
はじめに
業務でAzure Data Factoryに触れる機会があったので、学んだ内容を整理するために簡単なデータコピー処理の実装方法をまとめてみました。
実施概要
本記事では、Azure Data Factoryを使用してAzure Blob StorageからAzure SQL DatabaseへCSVファイルをコピーする処理の実装をします。

Azure Data Factoryとは、Azureが提供するデータ統合のためのプラットフォームです。ETL(抽出・変換・格納)やELTの機能を視覚的な操作で実現可能であり、クラウドのデータ統合だけでなくオンプレミスとクラウドを併用するハイブリッド環境や、Azure外部のデータソースともデータ統合が可能です。
Data Factoryには下記の4つの基本概念があり、これらを作成することでデータコピー処理を実装出来ます。
・リンクサービス:データソース(Blob、SQL)への接続を定義します。
・データセット:リンクサービスが参照するデータストアに格納されている入力/出力データを表します。フォルダ名やテーブル名といったデータ構造を示し、利用する実データを指定します。
・アクティビティ:データに対して実行するアクションを定義します。データのコピー・変換などのさまざまなアクティビティがあります。
・パイプライン:複数のアクティビティを論理的にまとめて管理するグループです。1つの処理を行うアクティビティを複数用意し、それらをパイプラインにまとめて管理します。
事前準備
- Data Factory
- Data Factoryを作成
- データソース(Blob)
- CSVファイルを格納するためのストレージアカウントを作成
- ストレージアカウント内にコンテナを作成
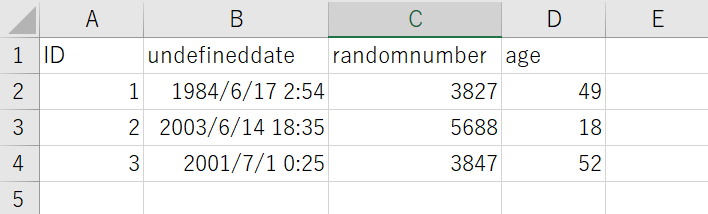
- コンテナ内にCSVファイルを作成(実際に使用したCSVファイルの中身↓)
- データソース(SQL)
- SQL Serverを作成
- SQL Databaseを作成
- 作成したデータベース内にテーブルを作成
- CSVファイルの中身とスキーマ(列名、列数など)が同じもの
実施手順
1.リンクサービスの作成
Blobリンクサービス
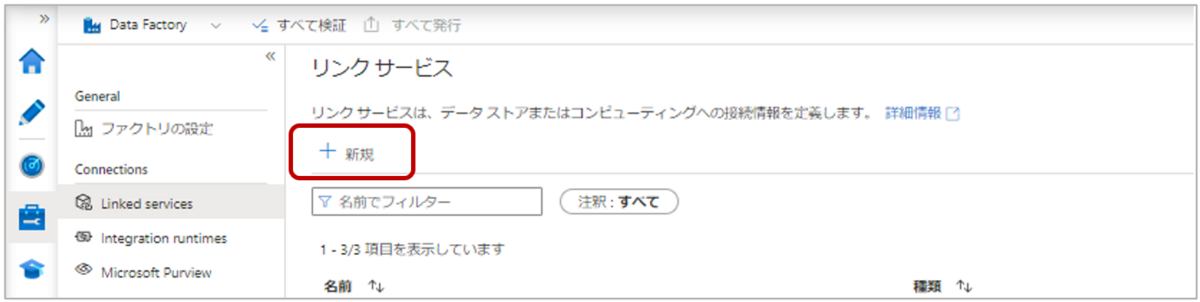
1-1.Data Factoryの左側ウィンドウ「管理」タブの”Connections”から「Linked services」を選択し、「新規」をクリックします。
