
Snowflakeは、AWSやGoogle Cloud、Microsoft Azureなどのクラウドプラットフォーム上でホストされるDWHサービスです。
ストレージとコンピュートを分離したマルチクラスタ・共有データアーキテクチャや、データの一元管理が可能な高い拡張性と柔軟性を備えるSnowflakeですが、今回はSnowflakeに対してAzure Data Factoryを使用してデータを連携する方法をご紹介します。
実施概要
本記事では、Azureのストレージアカウントに置かれているCSVファイルを、Snowflake内の同じカラムを持つテーブルにコピーします。
Data FactoryでのSnowflakeへの接続情報の作成とパイプライン作成に焦点を当てた記事となっていますので、データ取り込み元の接続情報の設定等は以下を参考にして事前準備として実施いただければと思います。
Data Factoryを使用してAzure Blob StorageからAzure SQL Databaseにデータをコピーする - JBS Tech Blog

本記事で使用するオブジェクトやファイルパスは以下の通りです。
- ストレージアカウント
- コンテナ:test01
- ディレクトリ:copy_to_snowflake
- ファイル名:sampletect1.csv
- Snowflake
- ウェアハウス:TESTWH_01
- データベース:TEST_DB01
- スキーマ:TEST_SCHEMA01
- テーブル:TABLE_USER01
事前準備
- Snowflakeアカウントの作成
- データをロードするためのSnowflakeアカウントを準備します。
- アカウントが無い場合、Snowflakeでは30日間のトライアルアカウントが使用出来ます。Snowflake Trial
- Snowflakeオブジェクトの作成
- Snowflakeにログインして、ウェアハウス、データベース、スキーマ、テーブル、ロールなどを作成します。
- テーブルは、使用するCSVファイルのカラム定義*1と同じものを作成します。
- Azure Data Factoryの作成
- データソースとなるリソースの作成およびData Factoryでの接続情報の作成
- 例)データソースをAzureのストレージアカウントとする場合、ストレージアカウントの作成およびData Factoryでストレージアカウントに接続するためのリンクサービスとデータセットの作成を行います。
- Data Factoryを使用してAzure Blob StorageからAzure SQL Databaseにデータをコピーする - JBS Tech Blog
- データソースに、SnowflakeにコピーするためのCSVファイルを配置
- 今回は以下のようなCSVファイルを使用します。

- 今回は以下のようなCSVファイルを使用します。
実施手順
Snowflakeリンクサービスの作成
1-1.Data Factoryの左側ウィンドウ「管理」タブの”Connections”から「Linked services」を選択し、「新規」をクリックします。
1-2.新しいリンクサービスページで「Snowflake」を選択し、「続行」をクリックします。

1-3.以下の表のとおりに、リンクサービスを作成します。
| 名前 | linkservice_snowflake |
| 統合ランライム経由で接続 | AutoResolveIntegrationRuntime |
| アカウント名 | Snowflakeアカウント名(<アカウントロケーター>.japan-east.azure) |
| データベース | データベース名 |
| ウェアハウス | ウェアハウス名 |
| ユーザー名 | ユーザー名 |
| パスワード | パスワード |
| ロール | デフォルトはPUBLIC。その他のシステムロールやカスタムロールを指定可能。 |
上記を設定後、リンクサービスの編集画面右下の「テスト接続」をクリックしてSnowflakeに接続出来ることを確認した後、設定を適用します。

データセットの作成
2-1.Factory Studio左側の「Author」タブの"データセット"から「新しいデータセット」をクリックします。
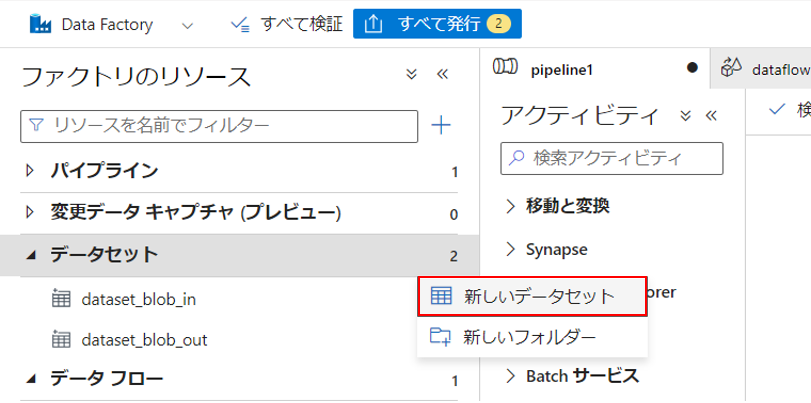
2-2.新しいデータセットページで「Snowflake」を選択し、「続行」をクリックします。

2-3.データセットの詳細を設定して「作成」をクリックします。
| 名前 | dataset_snowflake |
| リンクサービス | linkservice_snowflake |
| 統合ランタイム経由で接続 | ManagedIntegrationRuntime(AutoResolveIntegrationRuntimeでも可) |
| テーブル名 | <SCHEMA>.<TABLE> ※プルダウンで選択 |
| スキーマのインポート | 接続またはストアから |
2-4.データセットの作成後、「スキーマのインポート」をクリックしてカラム定義をインポートしておきます。

パイプラインの作成
3-1.Factory Studio左側の「Author」タブの"パイプライン"から「新しいパイプライン」をクリックします。

3-2.アクティビティの"移動と変換"から「データのコピー」をパイプラインにドラッグ&ドロップします。
 3-3.コピーアクティビティで以下の設定をします。
3-3.コピーアクティビティで以下の設定をします。

ソースタブで、CSVファイルを格納しているディレクトリとCSVファイル名を定義します。

シンクタブで、Snowflakeにデータをコピーするための事前コピースクリプトを設定します。Snowflakeのリンクサービス設定では、データべースとウェアハウスのみを定義しているため、ここでスキーマとテーブル名を定義します。

ストレージアカウントの、ファイルパスをステージングアカウントとして使用します。
リンクサービスとストレージパスを設定します。

3-4.マップタブで「スキーマのインポート」をクリックし、マッピングを確認します。
ここでは、ソーススキーマ(コピー元)とシンクスキーマ(コピー先)を読み込み、列のマッピングを定義します。

検証と発行
「すべて検証」をクリックしてパイプラインを検証し、エラーが出なければ「すべて発行」をクリックしてパイプラインを保存します。
パイプラインの実行と確認
5-1.「トリガーの追加」→「今すぐトリガー」をクリックし、パイプラインを実行します。

5-2. Data Factoryの左側ウィンドウ「Monitor」タブの”パイプライン実行”をクリックし、パイプラインの実行が成功したことを確認します。

5-3.Web UIでSnow sightにログインし、データが正常にコピーされていることを確認します。
SELECT * FROM table_user01;
実行結果:

おわりに
今回は、Data Factoryを使用してSnowflakeにデータをコピーする方法をご紹介しました。
本記事ではData FactoryからSnowflakeへのアクセスにプライベート接続を使用していませんが、Snowflakeへのプライベート接続についても今後別の記事でご紹介出来ればと思っています。
*1:事前準備5.を参照
