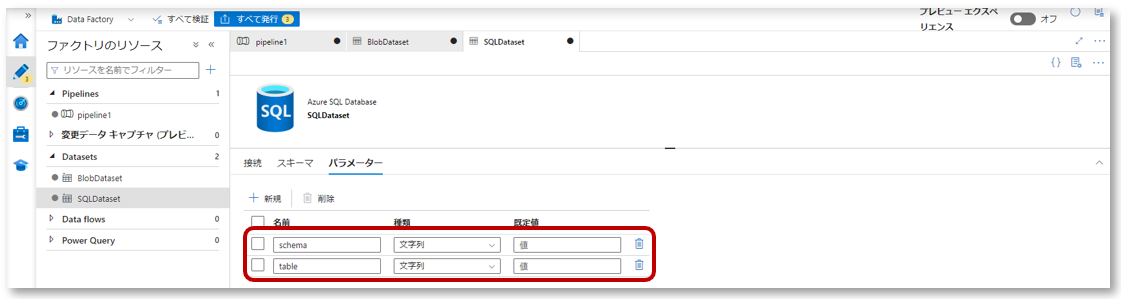
1-2.パラメーター「schema」と「table」を作成します。
1-3.接続タブのテーブルで、スキーマ下「動的なコンテンツの追加」をクリックし、パイプライン式ビルダーを開きます。
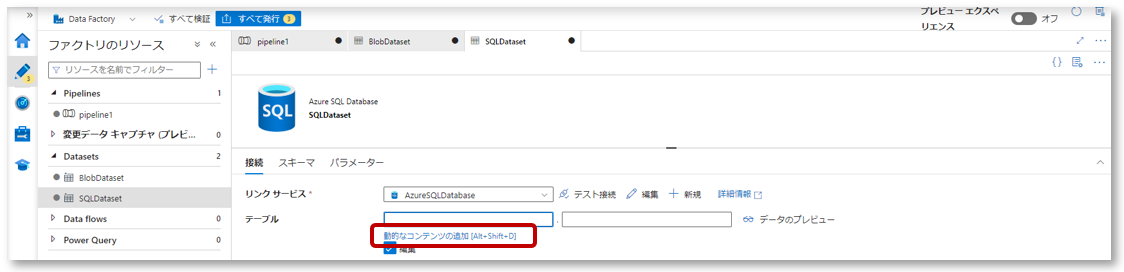
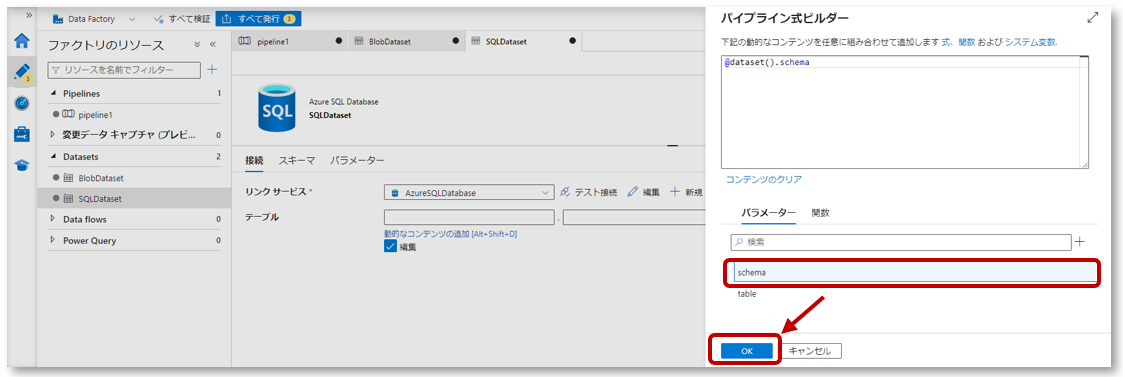
パイプライン式ビルダーのパラメータータブにある先程作成したパラメーター「schema」をクリックし、「OK」をクリックします。
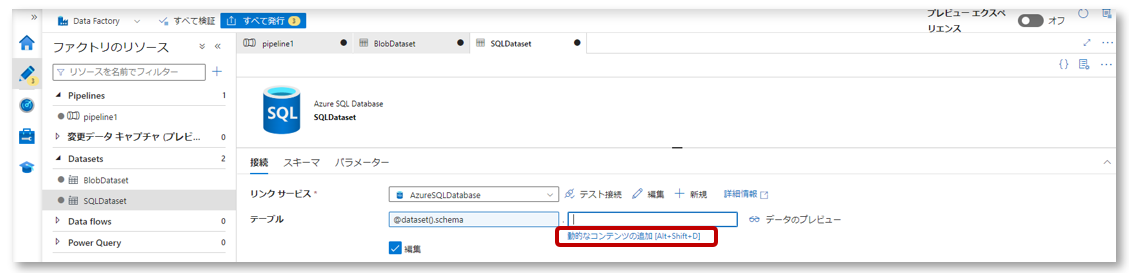
