
はじめに
MIcrosoft Syntexをご存知でしょうか?
Microsoft Syntexとは、人工知能(AI)や高度な機械学習を使用して、SharePoint Online(以後SPO)内のドキュメント整理を自動化できるサービスを指します。*1
抽出した属性(メタデータ)を使用することで、SPOの検索機能が向上するだけでなく、ドキュメントライブラリのプロパティ値入力などをノンコーディングで自動化することもできます。
Microsoft Syntexの機能については、運用担当ユーザーに対してのSyntexライセンス付与によって、新規で作成する環境だけでなく、現在運用されているSPOサイトにおいても使用することができます。
数あるMicrosoft Syntexの機能のうち、今回は、ドキュメント処理を行うカスタムモデルを用いた、Excelファイル内のメタデータ抽出の方法を説明します。
Excelファイルのメタデータ抽出は、Excelファイルが計算以外の用途に使用されるケースが(経験上)多いという点で、汎用性が高いと思われる一方、Microsoft側でのサンプルファイル提供がなく、実現性が不明瞭なところがありました。
また、非構造化データ(ExcelやWordなど)の文書ファイルを扱うカスタムモデル展開についても、現時点で日本語未対応*2のため、国内の環境上で、現段階で、どこまでモデルを実用化できるか、その検証結果についても共有できればと思い、筆を執らせていただいた次第です。
前提条件
- 想定ユーザーはSPO運用担当者とし、「SharePoint Syntex」ライセンスが付与されているものとします。
- SPO運用担当ユーザーは、「グローバル管理者」の役割を付与されているものとします。
