
本記事ではAzure AI Searchを使ってマルチモーダルRAG(Retrieval-Augmented Generation、検索拡張生成)基盤を、ドキュメントレイアウトスキルと、GenAI プロンプトスキルを使用して作成します。
今回は、総務省がPDFで公開している情報通信白書を題材に、テキストだけでなく画像(図表)からの情報も活用して質問に答える仕組みを解説します。
概要
以下の参考リポジトリのコードに沿って、マルチモーダルRAGの内容を解説します。
基本はAI Searchを用いてマルチモーダルRAGの基盤となるインデックスの作成を目指します。また記事の後半で、実際に作成されたインデックスの例や、回答生成結果を示します。
GenAI Prompt skill (Custom Skill) learn.microsoft.com
Document Layout skill (Resource Skill) learn.microsoft.com
準備
リソースの準備
Azure上で、以下のリソースをデプロイします。
- ストレージアカウント
- pdfdata (PDFをアップロードするコンテナ)
- imagedata(切り出した画像を保管するコンテナ)
- AI Search
- AI Foundry
- Azure OpenAI Service
- GPT-4o
- text-embedding-3-small
IAM設定
AI SearchのIDを有効化しておく必要があります。これはカスタムスキルから、各AzureリソースにEntr ID経由でアクセスするためです。
具体的にはストレージアカウントとAI Foundryに、AI Searchからアクセスできる権限をつけておきます。(今回は共同作成者を付与しました)
パッケージのimport
以下の通りimportします。
import base64, json, os, time, uuid import openai from openai import AzureOpenAI from pathlib import Path from typing import List from datetime import timedelta from azure.core.credentials import AzureKeyCredential from azure.storage.blob import BlobServiceClient, ContentSettings from azure.search.documents import SearchClient from azure.search.documents.models import VectorizedQuery from azure.search.documents.indexes import ( SearchIndexClient, SearchIndexerClient ) from azure.search.documents.indexes.models import ( AIServicesAccountIdentity,AIServicesAccountKey, AzureOpenAIEmbeddingSkill, ComplexField, ChatCompletionSkill, DocumentIntelligenceLayoutSkill, DocumentIntelligenceLayoutSkillChunkingProperties, FieldMapping, HnswAlgorithmConfiguration, IndexingParameters, IndexingParametersConfiguration, IndexProjectionMode, MergeSkill, NativeBlobSoftDeleteDeletionDetectionPolicy, SearchableField, SearchField, SearchFieldDataType, SearchIndex, SearchIndexer, SearchIndexerDataContainer, SearchIndexerDataSourceType, SearchIndexerDataSourceConnection, SearchIndexerIndexProjection, SearchIndexerIndexProjectionSelector, SearchIndexerIndexProjectionsParameters, SearchIndexerKnowledgeStore, SearchIndexerKnowledgeStoreFileProjectionSelector, SearchIndexerKnowledgeStoreProjection, SearchIndexerSkillset, ShaperSkill, SimpleField, SplitSkill, VectorSearch, VectorSearchAlgorithmConfiguration, VectorSearchProfile, InputFieldMappingEntry, OutputFieldMappingEntry, )
パラメータ設定
以下のようにパラメータを設定します。
# Azure Storage Account AZURE_STORAGE_CONN_STR = "" STORAGE_CONTAINER_NAME = "pdfdata" STORAGE_KS_CONTAINER_NAME = "imagedata" LOCAL_PDF = "data/00zentai.pdf" # Azure AI Search AZURE_SEARCH_ENDPOINT = "" # AI Search エンドポイントURL AZURE_SEARCH_ADMIN_KEY = "" # AI Search 管理キー AZURE_SEARCH_INDEX_NAME = "pdf-index" # 作成・使用するインデックス名 # Azure AI Foundry AI_SERVICES_ENDPOINT = "" # Azure AI Foundry エンドポイントURL AI_SERVICES_API_KEY = "" # Azure AI Foundry 管理キー # Azure OpenAI Service AZURE_OPENAI_ENDPOINT = "" # Azure OpenAIリソース エンドポイントURL AZURE_OPENAI_API_KEY = "" # Azure OpenAI APIキー EMBEDDING_MODEL_DEPLOYMENT = "text-embedding-3-small" # デプロイ済みEmbeddingモデル名 CHAT_MODEL_DEPLOYMENT = "gpt-4o" # デプロイ済みChatモデル名
ファイルアップロード
