
Azure AI Content Understandingは、生成AIを用いて文書・画像・音声・動画の情報を抽出し、構造化するサービスです。
Azure AI Content Understandingには、単一ファイルから情報を抽出する標準モードと、複数ファイルを横断してマルチステップ推論できるプロモードがあります。
本記事では、標準モードで単一ファイルの文書(注文書)から情報を抽出する文書分析(Document analysis)の方法を紹介します。*1
Azure AI Content Understandingとは
Azure AI Content Understandingは、生成AIを用いて文書・画像・音声・動画の情報を抽出し、構造化するサービスです。
ユーザーは抽出したい項目(フィールド)をスキーマとして定義します。例えば、注文書の場合は「注文番号」「発行日」「発注金額」などの項目を、どのように抽出・整形するか(そのまま抽出する、数値だけにするなど)を指定できます。
サービスはこのスキーマに基づき、対象コンテンツから情報を抽出するほか、必要に応じて分類や新しい情報の生成も行います。例えば、文章の要約、画像や動画の説明文の生成、カテゴリ分類なども可能です。
こうしたフィールド定義を活用することで、複雑なプロンプト設計をしなくても、業務に合わせた構造化データを取得できます。
標準モードとプロモードについて
Azure AI Content Understandingの二つのモードについて説明します。
標準モードは単一のファイルから構造化データを抽出できます。対象となるのは文書、画像、音声、動画です。
一方、プロモードは複数ファイルや参照データを組み合わせ、契約条件の検証、不整合発見など複雑な推論ができます。
簡単に違いを表にまとめました。
| 項目 | 標準モード (Standard) | プロモード (Pro) |
|---|---|---|
| 主な用途 | 単一ファイルからスキーマ抽出 | 複数ファイルや参照データを使った高度な判断・照合 |
| 入力対象 | ドキュメント、画像、音声、動画 | ドキュメント*2 |
| 入力ファイル数 | 1つ | 複数 |
| 推論処理 | 複雑な段階的判断は行わない | 段階的な判断・検証(マルチステップ推論)に対応 |
詳しい違いは以下のドキュメントで確認してください。
文書分析(Document analysis)について
Azure AI Content Understanding の 標準モード(Standard) では、文書・画像・音声・動画の分析が可能です。
