
Microsoft Fabricは、Microsoft のSaaS 型データ分析基盤サービスです。SaaS 型のため、容易にデータ分析の一連の流れを試すことができる特徴があります。
本記事では、Microsoft Fabricを利用してサンプルから祝日のデータを取得し、1年間の東京都の降水量へ休祝日を反映する方法を解説します。
データソースの準備
今回は、国土交通省気象庁のデータを利用します。
気象庁 Japan Meteorological Agency (jma.go.jp)
ここから、下記の内容を選択して CSV をダウンロードします。
気象庁|過去の気象データ・ダウンロード (jma.go.jp)
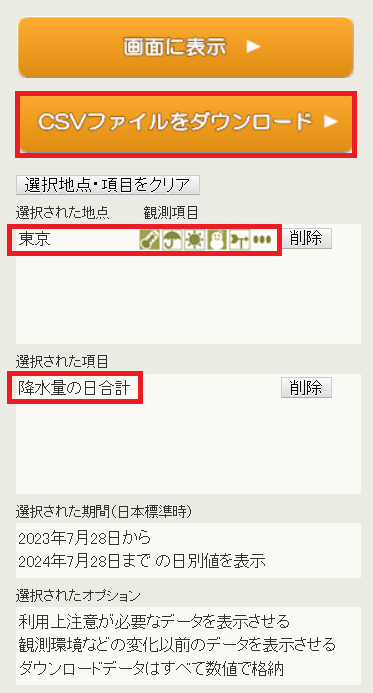
CSVファイルの1行目から3行目までを削除します。
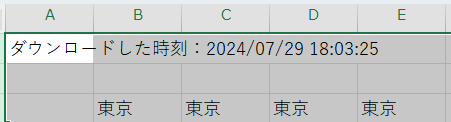
これで準備完了です。
データソースの取り込み
以前作成した記事を参考に、今回用意したデータソースをアップロードします。
オープンデータを利用して Microsoft Fabric を利用してみる - JBS Tech Blog

データのクリーニング