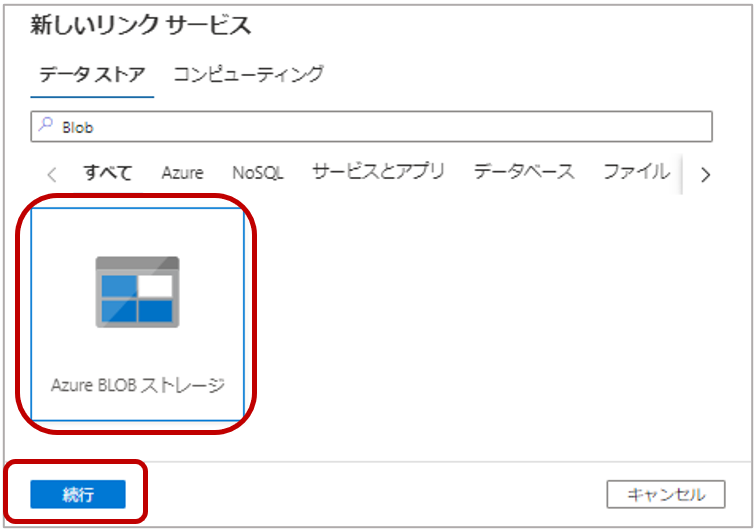
1-2.新しいリンクサービスページで「Azure Blob ストレージ」を選択し、「続行」をクリックします。
1-3.下記を設定し、「作成」をクリックします。
| 新しいリンクサービス | |
| 名前 | AzureBlobStorage |
| 説明 | - |
| 統合ランタイム経由で接続 | AutoResolveIntegrationRuntime |
| 認証の種類 | |
| アカウントキー | |
| 接続文字列 | |
| アカウントの選択方法 | Azureサブスクリプションから |
| └Azureサブスクリプション | サブスクリプションを選択 |
| └ストレージアカウント名 | ストレージアカウントを選択 |
| 追加の接続プロパティ | - |
| テスト接続 | 宛先のリンクサービス |
アカウントの選択方法では、3.事前準備で用意したストレージアカウントを選択します。
SQLリンクサービス
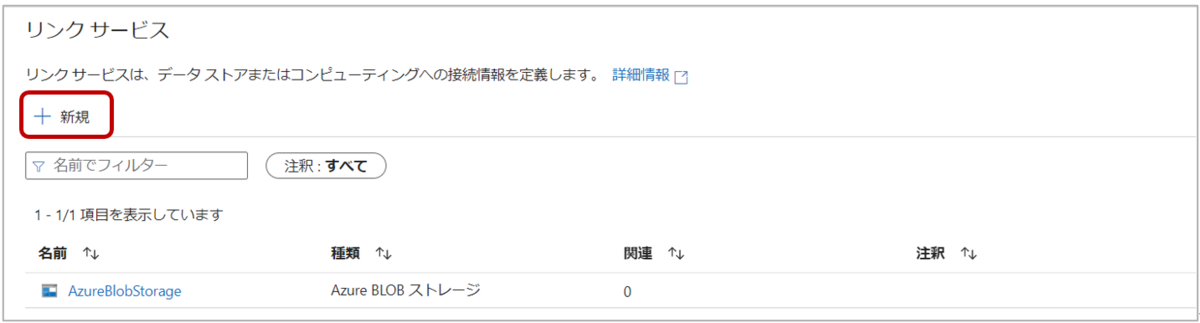
1-4. Data Factoryの左側ウィンドウ「管理」タブの”Connections”から「Linked services」を選択し、「新規」をクリックします。
