
はじめに
データを異なるサイトに同期したい場合に有効かつ便利な「Azure File Sync」の設計、構築、運用、トラブルシュートまでお役立ちな情報を全5回に渡りご紹介して参ります。
第2回目の本記事では、Azure File Syncのデータ同期の仕組みと機能についてご説明いたします。
第1回目の記事はこちらです:
データ同期のタイミング
前回記事にてご紹介しました通り、サーバーエンドポイントとクラウドエンドポイント間でデータを同期しますが、サーバーエンドポイント→クラウドエンドポイントと、クラウドエンドポイント→サーバーエンドポイントで同期のタイミングが異なります。
サーバーエンドポイント→クラウドエンドポイントのデータ同期
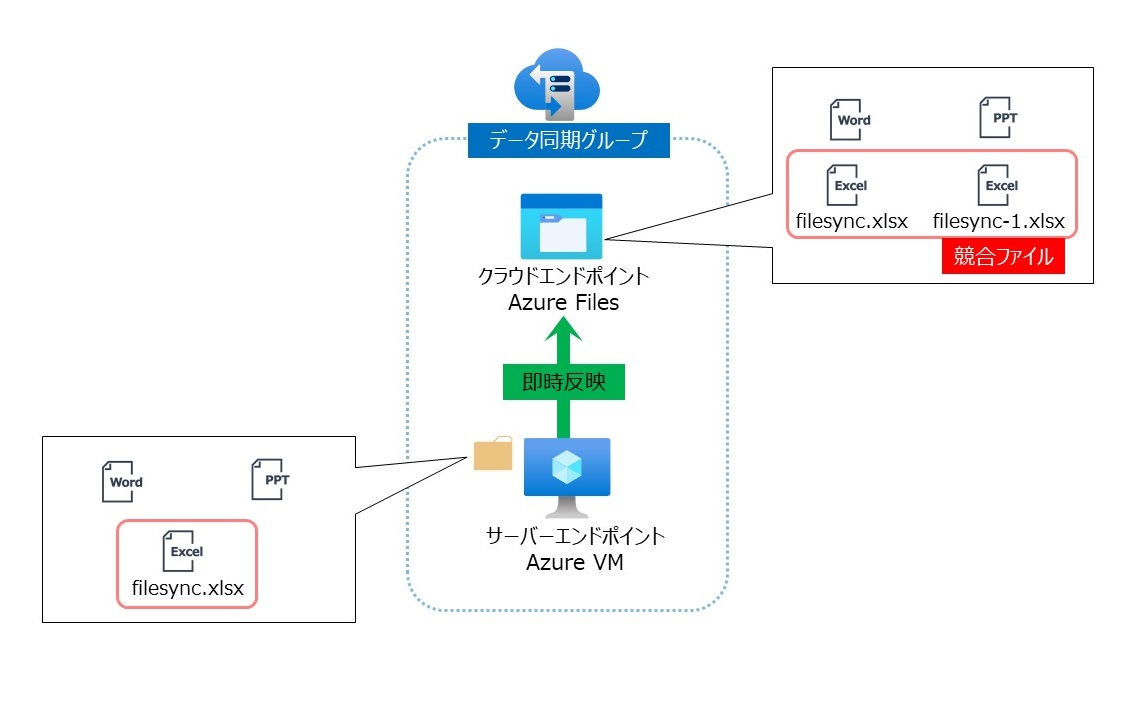
サーバーエンドポイントは即時反映のため、ファイルを作成、変更、削除をするとクラウドエンドポイント上にすぐに反映されます。
もし、サーバーエンドポイントが複数存在し、同じファイルが同時に変更された場合は両方の変更が保持され、競合した番号がファイル名に追加されます。
例)filesync.xlsxをほぼ同時に更新 → filesync.xlsx と filesync-1.xlsxが存在する
1つのファイルで100個まで競合ファイルが出来ます、100個以上になる場合は競合件数が99件にならない限りファイルの同期がされません。
クラウドエンドポイント→サーバーエンドポイントのデータ同期
クラウドエンドポイントは24時間に1度反映されます。ファイルを作成、変更、削除をしてもサーバーエンドポイント上で反映されるのは24時間に1度のタイミングです。