- 作成したモデルの適用先サイトは、「コミュニケーションサイト」とします。
- メタデータ抽出対象のExcelファイルは、書式テンプレートがあらかじめ固定されているものとします。
モデル作成
Excelファイルのメタデータ抽出を行うモデルを作成していきます。
作成手順は、大きく分けて3ステップとなります。
- トレーニング用ファイルをアップロードする
- ファイル分類モデルのトレーニングを行う
- 抽出対象の各メタデータごとに抽出器を作成する
トレーニング用ファイルの追加まで
SharePoint管理センターから、「コンテンツ センター」にアクセスします。*3

遷移した「コンテンツ センター」サイト上にて、画面左上の「+新規」>「モデル」をクリックします。
すると、「モデル作成のオプション」画面が表示されます。
画面上では、「請求書処理」などの「事前構築済みモデル」を選択することもできますが、今回は、「授業方法」(「ティーチング メソッド」とも表記されます)をクリックします。

「ティーチング メソッドでモデルを作成する」画面上では、入力必須の「モデル名*4」と任意の「説明」を入力後、「作成」をクリックします。

モデルのトレーニング用画面に遷移したら、左上の「ファイルの追加」をクリック*5し、モデルのトレーニングに必要なファイルを、下記の条件で用意し、アップロードします。
- 抽出対象ファイルと同じ種類のファイル:5ファイル以上*6
- 抽出対象ファイルと異なる種類のファイル:1ファイル以上
今回は、下のExcelファイルで作成された「作業計画書」を抽出対象ファイルとして、赤枠で囲んでいる、

- 作業対応者名