アップロードするPDFファイルには、令和6年情報通信白書を使用します。 www.soumu.go.jp
PDFデータをストレージアカウントのコンテナ上に配置します。ここではpdfdataコンテナのdata/00zentai.pdfに配置します。
以下を実行して、後にインデクサーに読み込ませるデータソースの情報を定義しておきます。
ds_container = SearchIndexerDataContainer(name=f"{コンテナ名}") data_source = SearchIndexerDataSourceConnection( name="local-pdf-datasource", type=SearchIndexerDataSourceType.AZURE_BLOB, connection_string=f"ResourceId=/subscriptions/{サブスクリプションID}/resourceGroups/{リソースグループ名}/providers/Microsoft.Storage/storageAccounts/{ストレージアカウント名};", container=ds_container, data_deletion_detection_policy=NativeBlobSoftDeleteDeletionDetectionPolicy() )
インデックスのフィールド定義
作成するインデックスのフィールドを、以下の通り定義します。
# 1. vectorSearch 構成 vector_search = VectorSearch( algorithms=[ HnswAlgorithmConfiguration( # kind='hnsw' はデフォルト name="vec_algo", parameters={"metric": "cosine"} ) ], vectorizers=[ AzureOpenAIVectorizer( vectorizer_name="vec-vectorizer", parameters=AzureOpenAIVectorizerParameters( resource_url=AZURE_OPENAI_ENDPOINT, deployment_name=EMBEDDING_MODEL_DEPLOYMENT, model_name=EMBEDDING_MODEL_DEPLOYMENT, ), ) ], profiles=[ VectorSearchProfile( name="vec_profile", algorithm_configuration_name="vec_algo", vectorizer_name="vec-vectorizer", algorithm_configuration_name="vec_algo" ) ] ) # 2. フィールド定義 fields = [ # 主キー SearchField(name="id", type=SearchFieldDataType.String, key=True, analyzer_name="keyword"), # 親子関連付け用キー(テキスト行) SearchField(name="text_document_id", type=SearchFieldDataType.String, searchable=False, filterable=True, hidden=False, sortable=False, facetable=False, filterable=True), # 親子関連付け用キー(画像行) SearchField(name="image_document_id", type=SearchFieldDataType.String, searchable=False, filterable=True, hidden=False, sortable=False, facetable=False), # 検索対象テキスト SearchableField(name="content_text", type=SearchFieldDataType.String, searchable=True, filterable=True, hidden=False, sortable=True, facetable=True), # 画像パスなど SearchField(name="content_path", type=SearchFieldDataType.String, searchable=False, filterable=True, hidden=False, sortable=False, facetable=False), # PDF名 SearchField(name="document_title", type=SearchFieldDataType.String, searchable=True, filterable=True, hidden=False, sortable=True, facetable=True), # ベクトル列 SearchField( name="content_embedding", type=SearchFieldDataType.Collection(SearchFieldDataType.Single), searchable=True, vector_search_dimensions=1536, vector_search_profile_name="vec_profile" ), ComplexField( name="locationMetadata", fields=[ SimpleField( name="pageNumber", type=SearchFieldDataType.Int32, searchable=False, filterable=True, hidden=False, sortable=True, facetable=True, ), SimpleField( name="boundingPolygons", type=SearchFieldDataType.String, searchable=False, hidden=False, filterable=False, sortable=False, facetable=False, ), ], ), ] # 3. インデックス index = SearchIndex( name=AZURE_SEARCH_INDEX_NAME, fields=fields, vector_search=vector_search )
スキーマを以下の通りまとめました。
