
Csol本部所属の福濵です。2023年に入社しSnowflakeについて基礎から勉強しています。
本記事ではSnowflakeのマイクロパーティションの仕組みについてご紹介します。
マイクロパーティションとは
概要
マイクロパーティションとはSnowflakeアーキテクチャのデータベースストレージ層に位置するものです。
格納するデータを小規模なファイル群として分割および圧縮したもののことをいいます。
以下がマイクロパーティションの構造です。
- 各マイクロパーティションは常に圧縮されて格納される
- 各マイクロパーティションの容量は圧縮状態で16MB(圧縮前は50~500MB)
- 従来の静的パーティションとは異なりテーブル作成時に自動で作成される
- 容量に合わせてテーブルの行でデータ分割する
- 作成したマイクロパーティション内では列ごとにデータがまとめられる(列指向ストレージ)
- イミュータブル(不変)
- 列ごとに行数、列内の最大値/最小値等を集計しメタデータとして管理する
また特長として以下が挙げられます。
- ファイルの圧縮により格納に必要な容量が少ない
- 事前定義が不要
- 列指向ストレージにより個々の列に対してスキャンが行われるため、クエリパフォーマンスが向上する
- メタデータを使用することで、正確なプルーニングが可能
このような構造、特長を踏まえ、マイクロパーティション作成時のデータの流れを見てみます。
参照:マイクロパーティションとデータクラスタリング | Snowflake Documentation
データの流れ
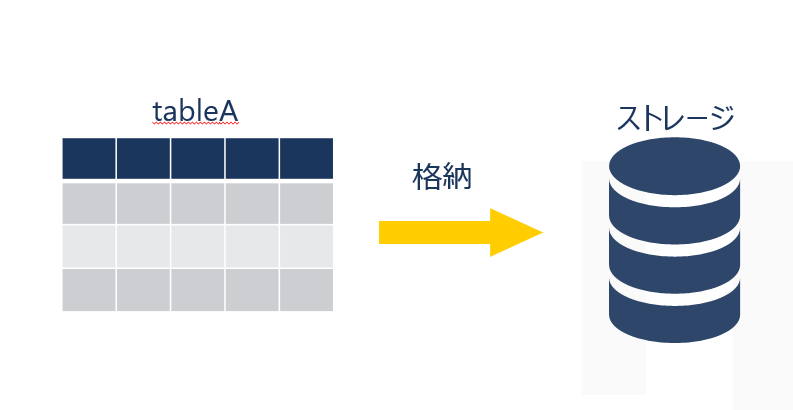
まずは従来の格納方法についてです。
従来の格納方法では、以下のようにテーブルデータはそのままストレージに格納されました。
しかし、マイクロパーティションの場合は、以下のように一定の容量でデータを分割し圧縮してから格納します。
