
Csol本部所属の福濵です。
本記事では、Microsoft Fabricのデータの取得からグラフ化の一連の手順についてご紹介します。
Microsoft Fabricを学び始めた方に参考にしていただければと思います。
はじめに
Microsoft Fabricとは
Microsoft社が提供するクラウドベースのオールインワン統合ソリューションのことです。
SaaS基盤上にPower BI、Azure Synapse、Azure Data Factoryを基にしたエクスペリエンスを1つの統合環境にまとめた構造となっています。これにより、すべてのデータ処理をFabric上で完結させることが可能となります。
以下がMicrosoftが述べる製品の利点と特徴です。
- 複数のベンダーの異なるサービスをまとめる必要がなくなる
- 業界に深く統合された幅広い分析へのアクセスが可能
- 身近で学びやすい共有エクスペリエンス
- 開発者は、すべてのリソースに容易にアクセスして再利用ができる
- 統合データレイクにより好みの分析ツールを使用しながらデータをそのまま保持できる
- 全てのエクスペリエンスにまたがる一元管理とガバナンス
参考:Microsoft Fabric とは - Microsoft Fabric | Microsoft Learn
実装内容
今回はローカル上のファイルをFabricのレイクハウスにアップロードし、そのデータをもとに整形、可視化を行います。
またパイプラインを作成し、定期実行の設定を行います。これによりグラフが自動で更新されるようにします。
実装準備
実装については以下の手順で行います。
- データのアップロード
- データのデータフローの作成
- データの可視化
- 定期実行の設定
今回は以下のデータセットを準備します。
sales_recordsテーブル
| ID | ITEM_ID | PURCHASED_AT |
| 1 | 1 | 2023-07-01 |
| 2 | 3 | 2023-07-01 |
| 3 | 5 | 2023-07-01 |
| 4 | 5 | 2023-07-01 |
| 5 | 3 | 2023-07-01 |
| 6 | 2 | 2023-07-01 |
| 7 | 3 | 2023-07-01 |
| 8 | 1 | 2023-07-01 |
| 9 | 2 | 2023-07-01 |
| 10 | 2 | 2023-07-02 |
| 11 | 4 | 2023-07-02 |
| 12 | 5 | 2023-07-02 |
| 13 | 1 | 2023-07-02 |
| 14 | 4 | 2023-07-02 |
| 15 | 2 | 2023-07-02 |
| 16 | 1 | 2023-07-02 |
| 17 | 4 | 2023-07-02 |
| 18 | 3 | 2023-07-02 |
| 19 | 4 | 2023-07-02 |
| 20 | 5 | 2023-07-03 |
| 21 | 4 | 2023-07-03 |
| 22 | 3 | 2023-07-03 |
| 23 | 1 | 2023-07-03 |
| 24 | 4 | 2023-07-03 |
| 25 | 2 | 2023-07-03 |
| 26 | 1 | 2023-07-03 |
| 27 | 3 | 2023-07-03 |
| 28 | 5 | 2023-07-03 |
| 29 | 2 | 2023-07-03 |
| 30 | 1 | 2023-07-03 |
itemテーブル
| ID | NAME | PRICE | COST |
| 1 | シャツ | 2900 | 900 |
| 2 | スカート | 3000 | 1200 |
| 3 | ジーンズ | 3000 | 1200 |
| 4 | ドレス | 9800 | 3000 |
| 5 | パーカー | 5500 | 1200 |
実装
データのアップロード
はじめにアップロード先であるレイクハウスを作成します。
Fabricを開き、1,左下のMicrosoft Fabricを押下し、2,Data Engineeringを選択します。
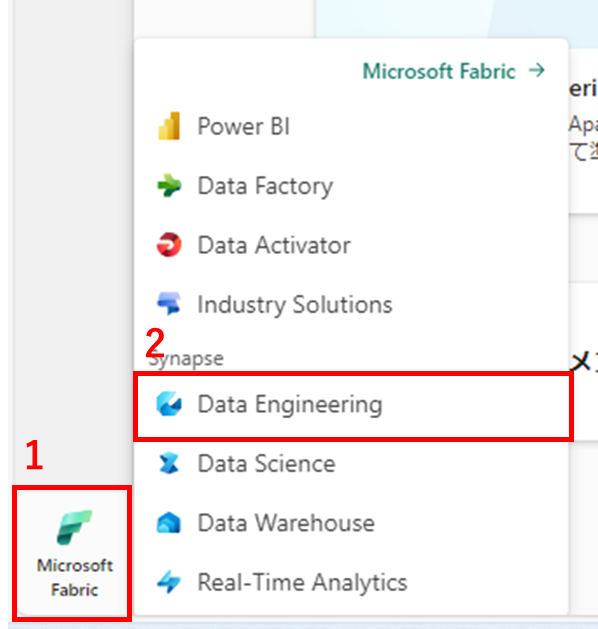
1,任意のワークスペースを選択し、2,+新規、3,レイクハウスを選択します。

