
近年、LLM(Large Language Models)に外部データを読み込ませて、学習していない内容についても回答を生成させるRAG(Retrieval Augmented Generation)技術が注目を集めています。
そこで、本記事ではSharePoint Online(SPO)に保存されているデータを対象として、RAGを構築する際のアーキテクチャについて解説していきます。
アーキテクチャ
以下の図が全体像になります。基本的には全てAzure上で動作する前提です。
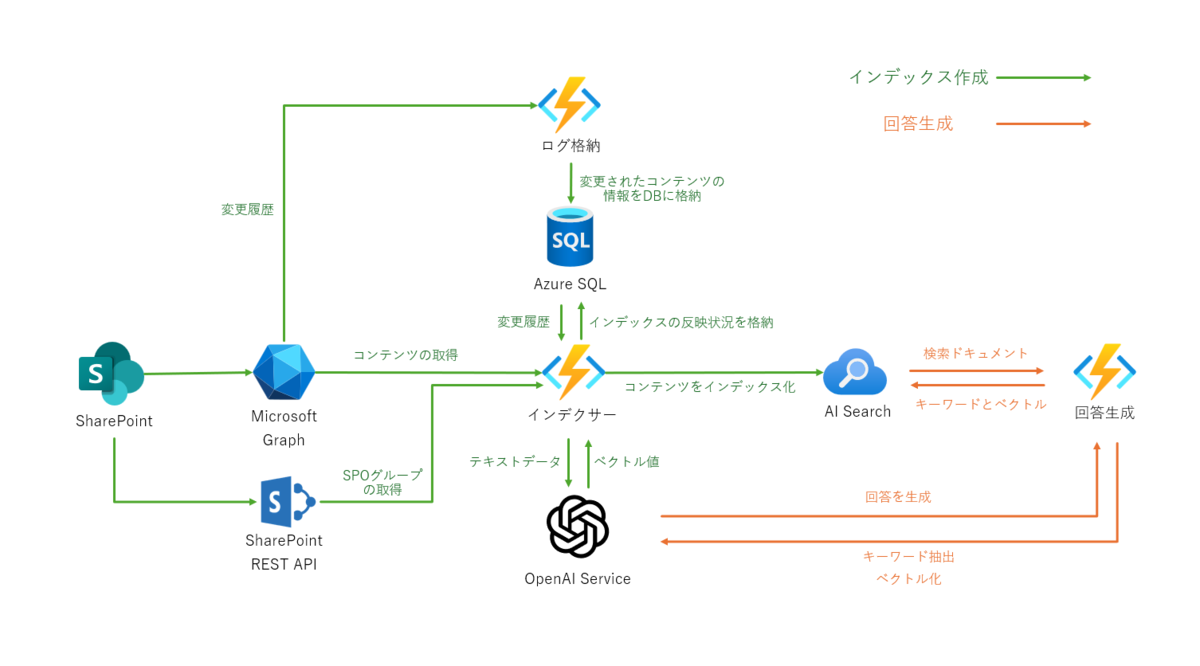
大きく分けると、SPOに保存されているデータをAI Searchに取り込む機能(インデックス作成)と、質問に関連するデータをAI Searchから取得して回答を生成する機能(回答生成)に分けられます。
本記事ではインデックス作成について詳しく解説していきます。
リソース
上記のアーキテクチャで使用しているAzureのリソースは以下の通りです。
| リソース名 | 用途 |
|---|---|
| Azure Functions | SPOへのAPI接続やデータの処理 |
| Azure SQL Database | SPOの変更履歴を管理 |
| Azure AI Search | 処理されたSPOのデータを検索 |
| Azure OpenAI Service | 検索されたデータから回答を生成, データのベクトル化 |
インデックス作成
インデックス作成では、Microsoft Graph と SharePoint REST API を使用してSPOのデータをAI Searchへ取り込みます。
以下の仕組みを定期実行することで、最新のSPOのデータをAI Searchで検索できる状態にできます。
処理1:変更履歴を取得
赤枠内の処理がSPOの変更履歴をSQL DBに保存する処理となります。このDBには、変更されたSPOコンテンツのIDを保存します。後続の処理ではこのIDを元にデータを取得して処理します。
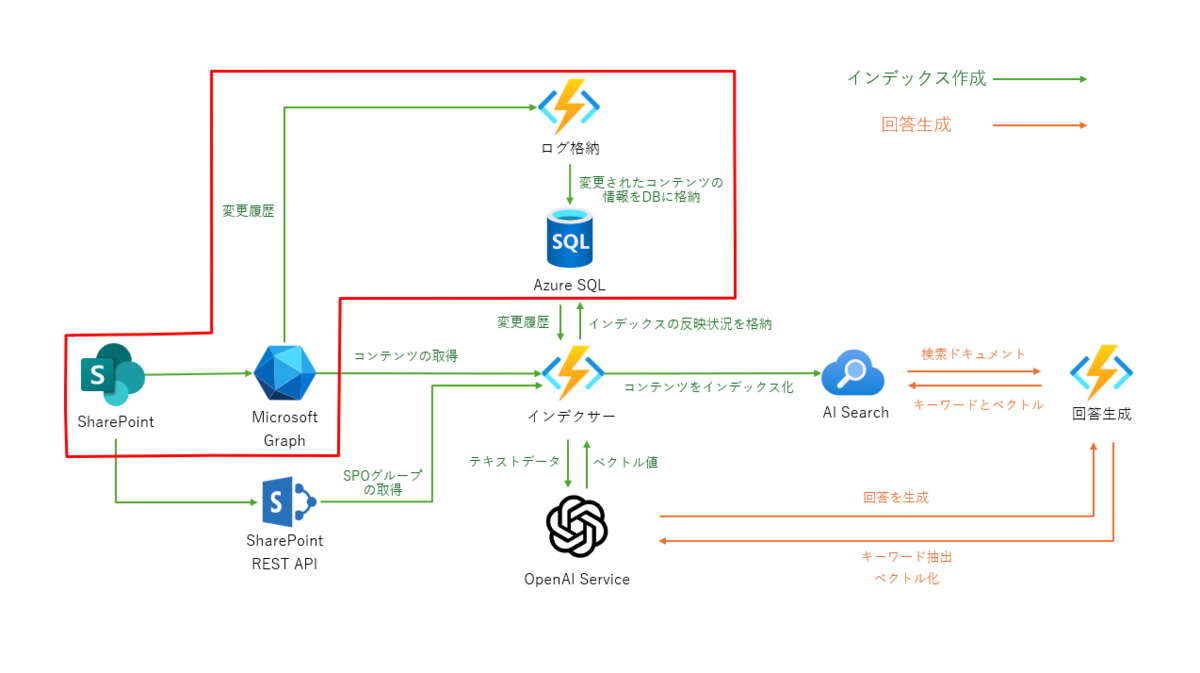
