
本記事では、データエンジニアリング初学者の学習記録として、データエンジニアリングの概要から実践までの内容をまとめています。
今回は後編として、Azure Data Factoryの実装手順やパイプラインについてご紹介します。
データの準備
今回は以下のデータを使用します。
- 監査ログ(Power Automate・Power Apps・Power BI)
- Microsoft Purview コンプライアンス ポータルから取得
- ユーザーデータ
- Microsoft Entra IDからユーザーの一覧をダウンロード
必要な Azure リソースの作成
- ストレージアカウント
- Azure Data Factory
- Azure SQL データベース
- Function App
ストレージアカウント
- データセット格納用のストレージアカウントを作成します。

- 基本情報等を設定します。

- 「詳細設定」で階層型名前空間を有効にします。

※以降の設定はすべてデフォルトのままにします。
- CSVファイル格納用のBlobコンテナを作成します。
- processedcontainer
- rawcontainer
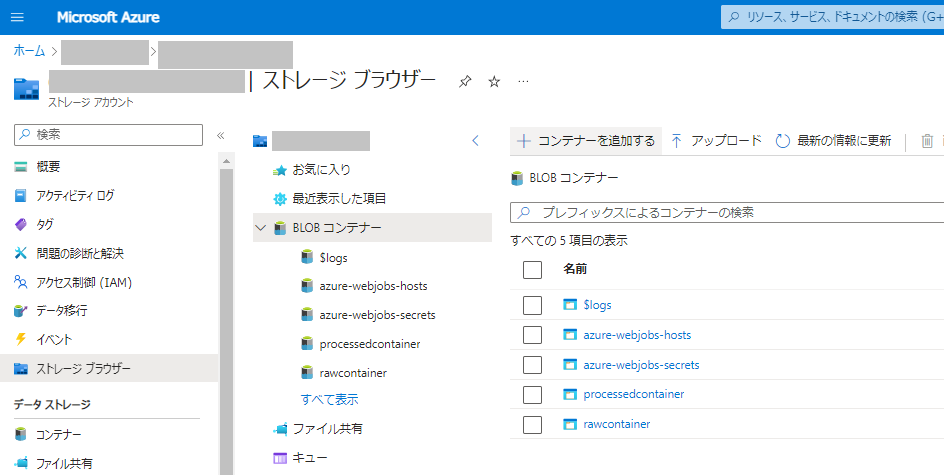
- 作成したrawコンテナーにCSVファイルをアップロードします。その際、以下のようにフォルダーを指定します。

Azure Data Factory
- Marketplaceで「Data Factory」を検索して作成します。

- 基本情報等を設定します。

※基本情報以外はすべてデフォルトの設定のままにします。
Azure SQL Database
- 加工したデータを格納するSQL Databaseを作成します。

- データベースの詳細を設定していきます。

- SQL Database サーバー未作成の場合は、「新規作成」をクリックします。
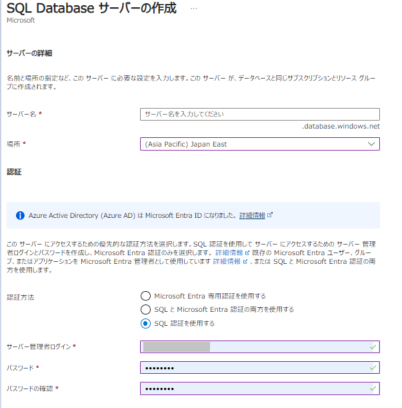
- 「ネットワーク」でファイアウォール規則の以下の設定を有効にします。

- 「追加設定」でデータベース照合順序を「Japanese_CI_AS」に設定します。

SQLテーブル
Azure SQL Databaseのクエリエディターから加工後のデータを格納するテーブルを作成します。
- Azure SQL Databaseを開きます。
- [クエリエディター]をクリックします。
- LogDataおよびUserDataテーブルを作成するクエリを実行します。
CREATE TABLE dbo.LogData ( CreationDate NVARCHAR NULL, ResourceDisplayName NVARCHAR NULL, ResourceId NVARCHAR NULL, EnvironmentDisplayName NVARCHAR NULL, RecordId NVARCHAR PRIMARY KEY, RecordType NVARCHAR NULL, Operation NVARCHAR NULL, UserId NVARCHAR NULL, ObjectId NVARCHAR NULL, AppName NVARCHAR NULL );CREATE TABLE dbo.UserData ( userPrincipalName NVARCHAR NULL, displayName NVARCHAR NULL, mail NVARCHAR NULL, id NVARCHAR PRIMARY KEY, department NVARCHAR NULL, userAddress NVARCHAR NULL );
Function App
今回使用するPower Platform監査ログは、AuditData列をJSON形式に変換して展開する必要がありました。
Azure Data FactoryのPower Queryやデータフローの組み込みの関数では、上記のデータを処理するのは難しいため、C#でCSV Helperを用い、AuditData列を読み取り・加工・変換したデータを新しいCSVとして保存することにしました。
- Marketplaceで「関数アプリ」を検索して作成します。