- 作業概要
- 作業背景
- 作業完了条件
の4点を、抽出対象としたいと思います。
なお、異なる種類のファイルとしては、下のような表が記載されているファイルを用意します。

トレーニングの分類子
ファイルのアップロードが完了したら、「トレーニングの分類子」をクリックします。
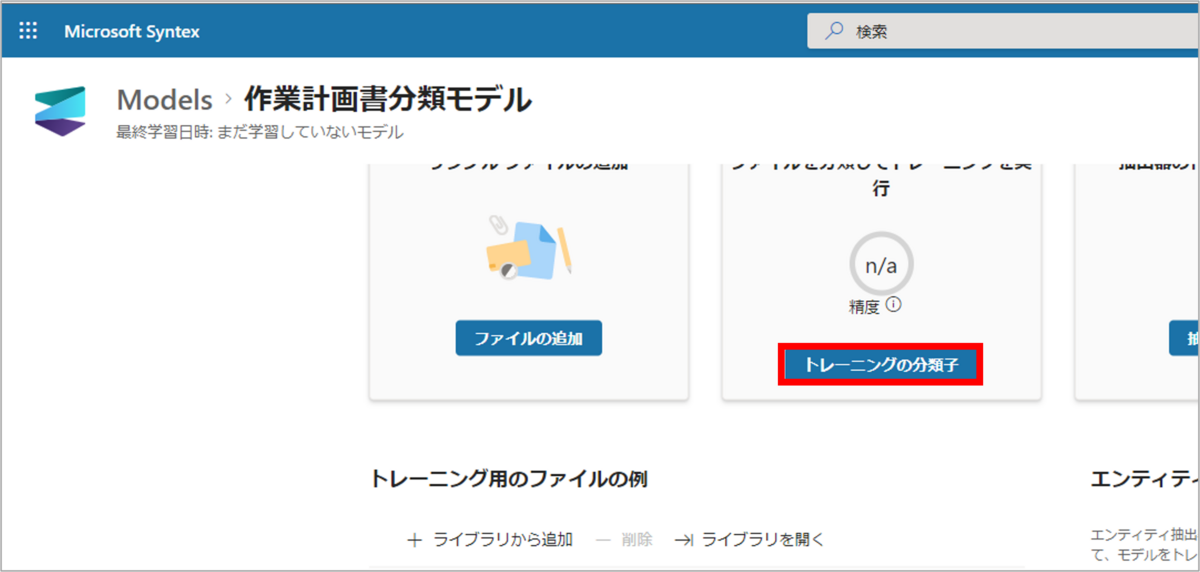
「トレーニングの分類子」では、アップロードした各ファイルについて、
- 抽出対象ファイルと同じ種類のファイル:ポジティブ
- 抽出対象ファイルと異なる種類のファイル:ネガティブ
のラベル付けを、「このファイルは<モデル名>の例ですか?」という各ファイルへの質問に対して、「はい」か「いいえ」で選択します。
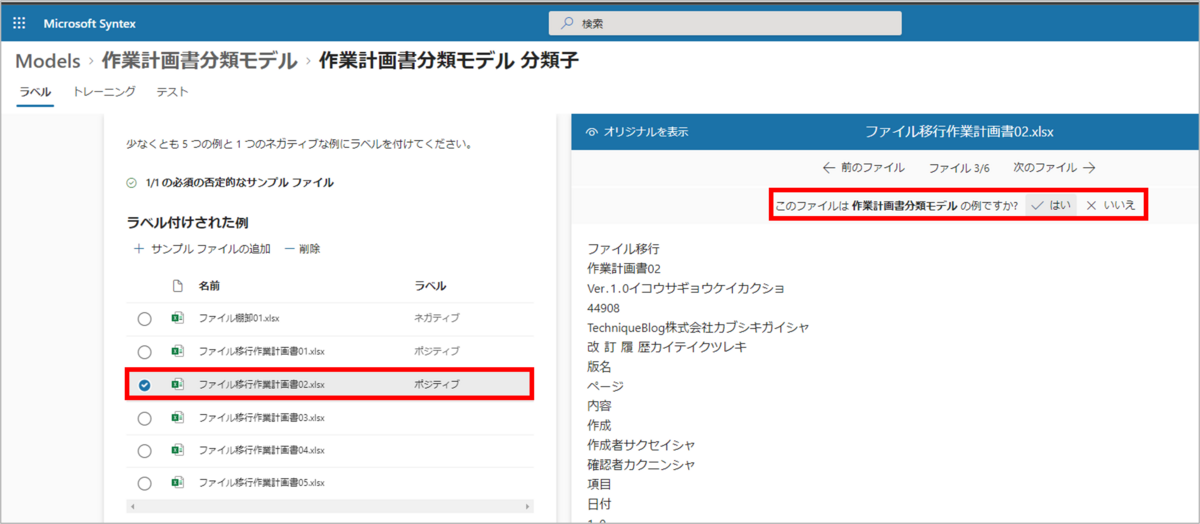
ラベル付けが完了したら、左上の「トレーニング」タブか、画面上部に表示される「トレーニング」リンクをクリックし、「トレーニング」画面に遷移します。
「トレーニング」画面では、抽出対象ファイルを識別する方法(特徴)を、モデルに対して設定する必要があります。
「説明」の「+新機能」>「空白」をクリックします。
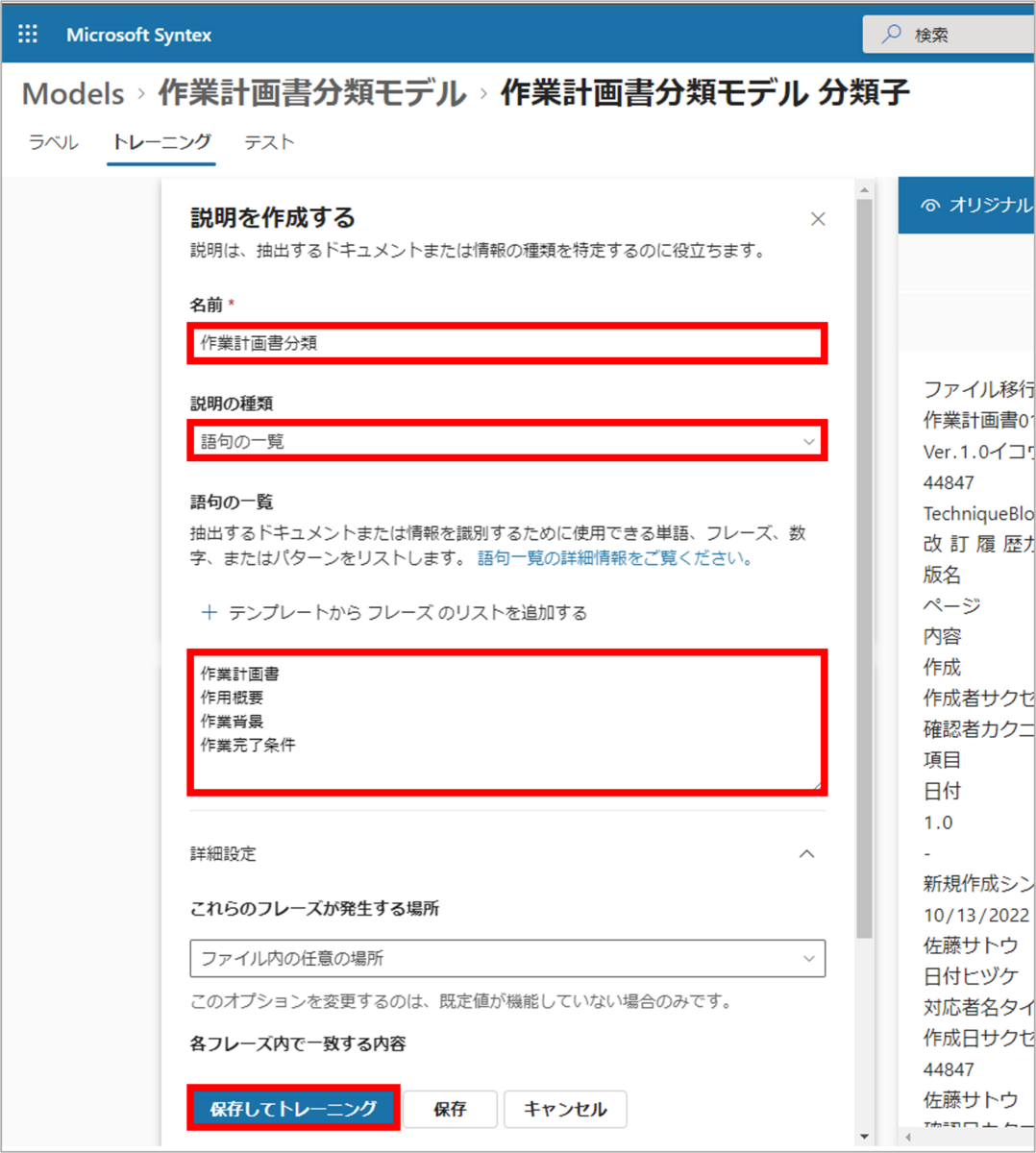
「説明を作成する」画面では、対象ファイルを識別するために使用できる単語やフレーズ、コロケーション(単語の組み合わせ)を指定します。
今回は、先述した抽出対象の4点を記載することで、対象ファイルを識別するためのメルクマール(指標)とします。
- 名前:<任意の名前>を入力
- 説明の種類:「語句の一覧」を選択