| スキーマ | 説明 | 値 |
|---|---|---|
| id | 自動で定義されるrowのID | 自動採番 |
| text_document_id | 切り出したtext_sectionsのID | 自動採番 |
| image_document_id | 切り出したnormalized_imagesのID | 自動採番(画像があるときのみ) |
| content_text | OCR文字列(text_sections)の生値 | OCR文字列 |
| content_path | 画像(normalized_images)のパス ※new_normalized_imagesを使用 |
カスタムスキルで切り出したAI Search内のフルパス |
| document_title | PDFの名称 | 投入ファイル名に基づく |
| content_embedding | OCR文字列(text_sections)のベクトル | text-embeddings-3のベクトル |
| locationMetadata/pageNumber | 画像(normalized_images)のページ番号 | Int文字列 |
| locationMetadata/boundingPolygons | 検出したsectionの座標 | 文字の場合は全てのparagraphの座標 画像の場合は1枚分の座標が代入される |
インデクサー定義
インデクサー動作概要
インデクサーの挙動は大まかに以下の通りとなります。
Document Intelligenceにより解析を行いOCR文字列と画像を抽出、これらに対してそれぞれAIモデルで処理を行い、マルチモーダルな検索が可能になるようインデックス化する仕組みになっています。
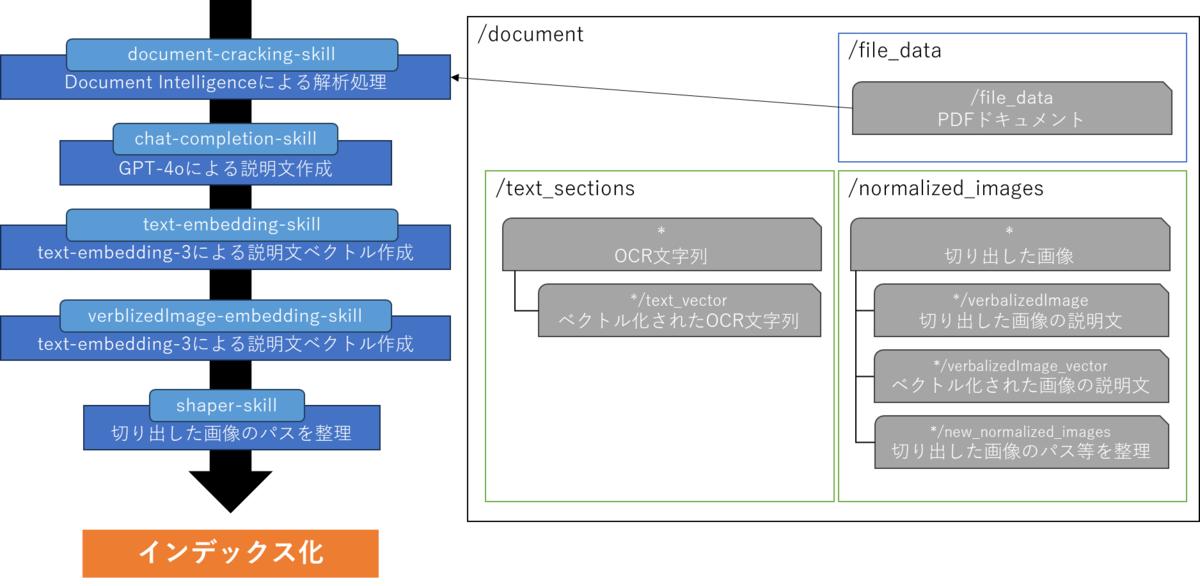
Document Intelligence解析
データソースから読み込んだPDFをDocument Intelligenceで解析します。
layout_skill = DocumentIntelligenceLayoutSkill(
name="document-cracking-skill",
description="Document Intelligence skill for document cracking",
context="/document",
output_mode="oneToMany",
output_format="text",
extraction_options=["images", "locationMetadata"],
markdown_header_depth="",
chunking_properties=DocumentIntelligenceLayoutSkillChunkingProperties(
unit="characters",
maximum_length=2000,
overlap_length=200,
),
inputs=[InputFieldMappingEntry(name="file_data", source="/document/file_data")],
outputs=[
OutputFieldMappingEntry(name="text_sections", target_name="text_sections"),
OutputFieldMappingEntry(
name="normalized_images", target_name="normalized_images"
),
],
)
マルチモーダルLLMモデルを使用した説明文生成
解析した/document/normalized_imagesの説明文を生成して、生成した文章を/document/normalized_images/*/verbalizedImageに格納します。
caption_skill = ChatCompletionSkill(
name="chat-completion-skill",
uri=f"{AZURE_OPENAI_ENDPOINT}/openai/deployments/gpt-4o/chat/completions?api-version=2025-04-01-preview",
timeout=timedelta(minutes=1),
context="/document/normalized_images/*",
inputs=[
InputFieldMappingEntry(
name="systemMessage",
source='=\'You are tasked with generating concise, accurate descriptions of images, figures, diagrams, or charts in documents. The goal is to capture the key information and meaning conveyed by the image without including extraneous details like style, colors, visual aesthetics, or size.\n\nInstructions:\nContent Focus: Describe the core content and relationships depicted in the image.