
はじめに
自然言語処理について学習したため、その成果をご紹介します。
今回やりたいことは、文章から関連文書を検索するためのタグ抽出、見出し作成補助などに利用できる重要な単語の抽出を行います。
自然言語処理(NLP)とは?
人間の言語を統計的に解析できる形に変換して、機械で処理することを指します。
コンピューターは数値計算を行いますが、日本語や英語のような自然言語は、画像のRGBや音声信号のような単純な数値に変換できないために工夫する必要があります。
具体的には数値に変換するOne-hot-Encordingアルゴリズムや、ベクトル化するためのWord2Vecモデル、文字列を正規化する前処理などの工夫が必要です。今回はこれらの手法を駆使して、重要単語の抽出プログラムを作成します。
達成目標
記事の中にはさまざまなワードが含まれており、例えばスポーツ記事ならチーム名、試合会場、試合の結果といったような単語が自動で抽出できると価値があるはずです。
ニュース記事から価値のある単語を自動でピックアップできる仕組みが構築できるまでを目標とします。
使用する環境・データセット
使用する環境、データセットの情報は下記の通りです。
PCスペック
OS: Windows10
メモリー: 32GB
バージョン情報
Python: 3.7.7
gensim: 4.1.2
scikit-learn: 0.23.1
SudachiPy: 0.6.0
学習用データセット
livedoorニュースコーパス
配布元: https://www.rondhuit.com/download.html#ldcc
検証用データセット
JWSAN-2145
配布元: http://www.utm.inf.uec.ac.jp/JWSAN/
重要単語抽出までの流れ
ニュース記事から重要単語を抽出するためには、いくつかのステップを踏む必要があります。
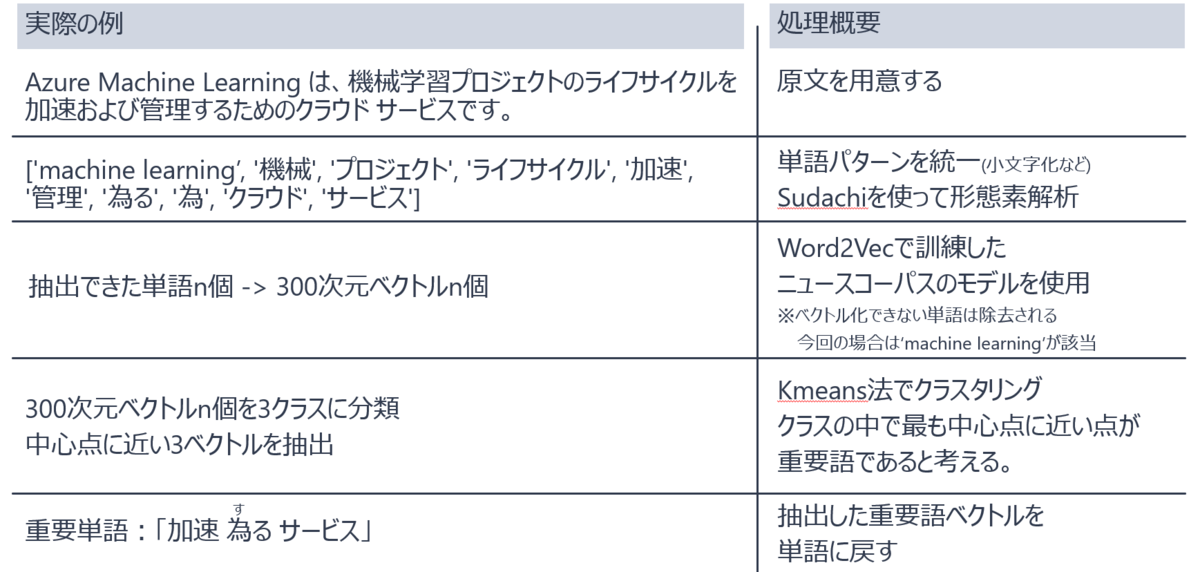
単語の大文字小文字などを統一したり、形態素解析と呼ばれる手法によって品詞単位に文章を分割します。これはPythonに専用のライブラリがあるため、それをそのまま用います。
3番目では、分解した品詞をAIで扱えるような形(ベクトル)に変換してあげます。これにはWord2Vecという機械学習手法を使用します。
4番目では、それらのベクトル化された単語をkmeans法と呼ばれる手法を使ってクラスタリングします。これらより、文章内で重要であると思われる情報をピックアップします。
ニュースコーパスWord2Vec学習結果
Word2Vecはニューラルネットワークを学習させることで、分散表現と呼ばれるベクトルを得ることを目的とした機械学習の手法です。数値に変換することが難しい自然言語の単語を、ベクトル化することができるようになっています。
今回の検証では2つのモデルを作成しましたが、既存のモデルとどの程度近づけたのかを比較するために、別なW2Vのモデルを調査して比較用のモデルとしました。

上二つのOriginal Modelが今回作成したモデルで、下3つが選定した公開済みモデルです。
「語彙」というのがモデルに入力したときにベクトル化できる単語の数です。オリジナルモデルが2万と最も低く、既知のWikiEntVec,chiVeは100万単語以上を学習しています。