接続タブのテーブルで、テーブル下「動的なコンテンツの追加」をクリックし、パイプライン式ビルダーを開きます。
パイプライン式ビルダーのパラメータータブにある先程作成したパラメーター「table」をクリックし、「OK」をクリックします。
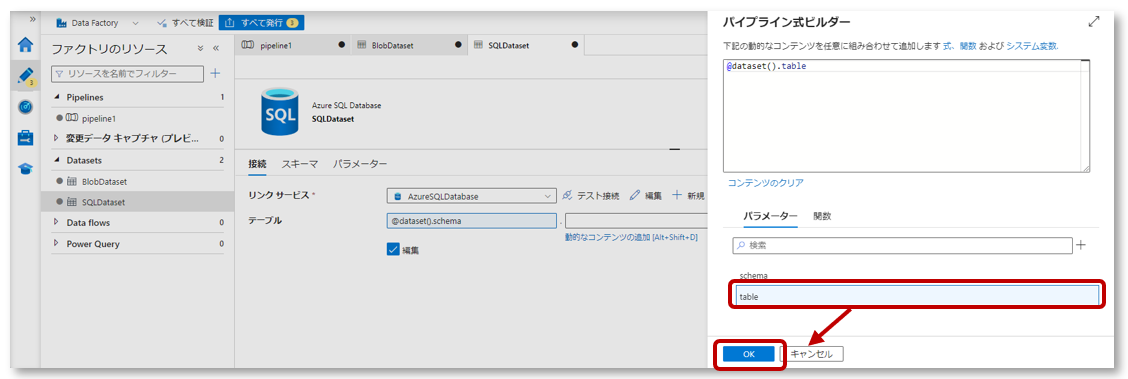
テーブルに、パラメーター「schema」、「table」が定義されたことを確認します。
パイプラインパラメーターの作成
Blob
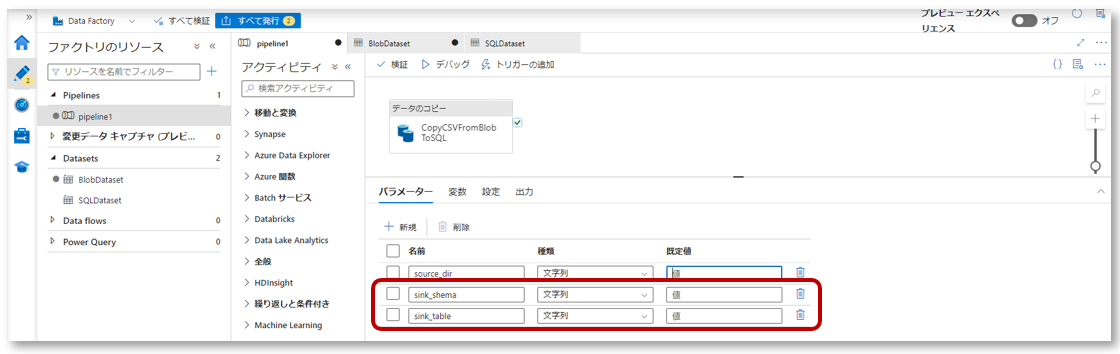
2-1.パイプライン編集画面を開き、パラメータータブから「新規」をクリックします。
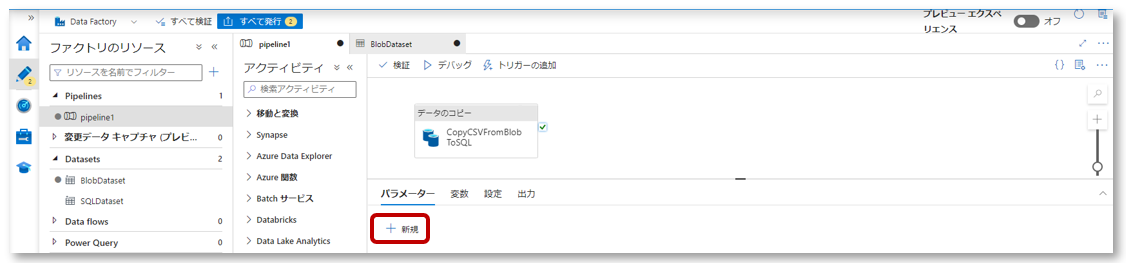