1-5. 新しいリンクサービスページで「Azure SQL Database」を選択し、「続行」をクリックします。
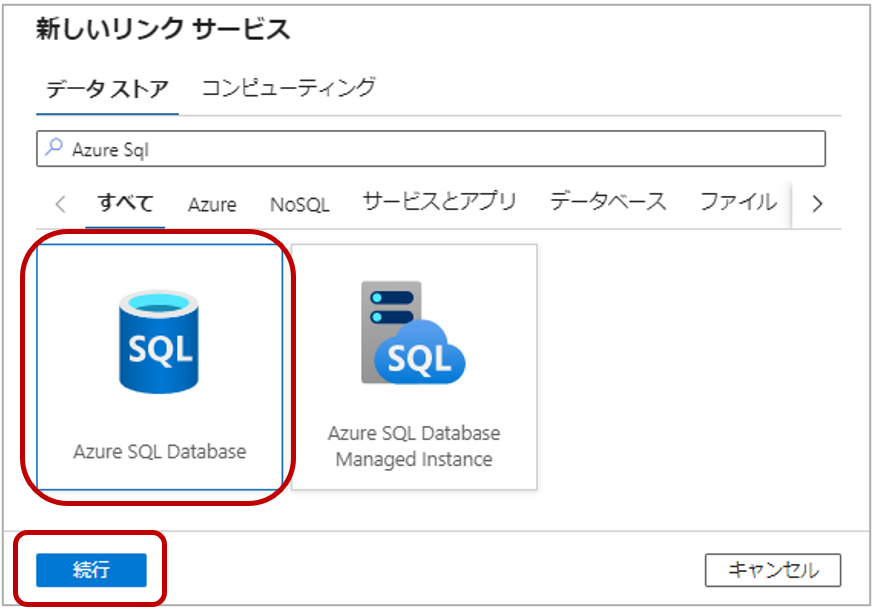
1-6. 下記を設定し、「作成」をクリックします。
| 新しいリンクサービス | |
| 名前 | AzureSQLDatabase |
| 説明 | - |
| 統合ランタイム経由で接続 | AutoResolveIntegrationRuntime |
| 接続文字列 | |
| アカウントの選択方法 | Azureサブスクリプションから |
| └Azureサブスクリプション | サブスクリプションを選択 |
| └サーバ名 | SQL Serverを選択 |
| └データベース名 | SQL Databaseを選択 |
| 認証の種類 | SQL認証 |
| ユーザー名 | SQL認証のユーザー名を入力 |
| パスワード | SQL認証のパスワードを入力 |
| Always Encrypted | □ |
| 追加の接続プロパティ | - |
| テスト接続 | 宛先のリンクサービス |
アカウントの選択方法では、3.事前準備で用意したSQL Server、SQL Databaseを選択します。