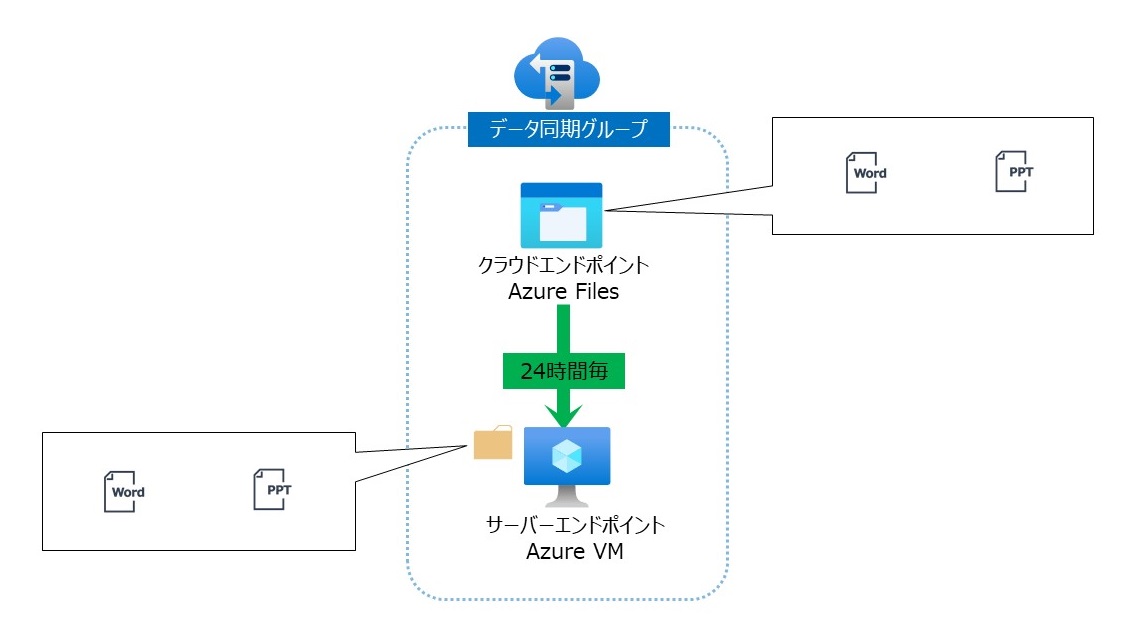 Azure File Syncには「変更検出ジョブ」がスケジューリングされており、ファイル共有内のフォルダ・ファイルをリストアップし同期するバージョンと比較するため、変更の検出はフォルダ・ファイル数が多いほど時間がかかるため、変更検出ジョブの実行タイミングが24時間以上かかる場合もあります。
Azure File Syncには「変更検出ジョブ」がスケジューリングされており、ファイル共有内のフォルダ・ファイルをリストアップし同期するバージョンと比較するため、変更の検出はフォルダ・ファイル数が多いほど時間がかかるため、変更検出ジョブの実行タイミングが24時間以上かかる場合もあります。
もし、Azure ファイル共有で変更されたファイルを直ちに同期したい場合はPowershellを実行しでデータの変更検出をします。
Install-module AzStorageSyncChangeDetection
Invoke-AzStorageSyncChangeDetection
-ResourceGroupName [リソースグループ]
-StorageSyncServiceName [ストレージ同期サービス名]
-SyncGroupName [同期グループ名]
-CloudEndpointName [クラウドエンドポイント名]
-DirectoryPath [ディレクトリパス名] ※
※当該パラメータを指定すると最大で10000個の変更項目を検出できます、指定しない場合は共有全体の変更を確認します。削除されたファイル、共有から移動されたファイル、削除後に同じ名前で作成したファイルの変更は検出いたしません。
サーバーエンドポイントの追加とデータ同期
ここで、サーバーエンドポイントをもう1つ増やすケースについて解説いたします。
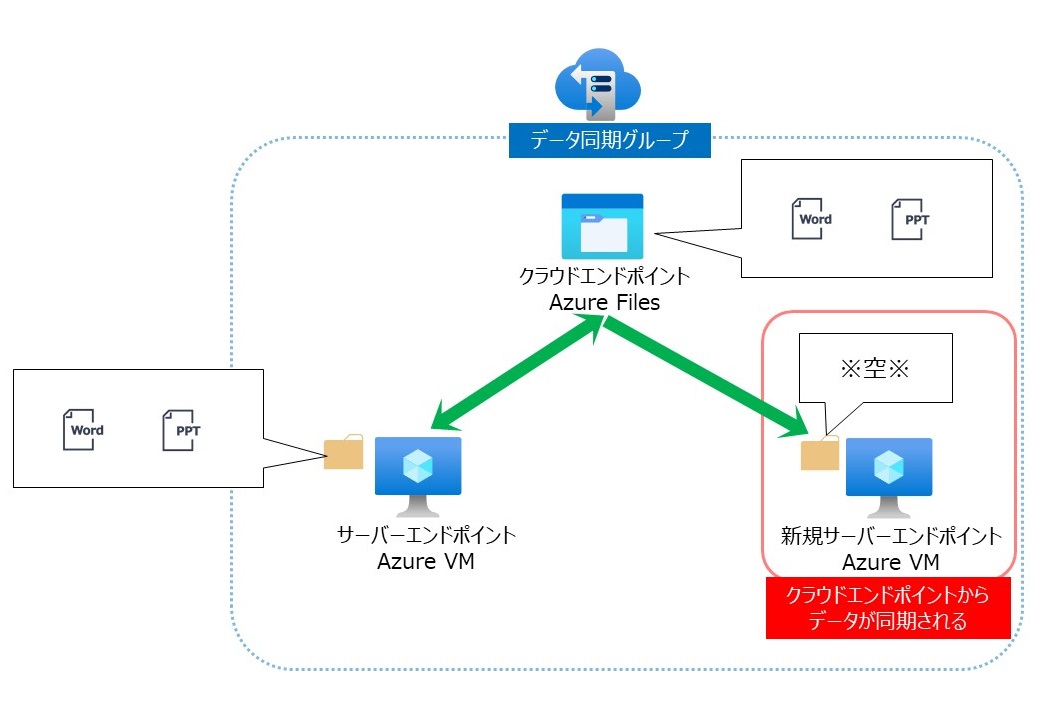
既にサーバーエンドポイントにもクラウドエンドポイントにもデータが同期されている状態で、データ同期グループにサーバーエンドポイントを追加するとして、