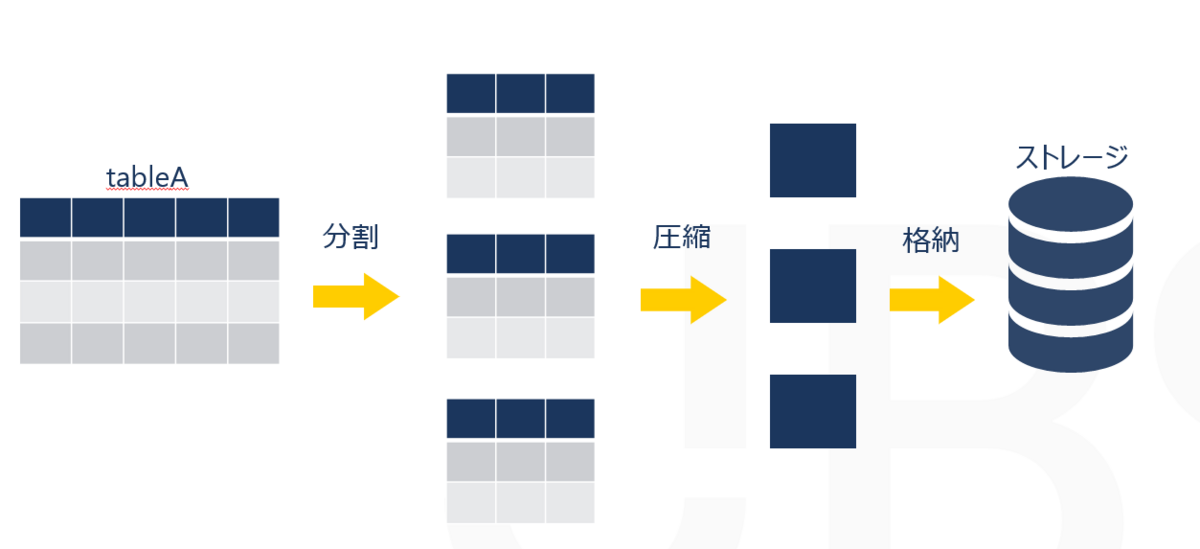
これにより少ないストレージ容量で格納することができます。
また、データ分割については行で分割し、列でまとめます。
例えば、tableAのデータのマイクロパーティションを作成する場合、まず一定容量に行で分割を行います。今回の例では2つのデータに分割されました。
次に作成されたマイクロパーティション内でデータを列ごとにまとめ、この際に列ごとにメタデータも作成します。そして作成されたマイクロパーティションは圧縮され格納されます。
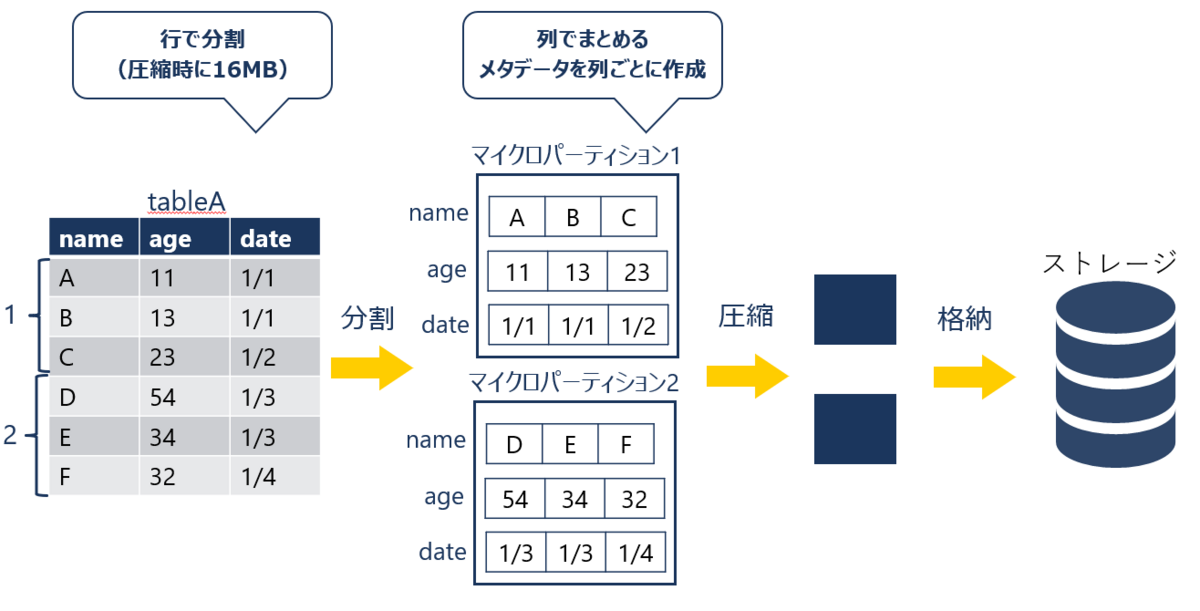
このようなマイクロパーティションの構造はプルーニングに役立ちます。
プルーニング
プルーニングとは、マイクロパーティションのメタデータを参照し、不要と確定しているマイクロパーティションを読み飛ばすことで処理対象データを減らす機能のことです。
プルーニング機能によりクエリパフォーマンス向上を図ることができます。
プルーニング機能を利用したデータ参照の例を1つ挙げます。
以下のクエリでは「tableAのdate列内の値が1/1の行のnameとdateの値を抽出する」という指示を出しています。
SELECT name, date FROM tableA WHERE date = '1/1';
このクエリが実行されたときの動きを見てみます。
まずマイクロパーティション作成時に一緒に作成したメタデータを参照しdate列内に1/1の値を含むデータを探します。これによりマイクロパーティション1にのみ対象データがあることを発見します。
続いて、マイクロパーティション1の指定した列を参照します。この際も列指向ストレージで保持されているためage列は参照せず、name列とdate列の2つのみ参照します。
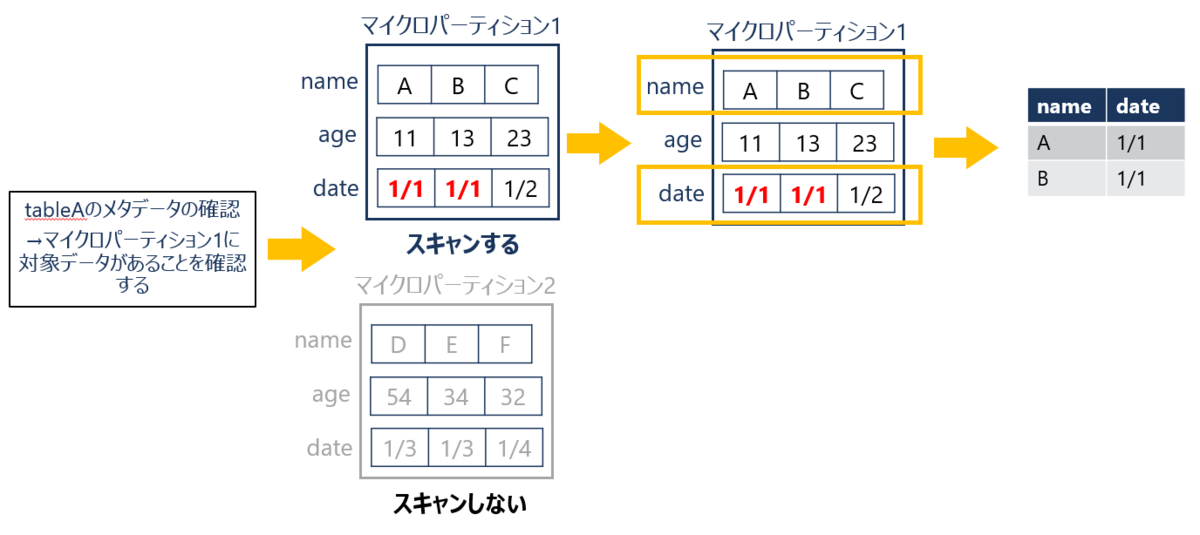
Snowflakeでは以上のようにプルーニング機能を利用してデータを参照します。