- 語句の一覧:<抽出対象など、対象ファイルを識別するための単語等>を入力
上記を指定後、「保存してトレーニング」をクリックします。
すると、トレーニングが開始されます。トレーニングは数秒で完了します。
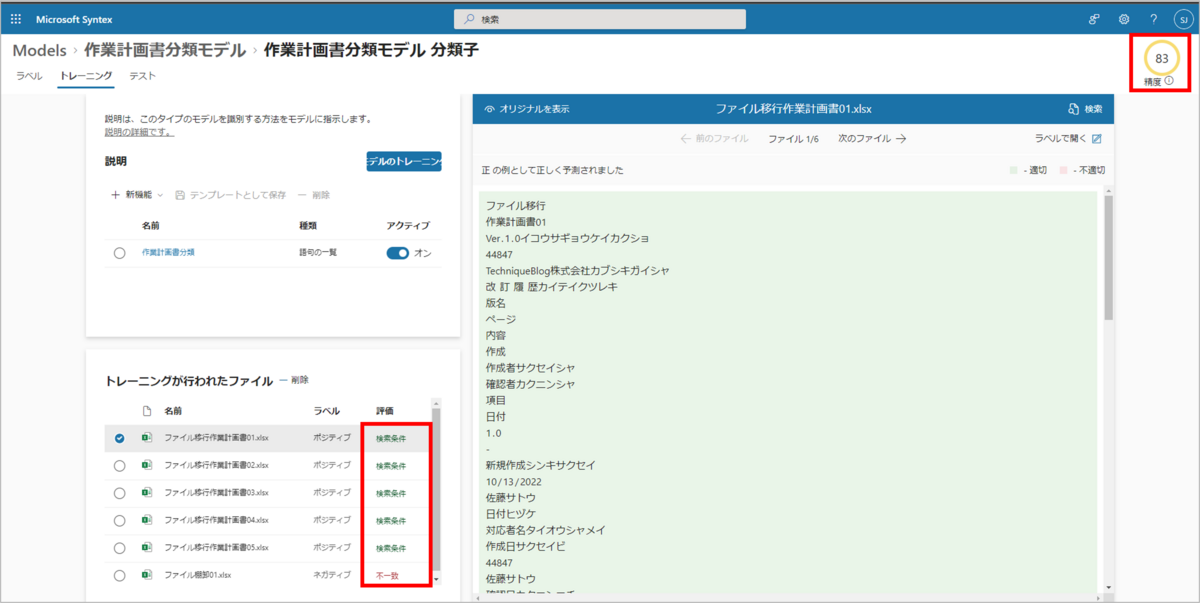
トレーニング完了後、対象ファイルに対し、「評価」の属性として、
- 検索条件:正しく予測された
- 不一致:誤って予測された
のいずれかが表示され、画面右上には、分類子としてのモデルの精度が表示されます。*7
トレーニング完了後、「テスト」タブをクリックすると、サンプルファイルを追加してリトレーニングを行うことで、モデルの改善を行うことができます。今回はスキップするので、「[トレーニング]を終了する」をクリックします。
抽出器の作成
分類子のトレーニングが完了したら、抽出器の作成を行います。まずは、4つの抽出対象のうち、「作業対応者名」用の抽出器を作成していきます。
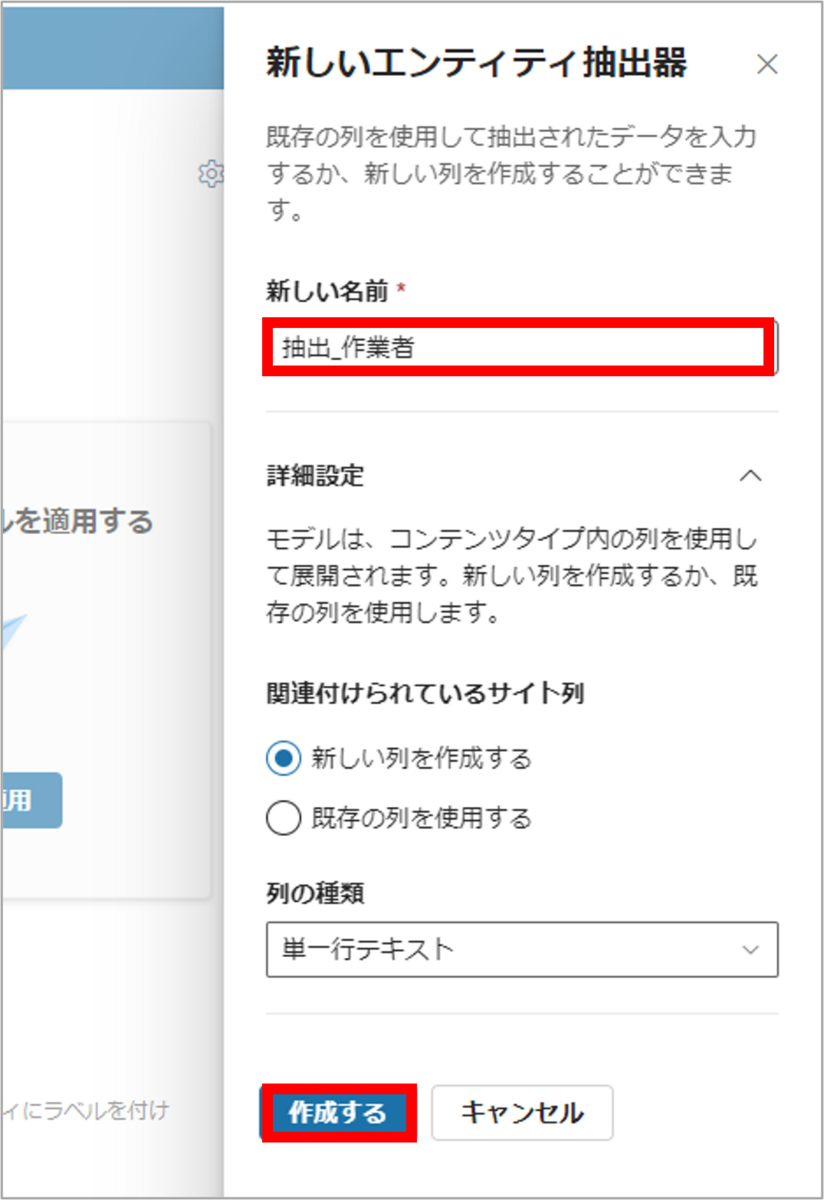
モデルのトレーニング用画面上の「抽出器の作成」をクリック*8後、「新しい名前」にて任意の名前を入力し、「作成する」をクリックします。
「抽出器」の「ラベル」タブ画面では、アップロード済みの各サンプルファイルに対して、抽出したい要素のラベル付けを行います。
Excelファイルのラベル付け画面では、ファイル内のテキストデータが、トークン(スペースや句読点を含まない文字や数字のひとまとまり)*9ごとに行で区切られて表示されるので、抽出する要素を特定し、マウスオーバーでラベリングします。*10

抽出対象でないネガティブなファイルについては、「ラベルなし」を選択します。