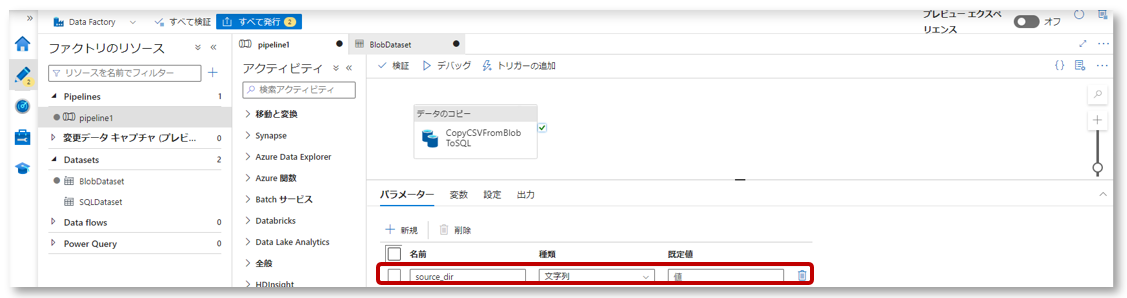
2-2.パラメーター「source_dir」を作成します。
SQL
2-1.パイプライン編集画面を開き、パラメータータブから「新規」をクリックします。
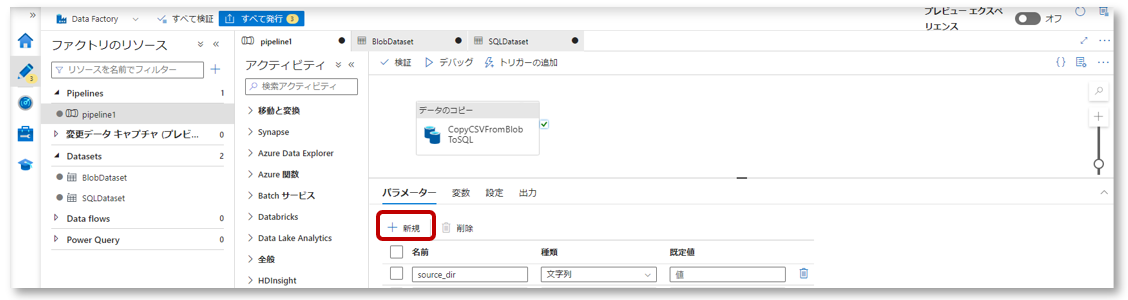
2-2.パラメーター「sink_schema」と「sink_table」を作成します。
アクティビティでパラメーターを指定
Blob
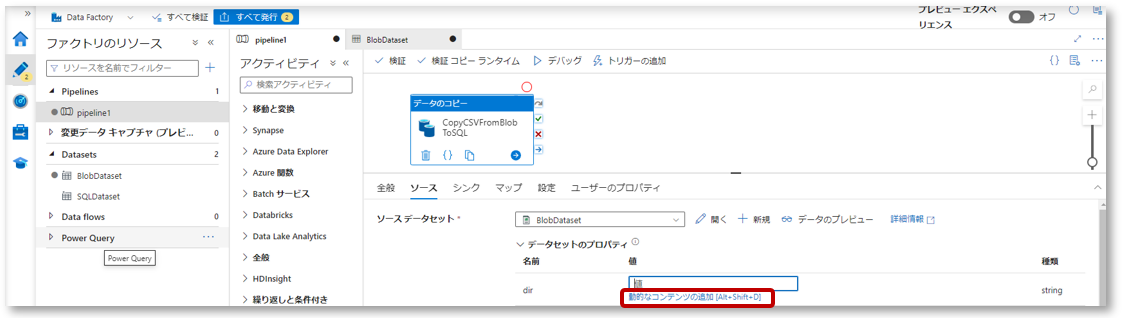
3-1.データコピーアクティビティ(CopyCSVFromBlobToSQL)をクリックし、ソースタブを開きます。