任意の名前を入力し、作成します。

作成を行うと、レイクハウスの画面に自動で切り替わります。
ここへデータのアップロードをしていきます。

1,データの取得から2,ファイルのアップロードを選択します。

アップロードするファイルを指定し、アップロードを押下します。
sales_recordsテーブルのデータファイルに関しても同様に行います。

エクスプローラーのFilesを選択すると、アップロードしたファイルが格納されていることが確認できます。

指定ファイルの…を選択し、1,テーブルに読み込む、2,新しいテーブルを押下します。
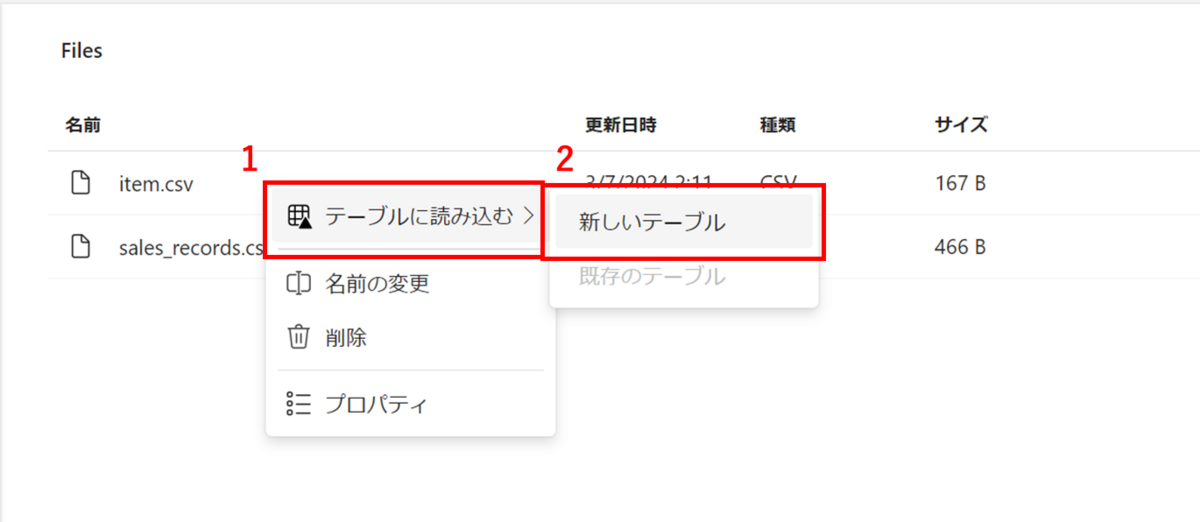
新しいテーブル名、テーブル設定を指定し、読み込みを押下します。

Tables内にテーブルデータが作成されたことが確認できます。
これでデータのアップロードが完了しました。

データフローの作成
取り込んだテーブルデータをもとにデータフローを作成しデータの整形を行います。
データフローの作成は以下の手順で行います。
- データの準備
- データの整形
- 公開先の指定
データの準備
1,ワークスペースの1,+新規から2,データフロー(Gen2)を選択します。

左上のDataflow1を選択し、任意の名前を入力します。

1,データの取得から2,詳細を選択します。

レイクハウスで検索し、新しいソースとしてレイクハウスを選択します。

認証の種類を選択し、次へを押下します。

1,アップロードしたファイルを選択し、2,作成を押下します。

以上でデータの準備が完了しました。
データの整形
ここからは、可視化しやすいようにデータの整形を行っていきます。
今回は商品別売上高についてレポート作成します。そのため2つのテーブルデータから商品名、各商品の売上合計値、売上日を抽出し、新しいテーブルとして作成します。
データフローの編集画面から1,結合、2,クエリのマージ、3,新規としてクエリをマージを選択します。