データセットの作成
Blobデータセット
2-1. Data Factoryの左側ウィンドウ「Author」タブの”Datasets”から「新しいデータセット」をクリックします。
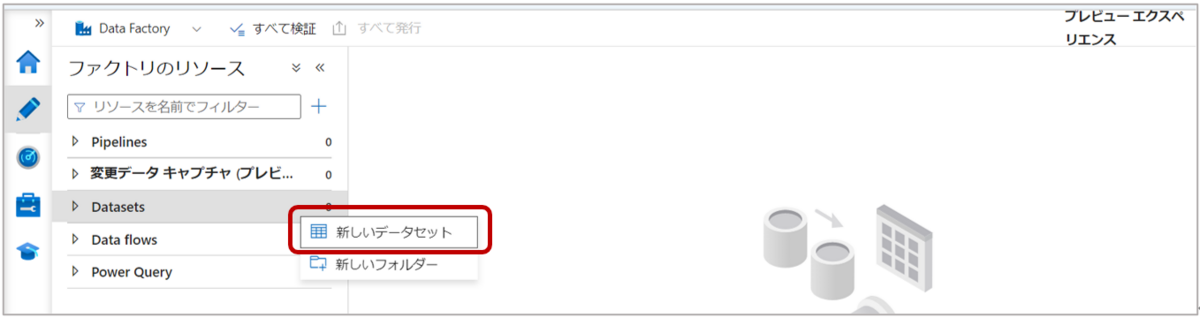
2-2.新しいデータセットページで「Azure Blob ストレージ」を選択し、「続行」をクリックします。
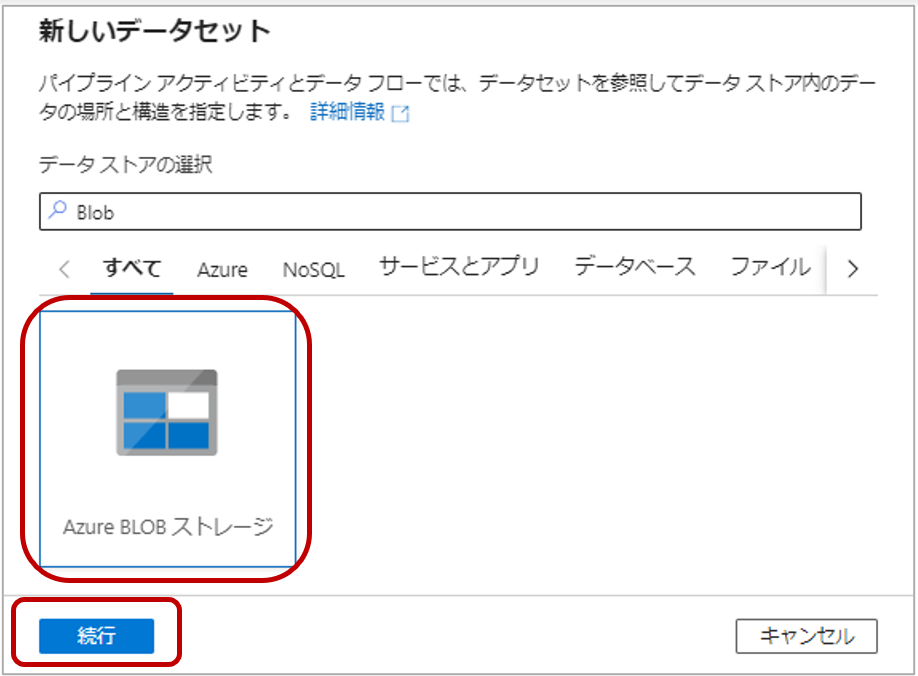
2-3.形式の選択でDelimited Textを選択し「続行」をクリックします。
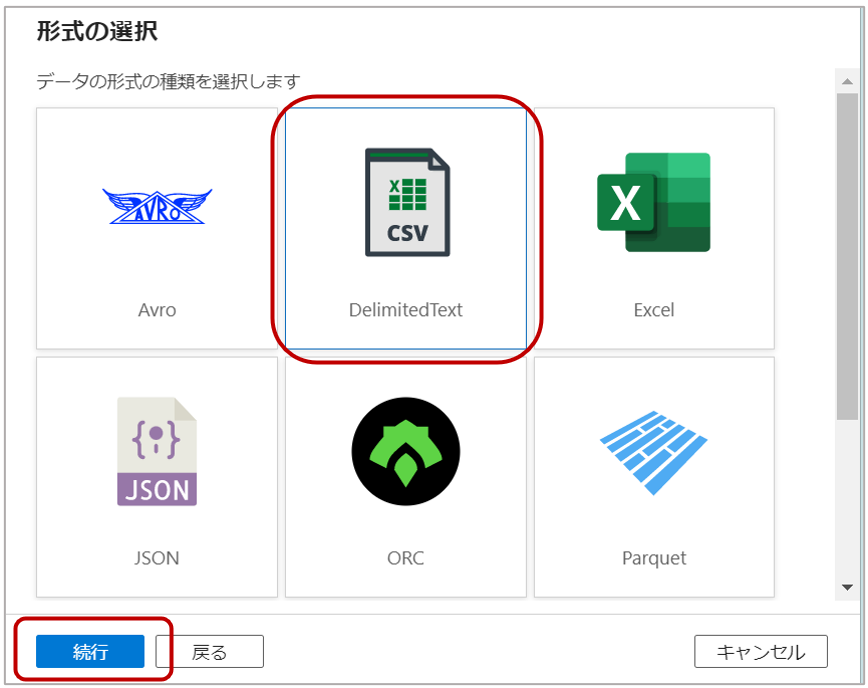
2-4.プロパティで下記を設定し、「ok」をクリックします。
| プロパティの設定 | |
| 名前 | BlobDataset |
| リンクサービス | AzureBlobStorage |
| ファイルパス | Blob(CSVファイル)が格納されているファイルパスを選択 |
| 先頭行をヘッダーとして | ☑ |
| スキーマのインポート | サンプルファイルから |
| └ファイルの選択 | 列スキーマをインポートするためにコピーしたいBlob(CSVファイル)を選択 |
