
本記事はAzure Databricks のシークレットスコープとAzure Key Vaultとの連携方法を説明します。
※ なお、本記事は、Azure Databricksをある程度使い慣れている方向けに書いていますので、Azure Databricksの概要や用語の解説は割愛しています。
- 概要
- 制限
- シークレットスコープの種類
- 検証内容
- 検証の前提
- 検証
- まとめ
概要
- Azure Databricksのシークレットスコープは、Databricksのワークスペース内で安全に認証情報や機密情報を管理するための仕組みです。
- シークレットスコープを使用することで、ユーザーはノートブック、ジョブで機密情報を記載することなく、セキュアな方法で認証情報やキーなどを保持することができます。
- シークレットスコープは、ワークスペース内での名前によって識別されるシークレットのコレクションです。シークレットスコープ内に直接認証情報や機密情報を登録することはありません。
- Azure Key Vaultでサポートされるものの場合、シークレットスコープでAzure Key VaultのリソースIDとAzure Key VuaultのVault URIを登録します。Key Vaultのシークレットの値を取得する際は、Azure Databricksのサービスプリンシパルの権限を利用してシークレットスコープに登録されたkey vaultのシークレットへアクセスします。
制限
シークレットスコープの利用には以下の制限事項があります。
- ワークスペース内でのシークレットスコープの数は
1000です。
シークレットスコープの種類
シークレットのスコープには、Azure Key Vault でサポートされるものと Databricks でサポートされるものと 2 種類があります。
本記事で取り上げるは、Azure Key Vaultでサポートされるシークレットスコープです。
Azure Key Vault でサポートされるシークレットスコープ
- シークレットスコープ内で紐づけられたAzure キーコンテナインスタンス内の全てのシークレットを利用することが可能となります。
- シークレットスコープへのアクセスをユーザーまたはグループごとに制限したい場合、それぞれのシークレットスコープに対して個別の Azure キーコンテナインスタンスを割り当てる必要があります。
- Azure Key Vault でサポートされるのは、「読み取り」のみです。シークレット値の更新はAzure Key Vault上で行います。
- シークレットスコープの名前は大文字と小文字が区別されません。
Databricks でサポートされるシークレットスコープ
- Azure Databricks によって所有および管理される暗号化されたデータベースに格納されます。
- シークレットスコープの名前は、機密ではないと見なされ、ワークスペース内のすべてのユーザーが読み取り可能です。
- Databricksでサポートされるシークレットスコープは本記事での説明対象外です。
検証内容

- Azure ストレージアカウント コンテナの読み書き権限を設定したShared Access Signature(SAS)の発行し、その値をAzure Key Vaultのシークレットに格納します。
- Databricks グループを2つ準備し、それぞれのグループにユーザーを所属させます。
- Databricks シークレットスコープを1つ準備します。
- 1つのグループにシークレットスコープへの管理権限を付与し、もう1つのグループには何も権限を付与しないことで、権限設定を行ったグループだけがシークレットスコープを参照できることをノートブックの実行結果より確認します。
検証の前提
今回の構成に必要なDatabricksの構成の前提条件は下記の通りです。
- 価格プランがプレミアム以上
- Azure ユーザー アクセス管理者 Azure RBAC ロール
- Databricks ワークスペース管理者権限
検証
Azure ストレージアカウント リソース作成
本作業はAzureポータル UI上で実施します。
Azure ストレージアカウントの作成
作業内容は以下記事をご参照下さい。 また「Hierarchical Namespace(階層型名前空間)」を有効にして、作成してください。 learn.microsoft.com
コンテナの作成
作業内容は以下記事をご参照下さい。 learn.microsoft.com
Shared Access Signature(SAS)の作成
作業内容は以下記事をご参照下さい。
割り当て権限(permissions)は以下を選択してください。
- 読み取り(
Read) - 書き込み(
Write) - 削除(
Delete) - リスト(
List) - 追加(
Add) - 作成(
Create)
Azure Key Vault リソース作成
本作業はAzureポータル UI上で実施します。
キーコンテナインスタンスの作成
キーコンテナ(Key Vault)の一覧画面の画面より「キーコンテナの作成(Create key vault)」を押下します。

