
Azure Cognitive Servicesとは、Microsoftが提供する一連のクラウドベースのサービスのことです。これらは、人工知能(AI)を活用して、コンピュータに人間のような「考える力」を与えることを目的としています。
今回は、Azure Cognitive Servicesを使って画像認識を行ってみました。
- Azure Cognitive Servicesとは
- Azure Cognitive Servicesの主な機能
- Azure Cognitive Servicesによる画像認識
- 事前準備
- image1/image2の画像認識結果
- おわりに
Azure Cognitive Servicesとは
Azure Cognitive Servicesは、クラウドベースのAIサービスです。
視覚、音声、言語、意思決定、検索の5つの主要カテゴリに分かれ、画像の中の顔を認識したり、音声をテキストに変換したり、感情を判断したりすることができます。
Azure Cognitive Servicesの主な機能
- 視覚サービス (Computer Vision)
- 画像分析:画像内のオブジェクトやシーンを認識し、キャプションやタグを自動生成
- 顔認識:特定の顔を認識し、比較やグループ化が可能
- OCR (光学文字認識):画像内のテキストを検出し、デジタルテキストに変換成
- 音声サービス
- 音声認識:音声を文字に変換し、リアルタイムでのトランスクリプションが可能
- 音声合成(Text-to-Speech):テキストを自然な発音の音声に変換
- 翻訳音声:音声を他の言語にリアルタイムで翻訳
- 言語サービス
- Text Analytics:テキストの感情分析、キーフレーズ抽出、言語の識別
- 翻訳API:テキストを複数の言語に翻訳
- QnA Maker:FAQスタイルの質問応答を構築可能
- 知識サービス (Knowledge)
- Personalizer:ユーザーの行動に基づいて、パーソナライズされたコンテンツを提供
- Anomaly Detector:時系列データに基づく異常検知
- 決定サービス
- Content Moderator:ユーザーが生成したコンテンツをスキャンし、不適切な内容を検出
- Azure Machine Learning:機械学習モデルを構築・デプロイし、カスタマイズしたAI機能を開発
- 翻訳音声:音声を他の言語にリアルタイムで翻訳
- リコメンデーションサービス
- Recommendation API:ユーザーの嗜好や行動に基づいて、商品やコンテンツを推薦
Azure Cognitive Servicesによる画像認識
Azure Cognitive Servicesを使用して、必要なリソースを作成して画像を認識するまでのプロセスを紹介します。
構成情報
今回は、Linuxサーバーとして、Azure上にデプロイしたRed Hat Enterprise Linux 8.5(以下、RHEL)を利用し、Azure Cognitive Servicesの連携を行います。
※今回は仮想マシンの作成方法は割愛します。
Azure Cognitive Servicesのリソース作成
1. Azure ポータルで「Cognitive」と検索し、 [Azure AI services] をクリックします。
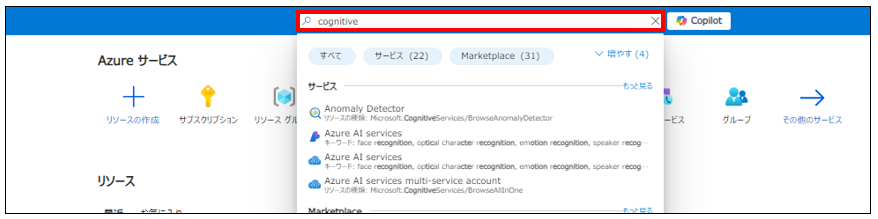
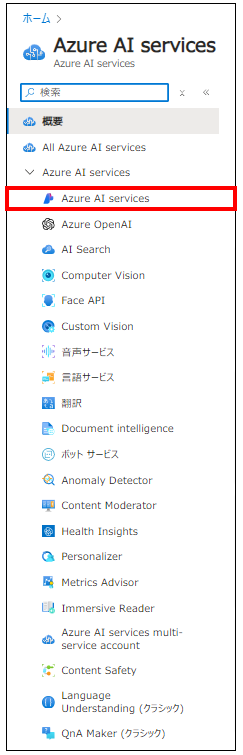
2. [Azure AI sservicesの作成]をクリックして、リソースを作成します。
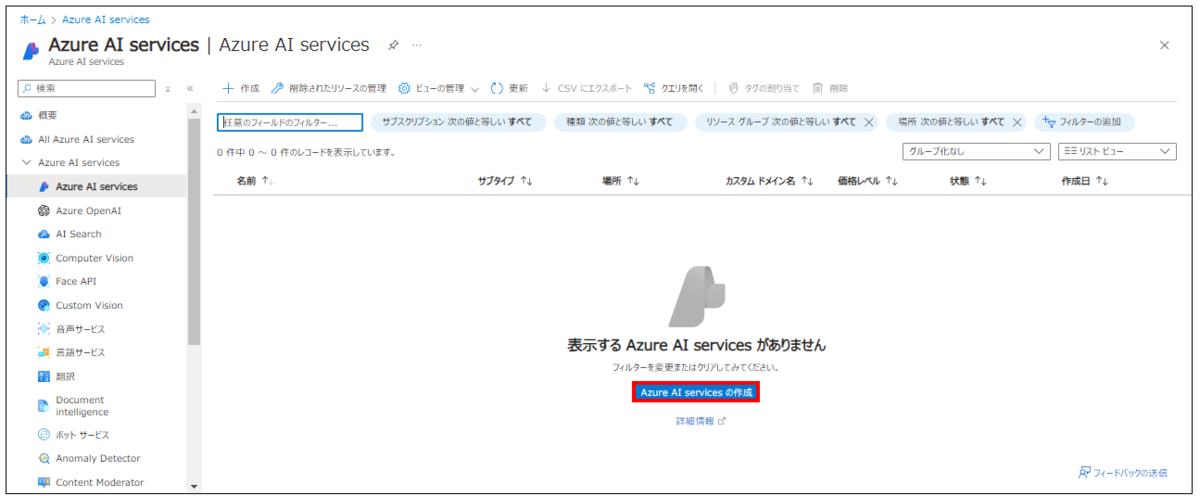
3. [Create Azure AI services]画面が表示されます。サブスクリプションやリソースグループ等を入力したら[確認と作成]をクリックします。

事前準備
APIキーとエンドポイントの取得
1. 作成したAzure AI servicesを開き、[キーとエンドポイント]をクリックします。

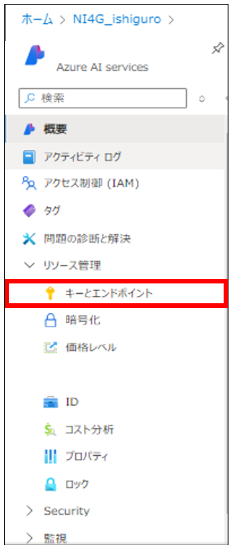
2. [キーとエンドポイント]の[キー1]と[トークン]の内容をメモします。

Pythonスクリプトの作成
1. 仮想マシンにログインしたら、必要なライブラリをインストールします。以下はPythonを使った一例です。
sudo yum install python3 python3-pip
2. 下記のパスへ画像認識させる画像を保存し、パスをメモします。今回は2つの画像を保存しており、それぞれがどのように画像認識されるのかを検証します。
/home/visonaryAPI/ImageRecognitionApp/image3. /home/visonaryAPI/ImageRecognitionApp/image配下にコードファイルを作成し、[image_recognition.py]という名前のファイルを作成します。以下のコードをコピーして、ファイルに貼り付けます。
※subscription_key = "APIキーとエンドポイントの取得の項2で取得したキー1"
※endpoint = "APIキーとエンドポイントの取得の項2で取得したトークン"