データセットのプロパティで、作成したデータセットパラメーター「dir」に「動的なコンテンツの追加」からパイプラインパラメーターを指定します。
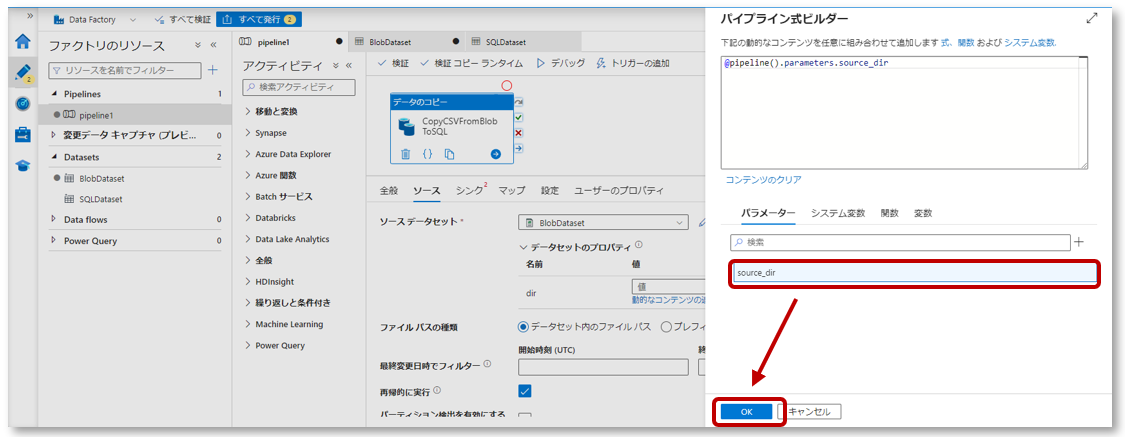
パイプライン式ビルダーのパラメータータブで「source_dir」をクリックし、「OK」をクリックします。
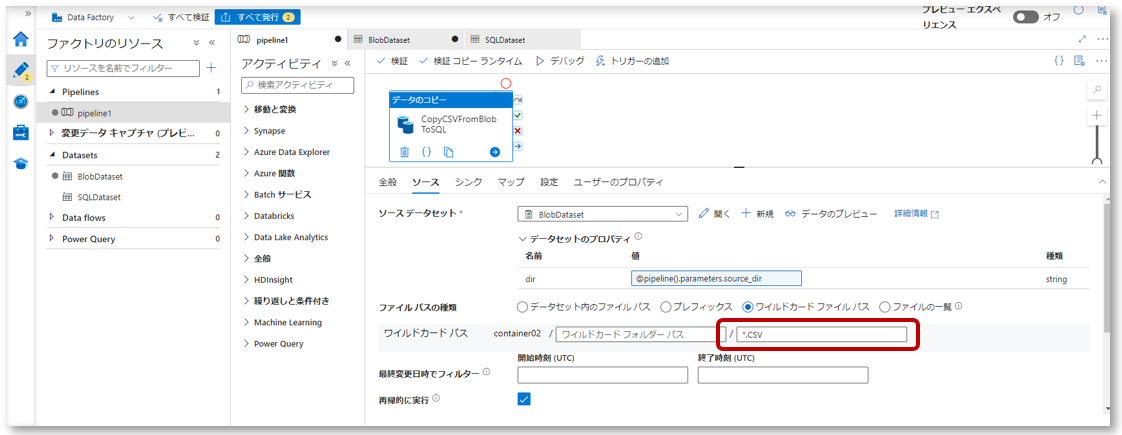
3-2.ワイルドカードパスを選択し、ワイルドカードファイルパスに「*.CSV」を入れます。
ここでは指定したディレクトリ内の、末尾に「.CSV」が付くファイルを指定しています。
SQL
3-1.データコピーアクティビティをクリックし、シンクタブを開きます。