\n\nFor diagrams, specify the main elements and how they are connected or interact.\nFor charts, highlight key data points, trends, comparisons, or conclusions.\nFor figures or technical illustrations, identify the components and their significance.\nClarity & Precision: Use concise language to ensure clarity and technical accuracy. Avoid subjective or interpretive statements.\n\nAvoid Visual Descriptors: Exclude details about:\n\nColors, shading, and visual styles.\nImage size, layout, or decorative elements.\nFonts, borders, and stylistic embellishments.\nContext: If relevant, relate the image to the broader content of the technical document or the topic it supports.\n\nExample Descriptions:\nDiagram: "A flowchart showing the four stages of a machine learning pipeline: data collection, preprocessing, model training, and evaluation, with arrows indicating the sequential flow of tasks."\n\nChart: "A bar chart comparing the performance of four algorithms on three datasets, showing that Algorithm A consistently outperforms the others on Dataset 1."\n\nFigure: "A labeled diagram illustrating the components of a transformer model, including the encoder, decoder, self-attention mechanism, and feedforward layers."\'',
),
InputFieldMappingEntry(
name="userMessage",
source="='Please describe this image.'",
),
InputFieldMappingEntry(
name="image",
source="/document/normalized_images/*/data",
),
],
outputs=[
OutputFieldMappingEntry(name="response", target_name="verbalizedImage")
],
)
注釈:プロンプト・プログラムは次のリポジトリのものを引用しています。 github.com
Text-To-Vector(OCR文字列)
Document Intelligenceで解析した/document/text_sectionsをベクトル化して、ベクトルを/document/text_sections/*/text_vectorに格納します。
embedding_skill = AzureOpenAIEmbeddingSkill(
name="text-embedding-skill",
context="/document/text_sections/*",
inputs=[
InputFieldMappingEntry(
name="text", source="/document/text_sections/*/content"
)
],
outputs=[OutputFieldMappingEntry(name="embedding", target_name="text_vector")],
resource_url=AZURE_OPENAI_ENDPOINT,
deployment_name=EMBEDDING_MODEL_DEPLOYMENT,
dimensions=1536,
model_name=EMBEDDING_MODEL_DEPLOYMENT,
)
Text-To-Vector(マルチモーダルLLMモデル生成の説明文)
/document/normalized_images/*/verbalizedImage(画像説明文)をベクトル化して、/document/normalized_images/*/verbalizedImage_vectorに格納します。
embedding_skill_vi = AzureOpenAIEmbeddingSkill(
name="verblizedImage-embedding-skill",
context="/document/normalized_images/*",
inputs=[
InputFieldMappingEntry(
name="text", source="/document/normalized_images/*/verbalizedImage"
)
],
outputs=[
OutputFieldMappingEntry(
name="embedding", target_name="verbalizedImage_vector"
)
],
resource_url=AZURE_OPENAI_ENDPOINT,
deployment_name=EMBEDDING_MODEL_DEPLOYMENT,
dimensions=1536,
model_name=EMBEDDING_MODEL_DEPLOYMENT,
)
画像情報の整理
切り出してきた画像(/document/normalized_images/*)の情報を整理して、/document/normalized_images/*/new_normalized_imagesに格納し、AI Searchのパスを用意します。