「抽出器」の「トレーニング」タブ画面では、対象ファイル内における抽出対象のデータが表示される語句のパターンや、表示される可能性のある範囲をそれぞれ指定します。
「トレーニングの分類子」と同様に、「説明」の「+新機能」>「空白」をクリックします。
「説明の編集」画面では、以下のように入力後、抽出対象の前後2トークン程度を、範囲ボックスで下のように囲みます。
- 名前:<任意の名前>を入力
- 説明の種類:「語句の一覧」を選択
- 語句の一覧:<抽出対象のデータが表示される語句のパターン等>を入力
- 「詳細設定」>「これらのフレーズが発生する場所」:「カスタム範囲」を選択

範囲ボックスの指定後、先ほどのように、「保存してトレーニング」をクリックし、抽出器のトレーニングを行います。
このトレーニングによって、ラベル付き箇所と同様の「予測」がされた場合は、以前同様「評価」列に「検索条件」と表示され、異なる「予測」がされた場合には、「不一致」と表示されます。
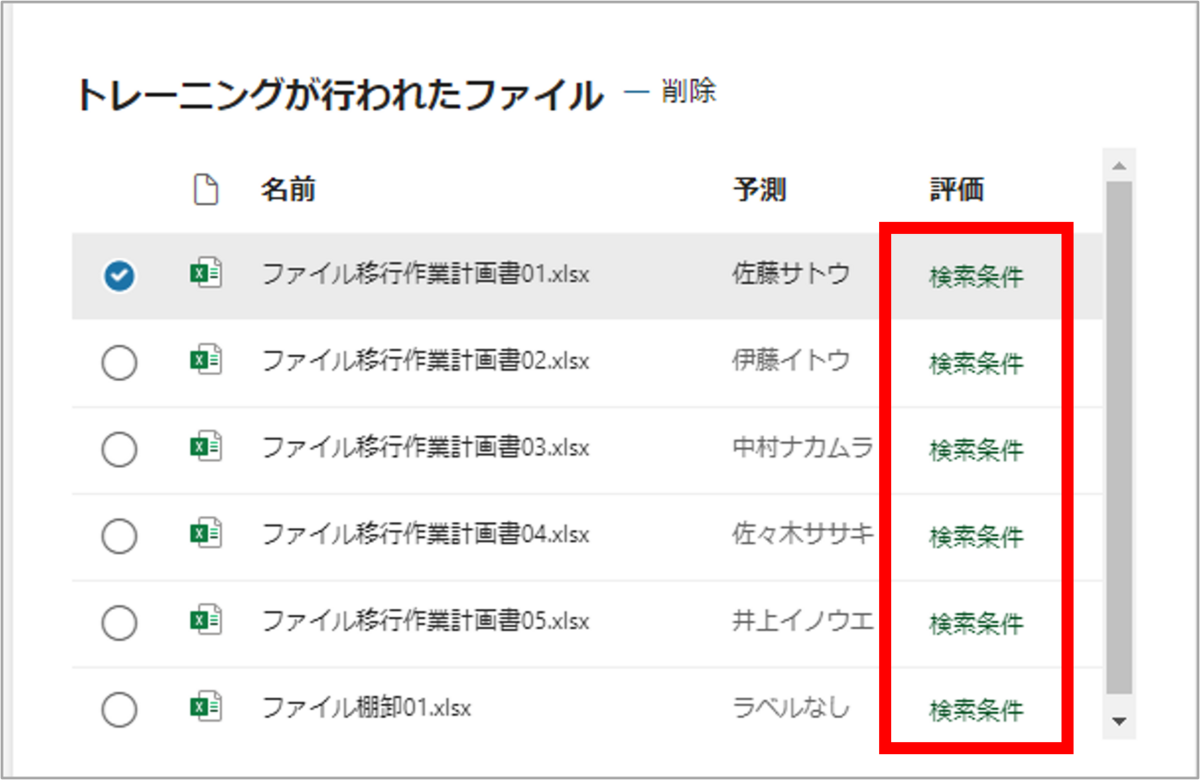
トレーニング後、精度が十分でない場合は、「テスト」タブで追加のサンプルファイルを対象にリトレーニングを行うことができます。
モデルに十分な精度が得られたら、「作業対応者名」用の抽出器の作成は完了です。
他の3つの抽出対象の抽出器も、上記の手順に沿って作成します。
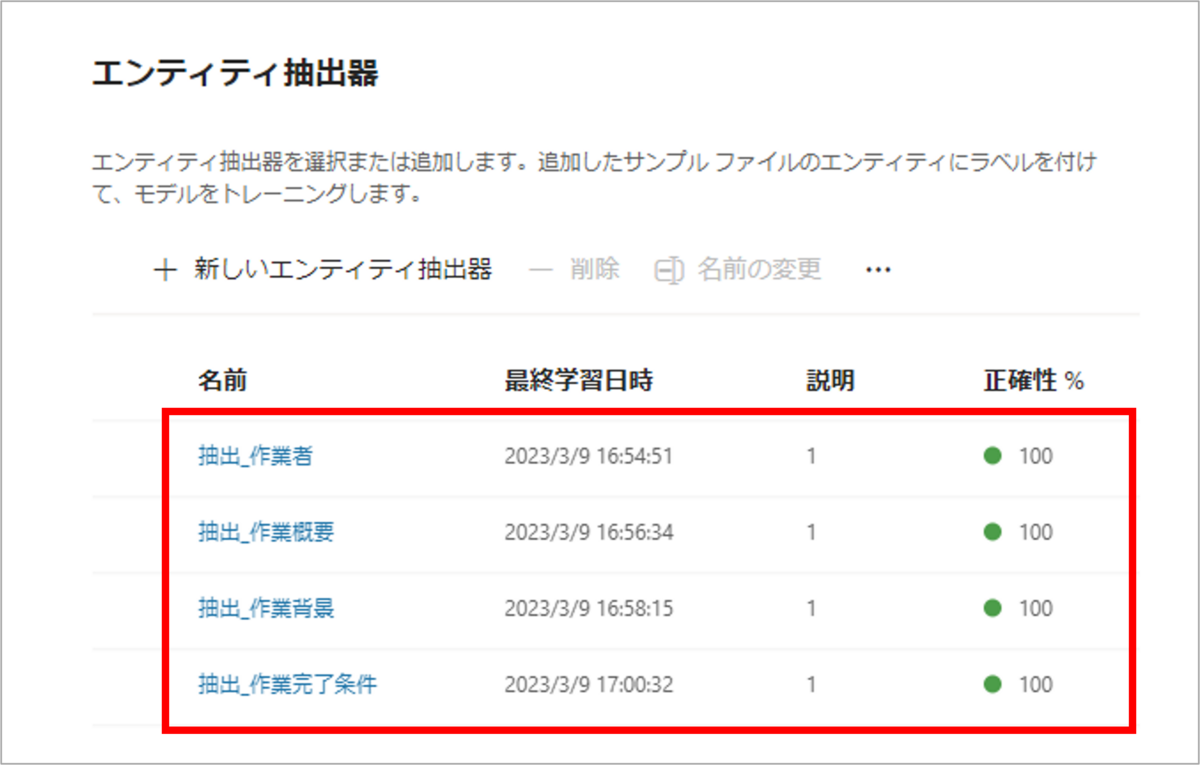
すべての抽出対象の抽出器作成が完了しましたら、モデルの準備は完了です。
モデル適用
作成したモデルを、メタデータを抽出したいドキュメントライブラリに適用します。*11