SQLデータセット
2-5. Data Factoryの左側ウィンドウ「Author」タブの”Datasets”から「新しいデータセット」をクリックします。
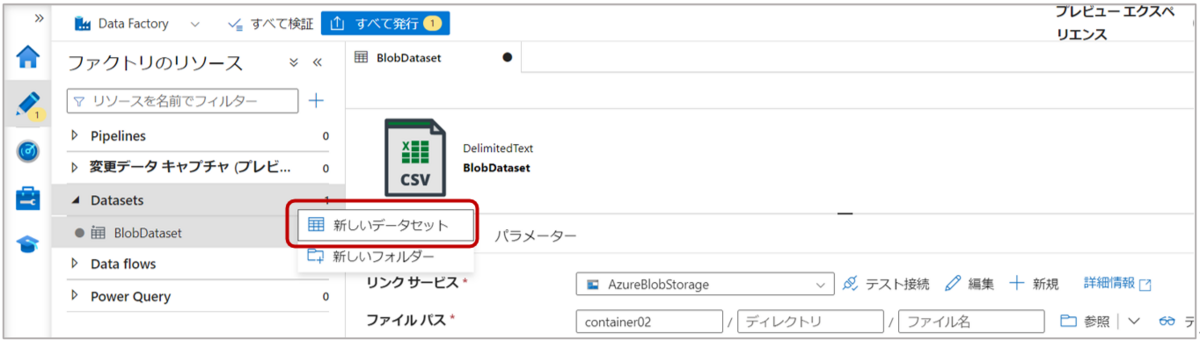
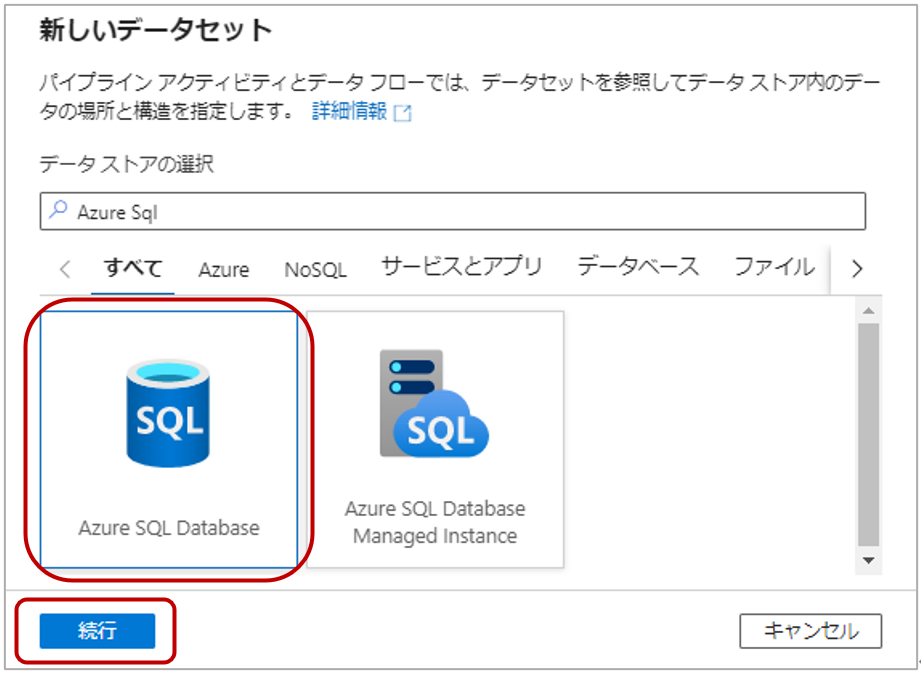
2-6.新しいデータセットページで「Azure SQL Database」を選択し、「続行」をクリックします。
2-7. 下記を設定し、「ok」をクリックします。
| プロパティの設定 | |
| 名前 | SQLDataset |
| リンクサービス | AzureSQLDatabase |
| テーブル名 | SQLテーブル名をドロップダウンで選択 |
| スキーマのインポート | 接続またはストアから |
パイプラインの作成
3-1. Data Factoryの左側ウィンドウ「Author」タブの”Pipelines”から「新しいパイプライン」をクリックします。
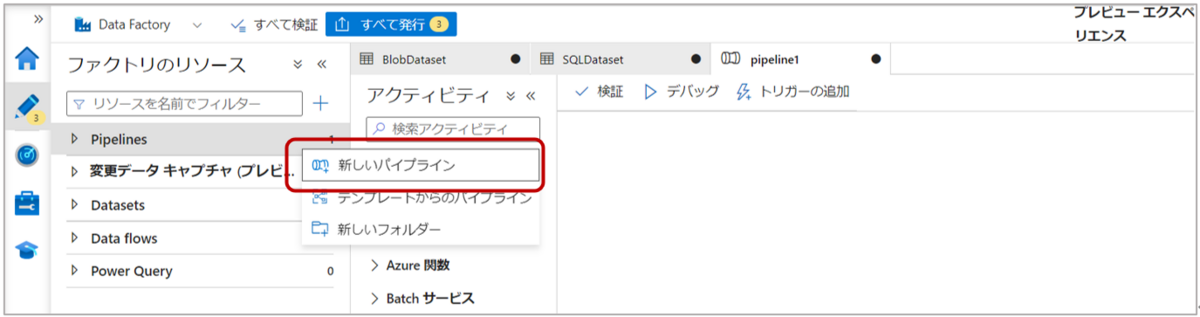
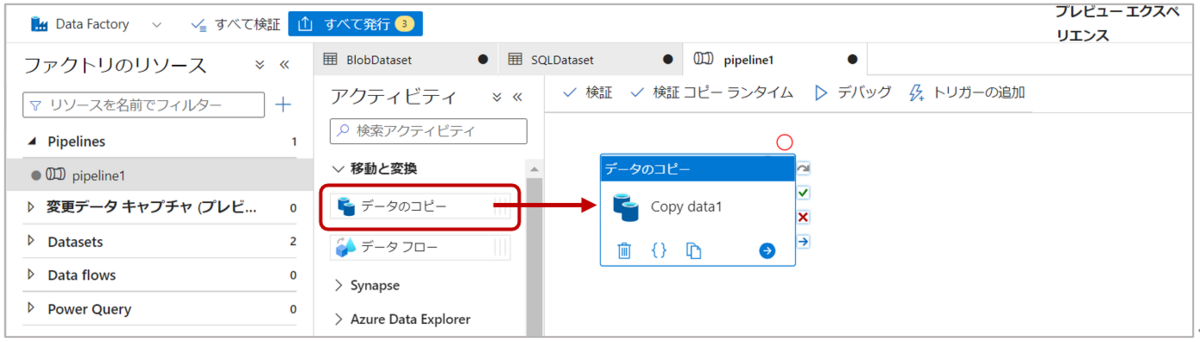
3-2.アクティビティの”移動と変換”から「データのコピー」をパイプラインにドラッグ&ドロップします。
