
Data&AIプラットフォーム部所属の福濵です。2023年に入社しSnowflakeについて基礎から勉強しています。
Snowflakeには、プルーニングというデータ参照のパフォーマンスを向上させる機能があります。これは、テーブルデータを格納しているマイクロパーティションのメタデータを参照し、不要と確定しているパーティションを読み飛ばすことで処理対象データを減らして性能を向上させることができます。
参考:Snowflake マイクロパーティション解説 - JBS Tech Blog
この、プルーニング機能をさらに効きやすくするための機能として、クラスタリングがあります。
本記事ではクラスタリングの機能について概要を紹介した後、クエリ実行時の内部の動きや、クラスタリング使用時の注意点について解説します。
なお、本記事は、以下の公式ドキュメントを参考にしています。
参照:マイクロパーティションとデータクラスタリング | Snowflake Documentation
クラスタリング
クラスタリングとは、任意の列をキーとしてパーティションの再編成を行い、プルーニングを効きやすくする機能のことです。
以下のようなtableAを例に、クラスタリングのある場合と無い場合を比較してみましょう。
tableA
| 出身地 | 名前 | 年齢 |
| 東京 | 田中 | 22 |
| 神奈川 | 鈴木 | 24 |
| 神奈川 | 高松 | 12 |
| 栃木 | 安藤 | 32 |
| 東京 | 高松 | 21 |
| 埼玉 | 川崎 | 11 |
| 千葉 | 林 | 16 |
| 栃木 | 鈴木 | 28 |
| 東京 | 大森 | 30 |
クラスタリングをする前
クラスタリングを行わない場合、マイクロパーティションはこのように分かれます。
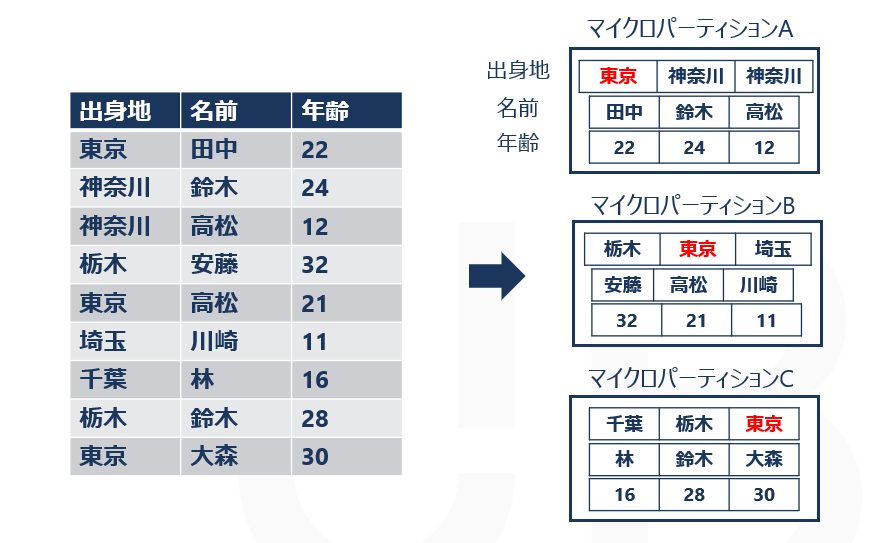
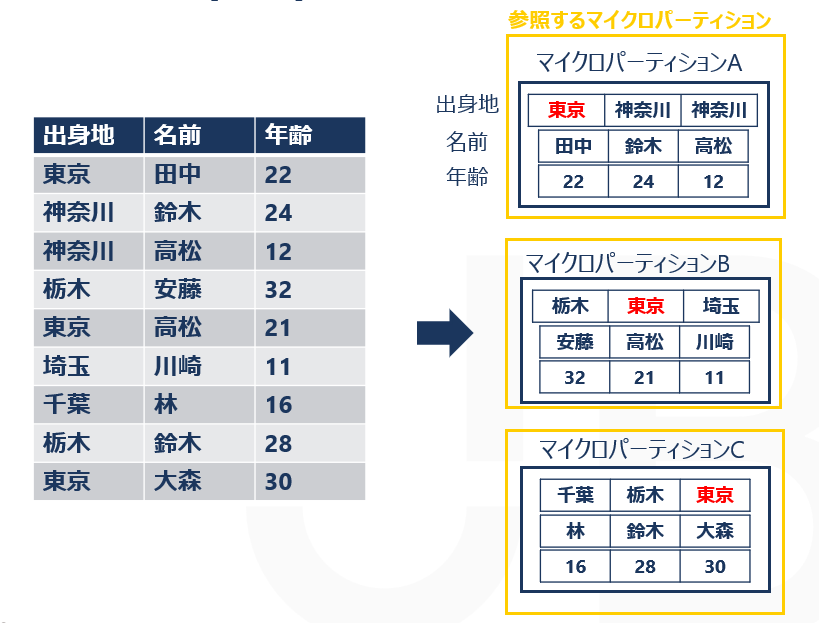
この状態で以下のSQL文を実行し、tableAの出身地が「東京」の行のみを出力させたとします。
SELECT *FROM tableA WHERE 出身地 = '東京';
クラスタリングをする前は、3つのマイクロパーティションを参照していることが分かります。
クラスタリングをした後