新規サーバーエンドポイント上のディスクは空の状態です。
「まさか、空の状態で旧サーバーエンドポイントとクラウドエンドポイントに同期してデータ消失!?」
...ということはございませんのでご安心下さい。
クラウドエンドポイントから新サーバーエンドポイントへ同期が実施されます。
つまり、クラウドエンドポイントのデータがマスター扱いとなります。
もし任意でクラウドエンドポイントもしくは旧サーバーエンドポイント上からデータを全部削除した場合は、新サーバーエンドポイントにも空の状態が同期されてしまいどこにもデータが無くなってしまいますのでご注意下さい。
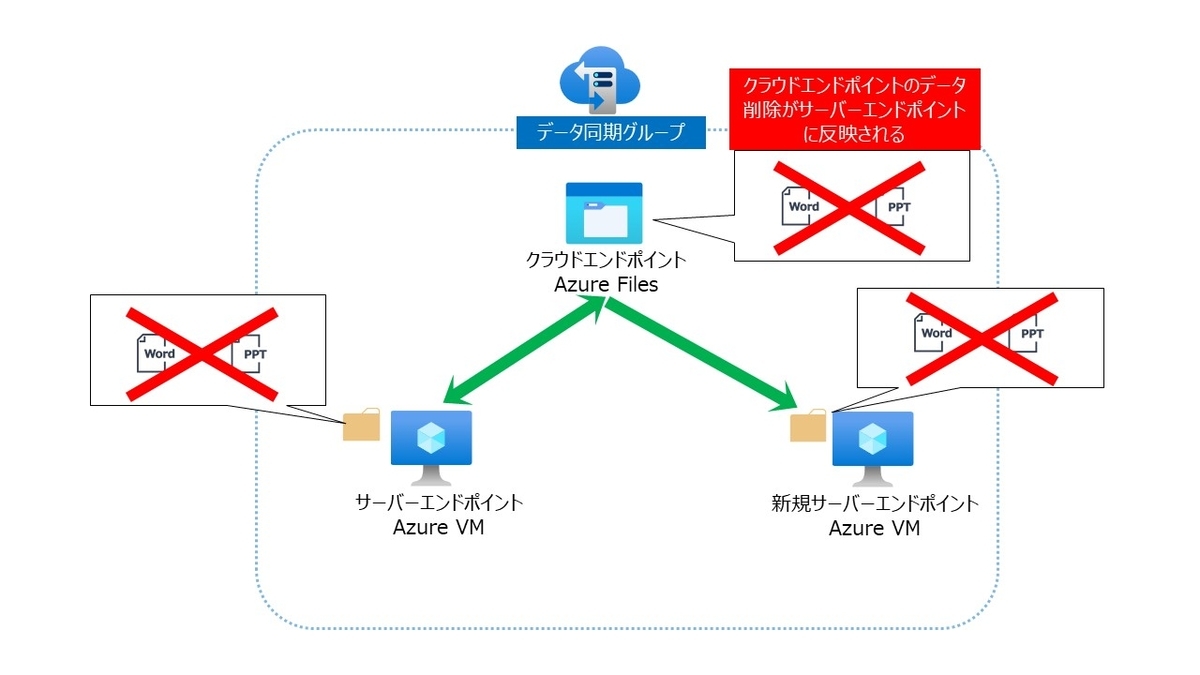
其ノ壱の記事で何故、クラウドエンドポイントがデータ同期グループ内で1つなのか本記事で解明するとお話しましたが、理由はクラウドエンドポイント上のデータがマスターとなり、複数のサーバーエンドポイントとも互いにデータ同期をするためです。
サーバーエンドポイント1のデータ更新→クラウドエンドポイントに同期→サーバーエンドポイント2に同期
もしくは、クラウドエンドポイントのデータ更新→サーバーエンドポイント1に同期、サーバーエンドポイント2に同期、といった流れです。
初期同期について
晴れてデータ同期グループを構成後、データを最初に同期する際のお話です。
デフォルトのマージまたはAuthoritative upload(権限のあるアップロード)の2つの動作があります。
マージ
クラウドエンドポイント上が空である前提の設定です。前項でご説明した空ディスクのサーバーエンドポイントを追加した場合の動作について問題無くデータ同期ができます。
Authoritative upload(権限のあるアップロード)
