
現在、ChatGPTをはじめとする大規模言語モデル(LLM: Large Language Model)は、インターネット上に公開されている膨大な情報を基に学習されています。 しかし、企業が扱う特定分野(ドメイン)に特化した情報や機密情報は、一般には公開されていないことが多く、これらはLLMの学習データには含まれていません。
そのため、AIの企業導入ニーズが高まる一方で、企業特有の業務や専門的なタスクにおいて、汎用のLLMでは十分な精度が得られないという課題が存在します。
本記事では、こうした課題に対する解決策として、ドメイン特化型モデルのアップデート手法のひとつである LoRA(Low-Rank Adaptation) に注目し、その仕組み、実装手順、学習コスト、適用シーンについてわかりやすくまとめます。
- 企業でのLLM導入における課題とモデル最適化手法について
- ファインチューニングの手法について
- Azure AI Foundryの概要
- Azure AI FoundryにおけるLoRAファインチューニングの実施
- ファインチューニングに関わるコストと運用上の注意点
- まとめと今後の見通し
企業でのLLM導入における課題とモデル最適化手法について
モデル最適化に向けた4つの手法
企業のタスクにLLMを適応させるためには、モデルにドメイン特化の情報や企業独自の要件を反映させる必要があります。そのための主なアプローチは、以下の4つに大別されます。
継続事前学習(Continued Pre-training)
既存のLLMを基盤とし、企業や特定分野のコーパス(文書データ)を追加で学習させる手法です。この方法により、モデルは新たなドメイン知識を習得し、基本的な言語理解能力を維持しながら、特化領域のタスクにも対応できるようになります。
| 項目 | 内容 |
|---|---|
| メリット |
|
| 注意点 |
|
| 使い分けのポイント |
|
| ツール・ライブラリ |
|
ファインチューニング(Fine-tuning)
LLMに対して、企業特有のタスクや目的に沿ったデータセットを用いて追加学習を行う方法です。分類・要約・FAQ応答や、特定のスタイルに沿ったアウトプット形式や用途にモデルを最適化できます。