3-3.コピーアクティビティで下記を設定します。
| 全般 | ||||
| 名前 | CopyCSVFromBlobToSQL | |||
| ソース | ||||
| ソースデータセット | BlobDataset | |||
| ファイル パスの種類 | ワイルドカードファイルパス | |||
| ワイルドカードパス | - | |||
| フォルダーパス | - | |||
| ファイル名 | * | |||
| シンク | ||||
| シンクデータセット | SQLDataset | |||
| 書き込む動作 | 挿入 |
3-4.マップタブで「スキーマのインポート」をクリックし、マッピングを確認します。
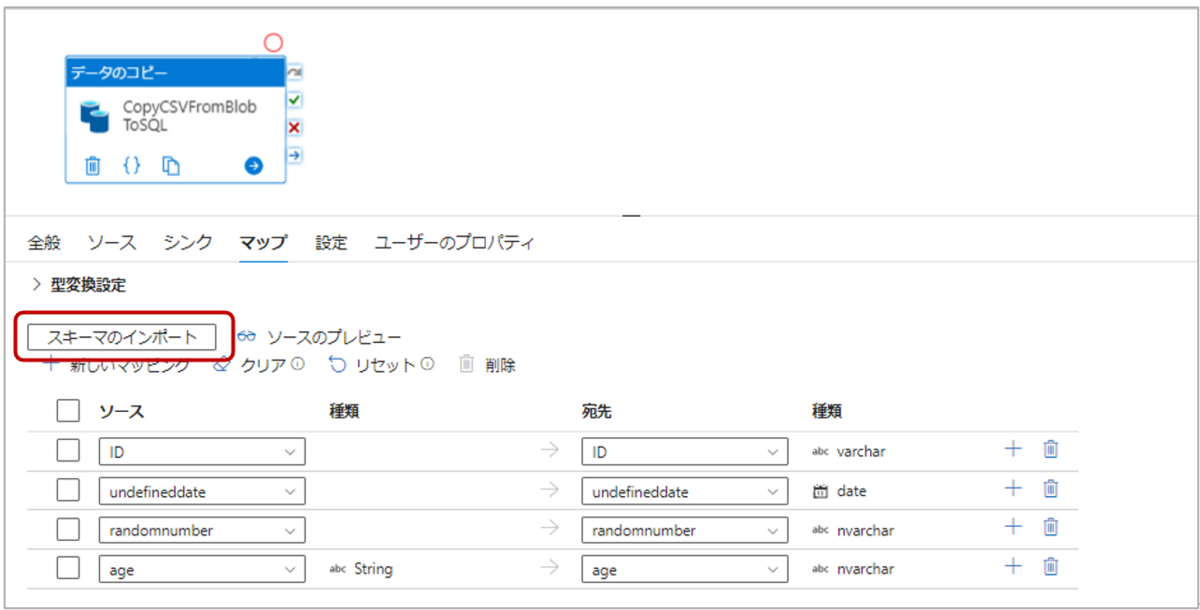
ここでは、ソーススキーマ(コピー元)とシンクスキーマ(コピー先)を読み込み、列のマッピングを定義します。
検証と発行
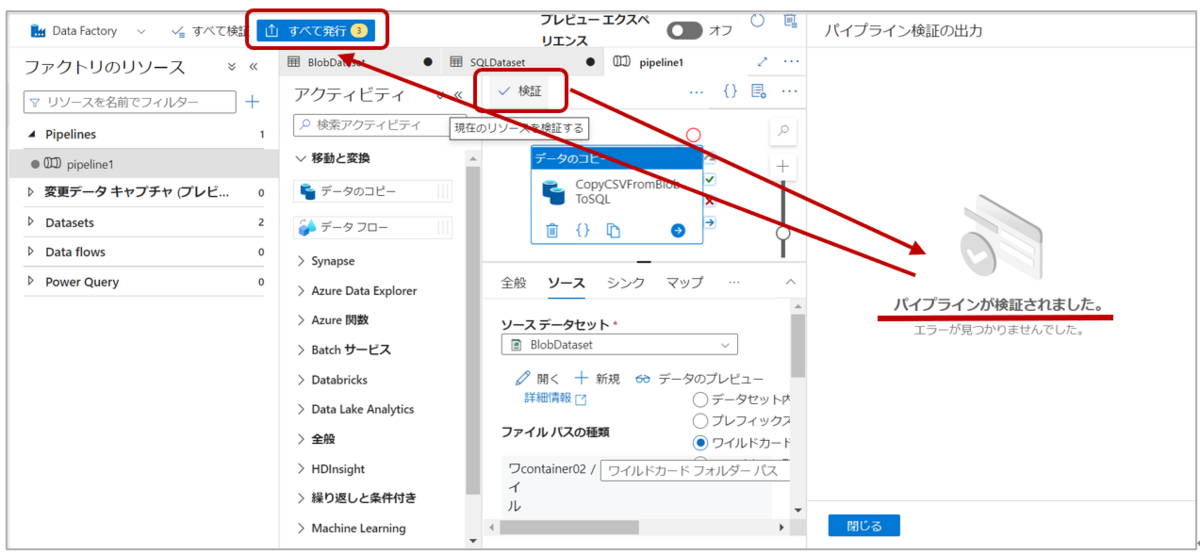
「検証」をクリックし、パイプラインを検証し、エラーが出なければ「すべて発行」をクリックしパイプラインを保存します。
パイプラインの実行と確認