その中の 文書分析(Document analysis) は、契約書や注文書、請求書などの非構造化文書から、スキーマ定義に沿って必要な項目を抽出・整形する機能です。
処理は大きく2段階に分かれます。
- コンテンツ抽出
-
- テキスト、数式、バーコード、選択マークなどの要素を分析する。
- 段落や表などのレイアウト構造を解析し、文書構造を保ったまま機械可読なデータに変換する。
- フィールド抽出
- 抽出情報からスキーマに基づき特定項目を抽出する。
- 正規化処理により表記ゆれを統一する。
Azure AI Document Intelligence(カスタムモデル)との違い
文書から必要な情報を抽出する似たサービスに Azure AI Document Intelligence のカスタムモデルがあります。
Azure AI Document Intelligence のカスタムモデルを利用する場合、抽出したいフィールドを事前にラベル(バウンディングボックス)付けしてモデルを学習させる必要があります(最低5件以上のサンプルが必要です)。
また、このモデルは学習データの形式に依存するため、抽出後の表記ゆれ(例:電話番号 012-xxx-6789 と 012(xxx)6789)を自動的に統一する機能はありません。
一方、Azure AI Content Understandingの文書分析(Document analysis)では、事前学習なしでスキーマ定義だけを行い、その定義に基づいてすぐに抽出処理を開始できます。さらに、正規化ルールを設定することで表記ゆれを自動的に統一し、抽出結果を一貫したフォーマットで利用できます。
文書分析(Document analysis)で注文書を抽出する手順
以下の注文書サンプルに対して文書分析を行います。
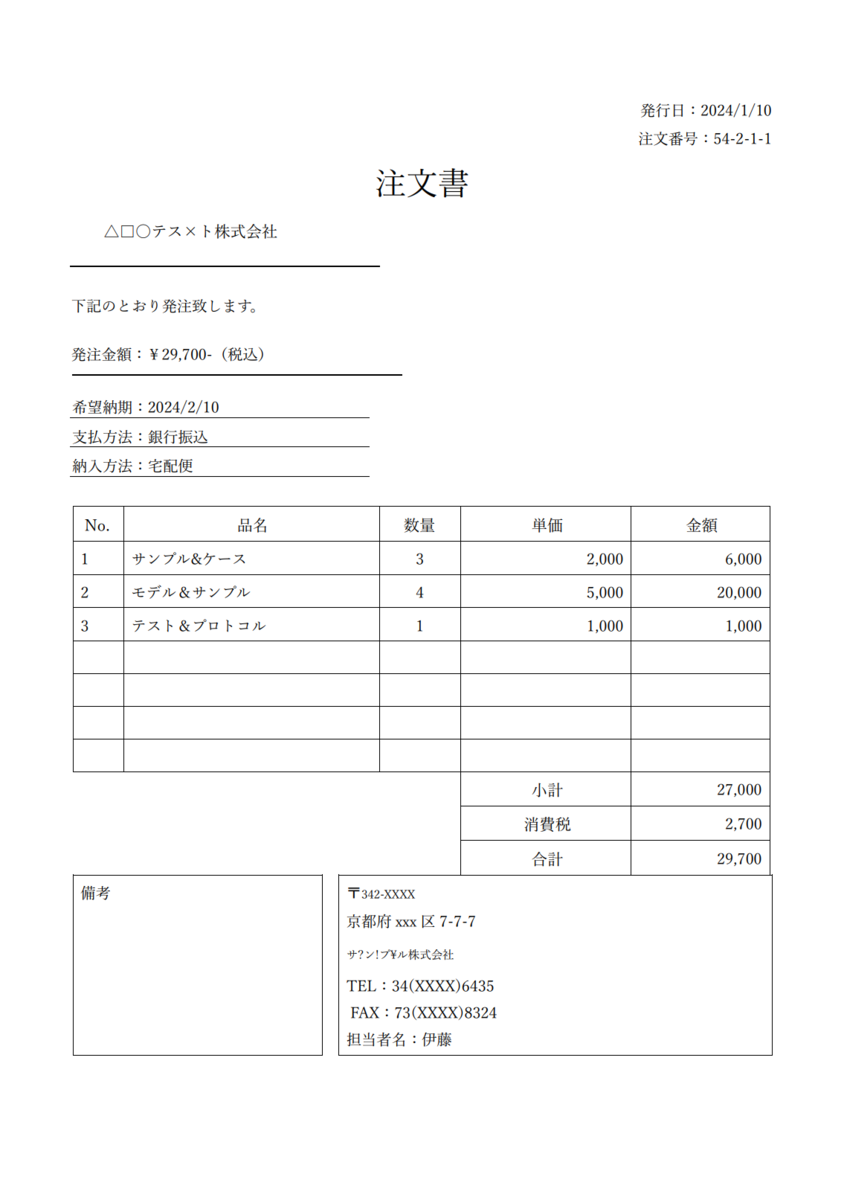
前提条件
- 「westus」「swedencentral」「australiaeast」のいずれかのリージョンに Azure AI Foundry リソースが必要です。
- Azure AI Foundry の管理センター(Management center)でストレージアカウントを接続している必要があります。
手順
-
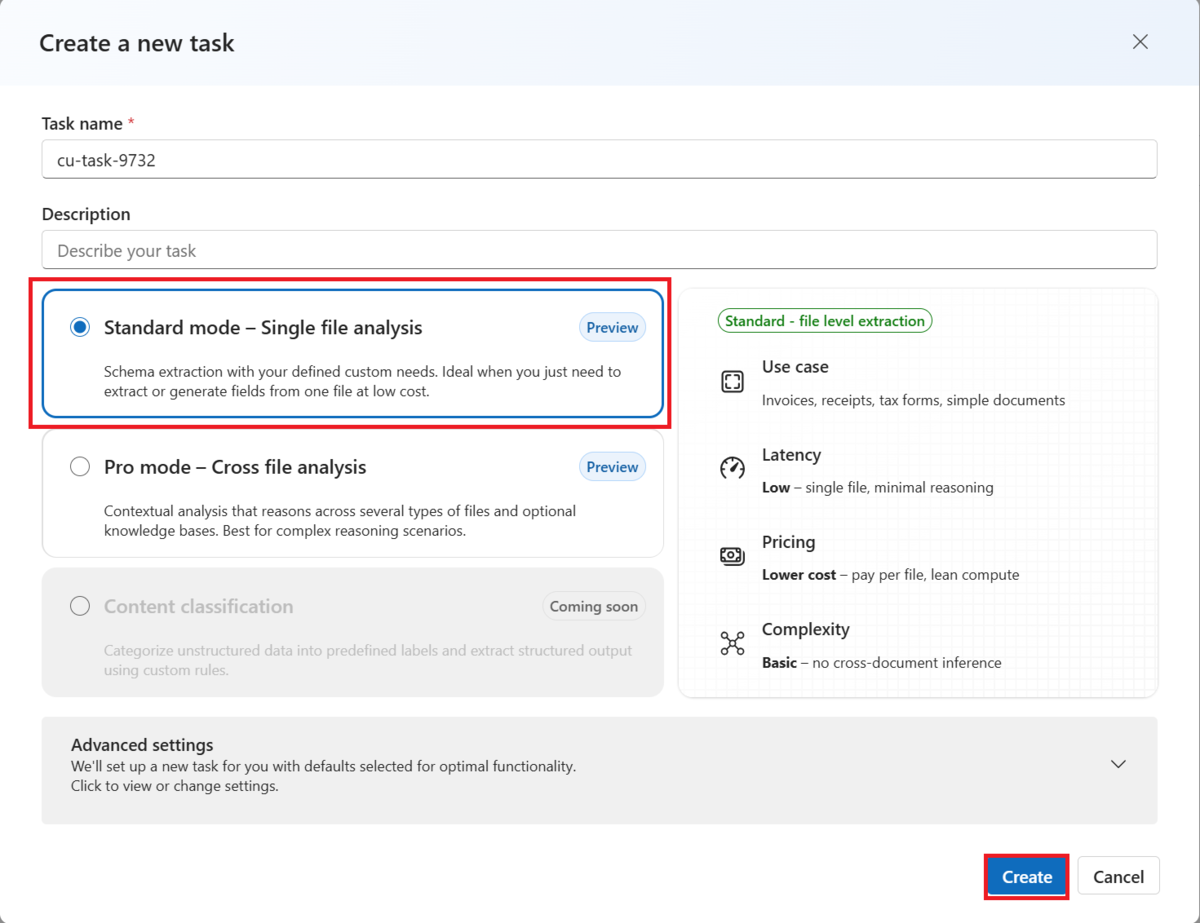
Azure AI Foundryポータルで「Content Understanding」の「Custom task」を開き、「Create」を押します。