データセットのプロパティで、作成したデータセットパラメーター「schema」に「動的なコンテンツの追加」から値を設定します。
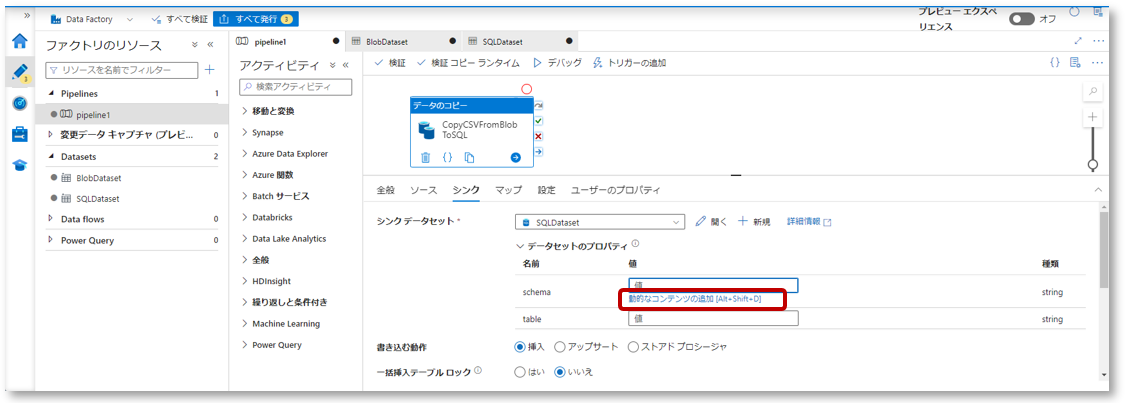
パイプライン式ビルダーのパラメータータブで「sink_schema」をクリックし、「OK」をクリックします。
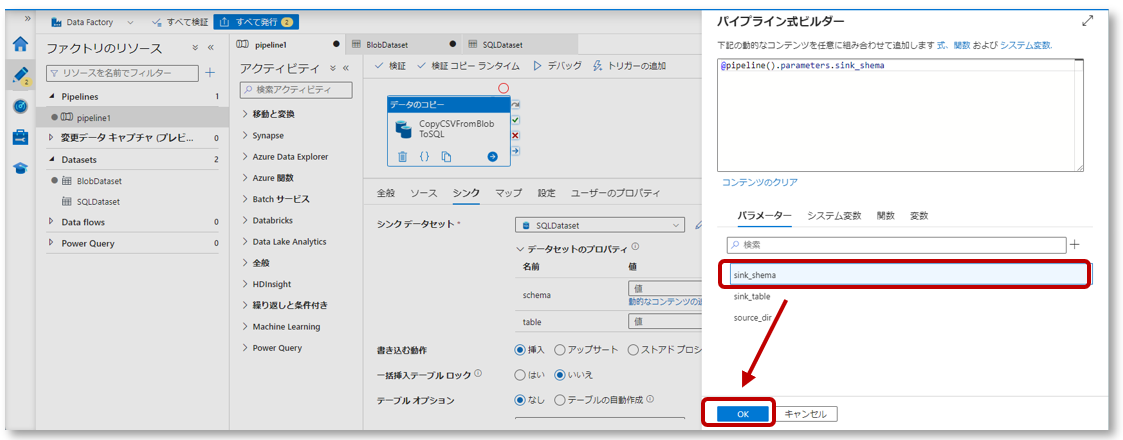
3-2. データセットのプロパティで、作成したデータセットパラメーター「table」に「動的なコンテンツの追加」から値を設定します。
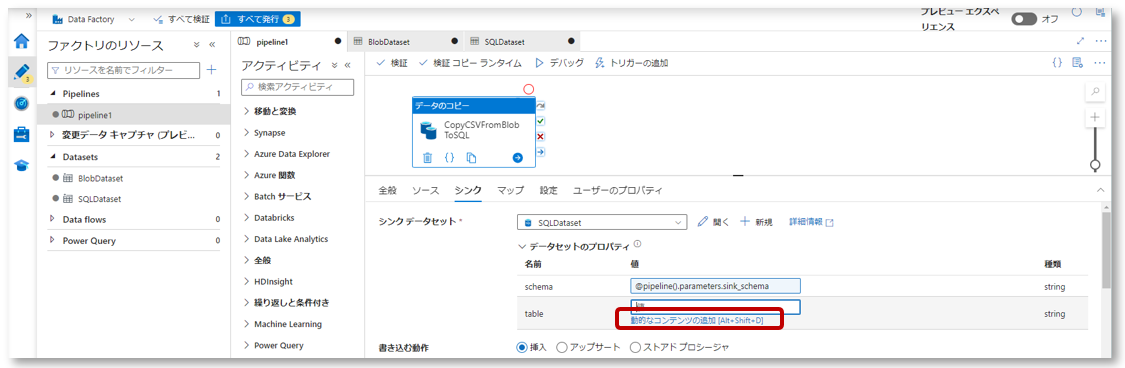
パイプライン式ビルダーのパラメータータブで「sink_table」をクリックし、「OK」をクリックします。