ノートブックの作成
"ノートブックを開く"から"新しいノートブック"を選択します。
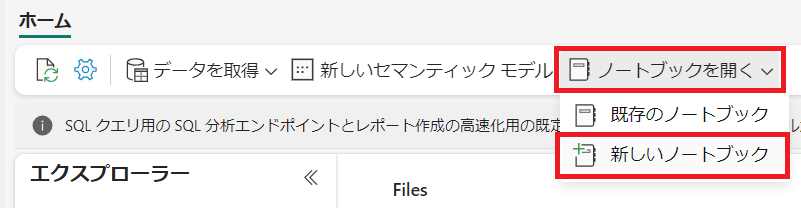
下記の画像の赤枠のマークを押下します。

鉛筆マーク (編集マーク) を押下し、編集状態にします。

画面右の項目からレイクハウスを選択し、"Files" > "Data.csv" 右の "..." > "データの読み込み" > "Spark" の順で選択します。
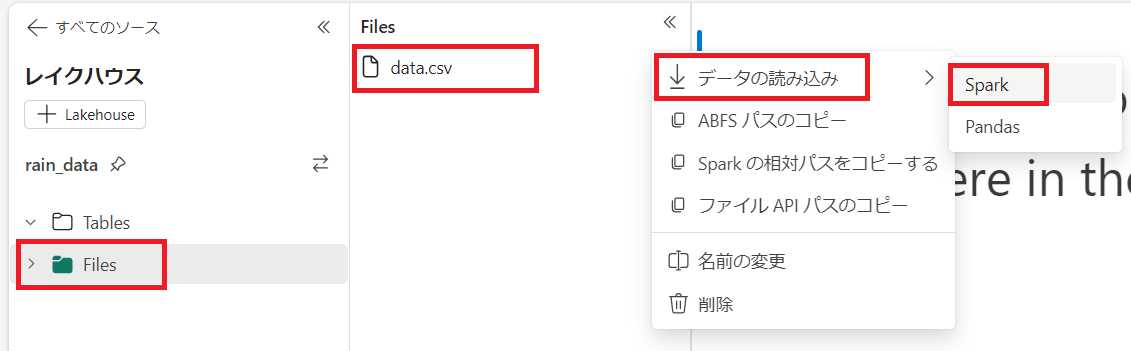
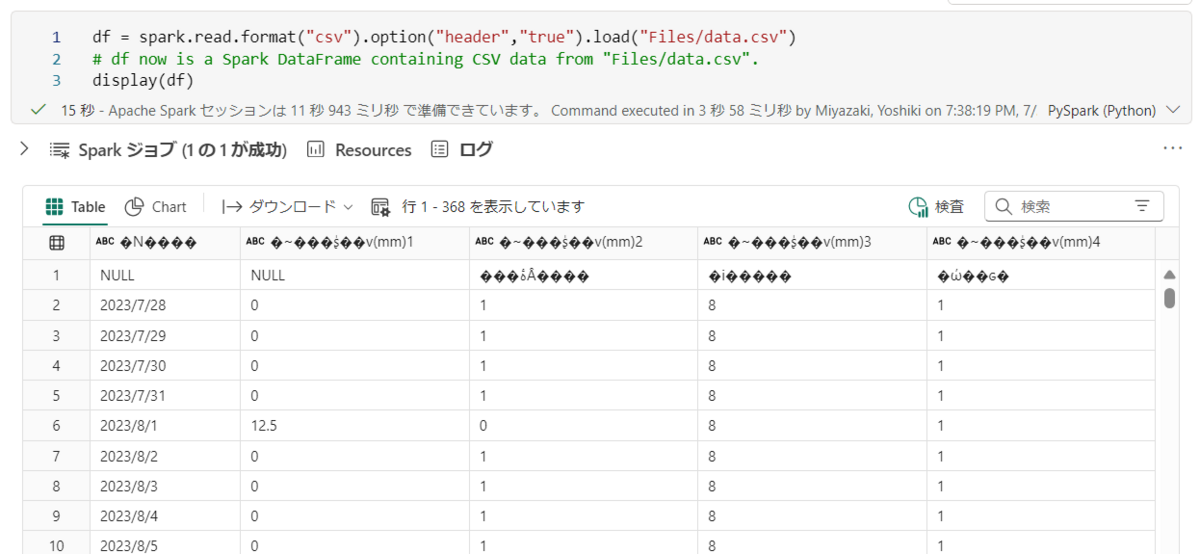
実行ボタンを押下し、データをデータフレームに読み込みます。

読み込みが完了するとデータが表示されます。
Data Wrangler による加工
GUIの操作をもとにPySpark を記述することができる、Data Wrangler を利用します。
"ホーム"から"Data Wrangler"を選択し、"df"を押下します。
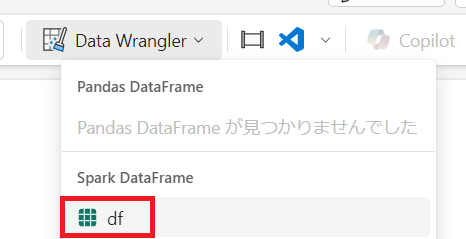
列名が文字化けしているので修正していきます。
"・・・"を押下します。