- 「Standard mode – Single file analysis」を選択して、 「Create」を押します。
- 「Browse file」で注文書をアップロードします。その後、「Document analysis」を選択し、「Create」を押します。

-
上矢印(インポート)を押し、jsonからスキーマを読み込みます。
(必要なら「Add new field」でフィールドを追加できます。)

読み込むスキーマは以下のjsonです。
このスキーマでは、注文書の各項目(例:発行日、注文番号、発注金額など)が文書内のどこにあるか、どの値を抽出するか、そして抽出後にどのような形式(例:日付フォーマットや数値のみなど)で整形するかを指定しています。
以下のリンクを参考に書きました。
Content Understanding を使用するためのベスト プラクティス - Azure AI services | Microsoft Learn
{ "fieldSchema": { "fields": { "発行日": { "type": "string", "method": "generate", "description": "文書の右上「発行日」から取得。YYYY/MM/DDやYYYY年MM月DD日などは全て「YYYY-MM-DD」に統一する。見つからない場合はnull。例:2025-11-22 " }, "注文番号": { "type": "integer", "method": "generate", "description": "文書右上「注文番号」から取得。ハイフン(-)などの区切り文字、区切り記号は無視する。例:2-4-5→245" }, "宛先": { "type": "string", "method": "generate", "description": "文書左上から取得。例:スーパー株式会社" }, "発注金額": { "type": "integer", "method": "generate", "description": "文書中央の「発注金額」から取得。「円」や「¥」など数値以外のものは無視する。例:¥1230-(税込み)→1230" }, "支払方法": { "type": "string", "method": "generate", "description": "文書中央の「支払方法」から取得。例: 前払い 口座引き落とし など" }, "希望納期": { "type": "string", "method": "generate", "description": "文書中央の「希望納期」から取得。YYYY/MM/DDやYYYY年MM月DD日などは全て「YYYY-MM-DD」に統一する。見つからない場合はnull。例:2025-11-22" }, "納入方法": { "type": "string", "method": "generate", "description": "文書中央の「納入方法」から取得。例: チャーター便 など" }, "品目一覧": { "type": "array", "items": { "type": "object", "properties": { "No": { "type": "integer", "method": "extract", "description": "1列目の「No.」から取得。例: 1" }, "品目": { "type": "string", "method": "extract", "description": "2列目の「品目」から取得。例: サンプル" }, "数量": { "type": "integer", "method": "extract", "description": "3列目「数量」から取得。「個」などの単位は無視し、数値のみ入れる。また、なければnullを返す例:5個→5" }, "単価": { "type": "integer", "method": "extract", "description": "4列目「単価」から取得。「¥」や「円」は無視する。また、なければnullを返す。例:4000円→4000" }, "金額": { "type": "integer", "method": "extract", "description": "5列目「金額」から取得。「¥」や「円」は無視する。また、なければnullを返す。例:4000円→4000" } }, "method": "extract" }, "method": "generate", "description": "文書中央のテーブルから取得。取得するものは「No.」「品目」「数量」「単価」「金額」" }, "小計": { "type": "integer", "method": "generate", "description": " 文書中央下の「小計」から取得。「円」や「¥」など数値以外のものは無視する。