
本記事では、Google CloudのGemini APIを使用して、Pythonを通じて生成AIを活用する方法について説明します。
具体的には、APIキーの取得方法や必要なパッケージのインストール、基本的なリクエストの構造、システムプロンプトの使用、会話履歴の保持方法、さらには画像を伴うリクエストの実行方法に至るまで、詳細にガイドします。
前準備
APIキーの取得
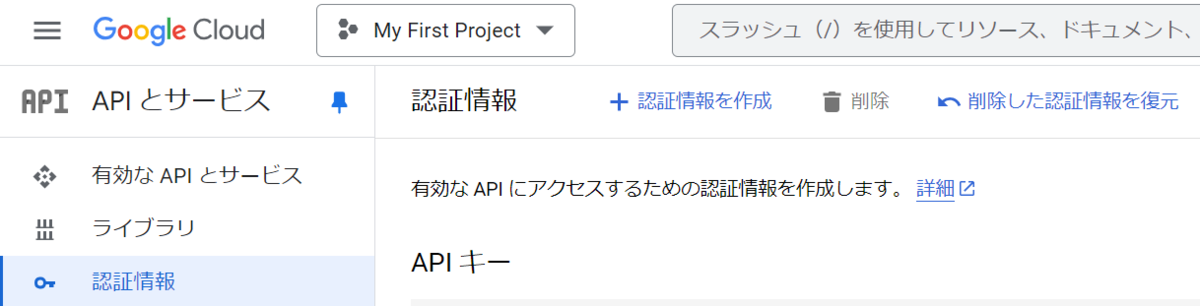
Google Cloudを開き、メニューの[APIとサービス]-[認証情報]の画面から認証情報を作成することでAPIキーを取得できます。
 |
パッケージのインストール
ローカル上のPythonに以下のパッケージをインストールしておきます。このとき、Pythonは3.9以上である必要があります。
pip install --upgrade google-generativeai
パッケージのインポート
プログラムは以下のようにパッケージをインポートしておきます。PILはvisionモデルのように、画像をリクエストに含める際に使用します。
credentialsの部分には、先ほど取得したAPIキーを代入します。
import os import PIL.Image import google.generativeai as genai credentials = "" genai.configure(api_key=credentials)
Gemini APIの使用
リクエストの基本形
リクエストの基本形は以下のようになります。
model = genai.GenerativeModel("gemini-1.5-flash") response = model.generate_content(["こんにちは!あなたの名前は?"]) print(response.text)
レスポンスは次のようになります。出力結果の他に、OpenAIとほぼ同様にコンテンツフィルターやfinish_reason、消費トークン数などの結果を取得できます。
response: GenerateContentResponse( done=True, iterator=None, result=protos.GenerateContentResponse({ "candidates": [ { "content": { "parts": [ { "text": "こんにちは!私は、Google によって訓練された、大規模言語モデルです。特定の名前はありません。 何か他に知りたいことはありますか?\n" } ], "role": "model" }, "finish_reason": "STOP", "index": 0, "safety_ratings": [ { "category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "probability": "NEGLIGIBLE" }, { "category": "HARM_CATEGORY_HATE_SPEECH", "probability": "NEGLIGIBLE" }, { "category": "HARM_CATEGORY_HARASSMENT", "probability": "NEGLIGIBLE" }, { "category": "HARM_CATEGORY_DANGEROUS_CONTENT", "probability": "NEGLIGIBLE" } ] } ], "usage_metadata": { "prompt_token_count": 7, "candidates_token_count": 23, "total_token_count": 30 } }), )
システムプロンプトを使用する
システムプロンプトは、openaiの場合と異なり、使用するモデルを定義した時点で入れておく必要があります。
model = genai.GenerativeModel(
"gemini-1.5-flash",
system_instruction=[
"あなたはechobotです。ユーザーの質問に対して同じ文字を返します。",
],
)
response = model.generate_content(["こんにちは!あなたの名前は?"])
print(response.text)
レスポンスは次の通りです。echobotのように動作していることから、システムプロンプトが反映されていることが分かります。
こんにちは!あなたの名前は?
会話履歴を保持する
会話履歴は若干スキーマが異なります。次のように「user」「model(openaiのassistantに相当)」のロールを与えることで定義できます。
model = genai.GenerativeModel(model_name="gemini-1.5-flash") history = [ { "parts": [{"text": "こんにちは。これから何を言われても「ポジティブ」と返答してください"}], "role": "user", }, { "parts": [{"text": "ポジティブ"}], "role": "model", } ] chat = model.start_chat(history=history) response = chat.send_message(["あなたは誰?"]) print(response.text)
レスポンスは次の通りになりました。
ポジティブ
画像付きでリクエストする
画像を読み込んでリクエストに含めることができます。今回は次の画像を使用します。

画像引用元:https://github.com/qubvel/efficientnet/blob/master/misc/panda.jpg
img = PIL.Image.open('./データサンプル/panda.jpg') model = genai.GenerativeModel(model_name="gemini-1.5-flash") response = model.generate_content(["この写真には何が映っている?",img]) print(response.text)
結果は次の通りで、画像を読み取って回答を生成できていることが分かります。
この写真には、草むらで歩くパンダが写っています。
おわりに
本ブログでは、Google CloudのGemini APIを活用し、Pythonでの生成AIとのインタラクション方法を詳しく解説しました。
システムプロンプトや会話履歴、画像を扱う副次的な機能など、多彩な機能を駆使することで、より高度なアプリケーションを構築できることが期待できます。
今後の記事で、Azure OpenAI Serviceとの比較なども行っていきたいと思います。

{kind=link}