1,左テーブルにsales_records、結合キーとしてitem_idを指定し、2,右テーブルにitem、結合キーにidを指定します。
3,結合の種類に左外部を選択し、4,OKを押下します。

1,itemの展開ボタンを押下し、2,OKを押下し、結合したitemテーブルの列を展開します。

nameおよびpurchsed_at列でグループ化および、priceの合計値を算出した列を抽出します。
1,変換から2,グループ化を選択します。

1,詳細設計を選択し、2,グループ化にはpurchased_atとnameを指定します。
3,新しい列名にsum、操作に合計、列にpriceをそれぞれ指定し、4,OKを押下します。

設定を終えると以下のようにデータの整形ができました。

このデータをレイクハウス内に格納します。
公開先の指定
整形したデータを指定します。
1,右下のデータの同期先の+をから、2,レイクハウスを選択します。

データの取得元と同じレイクハウスに格納するため、そのまま次へを押下します。

1,任意のテーブル名を入力し、2,格納先にレイクハウス内のファイルを指定し、3,次へを押下します。

設定の保存を押下します。

公開を押下し、データフローを反映させます。

レイクハウスに移動し、Tablesを見てみると作成したREPORT_TBが確認できます。

以上でデータフローの作成が完了しました。
データのグラフ化
データフローで作成したテーブルをもとにレポートを作成します。
1,Lakehouseから2,SQL分析エンドポイントを選択し、切り替えを行います。

1,REPORT_TBのその他のオプションを選択し、2,既定のデータセットに追加を押下します。これによりPowerBIを使用する時の参照テーブルとして設定されます。

1,報告から2,新しいレポートを選択します。

レポートの編集画面に自動で切り替わります。

1,視覚化に集合縦棒グラフを選択します。
2,REPORT_TBタブを開きnameをX軸に、purchased_atを凡例に、sumをY軸にそれぞれドラッグします。

1,ビジュアルの書式設定を選択し、2,X軸タブ内のタイトルタブを開き、タイトルテキストに「商品名」と入力します。

続いて1,Y軸タブ内の値タブを開き表示単位を「なし」にします。
2,タイトルタブを開きタイトルテキストを「売上合計値(円)」を入力します。
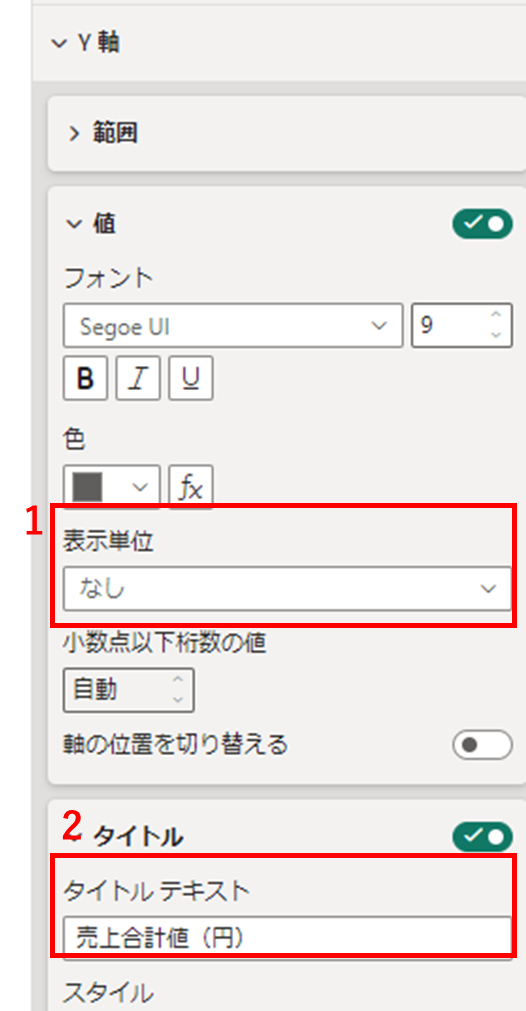
1,全般に切り替え、2,タイトルタブを開きテキストに「商品売上高」と入力します。

