
本記事では、データエンジニアリング初学者の学習記録として、データエンジニアリングの概要から実践までの内容をまとめています。
今回は前編として、データエンジニアリングおよびAzure Data Factoryについてご紹介します。
- データエンジニアリングとは?
- データエンジニアリングの必要性
- データエンジニアリングのプロセス
- Azure Data Factoryについて
- 実践するシナリオについて
- おまけ:ダミーデータを用意する
- まとめ
データエンジニアリングとは?
データエンジニアリングはデータサイエンティスト協会が定義している3つのスキルセットの1つです。

(出典:一般社団法人データサイエンティスト協会スキル定義委員会[2023]「2023年度スキル定義委員会活動報告/2023年度版スキルチェックリスト&タスクリスト公開」
具体的には、ビッグデータと呼ばれる大量のデータを活用してビジネスに役立つ情報を生成するプロセスで、以下の3つの主要な作業を行います。
- データ基盤の構築と運用
- データを整理し、データサイエンティストやビジネスアナリストが使いやすい形で保存するシステムを構築します。
- データ収集
- 有用なデータを見つけて収集します。
- 例)天気予報のデータや売上データを集めます。
- データの整理と加工:
- 収集したデータを整理し、分析しやすい形に加工します。
- 例)重複するデータを削除したり、グラフに変換したりします。
データエンジニアリングの必要性
ビジネスにおいてデータは貴重な資産です。事業成長に伴いデータの量と種類が増え、様々なデータソースが散在してしまうと価値を最大化できません。
そのため、データエンジニアリングによって、データベースやデータパイプラインを構築し、データの収集、保存、分析を効率的に行えるようにします。
また、ビジネスの意思決定には正確で信頼性のあるデータが必要です。データエンジニアリングはデータの品質を保証し、信頼性の高い基盤を構築できます。
まとめると以下の理由から必要不可欠だと言えます。
- データの価値を最大化する
- 効率的なデータ処理を実現する
- 信頼性の高いデータ基盤を構築する
- ビジネスの成果を支える
データエンジニアリングのプロセス
データエンジニアリングのプロセスは、以下の主要なステップで構成されます。
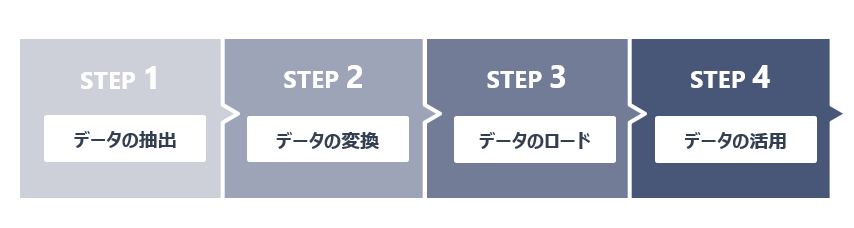
- データの抽出
- 異なるソースからデータを抽出します。
- これには、データベース、API、ファイルシステムなどが含まれます。
- データの変換
- 抽出したデータをビジネスルールや要件に基づいて変換します。
- このステップでは、データのクリーニング、標準化、集約などが行われます。
- データのロード
- 変換されたデータをデータウェアハウスやデータベースにロードします。
- データの活用
- ロードされたデータは、ビジネスインテリジェンス(BI)ツール、データビジュアライゼーションツール、または高度な分析ツールを使用して分析されます。
- このステップでは、パターン、トレンド、インサイトを特定し、ビジネスの意思決定をサポートするための有用な情報を提供します。
Azure Data Factoryについて
Azure Data Factory は、クラウドベースの ETL (Extract, Transform, Load) およびデータ統合サービスであり、データの移動と変換を大規模に制御するデータドリブンのワークフローを作成できます。以下は、Azure Data Factory の主な機能と利点です:
- データ主導型のワークフロー (パイプライン) の作成
- Azure Data Factory を使用すると、各種のデータストアからデータを取り込むことができるデータ主導型のワークフロー (パイプライン) を作成できます。
- これにより、データの移動、変換、統合を効率的に実行できます。
- スケジューリングと自動化
- パイプラインはスケジュールでき、定期的なデータの移動や変換を自動化できます。
- 例えば、毎日特定のデータソースからデータを抽出してデータウェアハウスにロードするパイプラインを設定できます。
- 視覚的なデータ変換
- Azure Data Factory では、コンピューティングサービス (Azure HDInsight Hadoop、Azure Databricks、Azure SQL Database など) やデータフローを使用してデータを変換する複雑な ETL プロセスを視覚的に作成できます。
- これにより、データの前処理や変換を簡素化できます。
- ビジネスインテリジェンス (BI) アプリケーションとの連携
- Azure Synapse Analytics などのデータストアに変換済みのデータを公開することで、ビジネスインテリジェンス (BI) アプリケーションから利用できるようになります。
- より的確な意思決定に活用できます。
実践するシナリオについて
今回は、Power Platformの監査ログを使用して、社内でのPower Platform定着率を可視化しました。