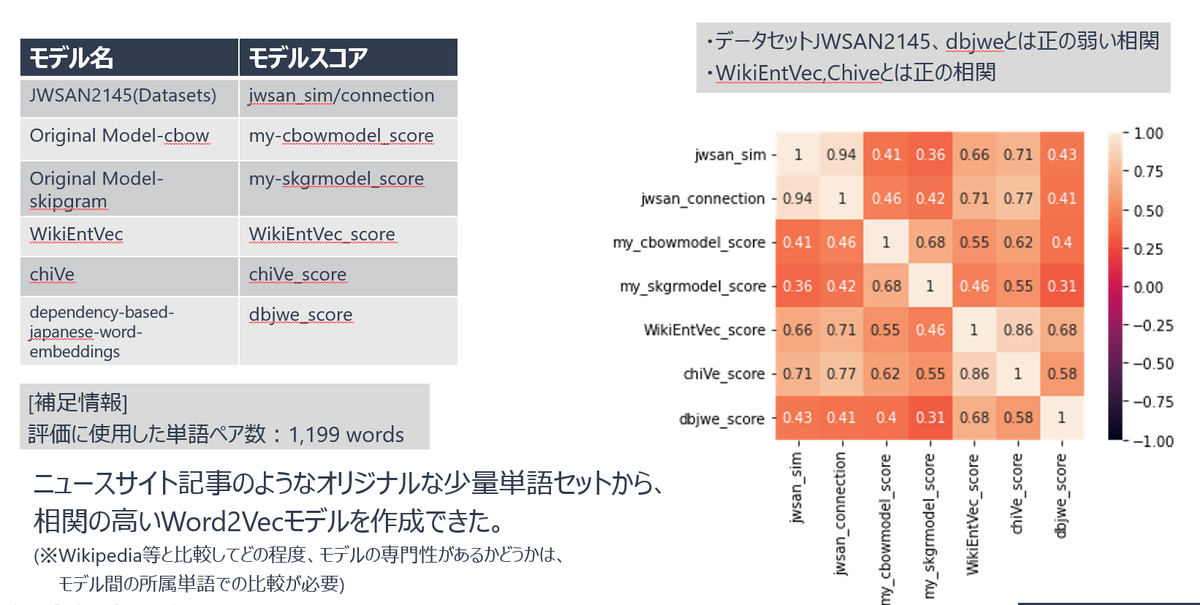
相関係数を用いた比較検証にはJWSAN2145と呼ばれるデータセットを用いました。
学習したモデルを、相関係数で比較した結果が右側の図です。結果としては既存のモデルに対して正の相関、弱い正の相関があるという結果になりました。
これらの結果から、ニュースサイトのような独自のデータセットから、相関の高いWora2Vecモデルを作成することができることが分かりました。
重要単語の抽出
単語抽出概要 K-means法
形態素解析、Word2Vec手法で単語をベクトル化した後はK-means法で単語のピックアップを行います。
K-means法はクラス分けの際、各グループの「平均値」を得ることができます。類似する単語がグルーピングされれば、その中で平均値に近い単語を選ぶことで、重要単語が抽出できると考えました。
k-meansのクラス数がそのままピックアップする単語数となります。
例文記事
今回は例としてJBSの新卒採用のサイトから重要単語のピックアップ例を提示したいと思います。
https://recruit.jbs.co.jp/special
今や、あたり前となったスマホ決済やSNS、
ネットショッピングの注文商品が翌日に届くこと、
自動車が自動運転で走ること。
私たちが創業した30年前にはまだ実現していないことでした。
これらは、さまざまな企業がITのチカラで、
ビジネス課題の解決や新サービスの創出により実現してきたこと。
それはやがて、私たちの生活や社会をも変えてきました。
JBSはITのプロフェッショナルとして、
多様な業種のお客さまの発展をITでリードすることで、
この先の未来も、生活や社会、そしてビジネスのあり方や
働き方までをも大きく変えていく礎となり続けます。
さぁ、切り拓こう、創り出そう、まだ実現していない未来を。
抽出結果
- Original Model(CBOW手法)
- 成る こと 実現 IT 力 創出 生活 社会 御客様 未来
- Original Model(Skip-Gram手法)
- 決済 運転 実現 居る IT プロフェッショナル 業種 この先 未来 作り出す
Word2Vecで学習していない「JBS」といった固有ワードは弾かれてしまっていますが、文章で伝えたい「ITのプロフェッショナルとして未来を作る」というニュアンスの周りの単語をピックアップできている印象です。
課題として「こと」「居る」のような余計なワードが含まれてしまっていますが、このような一般的で単独では役に立たない、除外するべき単語をストップワードと呼びます。これについては無条件で弾く設定を、今後処理に含めることで回避が可能だと考えています。
「決済」「運転」などの本質を関係ない単語も取り上げてしまっていますが、この点は今後の課題として考えております。現状では、記事の文字数に応じてピックアップする単語数を調整するなどの対策を考えています。
まとめ
今回はAIを使って重要単語をピックアップするまでの手順を示しました。独自のデータセットで作成しても、相関係数が高いWord2VecのModelが作成できることが分かりました。
重要単語のピックアップがうまくいっているかを定量的に検証する方法については詰められていないため、今後アンケートをとるなどの方法で検討していきます。また精度を向上させる手法についても引き続き検討を行います。