| 項目 | 内容 |
|---|---|
| メリット |
|
| 注意点 |
|
| 使い分けのポイント |
|
| ツール・ライブラリ |
|
RAG (Retrieval Augmented Generation)
RAG は、生成型言語モデルに対し、外部の知識ソース(ドキュメント、データベース、ウェブ情報など)から動的に情報を取得し、その情報を統合して回答を生成する手法です。これにより、モデル内部に組み込まれていない最新情報や詳細な専門知識を補完することが可能となります。
| 項目 | 内容 |
|---|---|
| メリット |
|
| 注意点 |
|
| 使い分けのポイント |
|
| ツール・ライブラリ |
|
プロンプトエンジニアリング(Prompt Engineering)
モデル本体は更新せず、入力指示文(プロンプト)を工夫することで、出力の精度や形式を調整する手法です。最も手軽かつ迅速に導入可能で、PoCや軽微なタスク改善に適しています。
| 項目 | 内容 |
|---|---|
| メリット |
|
| 注意点 |
|
| 使い分けのポイント |
|
本稿では、特に GPT-4o モデルをベースとした特定タスク対応に向けたファインチューニングについて、Azure AI Foundry を活用した実装手順と、その際に発生するコストに焦点を当てて解説します。
ファインチューニングの手法について
Azure AI Foundryで提供されているファインチューニングは、2025年3月現在、低コストファインチューニング として知られる LoRAという手法を採用しています。LoRAは、学習時に低ランク行列を導入し、モデル全体ではなく一部のパラメータのみを効率的に学習することで、学習コスト(計算資源や時間)を大幅に削減できる手法です。

メリットとして、学習にかかるコストや時間を大幅に削減できる一方で、モデルによっては通常のファインチューニングと比べて学習が最適化されにくく、精度が若干低下する場合があります。また、Anthropic Claude 3 や Google Gemini など、一部のLLMは LoRA に対応しておらず、適用できないケースもあります。
Azure AI Foundryの概要