これにより、データ参照時には不要なマイクロパーティションおよび列のスキャンをしないため、クエリの処理効率を上げることが可能になります。
イミュータブル(不変)
ここでは、マイクロパーティションのイミュータブルという特長について説明します。
イミュータブルとは不変という意味で、一度作成されたデータが変更されない性質を持つことをいいます。
マイクロパーティションのイミュータブルでは、既存のマイクロパーティションの変更の際は、更新をせずに新しいマイクロパーティションを作成するという性質となります。
以下の例はtableAを更新したときのマイクロパーティションの挙動を表したものです。
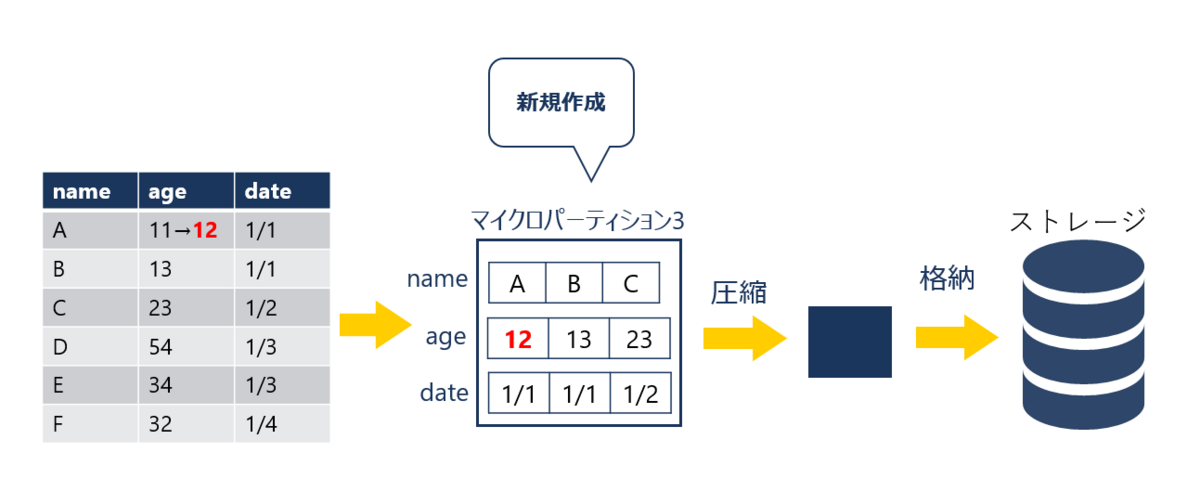
age列のデータを1箇所更新した場合、マイクロパーティション1を書き換えるのではなく、新しくマイクロパーティション3が作成されます。
この場合のストレージ内がどのようになっているか見てみます。
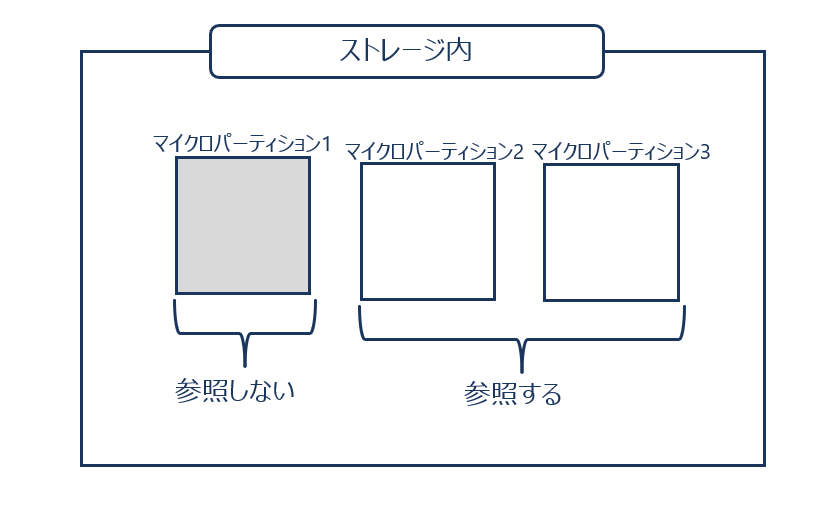
この時、ストレージ内には3つのパーティションが存在し、tableAの更新により古いデータを保持しているマイクロパーティション1と新しいデータを保持するマイクロパーティション3が同居しています。
Snowflakeではマイクロパーティションが新しく作成されると、データ参照時に新しいマイクロパーティションを参照先にするように自動的に切り替えを行います。
例えば、以下のようなtableAをすべて参照するクエリを実行したとします。
SELECT * FROM tableA;
この時、今まではマイクロパーティション1,2を参照していましたが、更新後はマイクロパーティション2,3を参照するように切り替わり、マイクロパーティション1は参照されなくなります。
参照されなくなった古いマイクロパーティションは、すぐには削除されず一定期間保持され、SnowflakeのTimeTravel機能やFail-Safe機能に使用されます。