tableAの「出身地」列をキーとしてテーブルを更新しクラスタリングを行うと、以下のように、重複する値が同じマイクロパーティションにまとまるように再編成が行われます。
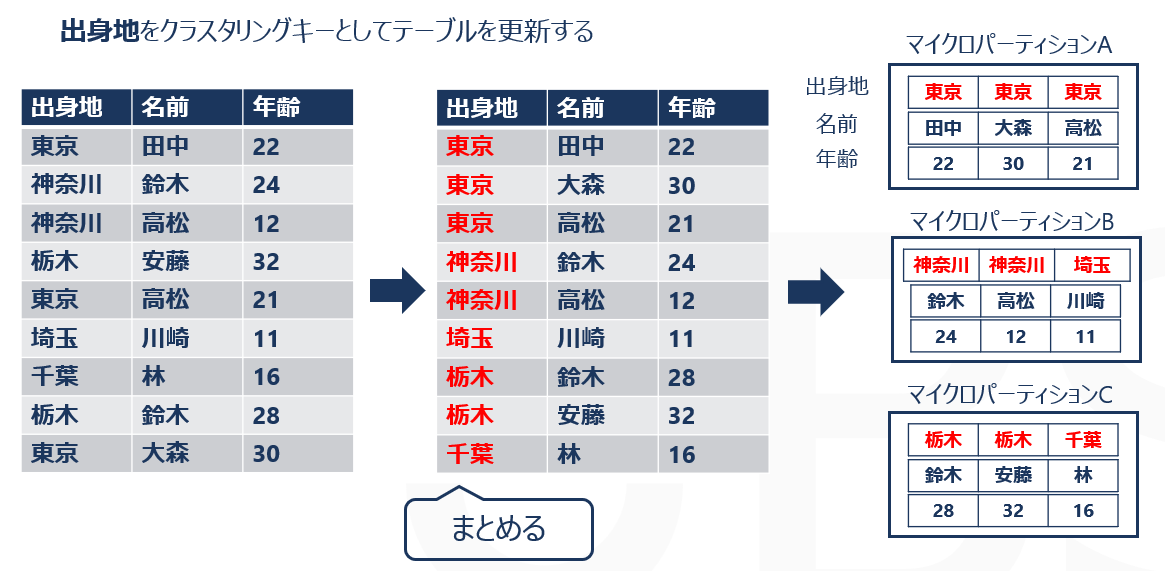
クラスタリングを行ったうえで、先ほどと同様に、tableAの出身地が「東京」の行のみを出力させてみましょう。
SELECT *FROM tableA WHERE 出身地 = '東京';
クラスタリング後は、参照するマイクロパーティションの数が一つだけになっており、クラスタリングをする前より参照数が少ないことがわかります。
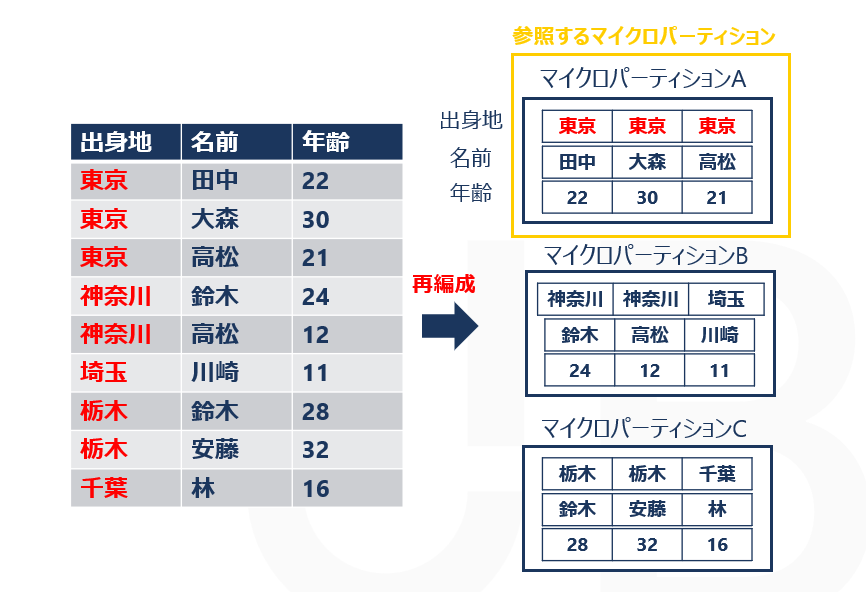
このように、同じ値が同じマイクロパーティションに格納されていることで、参照するマイクロパーティションの数を減らし、クエリのパフォーマンスを向上させることができます。
クラスタリング機能を設定するとクラスタリングメタデータが作成され、クエリ時にこのメタデータを参照してから、参照するマイクロパーティションを決定するようになります。
クラスタリングメタデータ
クラスタリングによるマイクロパーティションの再編成には、クラスタリングメタデータが使用されます。
これは、次の3つの要素で構成されます。
マイクロパーティションの総数
1つのテーブルをストレージに格納した際に生成される、マイクロパーティションの総数のことをいいます。
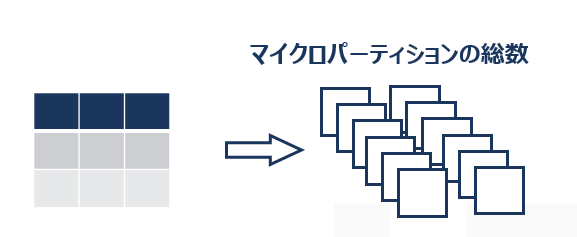
互いに重複する値を含むマイクロパーティションの数
例えば、「東京」という値を含むマイクロパーティションは3つ、「鈴木」という値を含むマイクロパーティションは2つとなります。

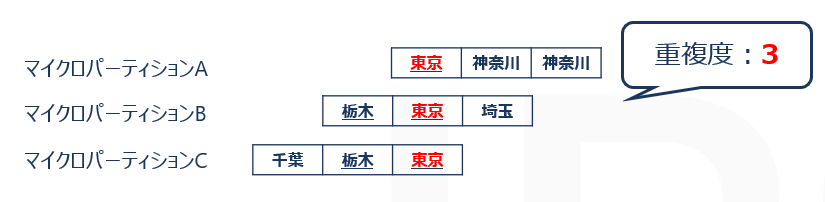
マイクロパーティションの深さ
クラスタリングキーとして指定した、特定の列におけるマイクロパーティションの重複度のことをいいます。
例えば「出身地」列をキーとした場合、マイクロパーティションの深さは3となります。
重複したマイクロパーティション数が多いほどパーティションの深さがあるということになります。
データ参照時は絞り込む値の重複度と同じ回数マイクロパーティションをスキャンすることになります。つまり、「深さがある」=「スキャンするパーティションが増える」事になり、クエリの効率が下がることを意味します。