Azure AI Foundryとは
Azure AI Foundry は、大規模言語モデル(LLM)の選定からカスタマイズ、セキュリティ確保、運用管理までを一元的に提供するプラットフォームです。特に、モデルの導入から運用までを包括的に管理できる点が特徴であり、Azure OpenAI Service と比較すると、より柔軟に モデルのカスタマイズ(例:ファインチューニングや継続学習) が可能であり、セキュリティや運用体制も一括して整備できる点に強みがあります。
| 評価軸 | メリット | デメリット |
|---|---|---|
| モデル選定 | 多様なモデルから選べる | 最適なモデル選定に時間がかかる |
| データ管理 | セキュアな環境で実施可能 | 他クラウドやオンプレとの連携が複雑 |
| スケーラビリティ | GPUリソースを柔軟にスケーリング可能 | コストが高くなりがち |
| 開発効率 | MLOpsと統合、運用が容易 | 設定や運用が標準Azure AIより複雑 |
前提条件
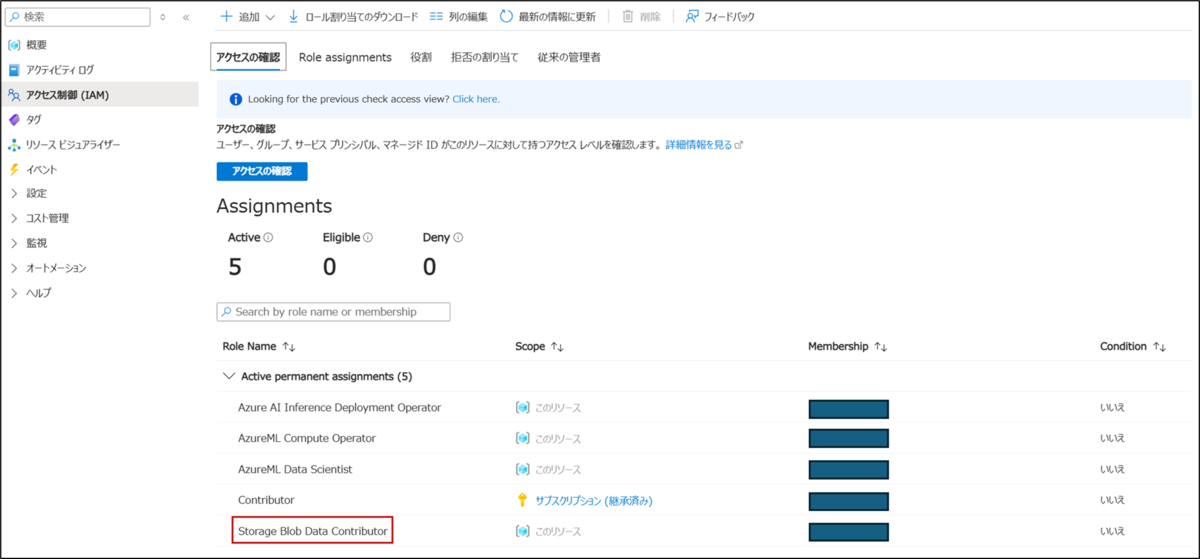
Azure AI Foundry におけるファインチューニングでは、学習データの保存および読み取りに Azure Blob Storage が使用されます。そのため、ファインチューニングを実行するリソースに対して、「Storage Blob Data Contributor」ロールを付与する必要があります。
付与された権限は、Azure ポータルの 「IAM (アクセス制御)」 画面から確認できます。
モデルの利用手順
Azure AI Foundry上でgpt-4oモデルをデプロイし、デプロイしたモデルを使用してみます。
-
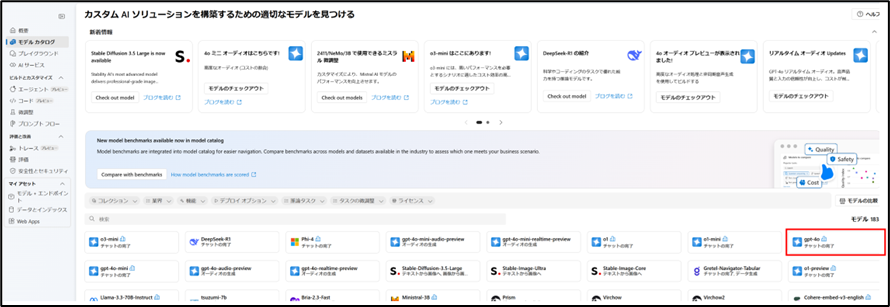
左ペインの「モデル カタログ」からgpt-4oを選択します。
-
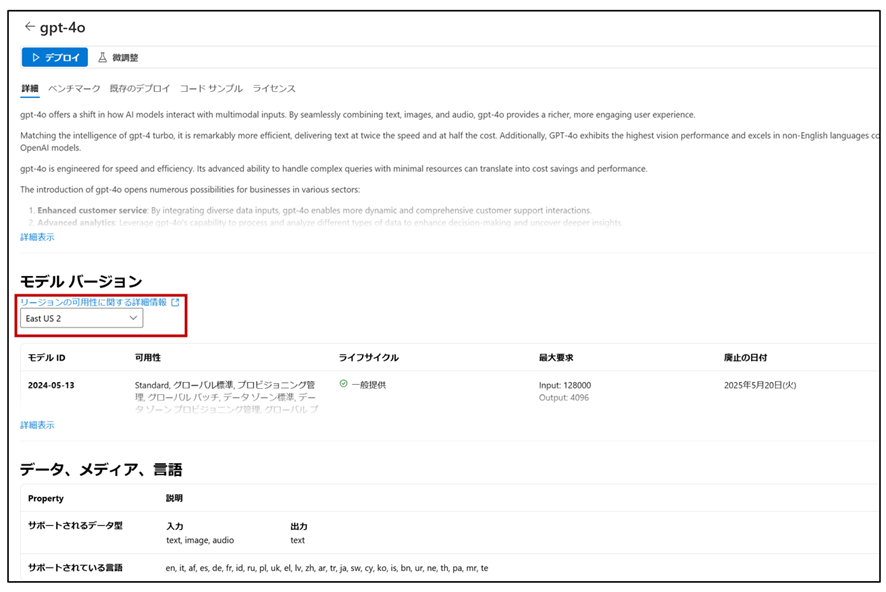
選択したモデルをデプロイします。この際、後に実施するファインチューニングを見越して、使用するリージョンとして「East US 2」を選択しています。リージョンによってはファインチューニングが実行できない場合があるため、注意が必要です。
