
Copilot+ PCは、最先端のAI機能とNPU(Neural Processing Unit)を搭載し、ローカル環境での大規模言語モデル(LLM)の高速かつ効率的な動作を実現します。
本記事では、AMD Ryzen™ AI 9 HX 370搭載したCopilot+PCのローカル環境で、大規模言語モデルを動作させる手順をご紹介します。
動作環境
個人的な購入で予算に限りがあったため、AI機能を搭載し、グラフィック性能も比較的高い「GMKtec EVO-X1」を選択しました。
このモデルには最大50TOPS(Tera Operations Per Second)の性能を持つNPUが搭載されており、軽量な大規模言語モデル(LLM)をローカルで動作させるには十分な処理能力を備えています。
また、Oculinkポートを搭載しているため、外部GPUの接続も可能であり、将来的にはGPUとNPUの性能比較なども試してみたいと考えています。
Lemonade SDK
AMDのAI対応CPU上でLLMアプリケーションを効率的に動作させるために、Ryzen AI向けに最適化された推論サーバー「Lemonade SDK」を採用しました。
インストール
下記サイトにアクセスし、Lemonadeインストーラー(Lemonade_Server_Installer.exe
)をダウンロードして実行します。
https://github.com/onnx/turnkeyml/releases
コンポーネント選択画面で、実行したいモデルを選択します。

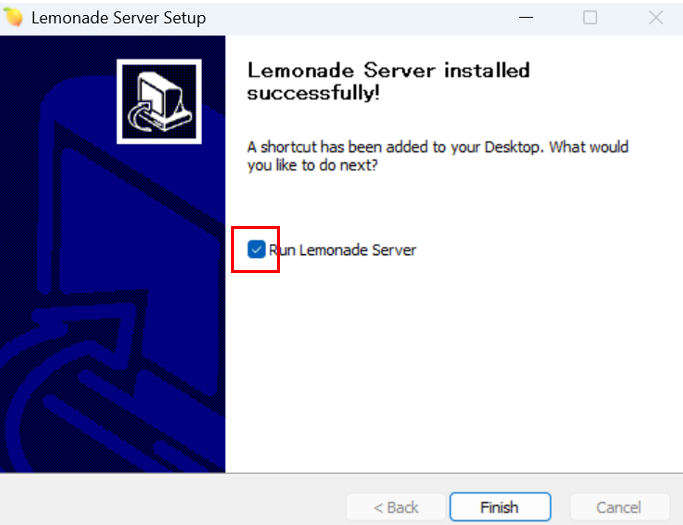
インストール終了画面で「Run Lemonade Server」にチェックをいれて「Finish」ボタンを押します。
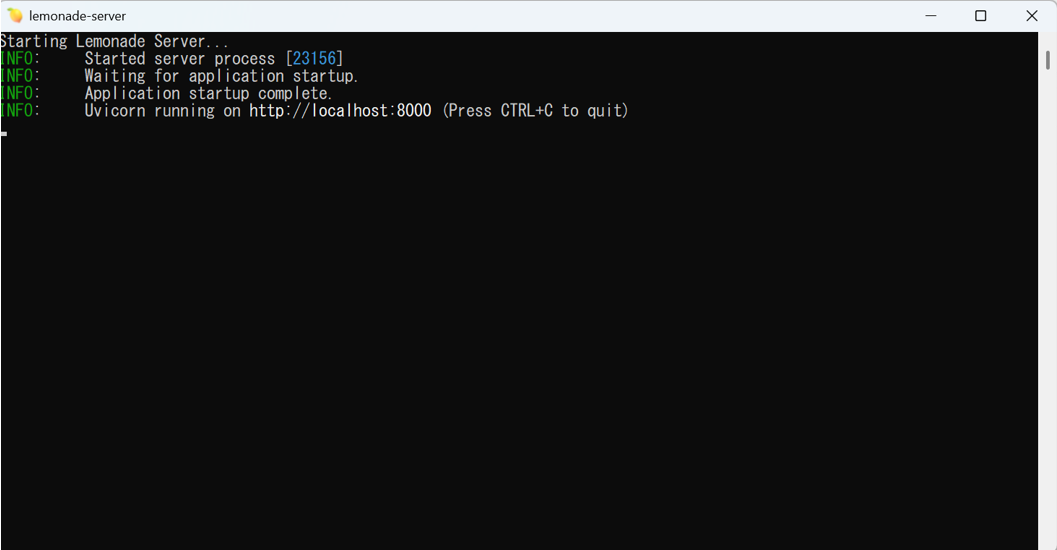
Lemonadeサーバーの起動画面が表示されるので、ウィンドウを閉じずに最小化しておきます。
※ 次回以降はデスクトップのショートカットから起動が可能です。
AI Toolkit for Visual Studio Code