■キー コンテナーの作成 > 基本情報(Basics)
以下の設定項目を記載後「次へ(Next)」を押下します。
| 項目 | 設定内容 |
|---|---|
| サブスクリプション(Subscription) | サブスクリプションを選択 |
| リソースグループ(Resource group) | リソースグループを選択 |
| インスタンスの詳細 > Key Vault 名(Key vault name) | Key vault名を記載 |
| インスタンス(Instance details) > リージョン(Region) | リージョンを選択 |
| インスタンス(Instance details) > 価格レベル(Pricing tier) | 標準(Standard)を選択 |

■キー コンテナーの作成 > アクセス構成(Access configuration)
- アクセス許可モデル(Permission model)に「コンテナーのアクセス ポリシー(Vault access policy)」を選択します。
- アクセス ポリシーで「作成」を押下します。

■キー コンテナーの作成 > アクセス構成 > アクセス ポリシーを 1 つ作成する > アクセス許可(Permissions)
シークレットのアクセス許可(Secret permissions)から取得(Get)と一覧(List)にチェック後「次へ(Next)」を押下します。

■キー コンテナーの作成 > アクセス構成 > アクセス ポリシーを 1 つ作成する > プリンシパル(Principal)
「AzureDatabricks」のプリンシパルを選択後「次へ(Next)」を押下します。

■キー コンテナーの作成 > アクセス構成 > アクセス ポリシーを 1 つ作成する > アプリケーション(Application)
「次へ(Next)」を押下します。

■キー コンテナーの作成 > アクセス構成 > アクセス ポリシーを 1 つ作成する > 確認および作成(Review + create)
設定内容を確認後「作成(Create)」押下するとアクセスポリシーが作成されます。

■キー コンテナーの作成 > アクセス構成(Access configuration)
「AzureDatabricks」のプリンシパルが追加されていることを確認後、「次へ(Next)」を押下します。

■キー コンテナーの作成 > ネットワーク(Networking)
- 「パブリック アクセスを有効にする(Enable public access)」にチェックします。
- パブリック アクセス(Public Access) > 許可するアクセス元(Allow access from)で「すべてのネットワーク(All networks)」にチェック(※シークレットの値を保存した後に変更します)

■キー コンテナーの作成 > タグ(Tags)
設定する場合、内容を記載して「次へ(Next)」を押下します。

■キー コンテナーの作成 > 確認および作成(Review + create)
設定内容を確認後「作成(Create)」押下するとリソースが作成されます。

シークレットの格納
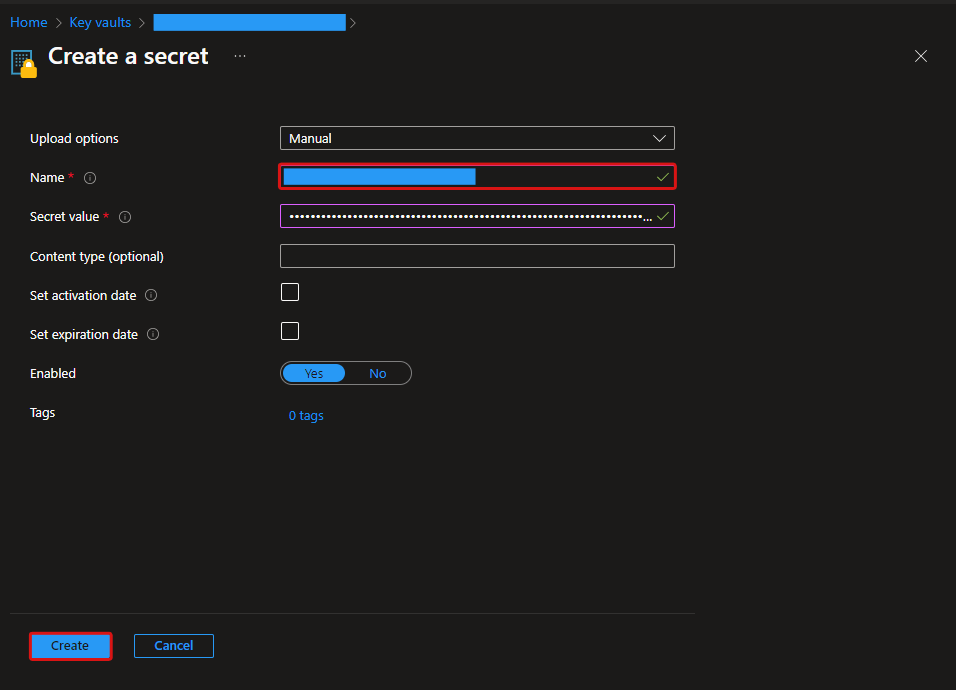
作成したキーコンテナのUIページの左メニューからシークレット(Secret)を選択後、「生成/インポート(Generate/Import)」を押下します。