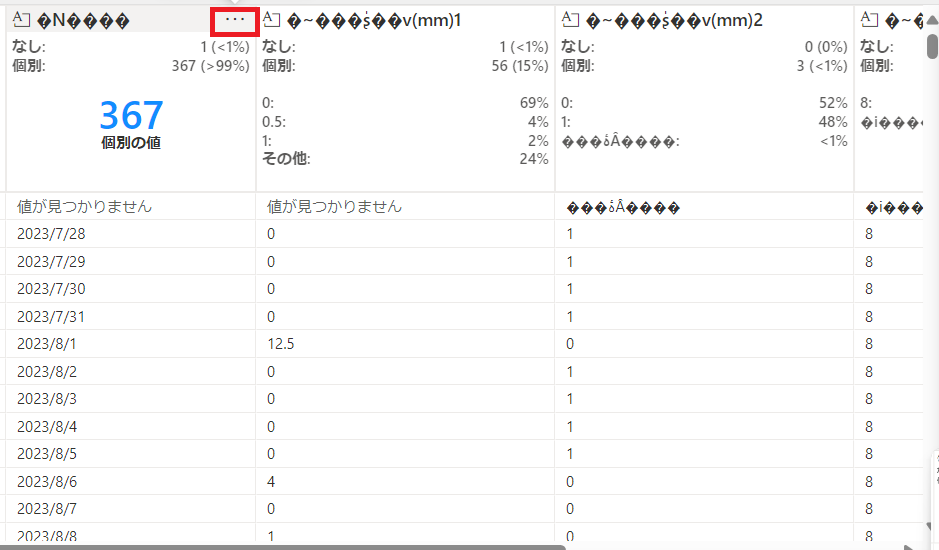
"列の名前の変更"を押下します。
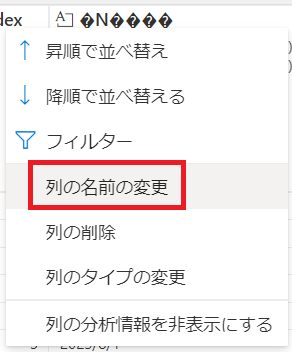
新しい列名を入力し、"適用"を押下します。
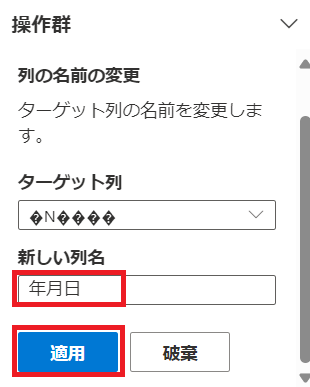
同じように右隣の列名も修正します。
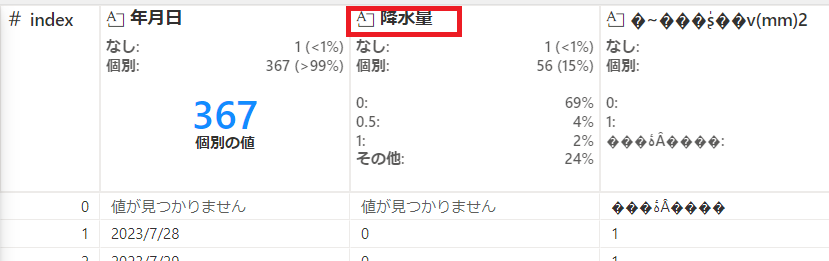 後ろ3列は今回利用しないため、各列"・・・"から"列の削除"を選択し、それぞれ削除していきます。
後ろ3列は今回利用しないため、各列"・・・"から"列の削除"を選択し、それぞれ削除していきます。
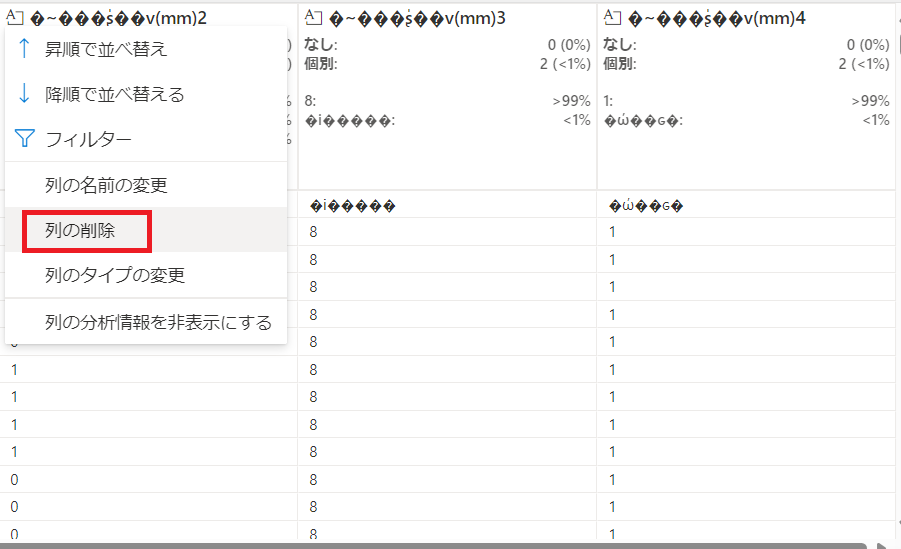
下記の画面で"適用"を押下すると削除できます。
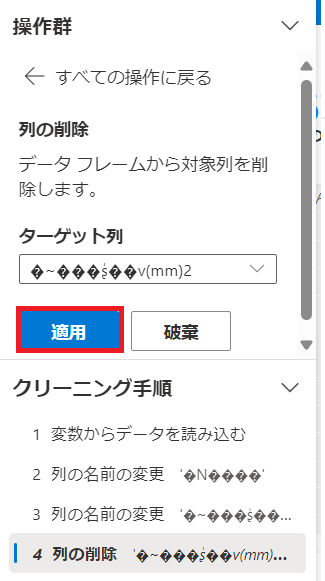
削除した結果は下記になります。

左の項目の"検索と置換"から"欠損値をドロップする"を選択し、欠損値を削除していきます。

ターゲット列を選択し、"適用"を押下します。
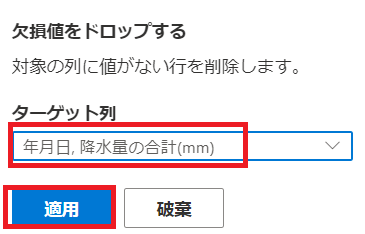