shaper_skill = ShaperSkill(
name="shapr-skill",
context="/document/normalized_images/*",
inputs=[
InputFieldMappingEntry(
name="normalized_images",
source="/document/normalized_images/*",
inputs=[],
),
InputFieldMappingEntry(
name="imagePath",
source=f"='{STORAGE_KS_CONTAINER_NAME}/'+$(/document/normalized_images/*/imagePath)",
inputs=[],
),
],
outputs=[
OutputFieldMappingEntry(name="output", target_name="new_normalized_images")
],
)
スキルセットの統合
上記で定義したスキルセットやデータとインデックスのマッピングを定義します。
documentIntelligenceAuth = AIServicesAccountKey(
key=AI_SERVICES_API_KEY,
subdomain_url=AI_SERVICES_ENDPOINT
)
skillset = SearchIndexerSkillset(
name="layout-skillset",
skills=[
layout_skill,
caption_skill,
embedding_skill,
embedding_skill_vi,
shaper_skill
],
index_projection=SearchIndexerIndexProjection(
selectors=[
SearchIndexerIndexProjectionSelector(
target_index_name=AZURE_SEARCH_INDEX_NAME,
source_context="/document/text_sections/*",
parent_key_field_name="text_document_id",
mappings=[
InputFieldMappingEntry(
name="content_embedding",
source="/document/text_sections/*/text_vector",
),
InputFieldMappingEntry(
name="content_text",
source="/document/text_sections/*/content",
),
InputFieldMappingEntry(
name="locationMetadata",
source="/document/text_sections/*/locationMetadata",
),
InputFieldMappingEntry(
name="document_title", source="/document/document_title"
), ],
),
SearchIndexerIndexProjectionSelector(
target_index_name=AZURE_SEARCH_INDEX_NAME,
source_context="/document/normalized_images/*",
parent_key_field_name="image_document_id",
mappings=[
InputFieldMappingEntry(
name="content_embedding",
source="/document/normalized_images/*/verbalizedImage_vector",
),
InputFieldMappingEntry(
name="content_text",
source="/document/normalized_images/*/verbalizedImage",
),
InputFieldMappingEntry(
name="content_path",
source="/document/normalized_images/*/new_normalized_images/imagePath",
),
InputFieldMappingEntry(
name="locationMetadata",
source="/document/normalized_images/*/locationMetadata",
),
InputFieldMappingEntry(
name="document_title", source="/document/document_title"
),
],
),
],
parameters=SearchIndexerIndexProjectionsParameters(
projection_mode=IndexProjectionMode.SKIP_INDEXING_PARENT_DOCUMENTS
),
),
cognitive_services_account=documentIntelligenceAuth,
knowledge_store=SearchIndexerKnowledgeStore(
storage_connection_string=AZURE_STORAGE_CONN_STR,
projections=[
SearchIndexerKnowledgeStoreProjection(
files=[
SearchIndexerKnowledgeStoreFileProjectionSelector(
storage_container=STORAGE_KS_CONTAINER_NAME,
source="/document/normalized_images/*",
)
]
)
],
),
)
構築
上記設定した内容をRunします。
