
本記事では、Google Cloud Platform(GCP)を利用して、資料を格納し、それを検索するアプリケーションを構築する手順をご紹介します。
Cloud StorageにCSVファイルをアップロードし、Agent Builderを使用して検索機能を実装します。具体的には、タイタニック号の生存者データを例に、データの準備から検索アプリの構築、及びPythonによる検索方法までを説明します。
手順
以下の手順により検索基盤を構築します。
- 前準備: APIを有効化する
- 資料を格納するストレージを準備する
- Cloud Storageに資料を配置する
- 検索アプリを構築する
- 検索アプリをPythonから使用する
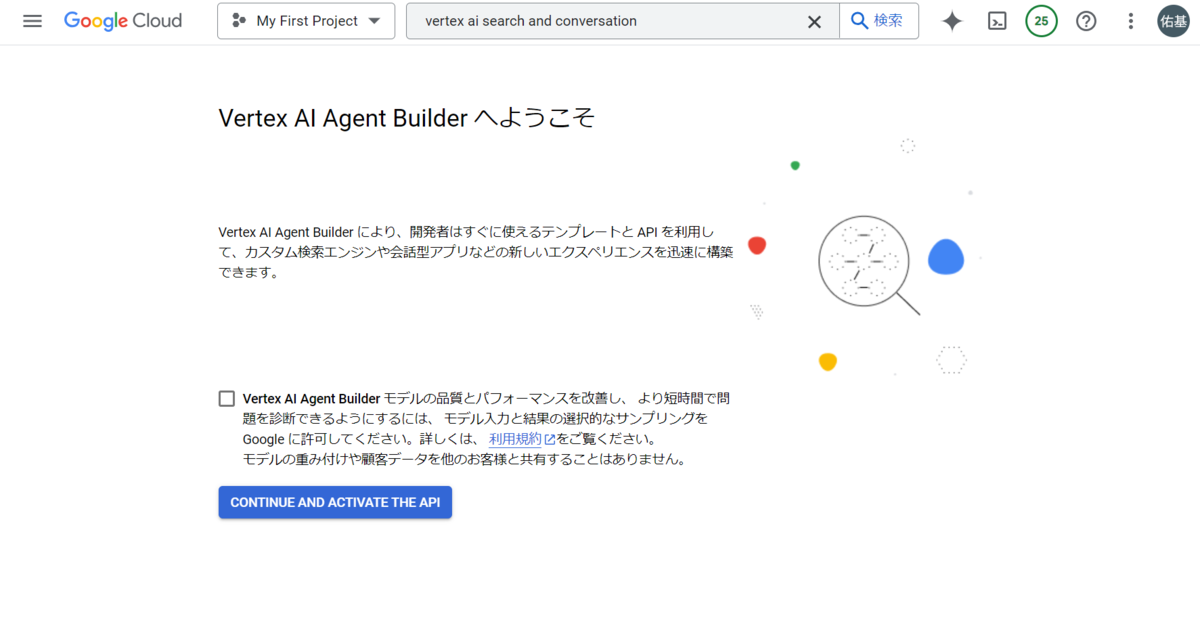
前準備: APIを有効化する
Cloud StorageとAgent Builderの2つをそれぞれ検索ボックスに入力してサービスを表示し、「CONTINUE AND ACTIVATE THE API」をクリックしてAPIを有効化します。
 |
資料を格納するストレージを準備する
GCPではストレージアカウントはプロジェクト単位で用意され、バケット(コンテナー)で各ファイルを管理します。
「作成」からバケットを作成します。
 |
名前は全GCPサービス上でユニークな名称を指定します。
Cloud StorageではBLOBストレージと同様に、フラットファイル構造によってファイル管理を行っています。Azure DataLakeStorage Gen2のように階層構造での管理を行いたい場合は、「このバケットで階層的な名前空間を有効にする」をONにします。
リージョンは、後のAgent Builderがusまたはeuで提供されるサービスになるため、Cloud Storageでもus/euいずれかのリージョンを選択します。
そのほかはデフォルトの設定でバケットを作成します。
Cloud Storageに資料を配置する
手動でファイルをアップロードする
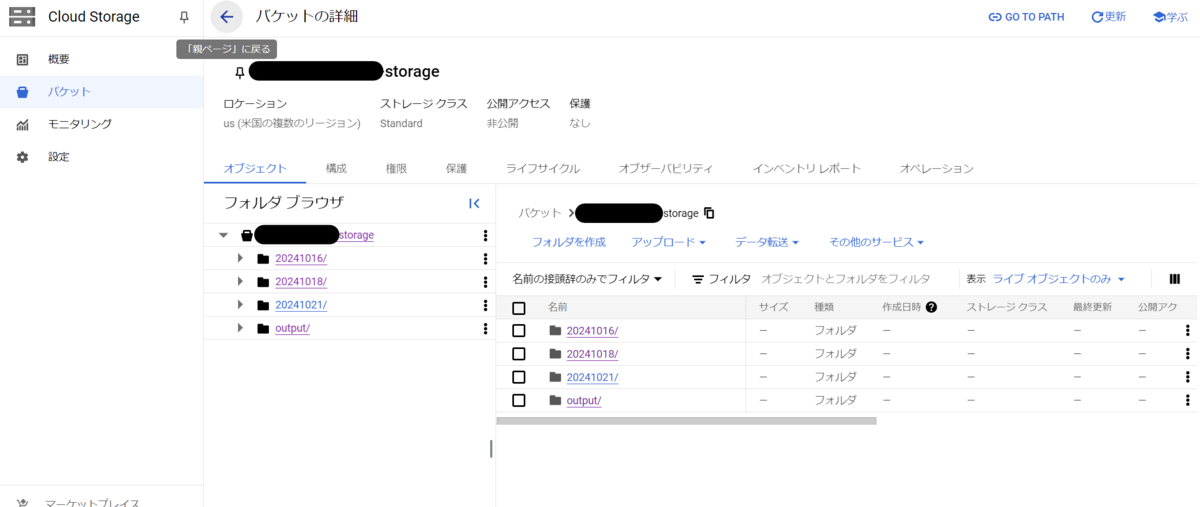
2番の手順でCloud Storage上にバケット(コンテナ)を作成したので、ここに資料を配置します。
Cloud Storageのバケット一覧から作成したバケットを選択します。
 |
任意で管理用のフォルダを作成した後に「アップロード」を選択して、バケットに対して手元の資料のアップロードを実施します。
 |
今回の記事では、タイタニック号生存予測のCSVファイルをアップロードしたものとします。
プログラムからファイルをアップロードする
Pythonからアップロードを実施することができます。
[IAMと管理]-[サービスアカウント]を選択して、サービスアカウントを作成します。作成後にjsonファイルがダウンロードできるため、これをPythonを実行する環境に補完しておきます。(GOOGLE_APPLICATION_CREDENTIALS環境変数にjsonのパスを設定します)
実行するv3.9以上のPython環境に以下のパッケージを導入します。
pip install --upgrade google-cloud-storage
以下のプログラムを実行します。