5-1.“トリガーの追加”→「今すぐトリガー」をクリックし、パイプラインを実行します。
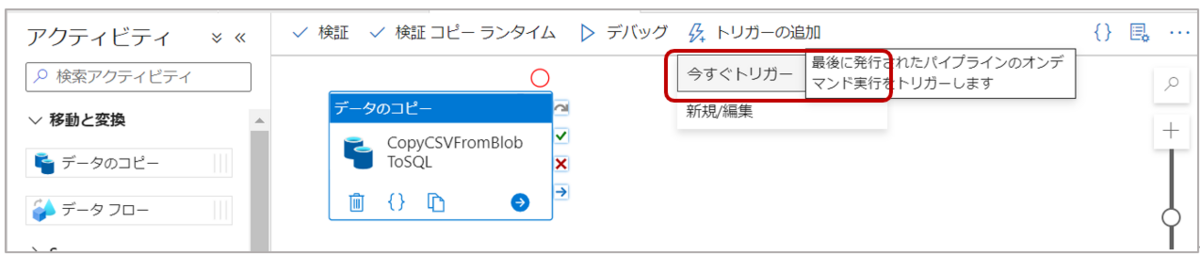
トリガーには「今すぐトリガー」以外にも、「新規/編集」からスケジュールトリガーやストレージイベントトリガーを設定出来ます。
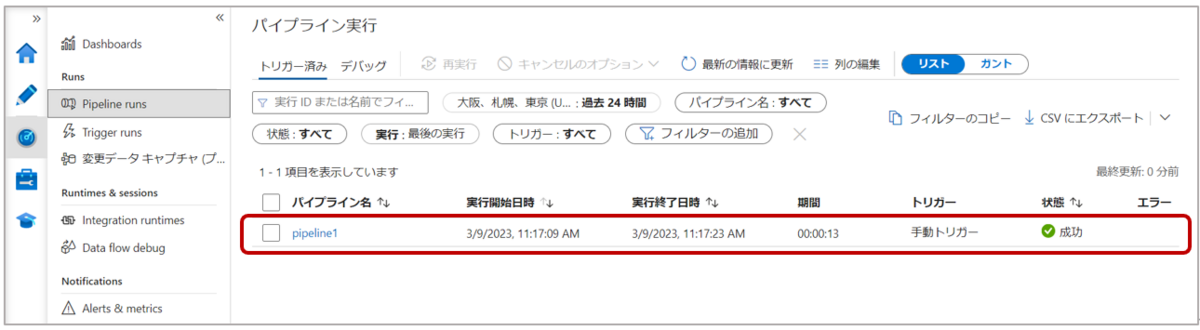
5-2. Data Factoryの左側ウィンドウ「Monitor」タブの”Pipeline runs”をクリックし、パイプラインの実行が成功したことを確認します。
5-3.Azure SQL Databaseを開き、テーブルにCSVファイルのデータがコピーされていることを確認します。

おわりに
本記事では、Azure Data Factoryを使用した簡易的なデータコピー方法を紹介しました。
コピーアクティビティの他にも、Azure Data Factoryではデータの加工・変換や実行スケジューリング、ストレージイベントによるパイプライントリガー、モニタリングなど様々な機能を利用することが出来ます。
また、パラメーター化されたデータパイプラインを作成することでより柔軟で効率的なデータ連携も可能なので、そちらについても紹介していきたいと思っています。