クリーニング後のデータは下記のようになります。
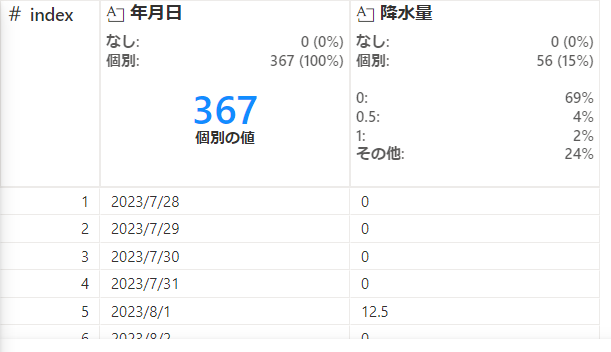
クリーニング手順を確認し、問題がなければ"コードをノートブックに追加する"を押下します。
プレビューを確認し、問題がなければ"追加"を押下します。
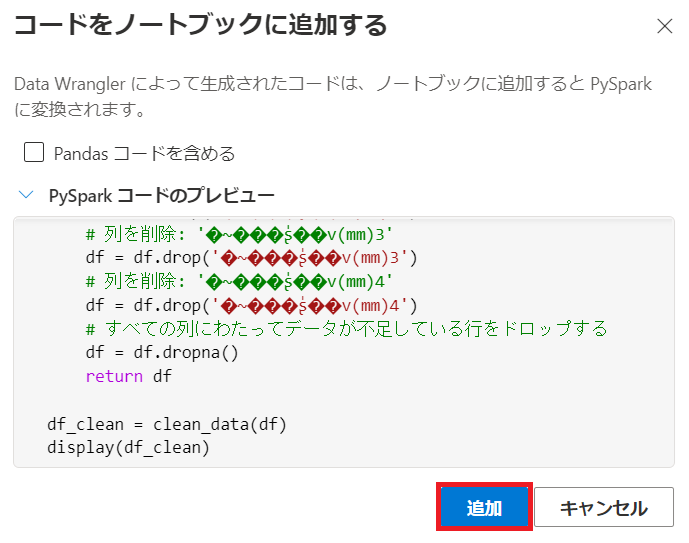
追加されたコードを実行します。

データがクリーニングされていることが確認できます。
テーブルの作成
最後のセルの左下にカーソルを合わせ、"+コード"が表示されたら押下します。 (コードセルの追加)
下記のコードを入力し実行します。
%%sql
--既存のテーブルの確認
DROP TABLE IF EXISTS rain_data.raindata
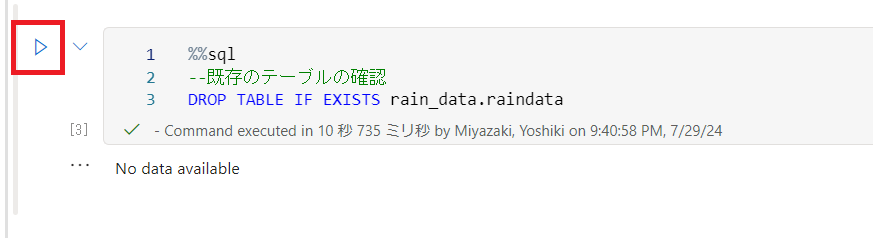
- rain_data : レイクハウス名
- raindata : 任意のテーブル名
※初回は No data available と表示されます。
先ほどと同様にコードセルを追加し、下記のコードを入力して実行します。
# テーブルを作成して編集したデータを入れる
table_name = "raindata"