import os from google.cloud import storage os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = "" file_path = "" bucket_name = "XXXXXXXXXX-storage" upload_path = "20241021/"+file_path.split('/')[-1] client = storage.Client() bucket = client.bucket(bucket_name) blob = bucket.blob(upload_path) blob.upload_from_filename(pdf_path)
GOOGLE_APPLICATION_CREDENTIALSにJSONのパス、file_pathにアップロードしたいローカル環境のファイル、buket_nameにバケット名を指定します。またupload_pathでバケット上で管理するBLOBの名称を指定しています。
検索アプリを構築する
データストアの作成
データをアップロードした後、そのファイルを検索サービスに認識させる必要があります。
[Agent Builder]-[データストア]を選択します。データソースを選択する画面になるので、Cloud Storageを選択します。
 |
Cloud Storage のデータをインポートの画面に遷移します。ここでアップロードしたファイルタイプによってチェックボックスを変更します。
今回はタイタニック号のデータのためQ&Aのファイルではありませんが、CSVファイルをアップロードしたので「チャット アプリケーション用のよくある質問の構造化データ(CSV)」を選択します。イメージとしては、例えば乗船者の名前を入力すると関連する行が抽出されるようなアプリケーションを想定します。
その後、単一のファイルもしくはフォルダ単位でパスを指定します。
 |
最後に任意のデータストアを作成して、データの前準備は完了です。
また後程のプログラムで使用するため、ここのデータストアのIDは別途メモしておきます。
検索アプリの作成
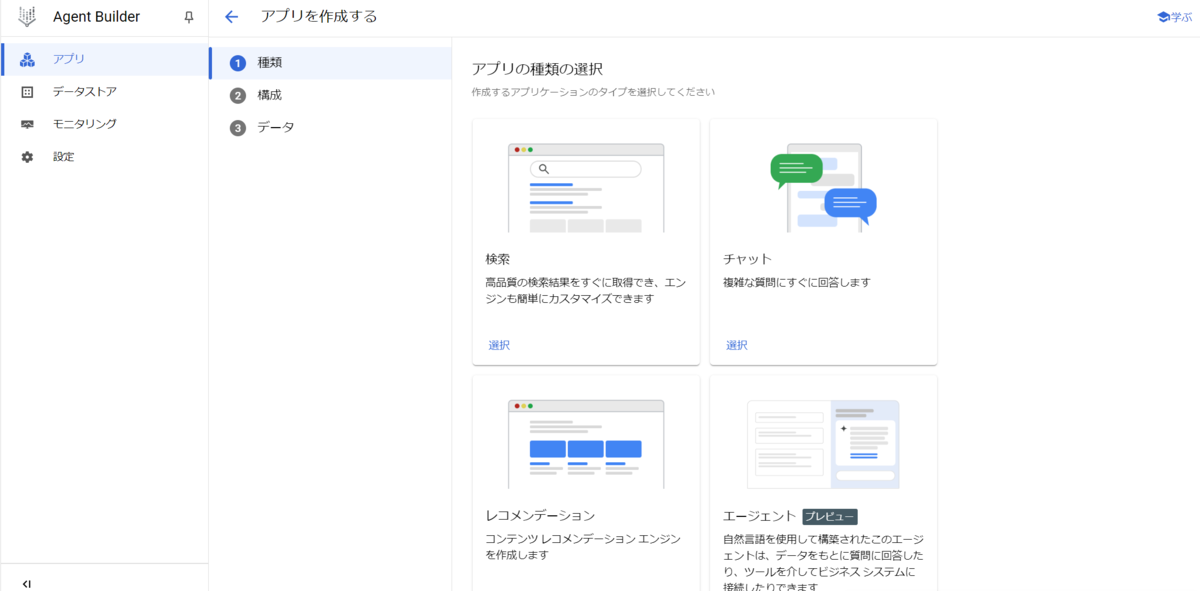
[Agent Builder]-[アプリ]より検索アプリを作成します。
今回は「検索」を選択します。
 |
アプリ構成の内容は汎用とし、2つともチェックボックスは外しておきます。検索アプリのロケーションはグローバルを選択します。
データストアの選択で先ほど作成したデータストアを選択して次に進むと、実際にインデックスが作成されます。
 |
[プレビュー]を選択し、任意のキーワードを入力して検索を実行すると、関連するカラムが抽出できることが確認できます。
 |
検索アプリをPythonから使用する
検索アプリをPython実行するにあたって、以下のパッケージをインストールしておきます。
pip install google-cloud-discoveryengine
以下のコードを実行します。プロジェクトID、データストアのIDを指定して実行すると検索結果を取得できます。
from google.api_core.client_options import ClientOptions from google.cloud import discoveryengine_v1 as discoveryengine from google.protobuf.json_format import MessageToDict def search_sample(gcp_project_id, data_store_id, search_query, k=10): client_options = ( ClientOptions(api_endpoint=f"global-discoveryengine.googleapis.com") ) client = discoveryengine.SearchServiceClient(client_options=client_options) serving_config = client.serving_config_path( project=gcp_project_id, location="global", data_store=data_store_id, serving_config="default_config", ) content_search_spec = discoveryengine.SearchRequest.ContentSearchSpec( snippet_spec=discoveryengine.SearchRequest.ContentSearchSpec.SnippetSpec( return_snippet=True ), summary_spec=discoveryengine.SearchRequest.ContentSearchSpec.SummarySpec( summary_result_count=5, include_citations=True, ignore_adversarial_query=True, ignore_non_summary_seeking_query=True, ), ) request = discoveryengine.SearchRequest( serving_config=serving_config, query=search_query, page_size=10, content_search_spec=content_search_spec, query_expansion_spec=discoveryengine.SearchRequest.QueryExpansionSpec( condition=discoveryengine.SearchRequest.QueryExpansionSpec.Condition.AUTO, ), spell_correction_spec=discoveryengine.SearchRequest.SpellCorrectionSpec( mode=discoveryengine.SearchRequest.SpellCorrectionSpec.Mode.AUTO ), ) response = client.search(request) result = response.summary.summary_text documents = [] if not response.results: return result, documents for r in response.results : json_text = MessageToDict(r._pb) document = json_text['document'] documents.append(document) return result, documents gcp_project_id = "" data_store_id = "" query = "Eliabeth" result, documents = search_sample(gcp_project_id, data_store_id, query) print(result) for document in documents: print(document['structData'])
resultを参照して、クエリと取得した検索結果に関する説明を取得できます。