# インデクサ定義 indexer=SearchIndexer( name="layout-indexer", description="Indexer to index documents and generate embeddings", data_source_name=data_source.name, target_index_name=index.name, skillset_name=skillset.name, parameters=IndexingParameters( batch_size=1, configuration=IndexingParametersConfiguration( data_to_extract="contentAndMetadata", allow_skillset_to_read_file_data=True, query_timeout=None, ), ), field_mappings=[ FieldMapping( source_field_name="metadata_storage_name", target_field_name="document_title", ), ], ) # リソース作成&実行 cred = AzureKeyCredential(AZURE_SEARCH_ADMIN_KEY) index_client = SearchIndexClient(AZURE_SEARCH_ENDPOINT, cred) indexer_client = SearchIndexerClient(AZURE_SEARCH_ENDPOINT, cred) index_client.create_or_update_index(index) indexer_client.create_or_update_data_source_connection(data_source) indexer_client.create_or_update_skillset(skillset) indexer_client.create_or_update_indexer(indexer) print("Indexer running …") indexer_client.run_indexer(indexer.name) # 進行状況を簡易ポーリング while True: status = indexer_client.get_indexer_status(indexer.name) if status.last_result and status.last_result.status in ("success", "transientFailure", "failure"): print("Indexer finished with status:", status.last_result.status) if status.last_result.error_message: print(status.last_result.error_message) break time.sleep(10)
検索用関数の準備
実際に検索する際のサンプル用関数を用意します。
client = AzureOpenAI(
api_key=AZURE_OPENAI_API_KEY,
azure_endpoint=AZURE_OPENAI_ENDPOINT,
api_version="2025-04-01-preview" # デプロイ時に選んだバージョン
)
def vector_search(query: str, k: int = 5):
vec = client.embeddings.create(
model=EMBEDDING_MODEL_DEPLOYMENT, input=query
).data[0].embedding
vector_query = VectorizedQuery(vector=vec, k_nearest_neighbors=3, fields="content_embedding")
docs = search_client.search(
search_text=query,
vector_queries=[vector_query],
top=k)
return docs
docs = vector_search(user_query)
実際の結果
ストレージアカウント
Document Intelligenceで解析した結果、抽出された画像はストレージアカウントに格納されています。
検索&回答生成
上記のプログラムでインデックスを構築して検索結果上位5件を取得し、GPT-4oでプロンプトを組んで回答生成を実施しました。
質問
カチャカの見た目を説明して
検索結果(上位1件目)
{ "@search.score": 6.836912, "id": "(ID略)_text_sections_108", "text_document_id": "(ID略)", "image_document_id": null, "content_text": "活用の現状·新たな潮流 第2節図表 Ⅰ-5-2-8 実証実験イメージdocomo MEC MECダイレクト™M (大分)5G大容量データ (映像·音声·ロホット制御)手術快償手術映像(リモート側)オペレーションユニットリアルタイムでの遠隔手術支援サージョンコックピット 《遠隔操作用》サージョンコックピットリモート側 (熟練医師)約500km東京ローカル側 (若手医師)神戸(出典)神戸大学*32イ 家庭用ロボット (Preferred Robotics)2023年2月に Preferred Roboticsは、専用のキャスター付きシェルフを自動運転で運んでくる 家庭用ロボット「カチャカ」を発表。自律移動ロボット「カチャカ」は、キャスター付きの専用 シェルフ(ワゴン)の下に潜り込んでドッキングし、目的の場所に移動させたり、元の位置に戻し たりできるという家具移動用のロボットで、音声認識に対応しているため、声により指示をするこ とができる*33 (図表Ⅰ-5-2-9)。家庭内のほか、法人での利用としては歯医者や工場、飲食店での 利用も増えており、例えば人手不足が深刻な歯医者においては患者に利用した機材を滅菌室へ運ぶ 等の工程をカチャカが担うことで、医者がより付加価値の高い業務や患者とのコミュニケーション に時間を割けるようになったほか、工場等においては部品の搬送等に耐久性やセンサを業務ユース に特化した「kachaka Pro」の利用がされている。