例:¥1230-(税込み)→1230" }, "消費税": { "type": "integer", "method": "generate", "description": " 文書中央下の「消費税」から取得。「円」や「¥」など数値以外のものは無視する。例:¥1230-(税込み)→1230" }, "合計": { "type": "integer", "method": "generate", "description": " 文書中央下の「合計」から取得。「円」や「¥」など数値以外のものは無視する。例:¥1230-(税込み)→1230" }, "備考": { "type": "string", "method": "generate", "description": "文書左下四角い枠の「備考」から取得。何もなければ「なし」を返す。(例1:備考 →なし)(例2:備考 20250831修正→20250831修正)" }, "発注元住所": { "type": "string", "method": "generate", "description": "郵便番号、都道府県、市区町村、町名・丁目、番地、建物・部屋番号を取得:例 〒123-xxxx 東京都yyy区zzz2丁目8番1号 ???? 10階1001号室" }, "発注元企業名": { "type": "string", "method": "generate", "description": " 発注元の会社名を取得 例: ○○株式会社" }, "発注元電話番号": { "type": "string", "method": "generate", "description": "発注元の電話番号を取得。「電話番号」や「TEL」などの横に書いてある。()や‐などは無視し、数値だけ取得する 例:「電話番号:123-xxx-789」→123xxx789 " }, "発注元FAX": { "type": "string", "method": "generate", "description": "発注元のFAXを取得。「FAX」などの横に書いてある。()や‐などは無視し、数値だけ取得する 例:「FAX:123-yyy-789」→123yyy789 " }, "発注元担当者名": { "type": "string", "method": "generate", "description": "発注元の担当者の名前を取得。「担当者名」などの横にかいてある。例:担当:あいうえお→あいうえお" } }, "definitions": {} } } }インポートが完了したら「Save」を押します。

- 「Run analysis」をクリックして解析を実行します。

実行結果
実行結果は以下のとおりです。

左側はコンテンツ抽出で検出した文字やテーブルの領域を示し、右側にはそれを基にフィールド抽出した結果が表示されています。*3
また、コンテンツ抽出とフィールド抽出した出力結果を表でまとめました。

この表と定義したスキーマ(JSON)を比較すると、値の抽出や表記ゆれへの対応が適切に行われていることが確認できました。ただし、品目の「&」が「&」と特殊文字に置換される点は改善の余地があります。
もしフィールド抽出で全く別の値を取得しているときは、どこからフィールド抽出すればいいかラベル付けする機能があるため試してください*4。
まとめ
本記事では Azure AI Content Understanding を使い、注文書からスキーマ定義に沿ってフィールドを抽出・構造化する手順を紹介しました。スキーマをプロンプトのように記述し、それを基に取得したい値を取れるため、業務データの加工や活用に有用と感じました。
今回は文書分析(Document analysis)のみを扱いましたが、標準モードには画像・音声・動画の分析機能もあります。これらについても機会があれば記事にしたいと考えています。また、プロモードによる複数ファイル横断の推論・照合は注目すべき機能なため、こちらも機会があれば紹介したいと思います。
*1:現在(2025/09/26)はプレビュー段階のため、一部機能に制限や変更の可能性があります。利用する際は最新の仕様や提供条件をご確認ください。
*2: 2025年9月26日時点の公式ドキュメントには明記されていませんが、PDF内の埋め込み画像は分析できない一方で、別ファイルとして用意したJPG等の画像は分析できました。
*3:jsonでもコンテンツ抽出、フィールド抽出したものが確認できます。取得できる値についてはリンクを確認してください。ドキュメント分析: Azure AI Content Understanding を使用して構造化コンテンツを抽出する - Azure AI services | Microsoft Learn
*4:自信を持って分析を文書化し、基礎を付け、コンテキスト内学習を行う - Azure AI services | Microsoft Learn