モデルのトレーニング用画面上の「モデルを適用」をクリック*12し、対象のドキュメントライブラリ(が存在するサイト)を選択します。
選択後、「追加する」をクリックすると、「列'Name'が存在しません。他のユーザーが削除した可能性があります。」の警告が表示されることがありますが、この警告表示は無視して問題ありません。

「追加する」をクリック後、適用先のドキュメントライブラリにアクセスすると、右上の「表示オプションの切り替え」にて、「<モデル名>」のビューが新しく追加されていることが確認できます。
また、追加されたビューに切り替えると、作成した抽出器に対応する列などが、以下のように左から順に追加されていることが確認できます。

- コンテンツ タイプ
- <抽出器名>
- 分類日
これで、ドキュメントライブラリへのモデル適用は完了です。
モデル実行
ファイルをドキュメントライブラリにアップロードして、ファイルのプロパティ追加が実際に自動化されるか、確認します。
モデルのトレーニングで使用したファイルとは異なるExcelファイルを、ドキュメントライブラリにアップロードします。
すると、ファイルのアップロードと併せて、「ファイルを分析しています。」と表示されますので、5分ほど待ちます。
5分後、ドキュメントライブラリ画面を更新すると、空欄だったプロパティが自動で追加されていることが確認できます。
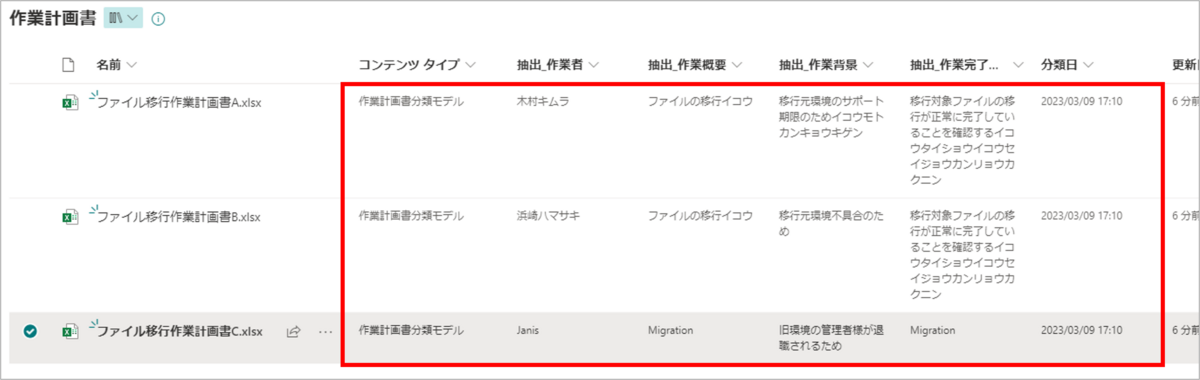
末尾に追加されるフリガナを削除したい、抽出した情報に抜け漏れなどがある場合は、各ファイルの「・・・」>「その他」>「プロパティ」から、適宜修正を行うこともできます。
おわりに