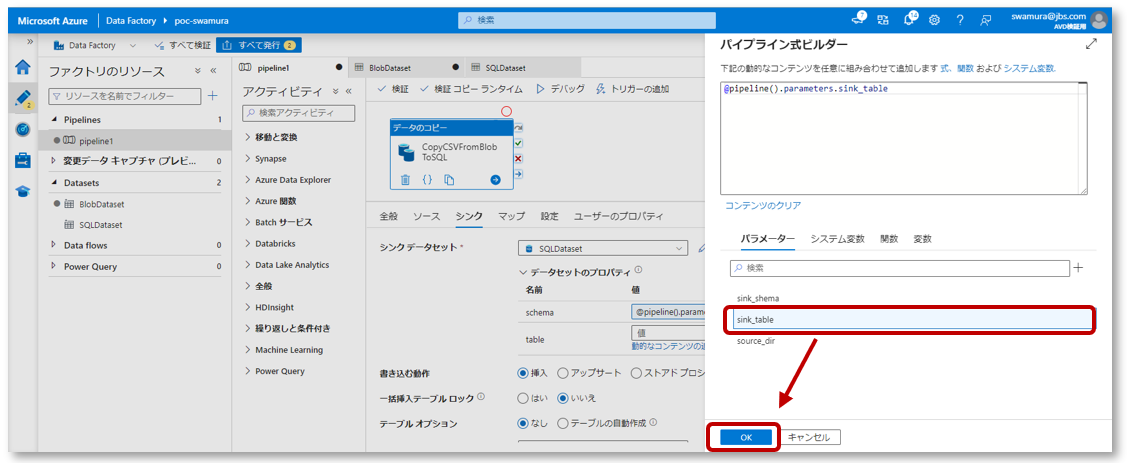
パイプラインパラメーターに値を入れる
- 今回使用するAzure Blob Storageのディレクトリを指定します
- SQLのスキーマとテーブル名を指定します
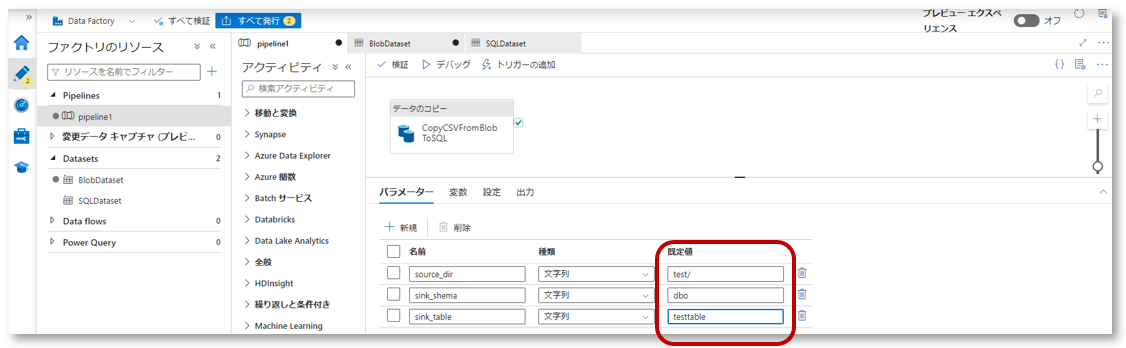
検証と発行
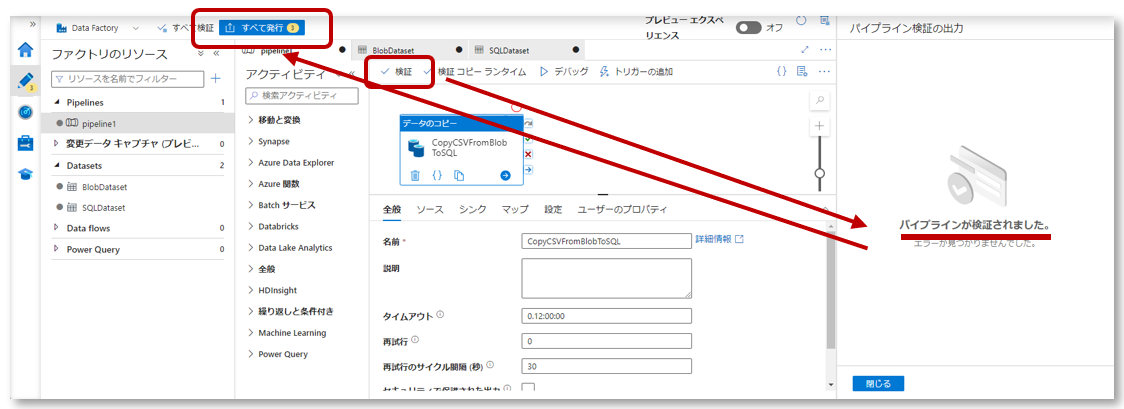
「検証」をクリックし、パイプラインを検証し、エラーが出なければ「すべて発行」をクリックしパイプラインを保存します。
パイプラインの実行と確認
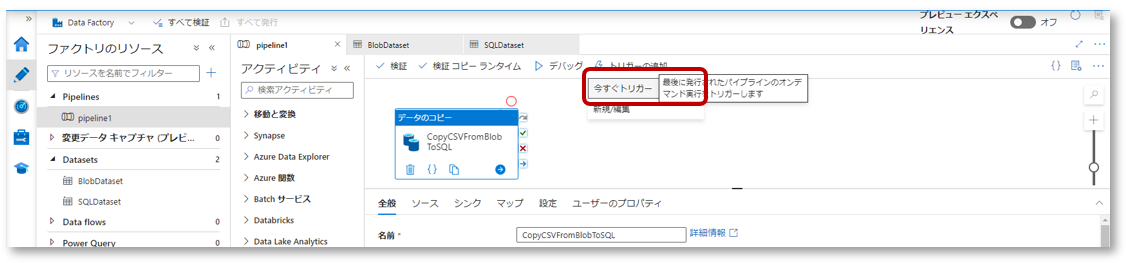