AI Toolkit for Visual Studio Codeを利用することで、フロントエンドの開発を行う必要がなく、ローカル環境でのAIモデルの実行・デバッグ・パラメータ設定などを直感的かつ簡易に行えるため、今回はこのツールを採用しました。
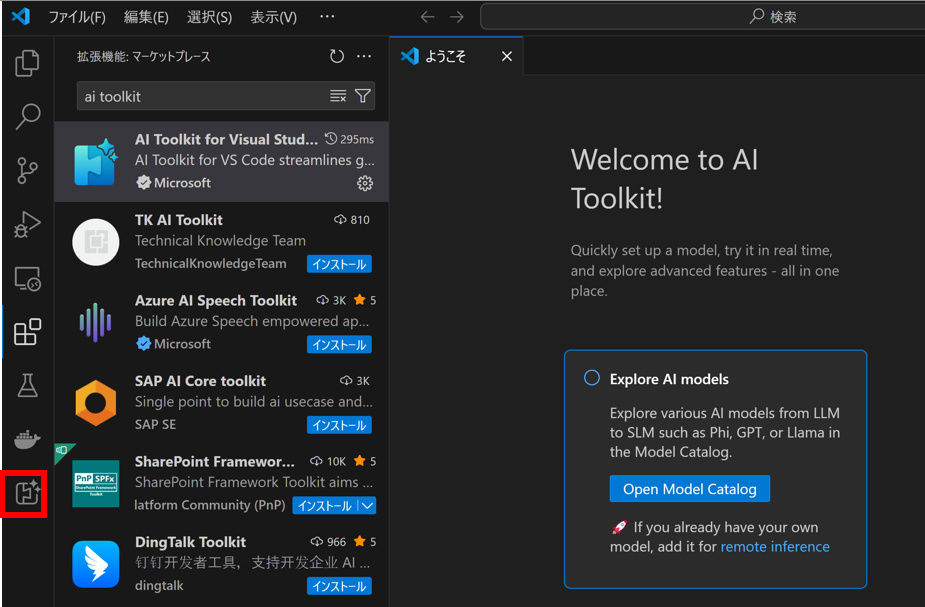
Visual Studio Codeのアクティビティバーから[拡張機能]を選択し、検索バーに「AI Toolkit」と入力します。
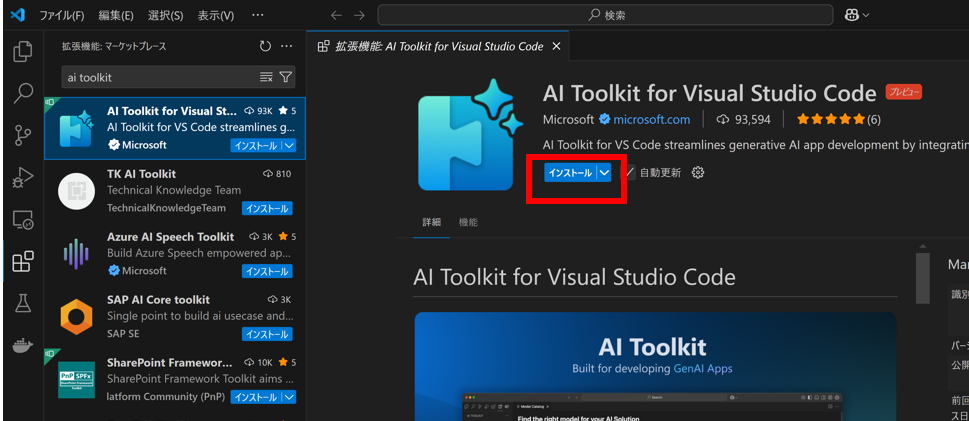
[AI Toolkit for Visual Studio Code] を選択し、[インストール] をクリックします。
インストールが完了すると、アクティビティ バーに AI Toolkit アイコンが表示されます。
カスタムモデル
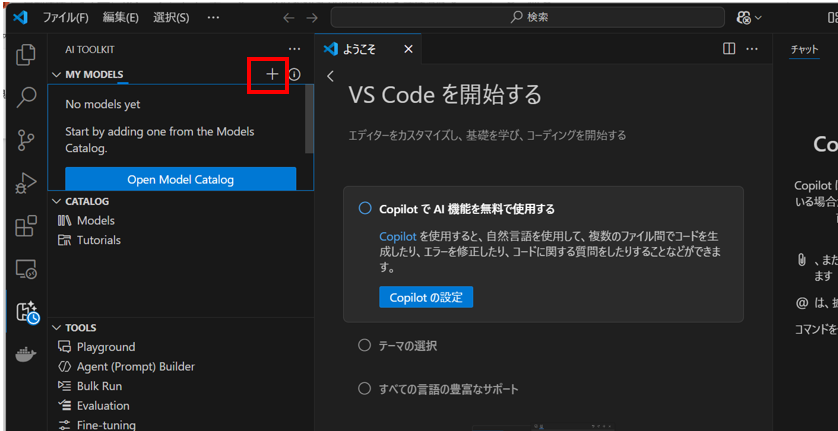
モデルの追加を選択します。