-
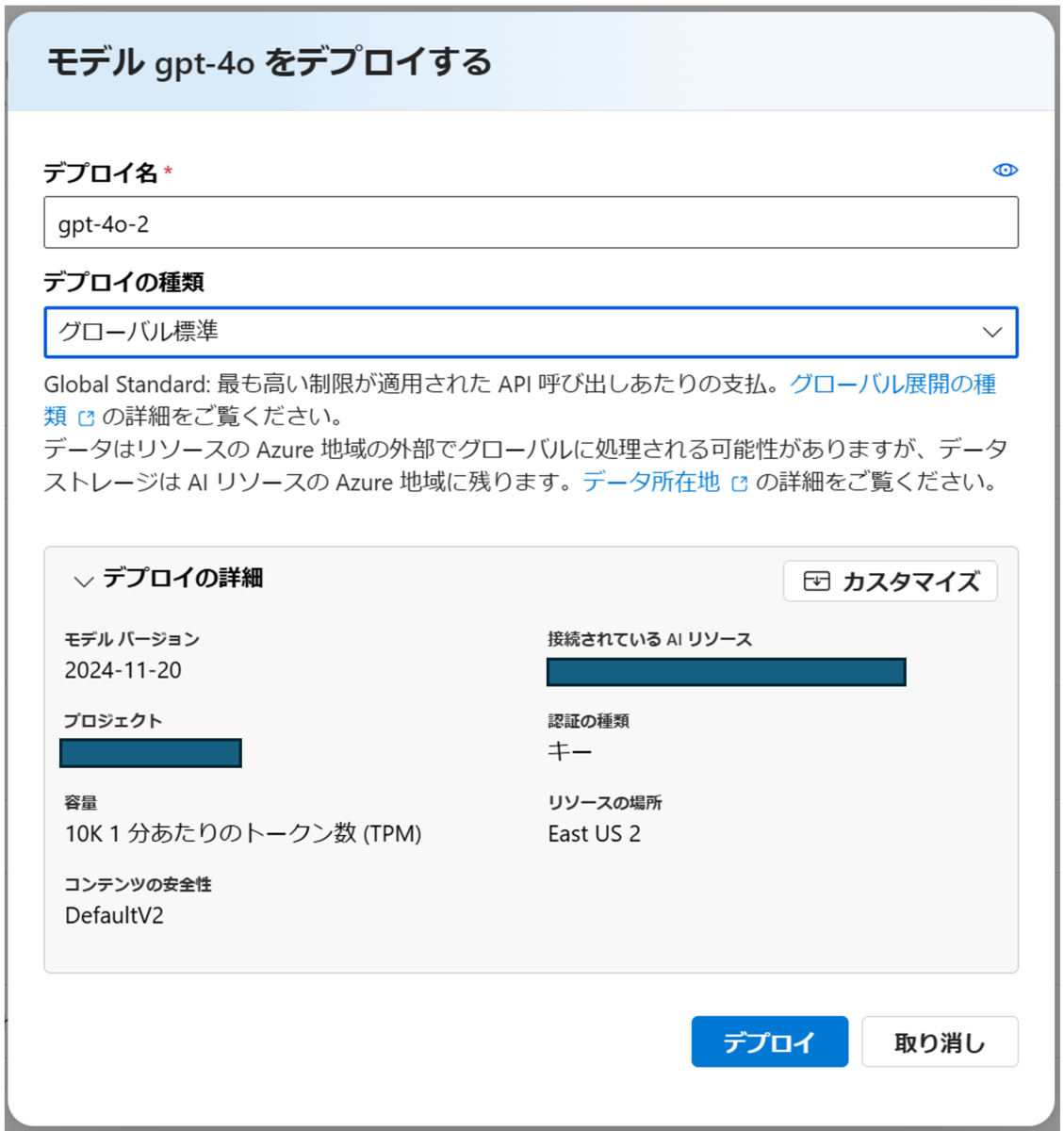
上側にある「デプロイ」をクリックすると、モデルデプロイの画面がポップアップされます。
-
デプロイしたモデルを利用し、チャット機能を通じて、日本ビジネスシステムズ株式会社(略称: JBS)について略称、正式名称それぞれで質問してみます。
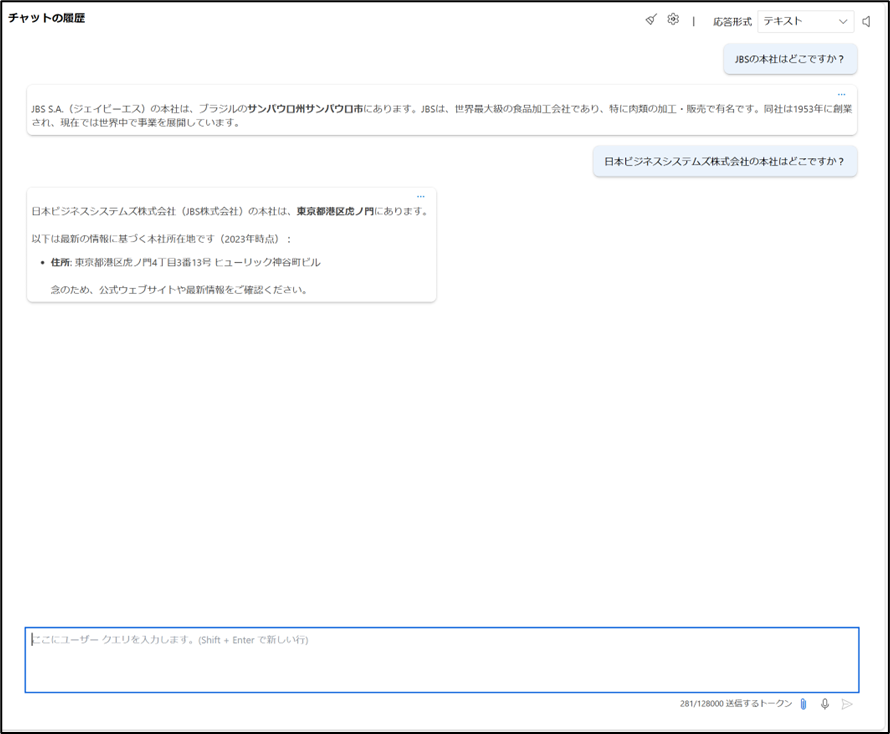 回答は得られたものの、出力内容には会社情報の誤りが含まれており、いわゆるハルシネーションが発生しています。
回答は得られたものの、出力内容には会社情報の誤りが含まれており、いわゆるハルシネーションが発生しています。
Azure AI FoundryにおけるLoRAファインチューニングの実施
学習データの用意
学習データは .jsonl 形式(拡張子:.jsonl)で作成します。各行には、プロンプト情報(システムメッセージなど)、ユーザーからの質問、およびそれに対する回答を組み合わせて記述します。具体的な記述方法については下記のフォーマット例をご参照ください。今回は、ハルシネーションが確認された 日本ビジネスシステムズ株式会社(JBS) に関する正確な情報を反映した学習データを用意します。
なお、学習データは最低でも10件以上必要です。10件未満の場合、アップロード時にエラーが発生するためご注意ください。
jbs_address_data.jsonl
(エンコード:UTF-8 BOM無し、改行:LFのみ)
{"messages": [{"role": "system", "content": "あなたは日本ビジネスシステムズ株式会社(略称:JBS)のアシスタントです。日本ビジネスシステムズのことに関して丁寧に答えます。"}, {"role": "user", "content": "JBSの本社はどこにありますか?"}, {"role": "assistant", "content": "東京都港区虎ノ門の虎ノ門ヒルズにあります"}]} {"messages": [{"role": "system", "content": "あなたは日本ビジネスシステムズ株式会社(略称:JBS)のアシスタントです。