There is no information about Elizabeth in the provided sources. The sources contain information about individuals named Elias, Badman, Abelseth, Abrahim, and Khalil. The sources provide details about their age, cabin, embarked location, fare, name, parch, passenger ID, passenger class, sex, sibsp, and ticket number. [1, 2, 3, 4, 5] For example, Elias, Mr. Joseph was 39 years old, embarked from C, and paid 7.2292 for his ticket. [1] Badman, Miss. Emily Louisa was 18 years old, embarked from S, and paid 8.05 for her ticket. [2]
documentsで検索された結果を10件取得できます。今回のケースでは、csvファイルの内容(タイタニック号の乗船者サンプルデータ)を、Dictの形で取得することができました。
{'Pclass': '3', 'Fare': '7.2292', 'Embarked': 'C', 'Name': 'Elias, Mr. Joseph', 'Ticket': '2675', 'SibSp': '0', 'Sex': 'male', 'Age': '39', 'Cabin': '', 'Parch': '2', 'PassengerId': '1229'} {'Pclass': '3', 'Fare': '8.05', 'Embarked': 'S', 'Cabin': '', 'Ticket': 'A/4 31416', 'SibSp': '0', 'Sex': 'female', 'Age': '18', 'Name': 'Badman, Miss. Emily Louisa', 'Parch': '0', 'PassengerId': '979'} {'Pclass': '3', 'Parch': '0', 'Embarked': 'S', 'Cabin': '', 'PassengerId': '1237', 'Ticket': '348125', 'Sex': 'female', 'Age': '16', 'Name': 'Abelseth, Miss. Karen Marie', 'SibSp': '0', 'Fare': '7.65'} ...
おわりに
本記事では、Google Cloud Platform (GCP) を使用して資料を管理し、検索アプリケーションを構築する方法について詳しく解説しました。Cloud Storageを活用したデータの格納、Agent Builderを通じた検索機能の実装、Pythonからの実行まで、具体的な手順とコード例を示しました。
RAG(Retrieval-Augmented Generation)を構築するためには、さらに検索結果をプロンプトに含めてLLM(大規模言語モデル)に入力する必要があります。これにより、モデルは外部データを参照しながら、より正確で信頼性の高い応答を生成します。
GCPの他のサービスを組み合わせることで、テキスト生成やデータ分析を強化し、実際のアプリケーションとしての価値を高めることが可能です。
引き続き、GCPやAI技術の最新のトレンド情報を提供していけたらと思います。