要は差分を同期します。既にデータが存在する状態で選択する項目で、Azure Data Boxを用いたオフライン移行での利用が挙げられます。
Azure Data BoxのデータがクラウドエンドポイントとなるAzure Filesに保存された状態で、サーバーエンドポイントの更新分をクラウドエンドポイント上のデータと同期します。新規と更新はサーバーエンドポイントからクラウドエンドポイントに同期され、サーバーエンドポイントに存在しない、即ち削除済みのデータはクラウドエンドポイント上から削除されます。
サーバーエンドポイントとクラウドエンドポインドと両方存在するデータかつフォルダ名が変更されていると、クラウドエンドポイント上から削除され、サーバーエンドポイントから再度同期されます。そのため、サーバーエンドポイント側のフォルダ名やフォルダ構成変更は辞めておくのが無難です。
クラウド階層化について
クラウド階層化とは、サーバーエンドポイント上のディスクにデータを配置せず、データの実態をクラウドエンドポイント上に保管します。
OneDriveでPCにファイルをダウンロードするようなものとお考え下さい。
よく使うファイルはサーバーエンドポイントのディスクに保管され、あまり使わないファイルはファイル名が表示はされているもののクラウドエンドポイントに保管され必要な時にダウンロードされます、この操作を「呼び戻し」と言います。
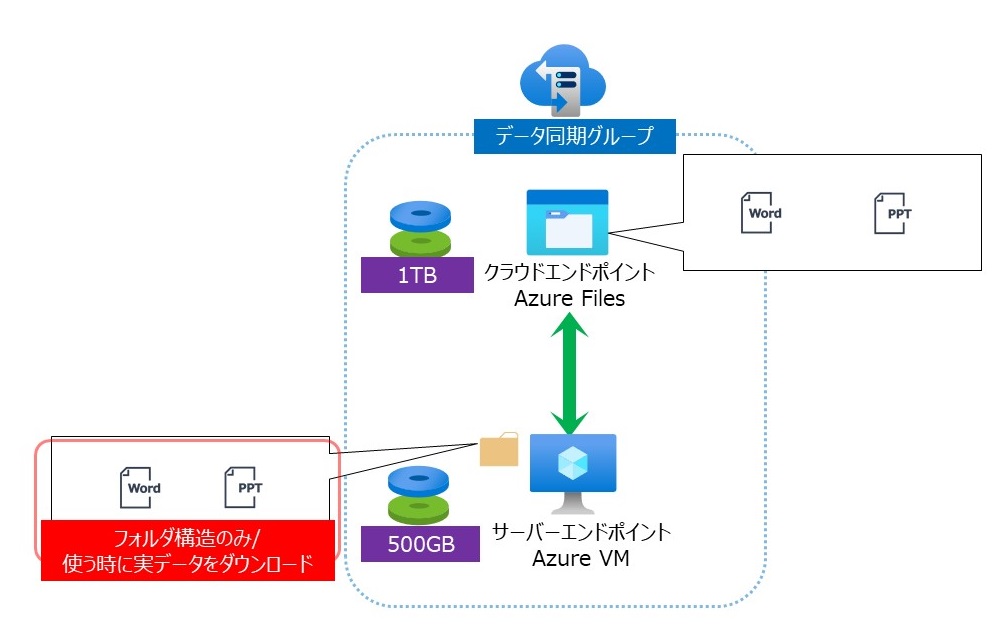
クラウド階層化を有効化するにあたり、あまり使わないファイルをクラウドエンドポイントに持っていくタイミングのポリシーが2つあります。
ボリュームの空き領域ポリシー
サーバーエンドポイントのボリュームの空き容量を割合(%)で指定し、使用されている容量をクラウド階層化します。
日付ポリシー