Nameに任意の名前(Name)とシークレット値(Secret Value)に、本記事で作成したShared Access Signature(SAS)の値を記入します。
ネットワーク構成の変更
作成したキーコンテナのUIページの左メニューからネットワーク(Networking)を選択後以下を実施します。
- 許可するアクセス元(Allow access from)で「特定の仮想ネットワークと IP アドレスからのパブリック アクセスを許可する(Allow public access from specific virtual networks and IP adresses)」を選択します。
- 例外(Exception)で「信頼された Microsoft サービスがこのファイアウォールをバイパスすることを許可する(Allow trusted Microsoft services to bypass this firewall)」を選択します。

Databricksリソースの作成
設定画面は、Databricks UIの右上の自アカウントを押下後のメニューから「管理者設定(Admin Settings)」を選択して開きます。

グループの作成
本検証ではDatabricksアカウントコンソールへアクセス権限がない環境での検証のため、グループはWorkspace上で作成します。
■設定 > ワークスペース管理者 > IDとアクセス(Identity and access)
設定画面より、ワークスペース管理者のIDとアクセスを選択し、グループ(Groups)の「管理(Manage)」を押下します。

■設定 > ワークスペース管理者 > IDとアクセス > グループ(Groups)
「グループを追加(Add Group)」を押下します。

■設定 > ワークスペース管理者 > IDとアクセス > グループ > 新しいグループを作成する(Create new group)
「名前(Name)」に任意の名前を記載し「作成(Create)」を押下します。

※本検証ではグループは権限があるグループとないグループの2つ作成します。
グループメンバーの追加
■設定 > ワークスペース管理者 > IDとアクセス > グループ(Groups)
グループ画面に遷移後、作成されたグループ名を押下します。

■設定 > ワークスペース管理者 > IDとアクセス > グループ > グループの詳細 > Members
グループの詳細画面で「Members」タブを選択後、「メンバーを追加(Add members)」を押下します。

■設定 > ワークスペース管理者 > IDとアクセス > グループ > グループの詳細 > メンバーを追加(Add members)
追加するユーザーを選択後、「追加(Add)」を押下します。

■設定 > ワークスペース管理者 > IDとアクセス > グループ > グループの詳細 > Entitlements
「Workspace access」にチェックします。