タイトルの通り、「ドキュメントライブラリのプロパティ追加を自動化」することはできましたが、いくつか課題も残りました。
- 漢字が含まれるメタデータについては、かなりの割合で末尾にフリガナが追加されてしまう
- 英語のセンテンスは、スペースによってトークンが変化してしまうため、抽出箇所がずれてしまう
- 書式テンプレートに変更があった場合、モデルを再トレーニングする必要がある
「1」については、日本語未対応故の問題でもありますが、自動化の使い勝手に著しく影響する内容であると思われます。
「2」については、以下の対策によって解消できる見込みですが、Excelファイルの性質上、文脈を分析することが難しいという問題は残ります。
- トレーニングデータ量を増やして、メタデータ抽出の精度を上げる
- 「抽出器」の「説明」における範囲ボックスを広げて、抽出範囲を拡げる
「3」については、書式テンプレートの変更だけでなく、トレーニングしたファイルとトークンの数が大きく異なる場合でも、モデルが機能しなくなる可能性があります。
ただ、上記デメリットを差し引いても、大量のドキュメント管理などのSPO運用シーンに合わせて、Microsoft Syntexを活用できる余地は大いにあると思います。
早期の日本語対応に期待しつつ、AI活用浸透の著しい昨今、SPOに関わる方々は、今後のSharePoint Syntexのアップデートを注視されてはいかがでしょうか。
*1:詳細は以下リンクを参照ください。
Microsoft Syntexの概要 - Microsoft Syntex | Microsoft Learn
*2:2023/03/15記事作成時点で日本語未対応となります。