使用するデータ
- 監査ログ(Power Automate・Power Apps・Power BI)
- ユーザーデータ
主な流れ

おまけ:ダミーデータを用意する
今回、一度実際の監査ログを使用してシナリオに取り組みましたが、メールアドレスや部署情報をマスキングする必要があり、そのデータ加工をAzure Data Factoryで行うのに苦労しました。
そこで、実際のデータの構造と同じダミーデータを生成できないか試してみました。
生成AIでPower Platformの監査ログとユーザー情報のダミーデータを作成する方法をご紹介いたします。
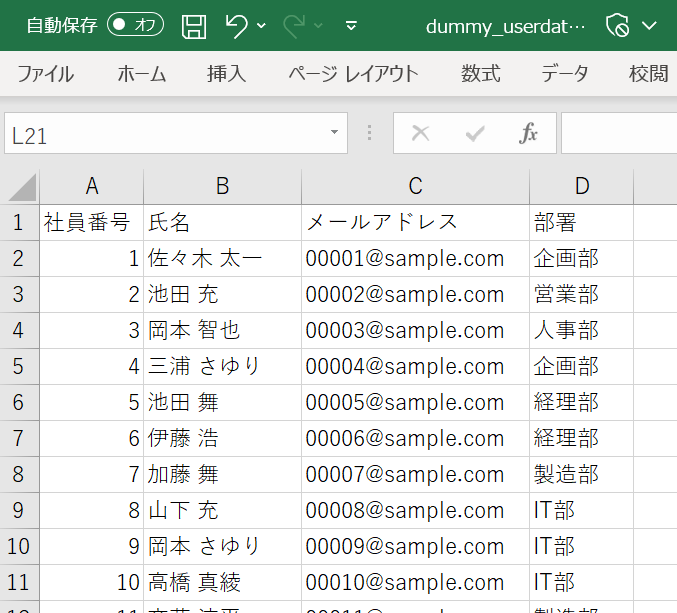
ユーザー情報の作成
今回は1000人のユーザー情報を作成します。データを作成するPythonコードはGPTを利用して生成しました。
プロンプト
あなたはシステムテストエンジニアです。特定の業務システムのシステムテストを実施するためのダミーデータを作成したいです。
以下の条件を満たしたダミーデータを作成するPythonコードを教えてください。
#条件
- CSVは1000行4列のデータ。
- ヘッダー行は"社員番号,氏名,メールアドレス,部署"で構成されている。
- IDは5桁で生成し、空いた部分は0埋めする。
- 氏名は"姓 名" のフォーマットで日本人の名前からランダムに生成する。
- 名は男性、女性半々の割合で生成する。
- メールアドレスは”[ID] @sample.com ”の形式で生成する。
- 部署は日本の企業でよく使われる本部を設定してください。
#ルール
- ID、メールアドレス、氏名は必ず一意の値でなければならない。
#出力
- CSV形式
- ファイル名:dummy_userdata.csv生成されたコード
import random
import csv
import faker
# Fakerのインスタンスを生成
fake = faker.Faker('ja_JP')
# 社員番号のリストを生成(1から1000までの整数を5桁の文字列に変換)
ids = [str(i).zfill(5) for i in range(1, 1001)]
# 本部のリストを生成
departments = ['営業部', '人事部', '開発部', '企画部', '製造部', '総務部', '経理部', 'IT部']
# CSVファイルに書き込む
with open('dummy_userdata.csv', 'w', newline='') as csvfile:
fieldnames = ['社員番号', '氏名', 'メールアドレス', '部署']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
# 生成した名前を保存するためのセット
created_names = set()
for i in range(1000):
# ランダムな日本人の名前を生成
name = fake.name()
# 名前が重複している場合は新しく名前を生成
while name in created_names:
name = fake.name()
created_names.add(name)
writer.writerow({
'社員番号': ids[i],
'氏名': name,
'メールアドレス': f'{ids[i]}@sample.com',
'部署': random.choice(departments),
})
Power Platform監査ログの作成
実際の監査ログをExcelで開き、Copilotを活用してダミーデータ生成のコードを書かせてみました。
プロンプト
あなたはシステムテストエンジニアです。特定の業務システムのシステムテストを実施するためのダミーデータを作成したいです。
以下の条件を満たしたダミーデータを作成するPythonコードを教えてください。
#条件
- CSVは10000行のデータ。
- このテーブルと同じデータ構造のダミーデータを作成してください。
- UserIdは1~1000のランダムな数値を使用してください。
- Operation列はOperationTableに存在する値を使用し、RecordType 列はOperation列の値に一致するものを設定してください。
- RecordTypeとOprationは紐づいている必要があります。
具体的には、Operationで「AnalyzedByExternalApplication」を設定した場合、RecordTypeは「20」である必要があります。
#OperationTableのデータ
[ここにOperationTableのデータを記載する]
#ルール
- RecordIdは必ず一意の値でなければならない。
#出力
- CSV形式
- ファイル名:dummy_logdata.csv生成されたコード
import csv
import random
import uuid
from datetime import datetime, timedelta
# OperationTableのデータを辞書に格納する
operation_table = {