※グループは権限があるグループとないグループの2つ作成していますので、それぞれにワークスペースに追加済の任意のユーザーアカウントを所属させています。
トークンの発行
シークレットスコープのアクセス制御には、Databricks CLIを使用します。 Databricks CLIの認証のためのアクセストークンを発行します。
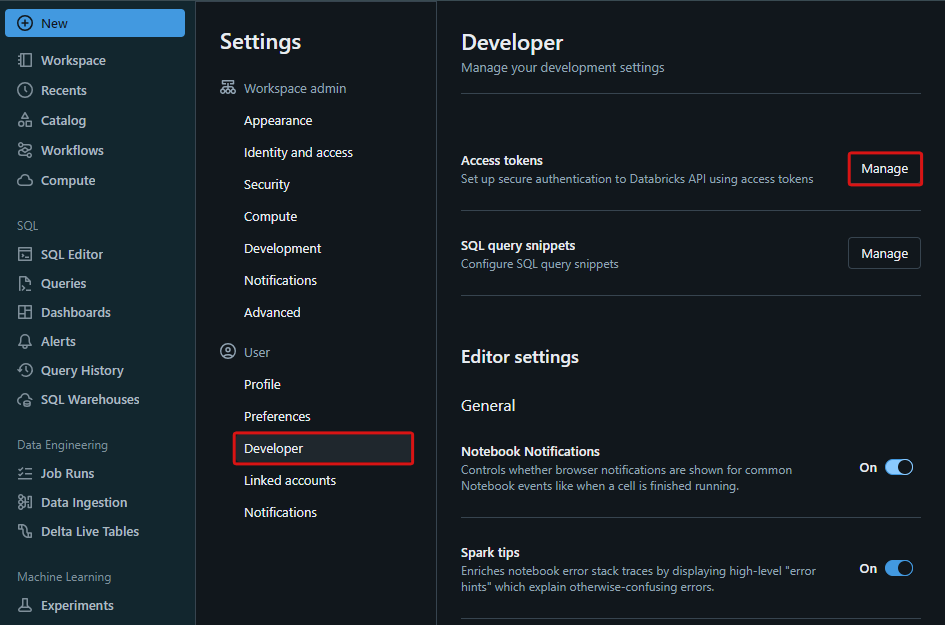
■設定 > ユーザー > 開発者(Developer)
設定画面より、ユーザーの開発者を選択し、アクセストークン(Access tokens)の「管理(Manage)」を押下します。
■設定 > ユーザー > 開発者 > アクセストークン(Access tokens)
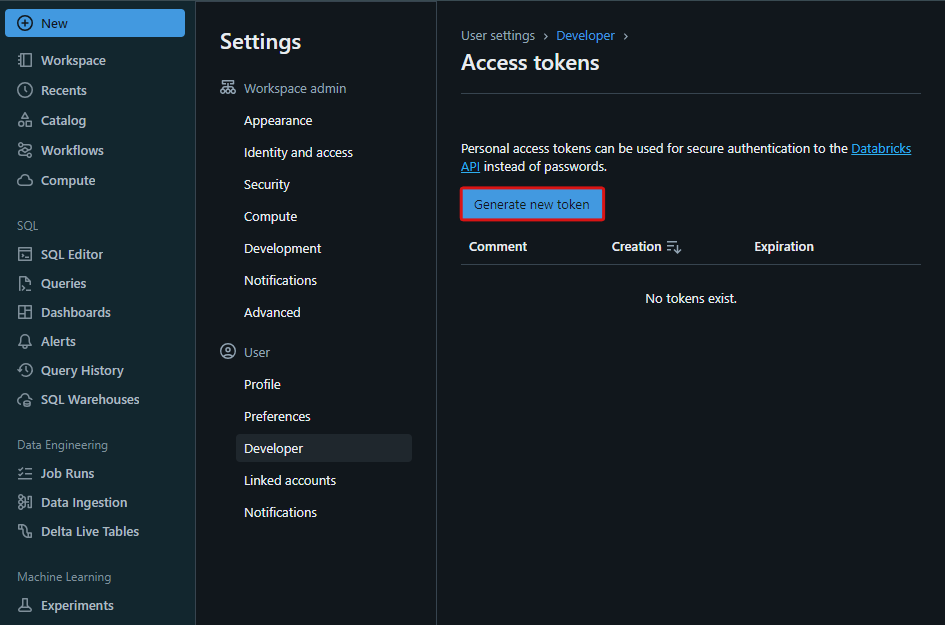
アクセストークン画面で「新規トークンを生成(Generate new token)」を押下します。
■設定 > ユーザー > 開発者 > アクセストークン > 新規トークンを生成(Generate new token)
新規トークンを生成画面で、コメント(Comment)に任意の値と存続期間(Lifetime)に任意の日数を記載し、「生成(Generate)」を押下します。

生成されたトークンが表示されるので値をコピーし、「完了(Done)」を押下します。
※この値の後のDatabricks CLIの設定手順で使用するためコピーしてください。