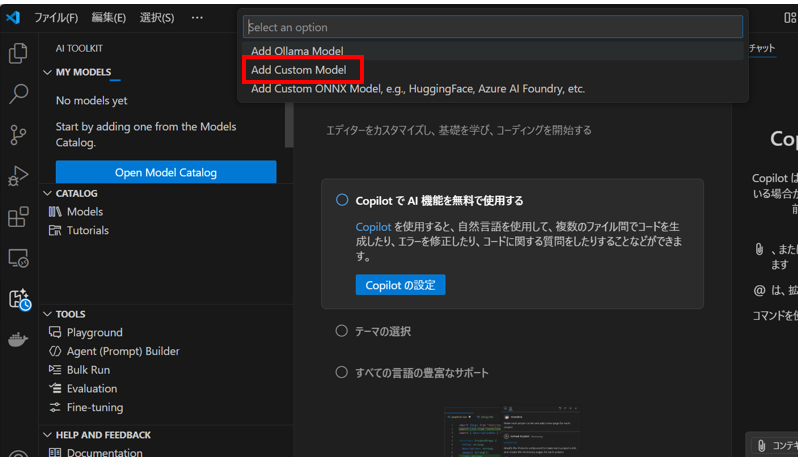
「Add Custom Model」を選択します。
「http://localhost:8000/api/v0/chat/completions」をインプットボックスに入力し、Enterキーを押します。

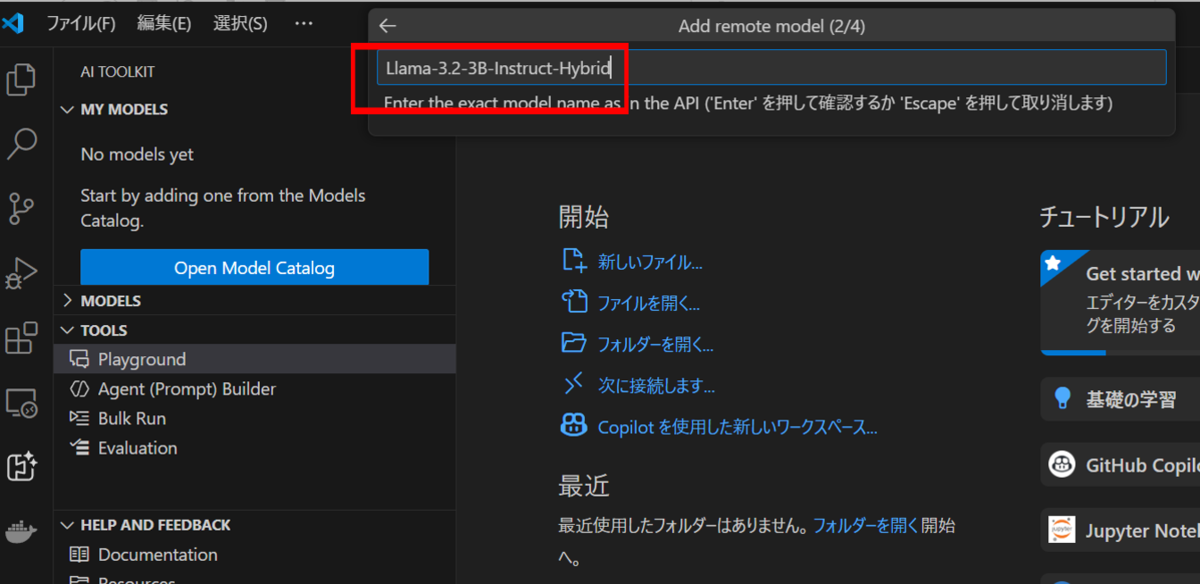
実行したいモデル名をインプットボックスに入力します。モデル名を入力後、Enterキーを押します。
今回は、Metaが開発したオープンソースのLLMモデル「Llama 3.2-3B-Instruct-Hybrid」を使用しました
この画面では、Enterキーを押します。
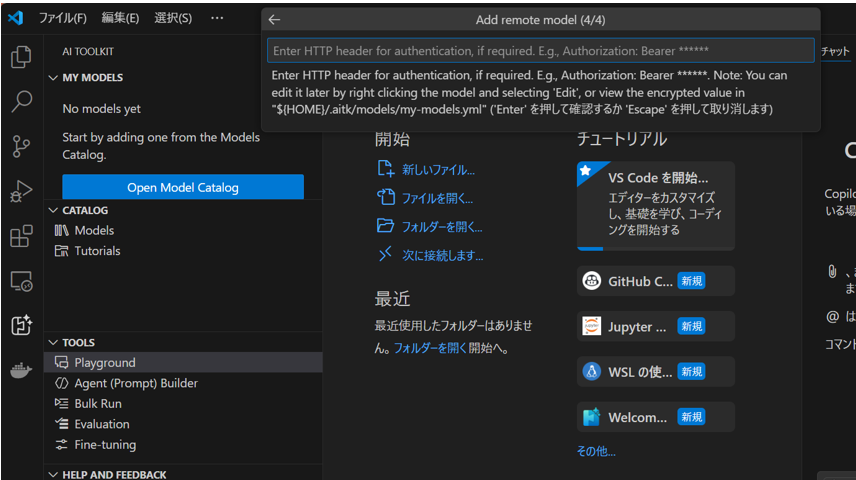
モデル名が表示されたら完了です。
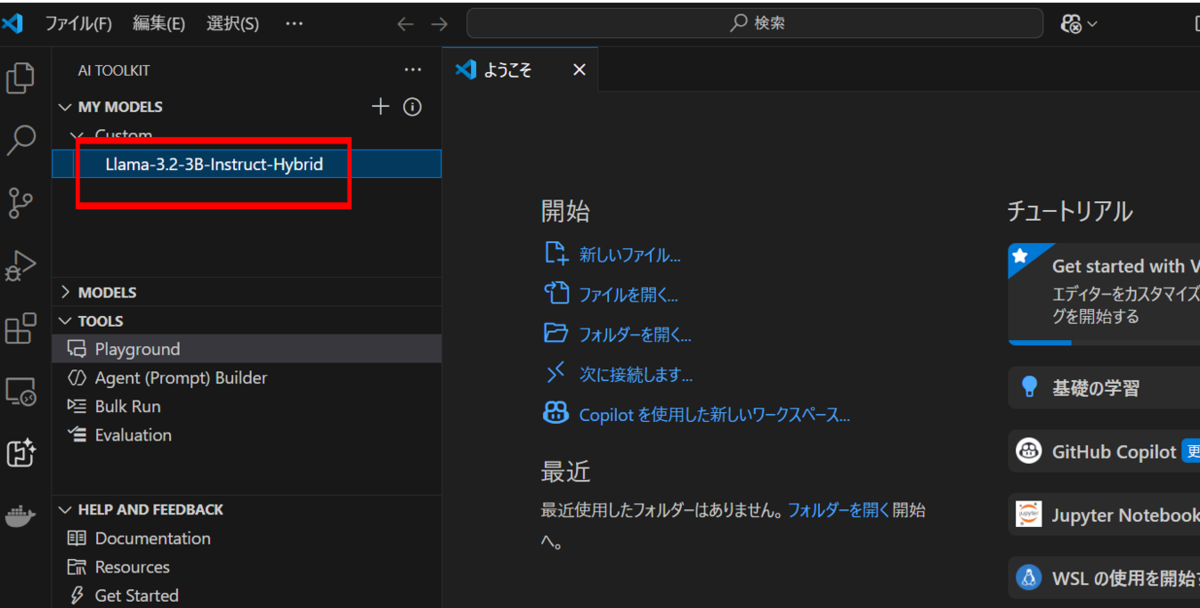
モデルの実行
「Playground」をクリックすると、プロンプト入力画面が表示されます。