6-1. “トリガーの追加”→「今すぐトリガー」をクリックし、パイプラインを実行します。
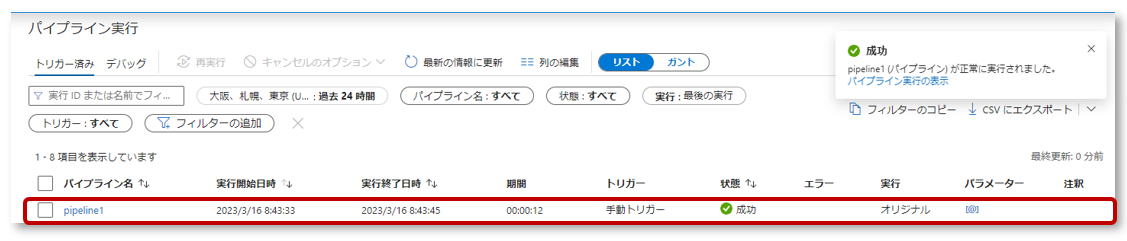
6-2. Data Factoryの左側ウィンドウ「Monitor」タブの”Pipeline runs”をクリックし、パイプラインの実行が成功したことを確認します。
6-3.Azure SQL Databaseを開き、テーブルにCSVファイルのデータがコピーされていることを確認します。

おわりに
パラメーター化されたデータパイプラインを作成し、環境によってパラメーターを使い分けることでより柔軟で効率的なデータ連携が可能になります。Azure Data Factoryではこのパラメーターを定義して様々な関数や詳細を指定することが出来ます。