そのため、クラスタリングはマイクロパーティションの重複度を最小限に抑え、同じ値が同じマイクロパーティションに集中するように設計する機能といえます。
自動クラスタリング
テーブルへのDML操作の実行時に自動で再クラスタリングを行う機能のことです。
Snowflakeのクラスタリングは、キーを指定すれば基本的に自動でクラスタリングが行われます。
これにより、マイクロパーティションをクラスタリングした状態を常に維持することができます。
※手動クラスタリングも可能ですがSnowflake公式では非推奨とされています。
参照:自動クラスタリング | Snowflake Documentation
例えば、先ほどのtableAに以下のデータを挿入したとします。
| 出身地 | 名前 | 年齢 |
| 神奈川 | 杉田 | 10 |
| 栃木 | 斎藤 | 35 |
| 群馬 | 篠原 | 40 |
すると、「出身地」列をもとに行が再編成され、マイクロパーティションが生成されます。古いマイクロパーティション(B, C)については以降参照されなくなります。
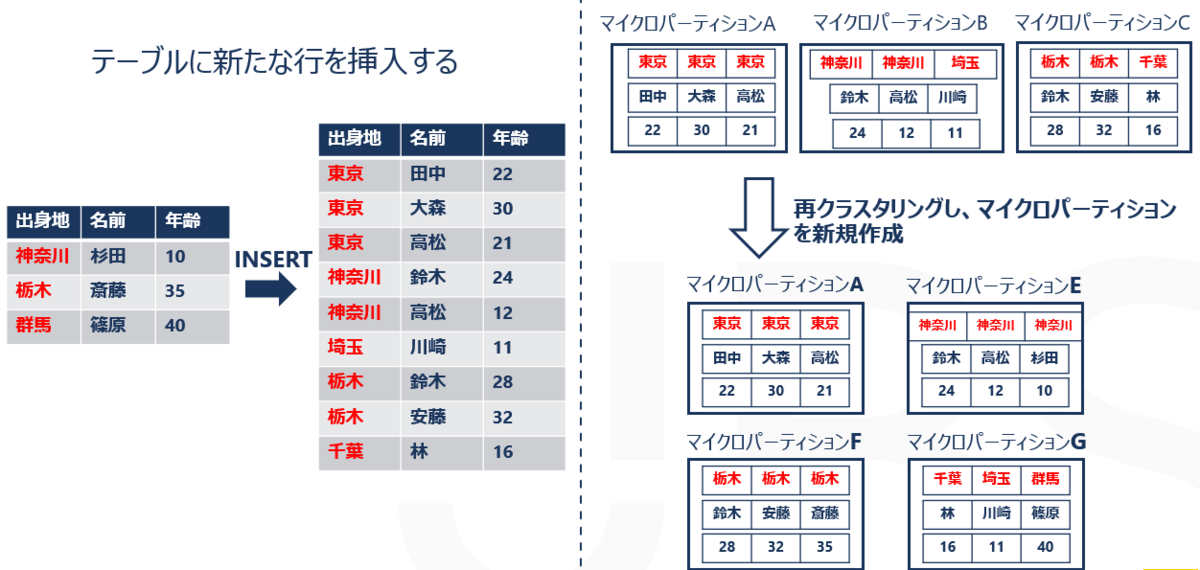
このように、クラスタリングを自動で再編成することで、クエリのパフォーマンスを維持することができます。
注意点
コンピュートリソースの影響
クラスタリングキーを指定したテーブルに対してDML操作(INSERT、UPDATE、DELETE)が多い場合、再クラスタリングを頻繁に行うこととなり、コンピューティングリソースを多く使用します。
これにより、プルーニングのスキャン効率を上げる以上にコンピューティングコストがかかる可能性があります。
Snowflakeではコストの最適化のために、以下の基準をすべて満たすテーブルについてクラスタリングキーの指定を推奨しています。
- データ量が数TB以上のテーブル
- 選択的なクエリ(指定した列に基づいてテーブルの一部だけを読み取る)またはデータを並べ替えるクエリ(指定した列に基づいてORDER BYでソートする)を頻繁に使用するテーブル
頻繁にDML操作が発生するテーブルをクラスタリングする場合は、更新をリアルタイムで行うのではなく、一定の時間間隔でまとめてバッチ更新を行うことで、コストを抑えることが可能です。