日本ビジネスシステムズのことに関して丁寧に答えます。"}, {"role": "user", "content": "JBSの住所を教えてください。"}, {"role": "assistant", "content": "〒105-0001 東京都港区虎ノ門2-6-1 虎ノ門ヒルズ ステーションタワー20階です"}]} {"messages": [{"role": "system", "content": "あなたは日本ビジネスシステムズ株式会社(略称:JBS)のアシスタントです。日本ビジネスシステムズのことに関して丁寧に答えます。"}, {"role": "user", "content": "JBSの住所は?"}, {"role": "assistant", "content": "〒105-0001 東京都港区虎ノ門2-6-1 虎ノ門ヒルズ ステーションタワー20階です"}]} ### 以下略 ###
学習データのアップロード
-
左ペインより、「データとインデックス」から「新しいデータ」へ進み、「ファイルまたはフォルダーをアップロードする」ボックスをクリックして用意したデータを選択します。
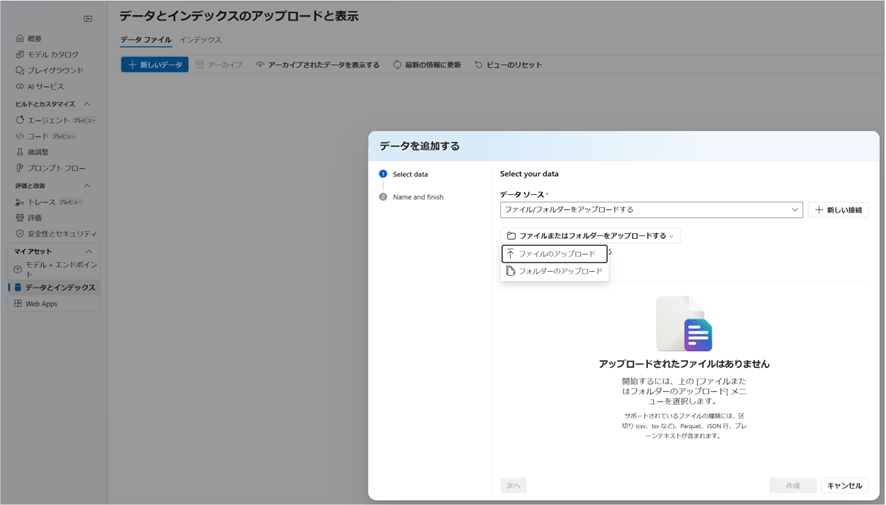
-
データ名を入力後、「作成」ボタンをクリックします。
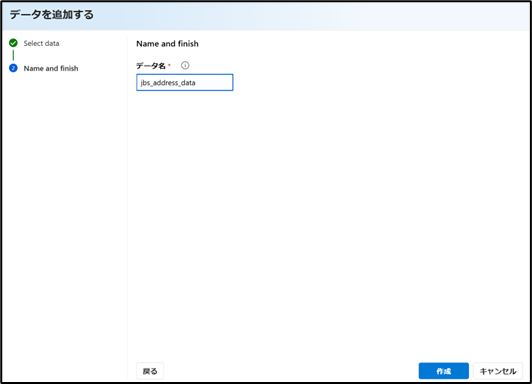
-
用意したデータのアップロードがうまく反映されれば成功です。
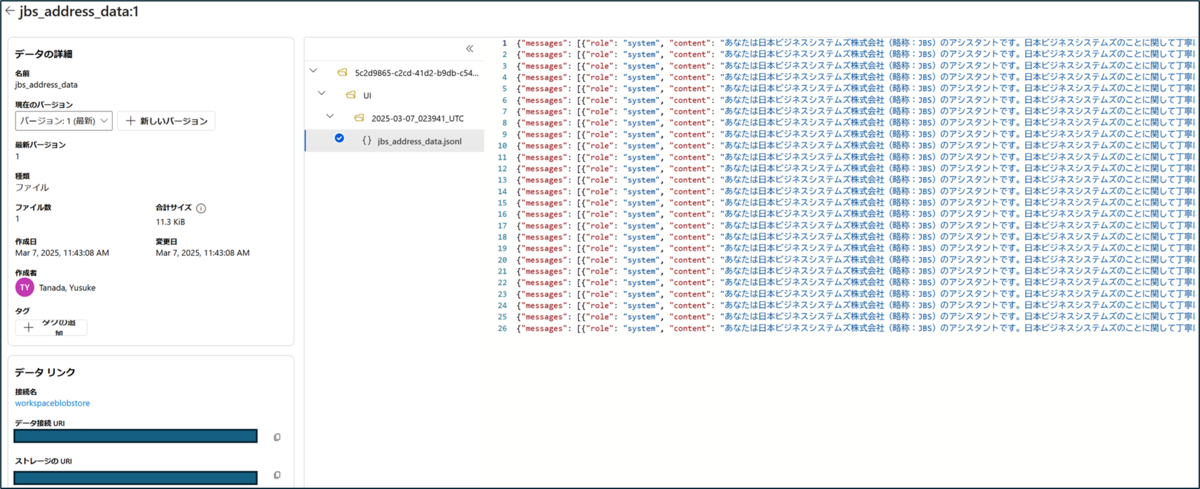
ファインチューニングの実施
-
左ペインより、「微調整」から「生成AIの微調整」>「モデルの微調整」と進みます。今回はファインチューニング対象のモデルとして gpt-4oを選択します。
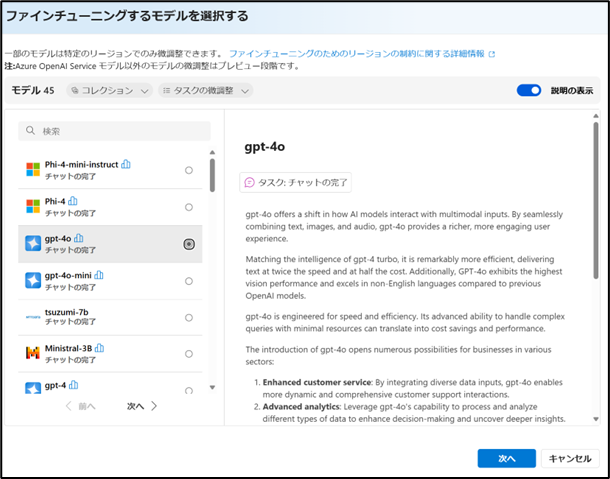
-
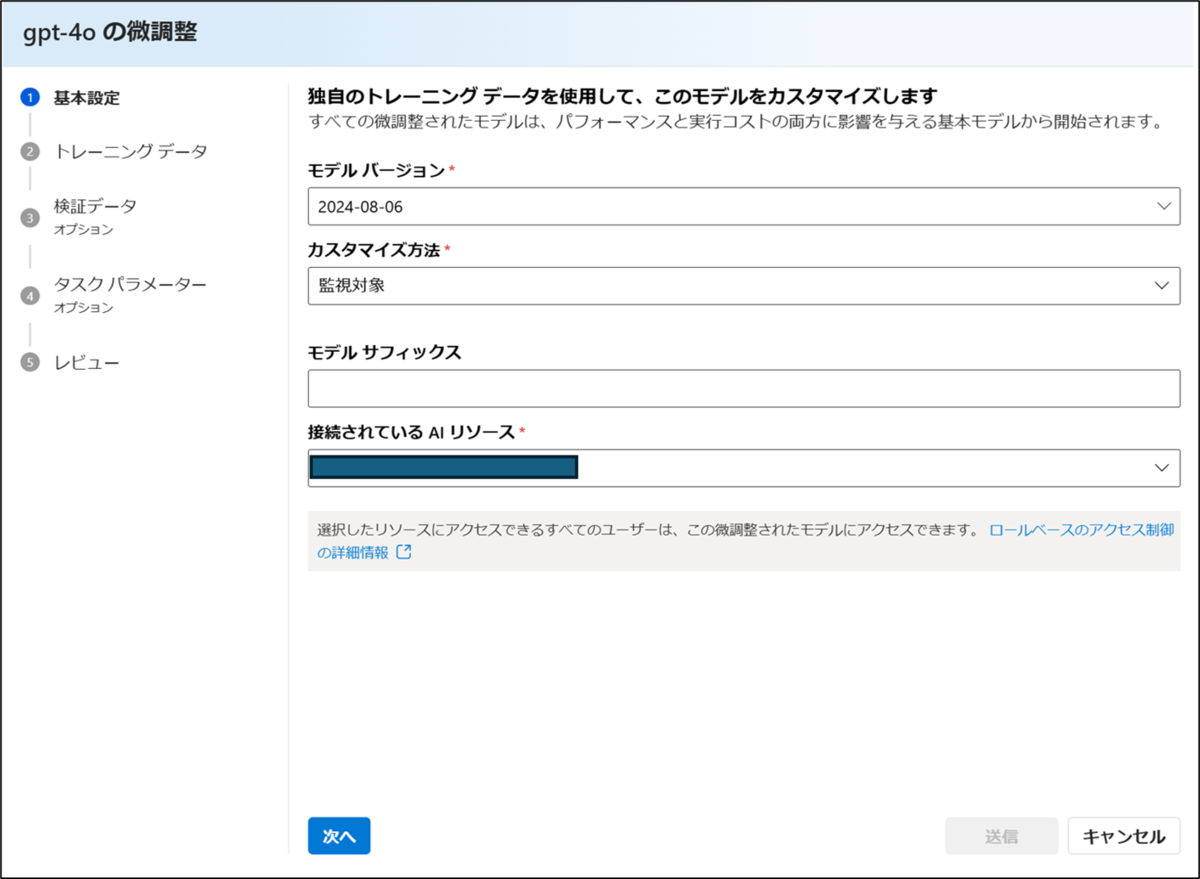
対象のモデルバージョンを確認後、「次へ」をクリックします。
-
4-2. 学習データのアップロード
でアップロードした学習用データを選択し、「次へ」をクリックします。