import requests
# APIキーとエンドポイントを設定
subscription_key = "APIキーとエンドポイントの取得の項2で取得したキー1"
endpoint = "APIキーとエンドポイントの取得の項2で取得したトークン"
# 画像ファイルのパス
image_path = "/home/visonaryAPI/ImageRecognitionApp/image/image1.JPG"
# APIのURLを設定
analyze_url = endpoint + "/vision/v3.1/analyze?visualFeatures=Description,Tags" #
try:
# 画像を開く
with open(image_path, "rb") as image:
# APIにリクエストを送信
response = requests.post(
analyze_url,
headers={
"Ocp-Apim-Subscription-Key": subscription_key,
"Content-Type": "application/octet-stream" # コンテンツタイプを追加
},
data=image
)
response.raise_for_status() # ここでHTTPエラーをチェック
# 正常時の解析結果を取得
analysis = response.json()
# 分析結果を表示
print(analysis)
except requests.exceptions.HTTPError as e:
print(f"HTTP Error: {e.response.status_code} - {e.response.text}") #
except FileNotFoundError:
print(f"Error: The file {image_path} was not found.") #
except Exception as e:
print(f"An error occurred: {str(e)}") #image1/image2の画像認識結果
1. 以下のコマンドで image_recognition.py というファイルを実行します。
python3 image_recognition.pypython3 image_recognition.pyの結果をタグ(Tags)と説明(Description)の2つに分けて結果を確認します。
image1の画像認識結果
python3 image_recognition.pyの結果を確認します。今回はこちらの画像認識を行いました。

ここでは分析したデータを見やすくするために改行を入れていますが、通常は改行を含まない形で結果が出力されます。
python3 image_recognition.py
{'tags': [{'name': 'text', 'confidence': 0.99505615234375},
{'name': 'design', 'confidence': 0.992041289806366},
{'name': 'graphic', 'confidence': 0.9133347272872925},
{'name': 'logo', 'confidence': 0.8528381586074829},
{'name': 'font', 'confidence': 0.7986361384391785},
{'name': 'typography', 'confidence': 0.7665104866027832},
{'name': 'graphics', 'confidence': 0.7482141256332397},
{'name': 'illustration', 'confidence': 0.6300663948059082},
{'name': 'abstract', 'confidence': 0.517926812171936},
{'name': 'clipart', 'confidence': 0.20357611775398254},
{'name': 'vector graphics', 'confidence': 0.18467581272125244}],
'description': {'tags': ['logo'],
'captions': [{'text': 'logo', 'confidence': 0.9413888454437256}]},
'requestId': 'c6463c80-9a22-4971-9592-737e93005d1a',
'metadata': {'height': 241, 'width': 666, 'format': 'Png'}}この結果をChatGPTで解析し、整理してみました。
タグ(Tags)
各タグには、名前(name)と、そのタグに対する確信度(confidence)が含まれています。確信度は0から1の範囲で、1に近いほどそのタグが正しいとされる割合です。
- {'tags': [{'name': 'text', 'confidence': 0.99505615234375},
- 画像内に明確なテキストが含まれており、非常に高い確信度が示されています。