- 基本情報等を設定します。

- 「Storage」で先ほど作成したストレージアカウントを選択します。
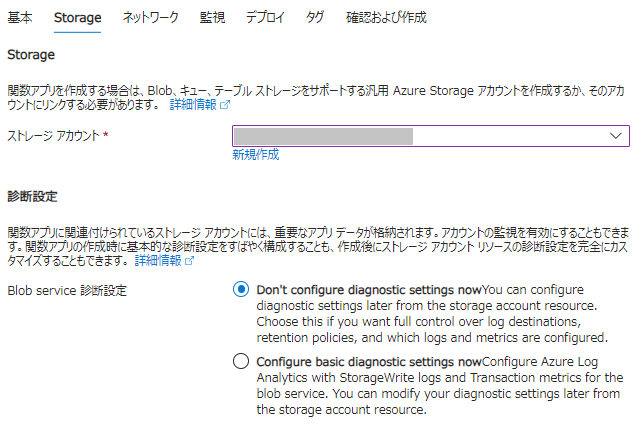
※以降の設定はすべてデフォルトのままにします。
- Visual Studioを開き、新しいプロジェクトを構成します。


-
コードを作成したら関数名を右クリックしてAzureに発行します。

Azure Data Factoryでの操作
Linked Service / データセットの作成
Linked Serviceとは、Data Factory が外部リソースに接続するために必要な接続情報を定義するものです。
接続用のコネクタは90種類以上あり、オンプレミス・クラウドの両方の指定が可能です。

- Azure Data Factory Studioを起動します。
- 画面左のメニューバーから [管理] - [リンクサービス]を選択します。
- [+新規]からAzure Blob ストレージのリンクサービスを作成します。
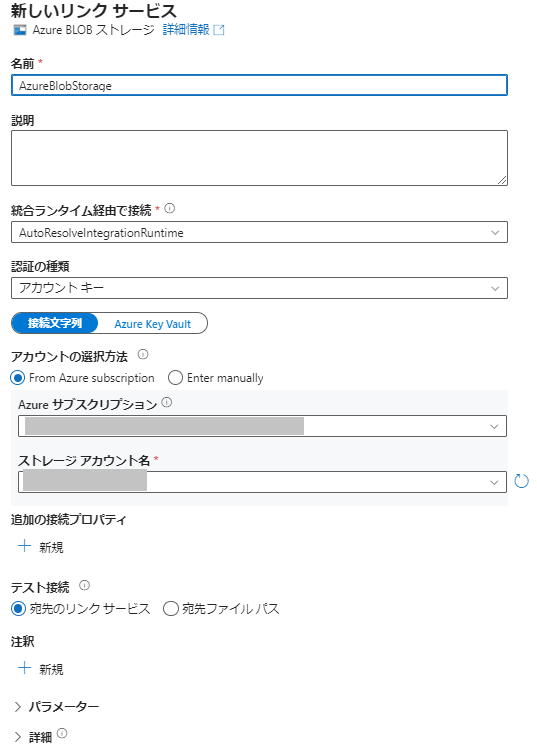
- Azure Function、Azure SQL Databaseのリンクサービスを同じように作成します。

パイプラインの作成
パイプラインとは、複数のアクティビティから成る論理的なグループで、アクティビティをセットとして管理できるメリットがあります。
- Azure Data Factory Studioを起動します。
- 画面左のメニューバーから [作成者] - [パイプライン]を右クリックします。
- [新しいパイプライン]をクリックします。

データセットの作成
データセットとは、データ ストア内のデータ構造を表しています。
パイプラインのアクティビティで入力と出力として使用するデータを指定または参照する際に使用します。
- Azure Data Factory Studioを起動します。
- 画面左のメニューバーから [作成者] - [データセット]を右クリックします。
- [新しいデータセット]をクリックします。
- データストアと形式を選択します。
- データストア:Azure Blob Strage
- データ形式:DelimitedText(CSV)
- プロパティを設定します。

- 同様の手順で残りの3つのデータセットを作成します。
- AzureSqlTable1:データフローのシンクに使用
- AzureSqlTable2:コピーアクティビティのシンクに使用
- DelimitedText_ProcessedLog:コピーアクティビティのソースに使用
- DelimitedText_User:データフローのソースに使用
データフロー
データフローとは、Azure Data Factory における視覚的に設計されたデータ変換です。 データ フローを使用すると、データ エンジニアは、コードを記述することなくデータ変換ロジックを開発できます。
- Azure Data Factory Studioを起動します。
- 画面左のメニューバーから [作成者] - [データフロー]を右クリックします。
- [新しいデータフロー]をクリックします。
- ソースを以下のように設定します。

- [+] - [フィルター] をクリックします。
- ユーザータイプをフィルターします。

- [+] - [選択] をクリックします。
- 必要な列をマッピングに追加します。

- [+] - [シンク] をクリックします。
- シンクを以下のように設定します。

アクティビティの作成
アクティビティとは、パイプライン内の処理ステップを表します。
アクティビティには3種類あります。
- データ移動アクティビティ
- ソースデータストアからシンクデータストアにデータをコピーするためのアクティビティです。
- 例)Copyアクティビティ
- データ変換アクティビティ
- データを処理または変換するためのアクティビティです。
- 例)データフローアクティビティ、Databricks Notebookアクティビティ
- 制御アクティビティ
- 他のアクティビティの実行を制御するためのアクティビティです。
- 例)条件付きアクティビティ、ループアクティビティ
- Azure関数アクティビティを追加します。
- 「設定」で作成したリンクサービス、関数名を設定します。