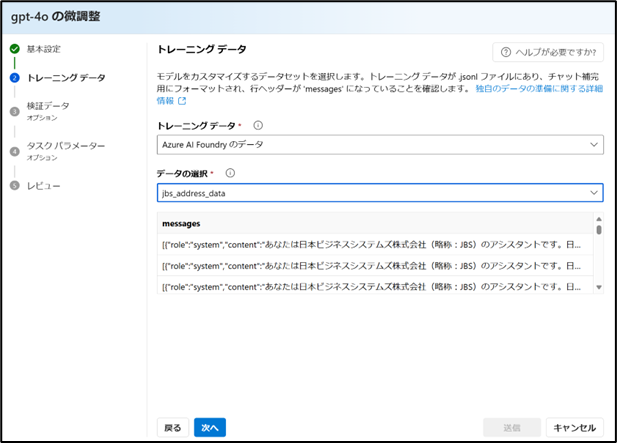
-
作成したモデルの検証が必要な場合は、検証用のデータを選択し、「次へ」をクリックします。
※今回は指定しません。
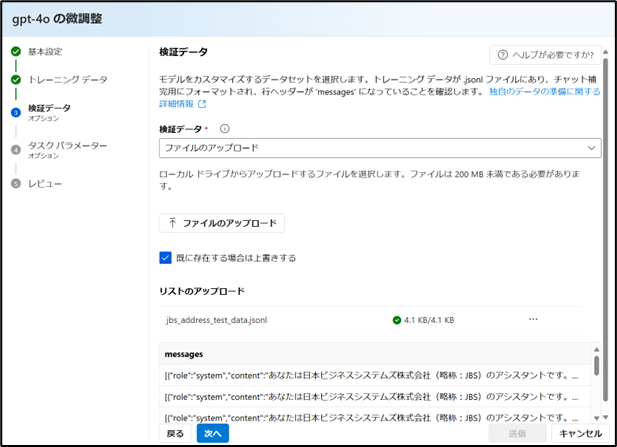
-
タスクパラメーターでは、ファインチューニングの詳細な設定を行うことができます。
※今回はすべてデフォルト設定のまま進めます。
以下は各パラメータの概要です。
項目 意味 調整のポイント 初期値 Batch Size 1回で学習するデータ数 メモリに余裕があれば大きく、リソースが限られる場合は小さめに設定 1.0 Learning rate multiplier 学習率の倍率 学習したモデルの出力に一貫性が見られない場合は、0.5 や 0.1 など小さめに設定し、 学習が十分に進まず出力の変化が乏しい場合は 1.0 以上に調整 1.0 Number of epochs 全データ学習の繰り返し回数 小さすぎると学習不足、多すぎると過学習に注意 1.0 Seed 乱数の初期値 実験再現性が必要な場合は固定値に設定 - -
最後に設定内容を確認後、「送信」をクリックします。
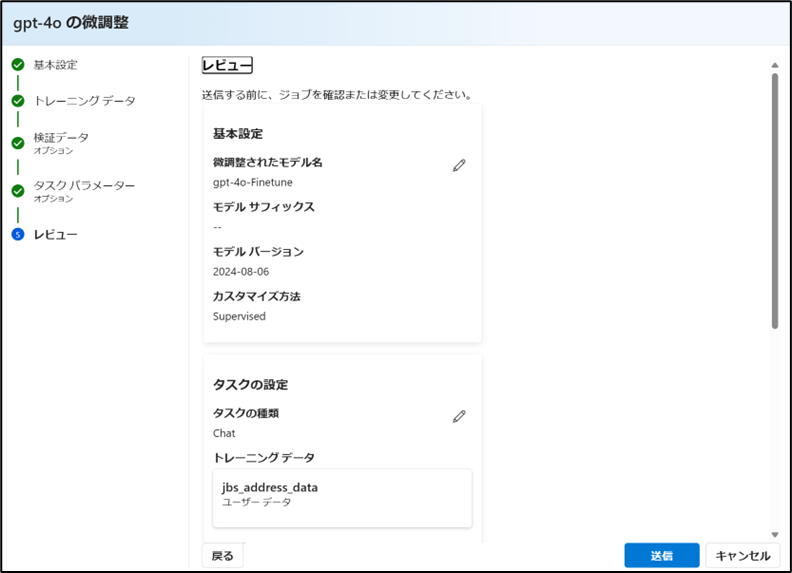
-
設定内容がAzure AI Foundryの作業キューに入り、一定時間経過後、ファインチューニングが実施されます。
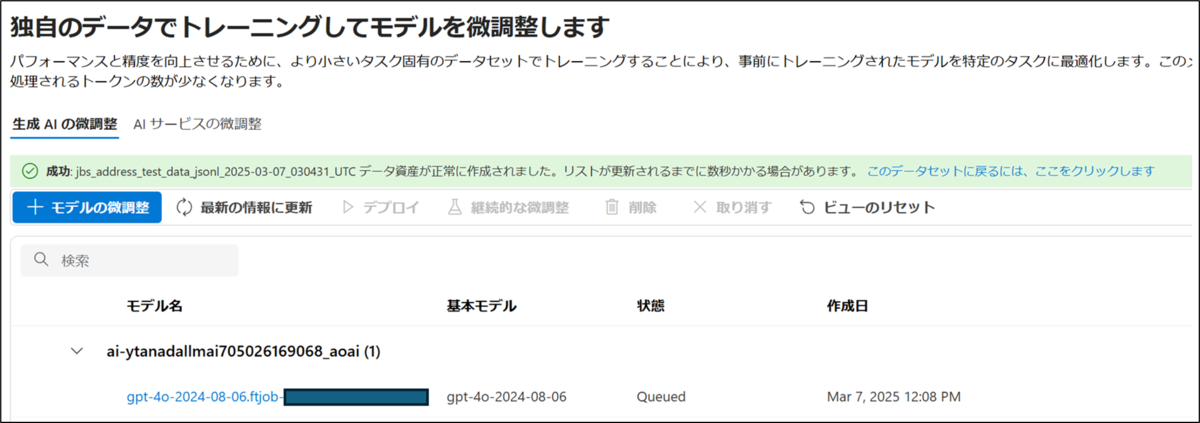
ファインチューニングの完了前後において、状態のステータスが「Queued」>「Running」>「Completed」へ遷移します。
ファインチューニングしたモデルのデプロイと挙動の確認
ファインチューニングが完了すると、ファインチューニング済みのモデルがリストに表示されます。対象のモデルを選択してデプロイを行います。
なお、モデルをデプロイした時点から ホスティングによるランニングコストが発生するため、注意が必要です。
- 対象モデルを選択
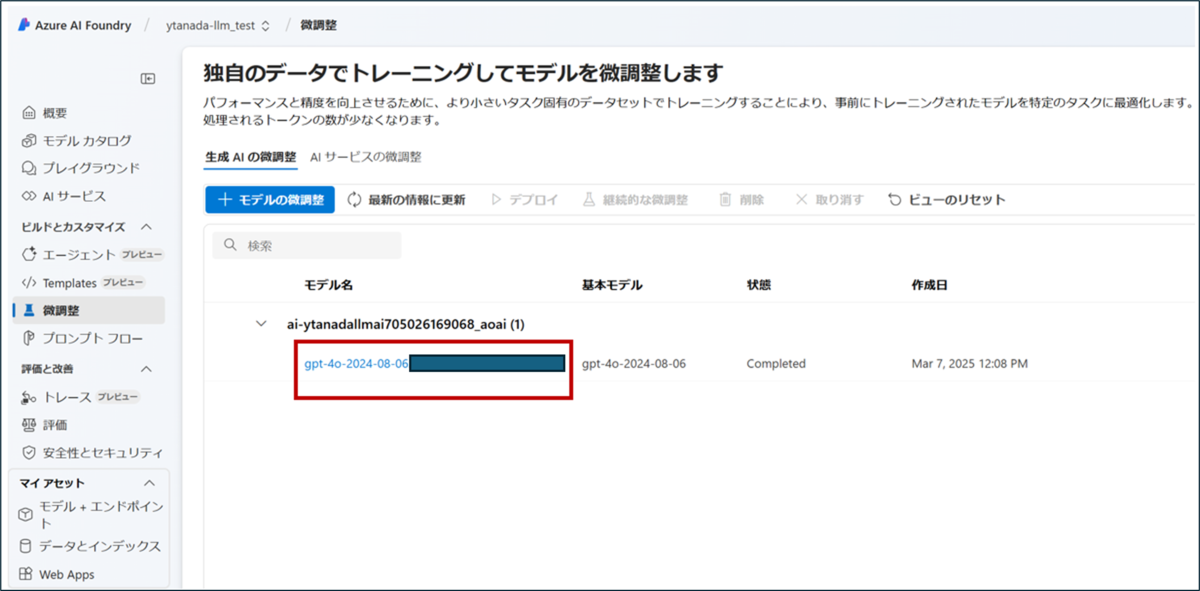
- 画面左上の「デプロイ」をクリック
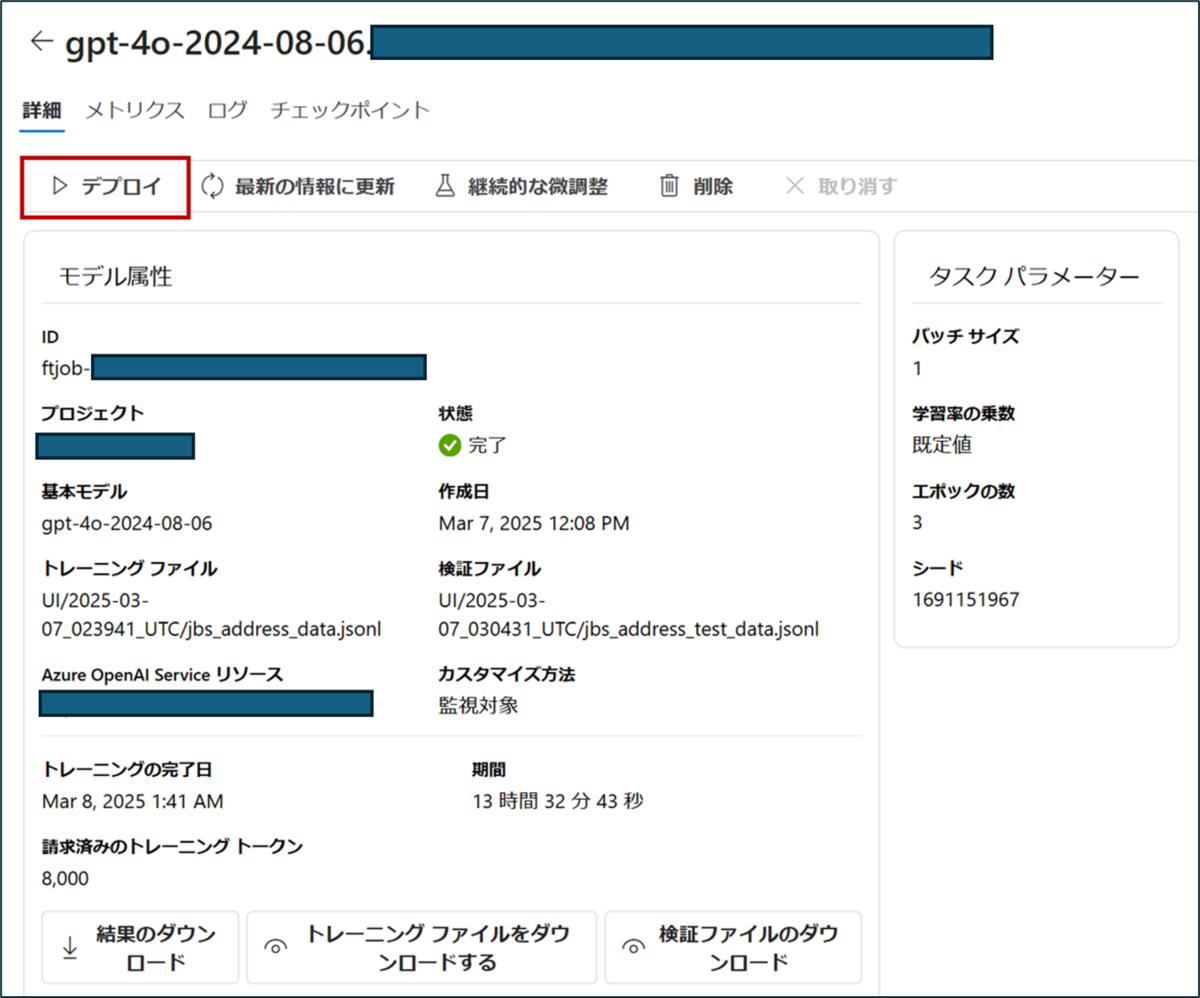