df_clean.write.mode("overwrite").format("delta").save("Tables/" + table_name)
print("Spark dataframe saved to delta table")

ジョブが成功していることを確認します。
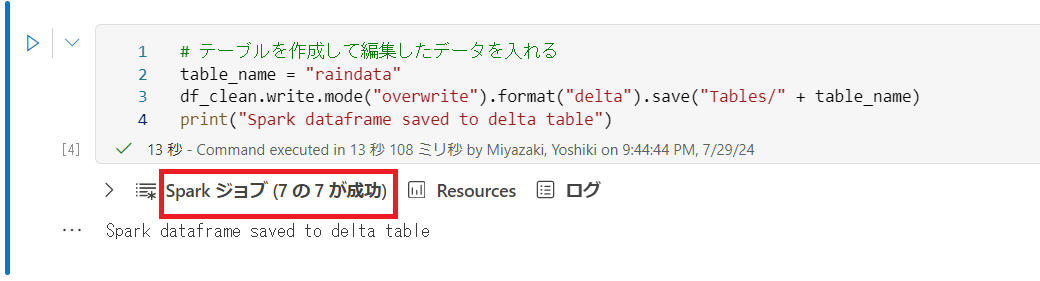
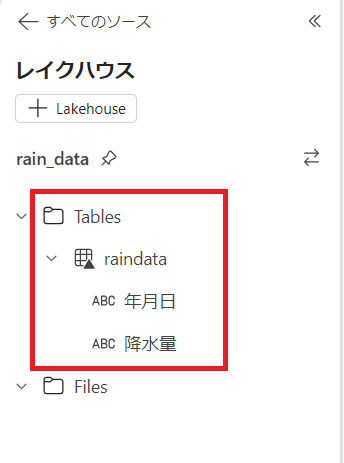
左の"Tables"からクリーニング後のテーブルが追加されていることを確認できます。
前半のまとめ
前半では、レイクハウスのテーブルへクリーニングしたデータを読み込みました。
データのクリーニングでは、GUIでの操作を PySpark のコードに変換できる Data Wrangler を利用しております。Data Wrangler は簡単にデータクリーニング用の PySpark を記述できるので、ぜひ利用してみてください。
データ分析において、企業では営業日のみのデータを集計するケースがあるため、今回の内容が参考になれば幸いです。
後半では、前半で用意したデータに祝日を反映し、視覚化を実施します。