- コピーアクティビティを追加します。
- 「ソース」と「シンク」を以下に設定します。


- データフローアクティビティを追加します。
- 「設定」で作成したデータフローを選択します。

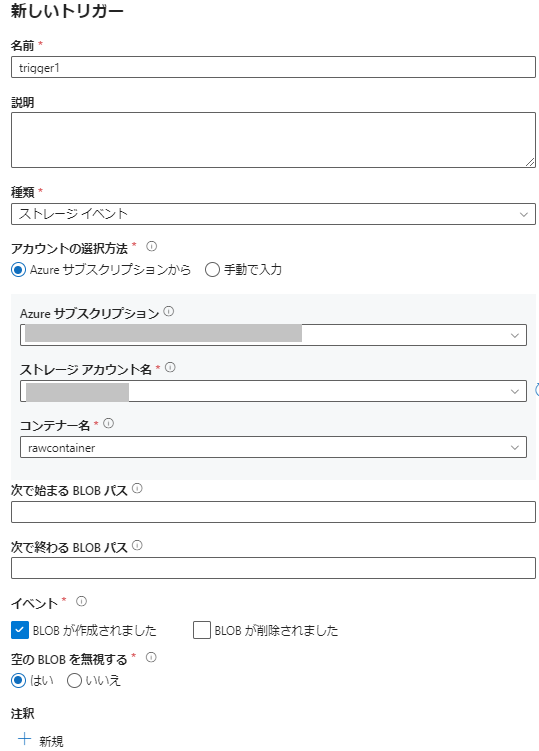
- 画面上部の [トリガーの追加] をクリックします。

- 指定したコンテナーにBlobが作成されたときにトリガーするように設定します。
データの可視化(Power BIとの連携)
加工したデータをPower BIレポートで可視化します。
- Power BI Desktopを開きます。
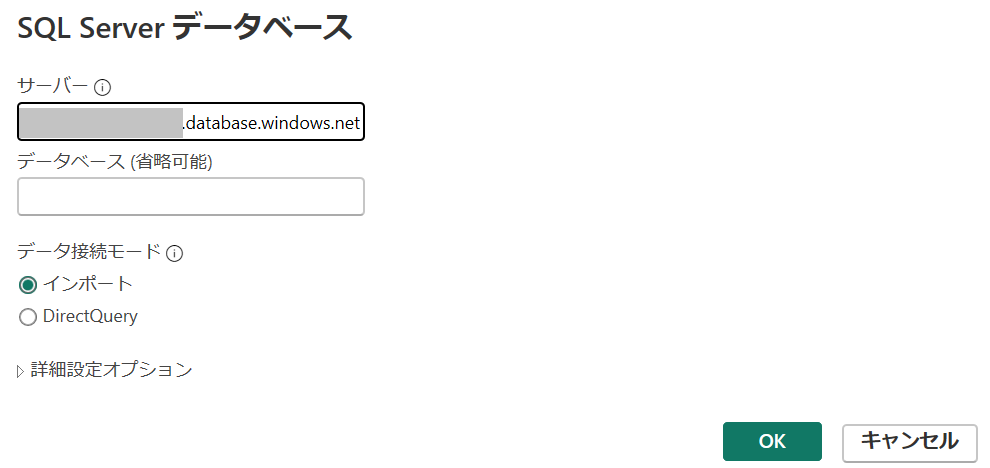
- [データを取得] - [SQL Server] をクリックします。
- サーバー欄にAzure SQL Databaseのサーバー名を入力します。
- 接続するテーブルを選択して [読み込み] をクリックします。
Power BIの操作は省略しますが、監査ログを使用して以下のようなレポートを作成しました。

つまづいた点
- 監査ログCSVファイルのデータ整形
- データフローやPower Queryを利用して監査ログを加工しようとしましたが、うまくいきませんでした。
- データフローやPower Queryでは、今回のシナリオを処理するのは難しいと分かるまでに時間がかかりました。
- SQLデータベース 日本語の文字化け
- 当初はSQL構築時に照合順序を既定のままで作成していたため、コピーアクティビティでデータ格納後、日本語が文字化けしていました。
- 照合順序をJapanese_CI_ASに設定して解決しました。
まとめ
今回は実際にAzure Data Factoryの実装方法とデータの抽出・加工・可視化をご紹介しました。
また、パイプラインを使用するメリットとして以下が挙げられます。
- 使いやすい形のデータを提供できる
- BI側でデータ整形を作り込みすぎると移行や改修が大変
- 処理速度が速い
- 大規模データを扱うときにPower BIのPower Queryでは処理速度の問題が出てくる
前編・後編にてデータエンジニアリング初学者の記録をご紹介しました。ご精読ありがとうございました。