プロンプトを入力すると、内部モデルを利用して回答が返ってきます。
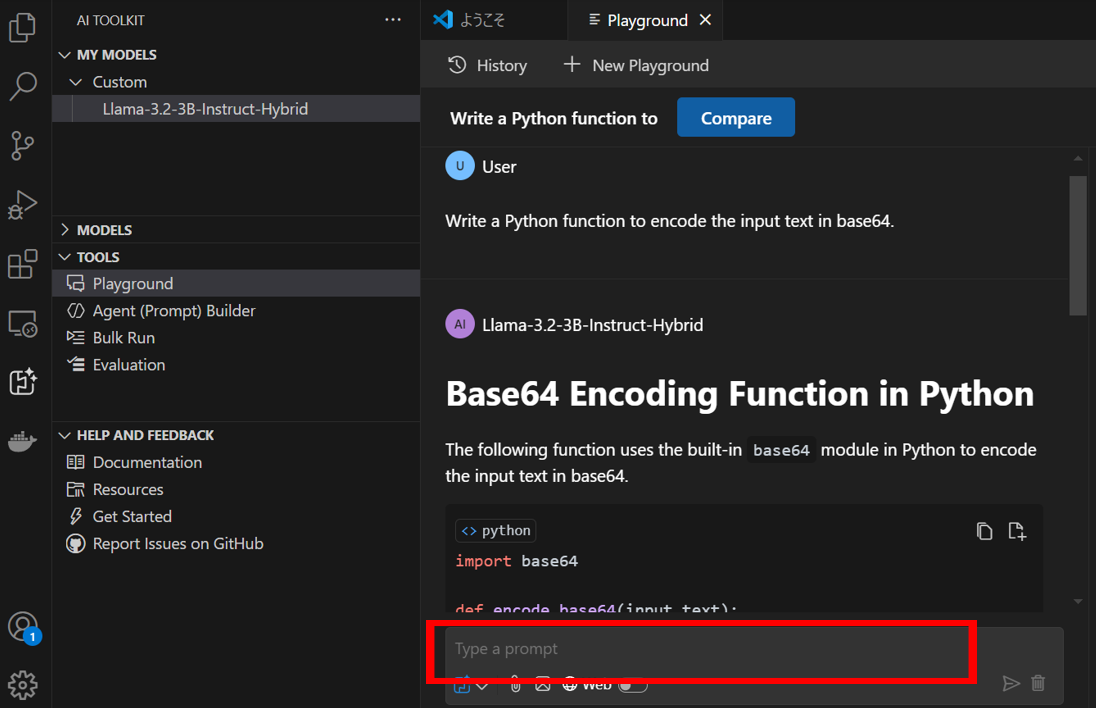
ハイブリッドモデルを利用したため、NPUとGPUがバランスよく利用されています。
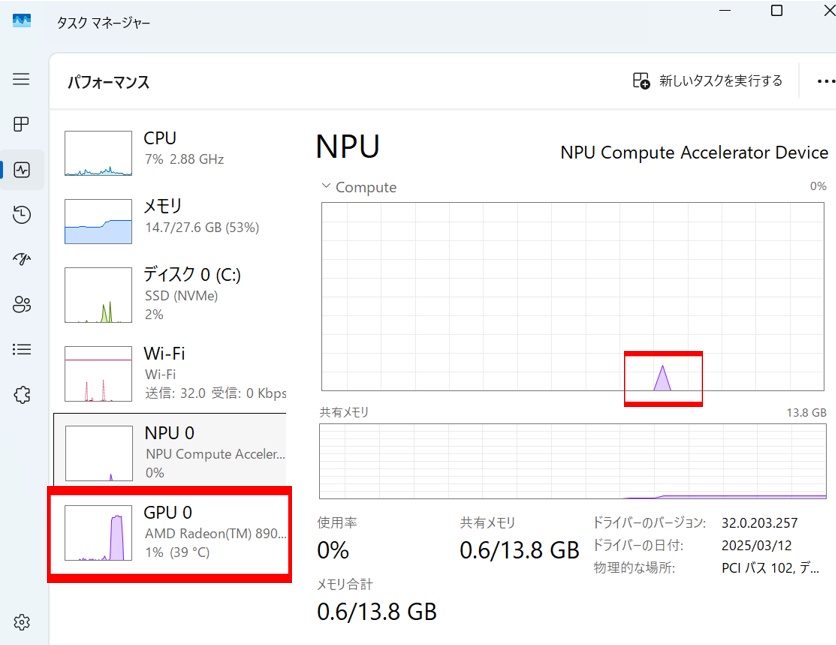
おわりに
本記事では、Copilot+ PCのローカル環境で大規模言語モデルを動作させる手順をご紹介しました。
セキュリティ的な観点からクラウド環境ではなくローカル環境で快適に生成AIを使いたいユーザー様もいると思いますので、今後はローカル生成AIをカスタムデータを利用して活用できるシステム開発も考えてみたいと思います。

神田 英樹(日本ビジネスシステムズ株式会社)
西日本事業本部 クラウドサービス2部3グループに所属しています。主にAzureなどのクラウドサービスを取り扱っています。趣味は特にありませんが、愛犬のお世話をして過ごすことが多いです。
担当記事一覧