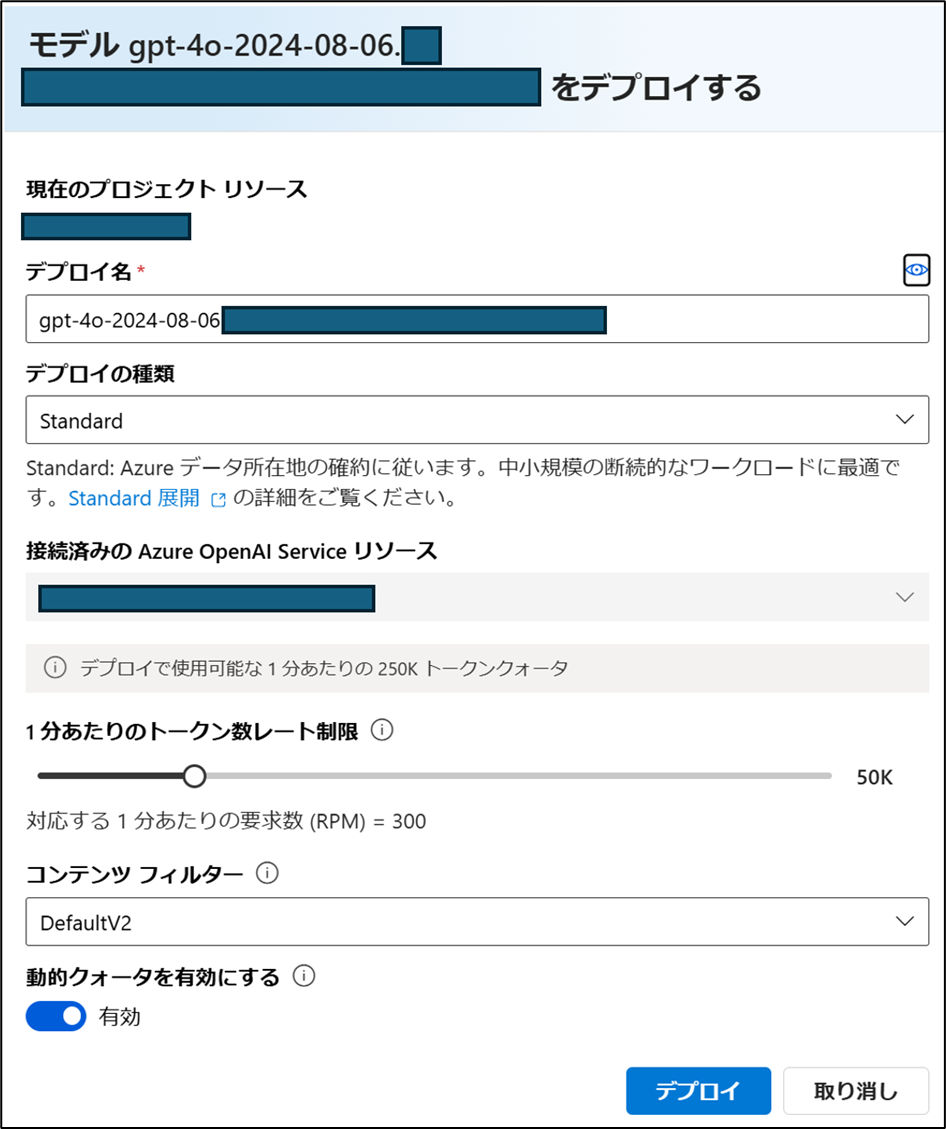
- 確認画面から「デプロイ」をクリック
- デプロイしたモデルに同じ質問をしてみます。
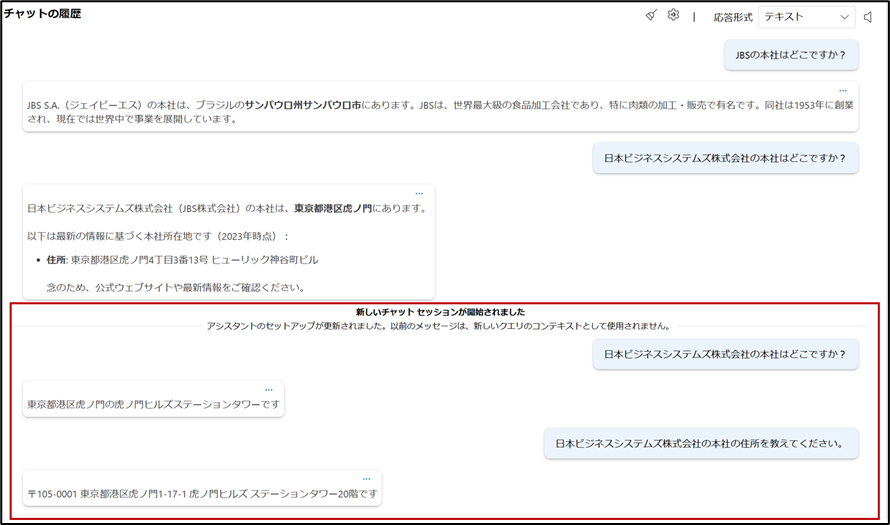
今度は正しい回答を得られました。
ファインチューニングに関わるコストと運用上の注意点
ファインチューニングにおけるコストについて
今回実施したファインチューニング用の学習データをもとに、ファインチューニングにかかった時間および費用をまとめました。Azure AI Foundry 上でファインチューニングを行う際の参考情報としてご活用ください。
なお、所要時間については実行時の状況により多少のばらつきが生じる場合があります。また、学習データは内部で形態素解析された上でトークン単位に変換されるため、データ件数と学習時間・費用は必ずしも比例しません。
| 件数 | トークン数 | 学習時間 | 費用 |
|---|---|---|---|
| 26 件 | 8,000 | 13 時間 32 分 | 24,300 円 |
運用費用について
作成したモデルは、チャットなどの生成AI機能として利用する際、’’入力および出力のトークン数に応じて費用が発生します。また、モデルがデプロイされている間は、利用の有無にかかわらずホスティング費用が継続的に発生する**点にも注意が必要です。
以下に、実際に発生した費用を基に、各コストの内訳をまとめます。 トークン費用については、Microsoft公式サイトの料金表を参考にしています。
なお、キャッシュされた入力とは、過去に同一の入力が送信された場合に、再度推論処理を行わず、あらかじめ保存された出力を返す仕組みです。この場合、通常の入力トークン料金よりも割安な料金が適用されます。
-
トークン費用 ※1$ = 149.5円として算出。小数点第2位以下を四捨五入
項目 単価(100 万トークンあたり) 入力 373.8 円 キャッシュされた入力 186.9 円 出力 1,495.1 円 -
ホスティング費用
1 日あたり 4,033 円
まとめと今後の見通し
Azure AI Foundryの利点と活用シナリオ