TimeTravel機能
定義した期間内の任意の時点の履歴データ(変更、削除されたデータ)にアクセスする機能です。
履歴データを保持できる期間はデフォルトでは1日(24時間)です。定義できる保持期間はEditionによって異なります。
Standard Edithionは保持期間を0日または1日に設定できます。
Enterprise Edition以上は保持期間を0日から90日の任意の値に設定できます。
参照:Time Travelの理解と使用 | Snowflake Documentation
Fail-Safe機能
TimeTravelとは別に問題発生時等に履歴データを確実に保護する機能です。
TimeTravel機能の保持期間が終了すると自動でFail-Safe期間に移行します。この期間は7日間です。TimeTravel機能とは異なり、障害発生時のデータ復旧を意図しているため、データへのアクセスはできません。
またデータ復旧には完了までに数時間から数日かかることがあります。
参照:Fail-safeの理解と表示 | Snowflake Documentation
注意点
Snowflakeではデータが更新されるたびに新しいマイクロパーティションが作成されます。しかしこれは更新頻度が高いほどその分ストレージコストが増加することを意味します。
そのため履歴データが不要なデータについてはTimeTravel機能を0日に設定したり、Snowsightから使用コストを確認したり等を行い、コスト管理を行うことが必要です。
おわりに
本記事ではSnowflakeのマイクロパーティションの仕組みについてご紹介しました。
マイクロパーティションはSnowflakeの大きな特徴の1つといえます。理解を深めることで、クラスタリングやコスト管理等の活用にも役立ちます。
本記事がSnowflake学習の参考になれば幸いです。