以下のグラフが作成され、データを可視化することができました。
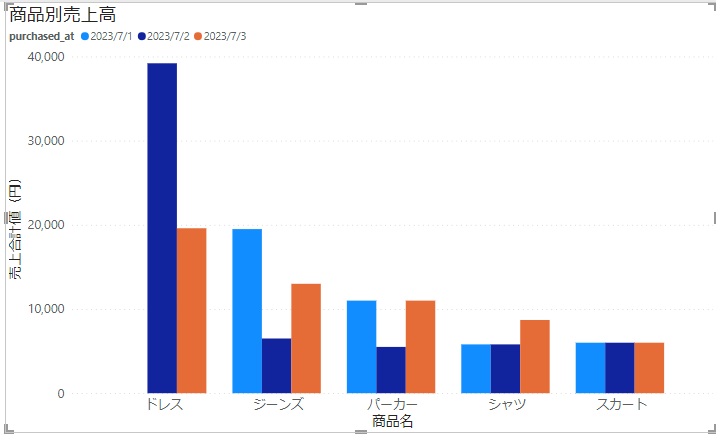
ここからさらにマトリクスを作成します。
1,視覚化にマトリクスを選択します。
2,nameを列に、purchased_atを行に、sumを値にそれぞれドラッグします。

上記の設定をすることにより、商品別の比較および数値を可視化することができました。

ここから作成したレポートを保存します。
1,ファイルを押下し、2,保存を選択します。

任意のレポートの名前を入力し、保存を押下します。

ワークスペースを開き、作成したレポートがあることが確認できます。

定期実行の設定
パイプラインを作成し、スケジュールトリガーを利用した定期実行の設定を行います。
今回は10分ごとに作成したデータフローが実行される機能を実装します。
まずワークスペースの1,+新規から2,データパイプラインを選択します。
任意の名前を入力し、作成します。

以下のようなパイプラインの編集画面に自動で切り替わります。
ここから作成したデータフローを指定します。
データフローを選択します。

設定タブを開き、データフローに作成したデータフロー(hfukuhama-Dataflow)を指定します。

ここからスケジュール実行の設定を行います。今回は10分ごとにパイプライン実行を行うよう指定します。
1,パイプラインを選択し、
2,スケジュールされた実行をオンにし、以下のように値を指定したら適用を押下します。
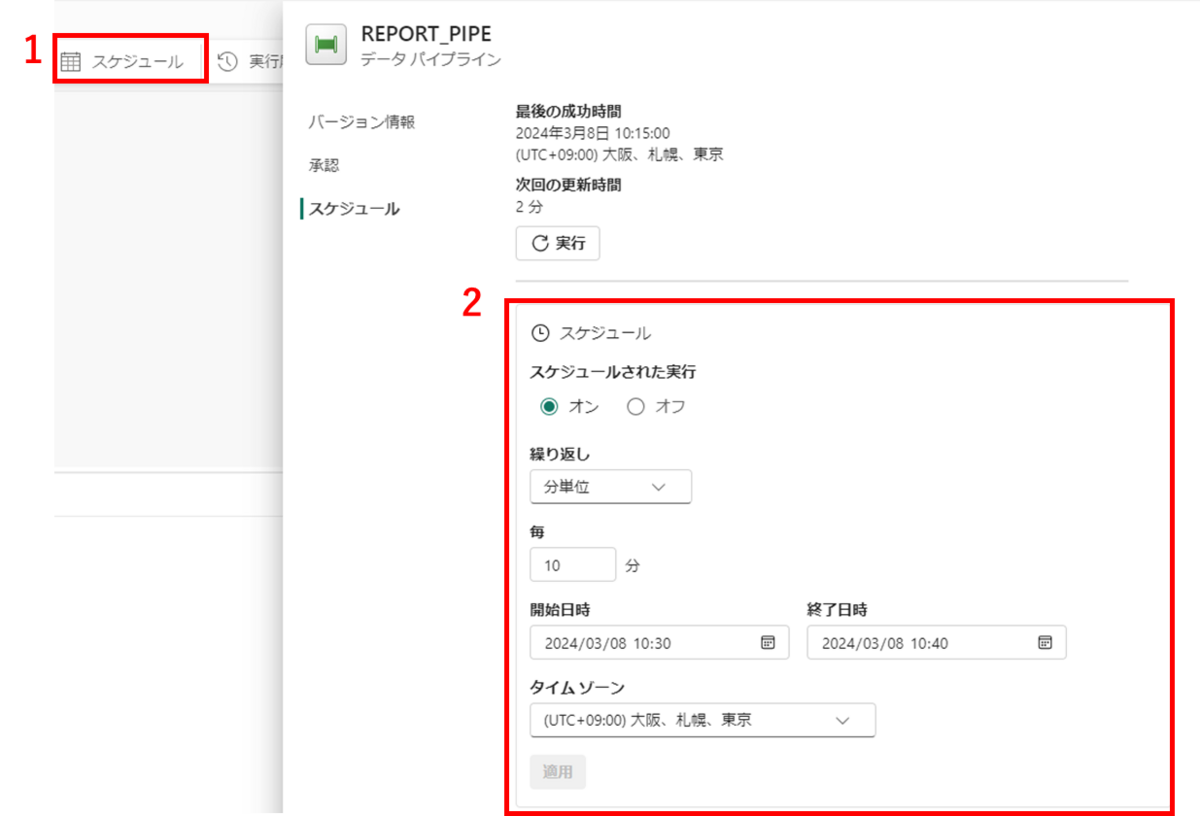
左上の保存を押下し、パイプライン編集画面を閉じます。