また、Snowflakeではクラスタリングする前に、普段よく実行するクエリでテストを行い、実装前後のコストパフォーマンスの評価を行うことを強く推奨しています。
参考:クラスタリングキーとクラスタ化されたテーブル | Snowflake Documentation
ストレージの影響
クラスタリングでは、再クラスタリングごとに物理的にテーブルの行が並び替えられ、その度に新しいマイクロパーティションが生成されます。
そのため、再クラスタリングの頻度が多いと大量のマイクロパーティションを生成し、ストレージを圧迫してしまう可能性があります。
参照されなくなった古いマイクロパーティションについては、デフォルトで1日、最大で90日まで保持するため、ストレージコストを考慮し、再クラスタリングの有無を決める必要があります。
参考:クラスタリングキーとクラスタ化されたテーブル | Snowflake Documentation
過度な再クラスタリングを防ぐために
テーブル作成時はテーブルの参照頻度やクエリパフォーマンスを考慮し、クラスタリング設定を行うことで不要なクレジット消費を防ぐことができます。
以下のコマンドやシステム関数を利用することでクラスタリングの状態の確認や管理を行うことができます。
テーブルの自動クラスタリングの一時停止、再開を行うクエリです。
ALTER TABLE <テーブル名> { SUSPEND | RESUME } RECLUSTER;
テーブルを構成するマイクロパーティションの総数や、マイクロパーティションの平均重複深度等のクラスタリング情報を確認する場合は、SYSTEM$CLUSTERING_INFORMATION関数が利用できます。
参照:ALTER TABLE | Snowflake Documentation
参照:SYSTEM$CLUSTERING_INFORMATION | Snowflake Documentation
おわりに
本記事ではSnowflakeのクラスタリングについてご紹介しました。
クラスタリングはテーブルやビューに設定することでクエリのパフォーマンスを向上させる反面、コンピューティングやストレージコストが増加する可能性があります。
特にTimeTravel機能でデータ保持期間を長く設定している場合は、不要なデータによるストレージの圧迫をしやすくなるため、テーブル設計において注意が必要です。
本記事がSnowflake学習の参考になれば幸いです。