最終アクセス日の指定日以降が階層化されます。ボリュームの空き領域ポリシーが優先されるため、日付ポリシー分の空き容量が無い場合は最もアクセスの少ないファイルの階層化がされます。
初期ダウンロードについて
サーバーエンドポイントを同期グループに追加した際に、3つのクラウドエンドポイントからのデータダウンロード方法があります。
最初に名前空間をダウンロードします
名前空間つまりフォルダやファイル名がダウンロードされ、データがダウンロードされます。クラウド階層化が無効の場合は既定の設定です。
名前空間のみダウンロードします
クラウドエンドポイントのフォルダ構造をダウンロードします、こちらは後述するクラウド階層化で既定の設定です。
ファイルは完全にダウンロードされたときに表示されます
データをすべてダウンロード後、サーバー上のフォルダに表示します。クラウド階層化では出来ない設定です。
まとめ
長文となりましたが、以下5点が要点です。押さえておけば設計時に、また、トラブルシュート時にお役に立てるのではないかと思います。
- サーバーエンドポイントからクラウドエンドポイントへの同期は即時反映
クラウドエンドポイントからサーバーエンドポイントへの同期は24時間に1度、Powershellで即時も可能 - クラウド階層化によりサーバーエンドポイントのディスク容量の節約が可能
- 初期同期はデータ無しの状態であればデフォルト値で問題なし、例外としてAzure Data Box利用時などは変更する
- クラウド階層化の有効化、無効化により初期ダウンロードの設定が異なる

熊田 沙代(日本ビジネスシステムズ株式会社)
かれこれサーバーエンジニア歴10数年。WindowsServer/Linux/OSS/vSphere/Hyper-Vと器用貧乏に経験し、現在はAzure IaaS/PaaSをメインとしたアーキテクトを担当してます。TEAM NACSのファンです。
担当記事一覧