シークレットスコープの作成
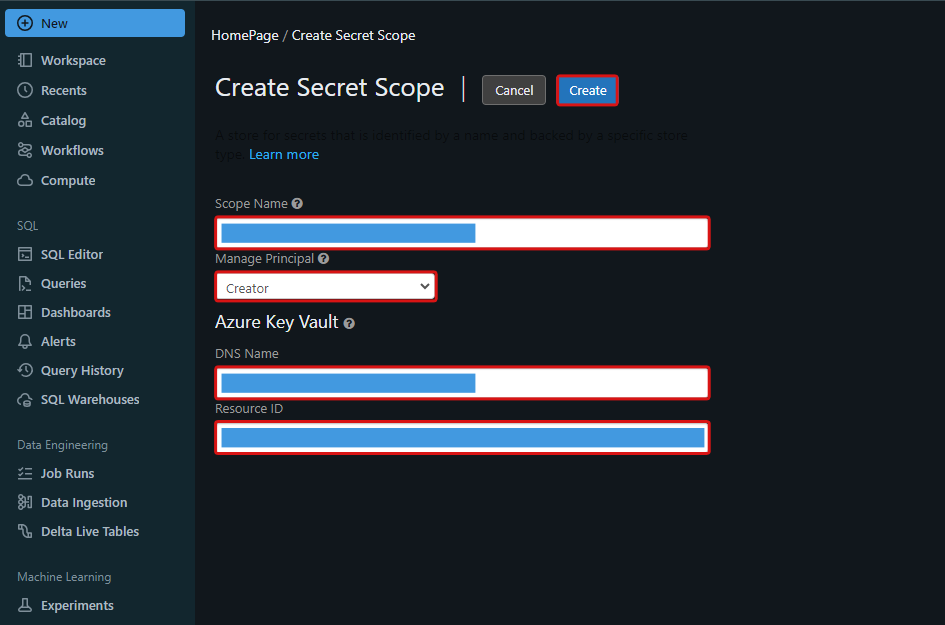
シークレットスコープ作成画面で、以下設定内容で「作成(Create)」を押下します。
| 項目 | 設定内容 |
|---|---|
| Scope Name | シークレットスコープ名を記載 |
| Manage Principal | Creatorを選択 |
| DNS Name | 本記事で作成したKey Vaultインスタンスの概要ページより「コンテナーの URI」を確認し記載 |
| Resource ID | 本記事で作成したKey VaultインスタンスのリソースID |
※シークレットスコープ作成画面はワークスペースのURLの末尾に#secrets/createScopeを追記してアクセスします。
https://<databricks-instance>#secrets/createScope
Databricks シークレットスコープのアクセス制御設定
本作業はVisual Studio Code上でGit Bashのターミナルを開いて実行しています。
※ 本作業はローカルPCにVisual Studio Code、Git Bash、Pythonがインストールされていることを前提に説明します。
権限設定のために必要なDatabricks CLIをローカルPCにインストールします。
$ pip install databricks-cli
Databricks CLIの構成を設定します
Databricks Hostは対象ワークスペースのURLを記載します。(https://<databricks-instance>)Tokenは本記事で作成したトークンの値を入力します。
$ databricks configure --token Databricks Host (should begin with https://): Token:
作成済のシークレットスコープを確認します。
$ databricks secrets list-scopes
※出力結果
Scope Backend KeyVault URL ----------------- -------------- --------------------------------------- <SecretScopeName> AZURE_KEYVAULT https://<KeyVaultName>.vault.azure.net/
本記事で作成したシークレットスコープに自アカウントのプリンシパルにMANAGE権限が付与されていることを確認します。
databricks secrets list-acls --scope ${SecretScopeName}
※出力結果
Principal Permission -------------------------- ------------ <CreateUser_PrincipalName> MANAGE
本記事で作成したグループの1つにシークレットスコープのMANAGE権限を割り当てます。
databricks secrets put-acl --scope ${SecretScopeName} --principal ${Group_PrincipalName} --permission MANAGE
作成ユーザーのMANAGE権限をシークレットスコープから削除します。
databricks secrets delete-acl --scope ${SecretScopeName} --principal ${CreateUser_PrincipalName}
シークレットスコープの権限付与状況を最終確認します。 ここでは、2つ作成したグループのうち1つに割り当てられていることが確認できます。
databricks secrets list-acls --scope ${SecretScopeName}
※出力結果
Principal Permission ---------------------- ------------ <Group_PrincipalName> MANAGE
ノートブックの編集と検証
ノートブックをpythonで実行してシークレットスコープの読み取りを検証していきます。
ノートブック ウィジェットの編集
ノートブックを開き、以下記事を参照にウィジェットにシークレットスコープ名を記載します。

functionsのインポート
DataFrame処理の際に利用するpyspark.sqlのfunctionsをインポートします。
from pyspark.sql.functions import *