- このため、文字情報が重要な役割を果たしていることを示唆しています。
- {'name': 'design', 'confidence': 0.992041289806366},
- 画像がデザイン面で非常に評価されていることが示されています。
- 視覚的に魅力的で、効果的なコミュニケーションが行われていると言えます。
- {'name': 'graphic', 'confidence': 0.9133347272872925},
- 高い評価を得ていることから、視覚的な要素が豊富で、デザインにおいて重要な役割を果たしていることがわかります。
- {'name': 'logo', 'confidence': 0.8528381586074829},
- ロゴの存在が強調されており、企業やブランドの識別が可能であることを示しています。
- これは、ブランディングにおいて非常に重要です。
- {'name': 'font', 'confidence': 0.7986361384391785},
- 使用されているフォントスタイルが明確に認識されており、デザインの一貫性やブランドのアイデンティティに寄与していると考えられます。
- {'name': 'typography', 'confidence': 0.7665104866027832},
- フォントのデザインやレイアウトに関する要素が強調されています。
- これにより、視覚的なインパクトが増します。
- {'name': 'graphics', 'confidence': 0.7482141256332397},
- 画像全体に視覚的要素が散りばめられており、視覚的な魅力を高めていることが示されています。
- {'name': 'illustration', 'confidence': 0.6300663948059082},
- 描かれた要素があり、画像に独自性やアート的な表現を与えています。
- {'name': 'abstract', 'confidence': 0.517926812171936},
- 抽象的なデザイン要素が含まれている可能性があり、抑制された芸術的な表現を示唆しています。
- {'name': 'clipart', 'confidence': 0.20357611775398254},
- 少しのクリップアート要素が含まれている可能性がありますが、全体のデザインに対する影響は限られていると見られます。
- {'name': 'vector graphics', 'confidence': 0.18467581272125244}],
- ベクター形式の要素が認識されている可能性がありますが、その影響は小さいと考えられます。
説明(Description)
- 'description': {'tags': ['logo'],
- 画像は明確にロゴを示しています。
- 'captions': [{'text': 'logo', 'confidence': 0.9413888454437256}]},
- 確信度が94.14%であることから、ブランド認知や商業的な利用が意図されている可能性が非常に高いです。
- ロゴに対する高い確信度は、視覚的なアイデンティティの強化に対して重要です。
image1のまとめ
この画像は、特に「ロゴ」や「テキスト」の要素が際立っており、企業ブランディングに寄与する重要なビジュアル要素が豊富であることがわかります。
また、デザインやグラフィックに対する高い確信度は、その視覚的な強さを示しています。
この情報をもとに、今後のマーケティングやブランディング戦略を考える際の貴重な指針となる。という結果が出ています。
image2の画像認識結果
同じくpython3 image_recognition.pyの結果を確認します。image1に続きこちらの画像認識を行いました。

python3 image_recognition.py
{'tags': [{'name': 'design', 'confidence': 0.98970627784729},
{'name': 'text', 'confidence': 0.9810315370559692},
{'name': 'graphic', 'confidence': 0.840408444404602},
{'name': 'logo', 'confidence': 0.8247137069702148},
{'name': 'illustration', 'confidence': 0.7325313687324524},
{'name': 'font', 'confidence': 0.6880918741226196},
{'name': 'graphics', 'confidence': 0.6851901412010193},
{'name': 'abstract', 'confidence': 0.6702361106872559},
{'name': 'clipart', 'confidence': 0.18124163150787354},
{'name': 'vector graphics', 'confidence': 0.1742241084575653}],
'description': {'tags': ['company name'],