*3:「https://」から始まる下記URLを直接入力することでもアクセスできます。
URL:<テナント名>.sharepoint.com/sites/ContentsCenter
*4:この名前が、モデル適用先のドキュメントライブラリ上のビュー名となります。
*5:「トレーニング用のファイルの例」下の「ライブラリから追加」をクリックでも同様です。
*6:4ファイル以上でもトレーニング自体は可能です。
*7:今回はネガティブのラベル付けをしたファイルが、正の予測として誤って予測されたため、精度83となっていますが、後続の「抽出器の作成とトレーニング」を行うと、負の予測として正しく予測し直され、精度100となることが確認できました。
*8:「エンティティ抽出器」下の「+新しいエンティティ抽出器」をクリックでも同様です。
*9:詳細は以下リンクを参照ください。
Microsoft Syntexの説明の種類 - Microsoft Syntex | Microsoft Learn
*10:ラベル付け画面上では、漢字のフリガナがランダムで単語の末尾に追加されたり、日付の表記がExcelファイル上の表記と異なって表示されたりしますが、日本語未対応による仕様のようです。
*11:ドキュメントライブラリ上から「分類と抽出」にてモデル適用可能ですが、今回は割愛します。
*12:「モデルが適用される場所」下の「+ライブラリの追加」をクリックでも同様です。

色部 晟洋(日本ビジネスシステムズ株式会社)
SharePoint Onlineサイト構築・Microsoft365移行等でプリセールス・PMを経験後、AI等の先端技術を扱う部門に異動。好きな映画は『風立ちぬ』です。
担当記事一覧