図表 Ⅰ-5-2-9 カチャカ1 家具認識センサー 家具のドッキング位置を検出2 ドッキングユニット 家具と連結してパワフルに運ぶ(20kgまで)3 LEDリング 光でカチャカの状態を知らせる4 フロントカメラ 画像認識のための情報を取得5 レーザーセンサー 周囲の障害物との距離をセンシング6 3Dセンサー 家具や人、物との距離をセンシング(出典) Preferred Robotics「人の指示で家具を動かすスマートファニチャー·プラットフォーム「カチャカ」2023年5月17日(水)新発売」*34第5章 デジタルテクノロジーの浸透*32 国立大学法人神戸大学,「東京-神戸間(約500km)で商用の5G SA を活用し遠隔地からロボット手術を支援する実証実験に成功」2023 年2月1日,<https://www.kobe-u.ac.jp/ja/news/article/2023_02_01_01/index.html> (2024/3/28参照)*33 Impress Watch「棚を運ぶ·片付ける。新しい家庭用ロボット「カチャカ」登場」2023年2月1日,<https://www.watch.impress. co.jp/docs/news/1475076.html> (2024/3/6参照)*34 Preferred Robotics,「人の指示で家具を動かすスマートファニチャー·プラットフォーム「カチャカ」2023年5月17日(水)新発売」 2023年5月12日,<https://www.pfrobotics.jp/news/fYD7X2FW> (2024/3/28参照)令和6年版 情報通信白書 第Ⅰ部 85", "content_path": null, "document_title": "00zentai.pdf", "locationMetadata": { "pageNumber": 99, "boundingPolygons": "(paragraphの座標省略)" } }
回答
カチャカは、キャスター付きの専用シェルフ(ワゴン)を自動運転で移動させる家庭用ロボットです。専用シェルフの下に潜り込んでドッキングし、目的地まで移動させたり元の位置に戻したりします。訪問や音声認識に対応しており、家具移動を効率化する機能を持っています。外観の特徴としては以下の点が挙げられます: 1. 家具認識センサー - 家具のドッキング位置を検出。 2. ドッキングユニット - 家具と連結して最大20kgの物体を運搬可能。 3. LEDリング - 光でロボットの状態を知らせる。 4. フロントカメラ - 画像認識情報を取得。 5. レーザーセンサー - 障害物との距離を測定。 6. 3Dセンサー - 家具や人、物との距離を認識。
資料の85ページ目(PDF 99ページ目)の資料を基に回答を生成させる課題でしたが、意図した通りの回答が実現されています。
一方で、画像としてはnormalized_images_91.jpgという名前で以下のようなものが保存されていましたが、回答生成には使用できませんでした。AI Searchのインデックスには情報として登録されていたものの、今回の検索クエリにはヒットしなかったためです。
抽出された画像
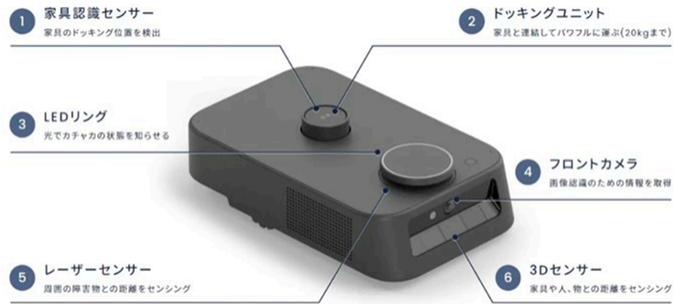
登録されていたインデックス(今回はヒットせず)
{ "@search.score": 2.9090638, "id": "(ID略)_normalized_images_91", "text_document_id": null, "image_document_id": "(ID略)", "content_text": "The image depicts a labeled diagram of a robotic device highlighting its six key components: \n\n1. **Furniture Recognition Sensor**: Detects docking points on furniture. \n2. **Docking Unit**: Facilitates powerful attachment to furniture, supporting loads up to 20 kg. \n3. **LED Ring**: Indicates operation status via light signals. \n4. **Front Camera**: Captures visual information for image recognition. \n5. **Laser Sensor**: Senses surrounding objects for spatial awareness and positioning. \n6. **3D Sensor**: Measures distance to nearby objects and senses the surrounding environment in three dimensions. \n\nEach component contributes to the device's functionality, including navigation, interaction with furniture, and environmental sensing.", "content_path": "imagedata/(ID略)/normalized_images_91.jpg", "document_title": "00zentai.pdf", "locationMetadata": { "pageNumber": 99, "boundingPolygons": "[[{\"x\":1.8649,\"y\":7.4079},{\"x\":6.3523,\"y\":7.4078},{\"x\":6.3528,\"y\":9.4302},{\"x\":1.865,\"y\":9.4303}]]" } },
まとめ
今回は新しく公開されたカスタムスキルを活用してマルチモーダルRAGを実現しました。
カスタムスキルを活用することで、極めてリッチな回答がわずかなコードから得られます。開発工数を削減しつつ、安定したマルチモーダル的な回答生成のインデックス作成が実現可能となります。
最初の一歩として、本記事の内容とコード断片をなぞりながら、Azure AI Searchを使ったマルチモーダルRAG構築にぜひ挑戦してみてください。