1度目のパイプライン実行の後にsales_recordsテーブルに以下のデータを追記し、挙動を確認します。
| ID | ITEM_ID | PURCHASED_AT |
| 31 | 1 | 2023-07-04 |
| 32 | 2 | 2023-07-04 |
| 33 | 3 | 2023-07-04 |
| 34 | 4 | 2023-07-04 |
| 35 | 5 | 2023-07-04 |
| 36 | 2 | 2023-07-04 |
| 37 | 3 | 2023-07-04 |
| 38 | 2 | 2023-07-04 |
| 39 | 4 | 2023-07-04 |
| 40 | 5 | 2023-07-04 |
1度目の実行確認

データを追記

2度目の実行を確認します。

確認を終えたら、レポート(REPORT_TEST)を開き、内容が反映されているか確認します。
更新を押下します。

2024/7/4のデータが反映され定期実行が問題なく行われていることを確認できました。
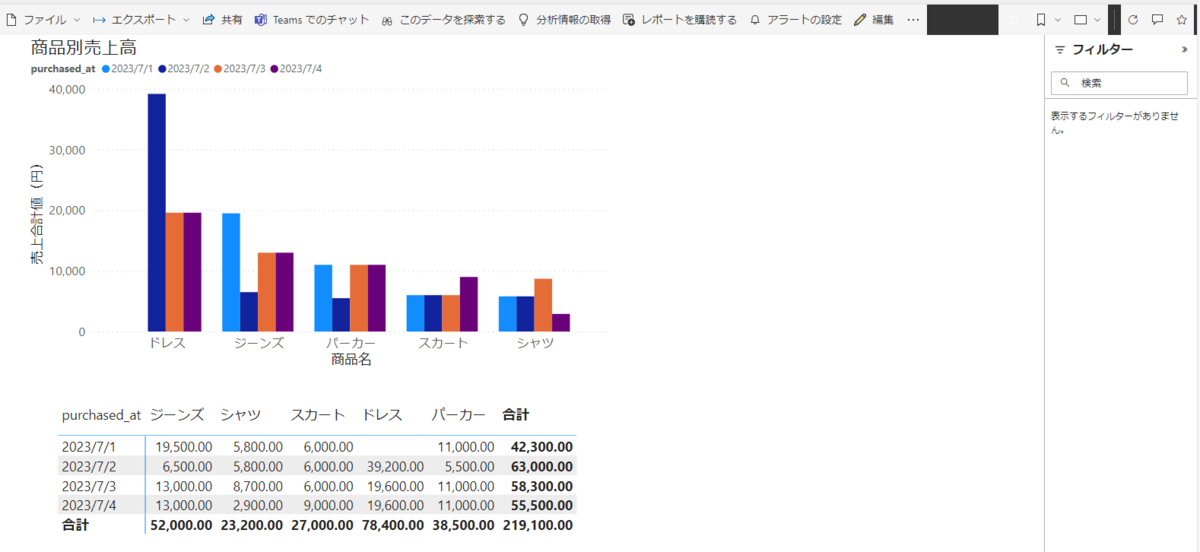
以上でスケジュールトリガーの実行が完了しました。
おわりに
Microsoft Fabricを使用したデータの取り込みからデータの可視化までの一連の手順についてご紹介しました。
ここではデータの取得先としてローカル上のファイルをアップロードしましたが、Microsoft Fabricには145以上のコネクタがサポートされているため、多くのサービスとのデータ連携も可能です。また、データの用途についても、分析のための可視化だけでなく、機械学習等にも活用できます。
本記事がMicrosoft Fabricの実装の参考になれば幸いです。