Azure AI Foundry は、視認性の高い UI/UXとノーコードでの操作性を備えており、誰でも簡単にファインチューニングを実施できることが大きな利点です。 さらに、Azure OpenAI Service とレイアウトや操作感がほぼ共通しているため、両者の使い分けや移行もスムーズに対応しやすいという特徴があります。
一方、モデルのデプロイ時には使用の有無にかかわらずホスティング費用が継続的に発生するため、運用コストが比較的高くなる点には注意が必要です。例えば、学習データが数百件未満の場合は、ファインチューニングにかかる初期コストやリソースの観点から、プロンプトエンジニアリングで対応した方がコスト効率に優れるケースが多く見受けられます。また、参照するデータが頻繁に更新される場合は、RAGを活用することで、最新情報を動的に取得でき、結果としてコスト効率が向上する場合もあります。 ただし、プロンプトエンジニアリングではモデルの重みが更新されないため、繰り返しのタスクにおいて回答の一貫性やフォーマットの整合性を維持するのが難しいという課題もあります。また、RAG は外部の知識ソースに依存するため、検索結果の品質やレイテンシの問題から、回答の正確性が損なわれるリスクも存在します。
これらを踏まえると、学習データが数百件以上存在し、更新頻度が低く、回答の一貫性が求められる業務で、得られる効果が運用コストを上回ると見込まれる場合には、Azure AI Foundry を活用したファインチューニングが有効な選択肢となります。
今後の見通し
今後は、他社の生成AIサービスとの競争や最適化の進展により、1トークンあたりの利用コストがさらに低減していくことが期待されます。これにより、ファインチューニングの導入ハードルも次第に下がり、より多くのユースケースにおいてドメイン特化型のLLM活用が現実的になると考えられます。
おわりに
LLM最適化には多岐にわたる手法が存在します。継続事前学習、ファインチューニング、RAG、プロンプトエンジニアリングなどの手法の中から、実際の業務では、データの更新頻度、データ量、タスクの特性に応じて最適な手法を選定する必要があります。
本記事が、各手法の特徴やメリット・注意点を踏まえた選定基準の理解の一助となることを期待します。