SecretScopeからのシークレット読み取り
この処理でシークレットスコープからの読み取りを確認します。
secretScopeName = dbutils.widgets.get("secretScopeName") storageAccountName = dbutils.secrets.get(scope = secretScopeName, key = "storageAccountName") BlobSharedAccessToken = dbutils.secrets.get(scope = secretScopeName, key = "BlobSharedAccessToken") containerName = dbutils.secrets.get(scope = secretScopeName, key = "containerName") path=f"wasbs://{containerName}@{storageAccountName}.blob.core.windows.net/online_retail/raw"
権限が付与されたグループに属するユーザーが実行した場合、以下のように処理が成功します。

権限が付与されていないグループに属するユーザーが実行した場合、以下のように読み取りに失敗します。この結果からシークレットスコープは正しく権限を割り当てたユーザー、グループだけに読み取りが可能であることが確認できました。

以降は読み取り権限が付与されたユーザーが正しくAzure Key Vaultのシークレットに格納された値を読み取り、SASの権限でストレージアカウントへの操作が可能であることを確認していきます。
Spark構成の設定
ユーザーがストレージアカウントのデータ読み取りできるようにするためにSparkの構成を設定します。
spark.conf.set(
f"fs.azure.account.auth.type.{storageAccountName}.dfs.core.windows.net"
, "SAS"
)
spark.conf.set(
f"fs.azure.sas.token.provider.type.{storageAccountName}.dfs.core.windows.net"
, "org.apache.hadoop.fs.azurebfs.sas.FixedSASTokenProvider"
)
spark.conf.set(
f"fs.azure.sas.fixed.token.{storageAccountName}.dfs.core.windows.net"
, BlobSharedAccessToken
)
spark.conf.set(
f"fs.azure.sas.{containerName}.{storageAccountName}.blob.core.windows.net"
, BlobSharedAccessToken
)

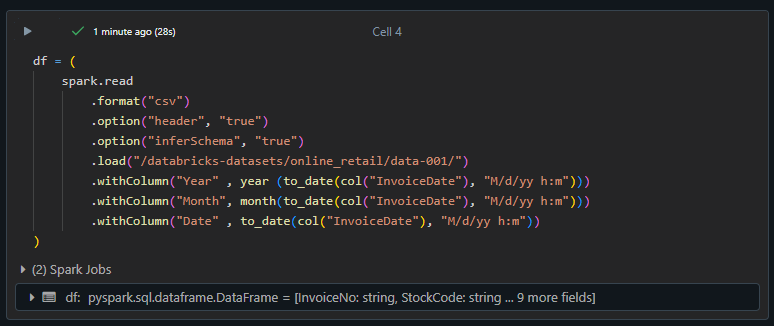
DataFrameの作成
ストレージアカウントへデータを書き込むDataFrameを生成します。
データはdatabricks-datasets配下のonline_retailを利用しています。
df = (
spark.read
.format("csv")
.option("header", "true")
.option("inferSchema", "true")
.load("/databricks-datasets/online_retail/data-001/")
.withColumn("Year" , year (to_date(col("InvoiceDate"), "M/d/yy h:m")))
.withColumn("Month", month(to_date(col("InvoiceDate"), "M/d/yy h:m")))
.withColumn("Date" , to_date(col("InvoiceDate"), "M/d/yy h:m"))
)
Storage Accountへの書き込み
ストレージアカウントへの書き込みを行います。
(
df.write
.format("parquet")
.mode("overwrite")
.save(path)
)
処理が成功しているため、SASの書き込み権限が機能していることが確認できました。

Storage Accountからの読み取り
前の手順でストレージアカウントへ書き込んだデータが読み取り可能であることを確認します。
df = (
spark.read
.format("parquet")
.load(path)
)
display(df)
処理が成功しているため、SASの読み取り権限が機能していることが確認できました。

まとめ
本記事ではAzure Databricks のシークレットスコープとAzure Key Vaultとの連携方法の説明と検証を行いました。
今後もAzure Databricksに関する記事を投稿する予定ですので、是非ご一読下さい。