"AnalyzedByExternalApplication": "20",
"ConnectFromExternalApplication": "20",
"CreateDataset": "20",
"CreateReport": "20",
"DeleteEmailSubscription": "20",
"DeleteReport": "20",
"DiscoverSystemDetailsOfMoniker": "20",
"DownloadReport": "20",
"EditDataset": "20",
"EditReport": "20",
"ExportArtifact": "20",
"ExportReport": "20",
"GenerateCustomVisualAADAccessToken": "20",
"GenerateDataflowSasToken": "20",
"GenerateScreenshot": "20",
"GetAllScorecards": "20",
"GetGroupUsers": "20",
"GetSnapshots": "20",
"GetWorkspacesInfoAPI": "20",
"GetWorkspacesInfoResult": "20",
"Import": "20",
"ListLakehouseTables": "20",
"OptInForPPUTrial": "20",
"ReadArtifact": "20",
"RefreshDataset": "20",
"ShareReport": "20",
"UpdateDatasetParameters": "20",
"UpdateDatasourceCredentials": "20",
"UpdateWorkspaceAccess": "20",
"ViewReport": "20",
"ViewTile": "20",
"CreateFlow": "30",
"DeleteFlow": "30",
"EditFlow": "30",
"PutPermissions": "30",
"CreatePowerApp": "45",
"DeletePowerApp": "45",
"LaunchPowerApp": "45",
"PowerAppPermissionEdited": "45",
"PublishPowerApp": "45",
"UpdatePowerApp": "45",
"PutConnection": "187",
"PutConnectionPermission": "187"
}
# CSVファイルに書き込む
with open('dummy_logdata.csv', mode='w', newline='') as file:
writer = csv.writer(file)
# ヘッダー行を書き込む
writer.writerow(["RecordId", "CreationDate", "RecordType", "Operation", "UserId"])
# 10000行のダミーデータを作成する
for i in range(10000):
record_id = str(uuid.uuid4())
start_date = datetime.strptime('2023-01-01', '%Y-%m-%d')
end_date = datetime.strptime('2023-12-31', '%Y-%m-%d')
time_between_dates = end_date - start_date
days_between_dates = time_between_dates.days
random_number_of_days = random.randrange(days_between_dates)
creation_date = start_date + timedelta(days=random_number_of_days)
creation_date = creation_date.strftime('%Y/%m/%d')
operation = random.choice(list(operation_table.keys())) # OperationTableのOperation列からランダムに選択
record_type = operation_table[operation] # Operation列の値に一致するRecordType列の値を設定
user_id = random.randint(1, 1000) # 1〜1000のランダムな数値を設定
# 行を書き込む
writer.writerow([record_id, creation_date, record_type, operation, user_id])
まとめ
今回はデータエンジニアリングとは何か、概要からその必要性などをご説明しました。
後編では実践編として、実際にAzure Data Factoryで実装したパイプラインなどをご紹介しますので、合わせてご覧ください。