'captions': [{'text': 'company name', 'confidence': 0.44931715726852417}]},
'requestId': '6e6428ad-6e17-4740-843c-df58cc15b71a',
'metadata': {'height': 232, 'width': 665, 'format': 'Png'}}image1同様、この結果をChatGPTで解析し、整理してみました。
タグ(Tags)
- {'tags': [{'name': 'design', 'confidence': 0.98970627784729},
- 画像が全体としてデザイン的要素に富んでおり、視覚的に洗練された印象を与えていることが示されています。
- この高い確信度は、全体の構成や配色、バランスが優れていることを意味します。
- {'name': 'text', 'confidence': 0.9810315370559692},
- 画像内に何らかのテキストが明確に存在していることを示しています。
- 特に「会社名」というタグからも、ブランド名や商業用のメッセージが含まれている可能性も高いです。
- {'name': 'graphic', 'confidence': 0.9133347272872925},
- 高い評価を得ていることから、視覚的な要素が豊富で、デザインにおいて重要な役割を果たしていることがわかります。
- {'name': 'graphic', 'confidence': 0.840408444404602},
- グラフィカルな要素が豊富であり、視覚的に魅力的なデザインであることを示しています。
- これにより、ビジュアルコミュニケーションの効果が高まります。
- {'name': 'logo', 'confidence': 0.8247137069702148},
- ロゴが明確に認識されていることを示しています。
- 自社のブランドイメージを強化するために重要な要素です。
- {'name': 'illustration', 'confidence': 0.7325313687324524},
- イラストが含まれていることから、手描きやデジタルアートの要素があると考えられ、デザインに独自性を与えています。
- {'name': 'font', 'confidence': 0.6880918741226196},
- 使用されているフォントスタイルが特定でき、ブランディングやメッセージの伝達に影響を与えることがあります。
- {'name': 'graphics', 'confidence': 0.6851901412010193},
- 画像全体の視覚的要素が組み合わさって、より高い視覚効果を生み出していることが示唆されます。
- {'name': 'abstract', 'confidence': 0.6702361106872559},
- 抽象的なデザイン要素が含まれている可能性があり、抑制された芸術的な表現を示唆しています。
- {'name': 'clipart', 'confidence': 0.18124163150787354},
- クリップアートの要素がある可能性が低いですが、デザインの一部に簡素化されたグラフィック要素が含まれているかもしれません。
- {'name': 'vector graphics', 'confidence': 0.1742241084575653}],
- ベクター形式のデザインが含まれている可能性が低いですが、スケーラビリティや品質の維持が重要です。
説明(Description)
- 'description': {'tags': ['company name'],
- この画像は、特に「ロゴ」や「テキスト」の要素が際立っており、企業ブランディングに寄与する重要なビジュアル要素が豊富であることがわかります。
- ''captions': [{'text': 'company name', 'confidence': 0.44931715726852417}]},
- キャプションの確信度が44.93%であったことから、画像の解釈においてテキスト認識が完全ではなく、さらなる明確さが求められます。
image2のまとめ
この画像は企業のブランドを強化するための資産として、デザイン性と視覚的魅力に優れた要素が組み合わさったものと分析できます。
特に、高い確信度を持つ「デザイン」や「テキスト」の要素は、ビジュアルマーケティングの戦略において重要な役割を果たします。
おわりに
Azure Cognitive Servicesを利用した画像認識ついてご紹介しました。
AIの力を借りることで、画像の内容を瞬時に理解し、分析することが可能になる一方で、その精度にはまだ改善の余地があることも感じました。
特定のタグや説明文が期待した結果とは異なる場合があり、AIが捉えきれない細かなニュアンスがあると感じております。
それでも、技術の進化がもたらす可能性は大きく、画像認識の精度も今後さらに向上していくことは間違いないと感じました。

石黒 允規(日本ビジネスシステムズ株式会社)
ネットワークインテグレーション部に所属しており、主にAzureに関する業務を行っています。 JBS野球部にも所属しており、週末を楽しく過ごしております
担当記事一覧