SPOの変更履歴の取得には、Microsoft Graph のデルタ クエリを使用します。詳細は以下を参考にしてください。 learn.microsoft.com
例えば、ドキュメントライブラリの更新情報を取得する場合は、以下のようなリクエストを送信します。
https://graph.microsoft.com/v1.0/sites/{サイトID}/drives/{ドライブID}/root/delta
すると、以下のように変更履歴が取得されます。
HTTP/1.1 200 OK Content-type: application/json { "value": [ { "id": "0123456789abc", "name": "folder2", "folder": { }, "deleted": { } }, { "id": "123010204abac", "name": "file.txt", "file": { } } ], "@odata.deltaLink": "https://graph.microsoft.com/v1.0/me/drive/root/delta?(token='MzslMjM0OyUyMzE7MzsyM2YwNDVhMS1lNmRmLTQ1N2MtOGQ5NS1hNmViZDVmZWRhNWQ7NjM3OTQzNzQwODQ3NTcwMDAwOzU4NTk2OTY0NDslMjM7JTIzOyUyMzA')" }
次回以降の変更履歴は、取得した「@odata.deltaLink」の値をリクエストすることで差分を取得することができます。
処理2:データをAI Searchにインデックス化
次に、先ほどの変更履歴から取得したIDのコンテンツを、AI Searchにインデックス化していきます。
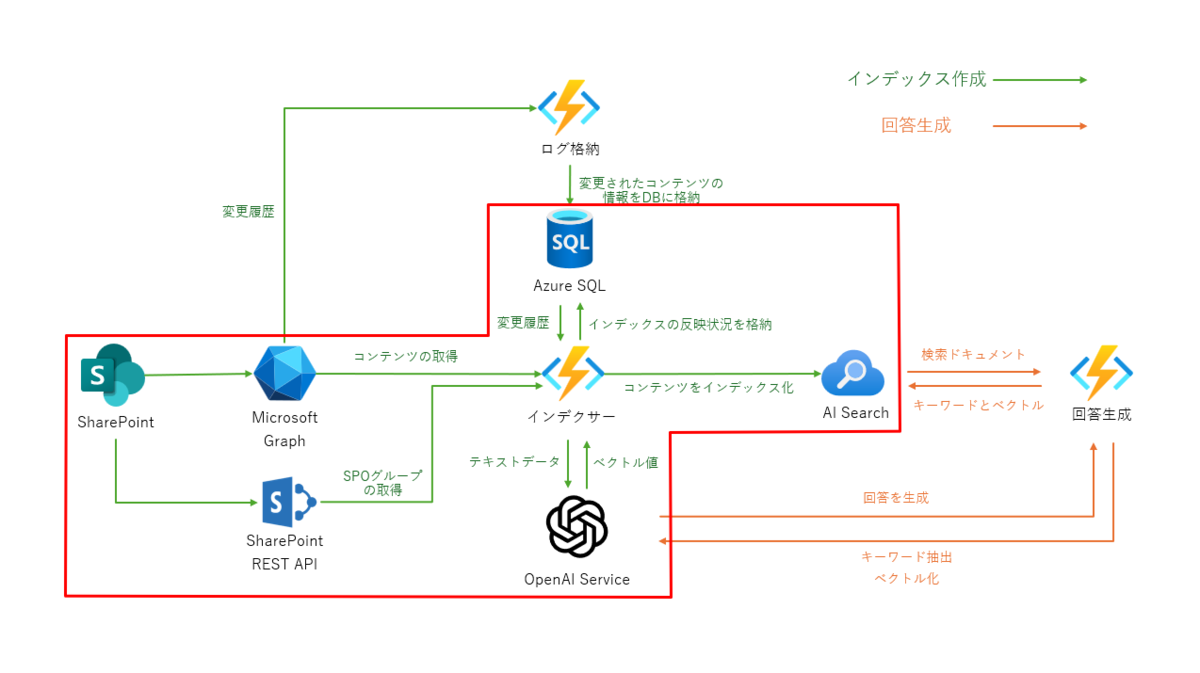
SPOのコンテンツを取得する方法については、以下の記事にて詳しく解説しています。
取得したコンテンツからPythonなどを用いてテキストを抽出し、OpenAIでベクトル化したテキストと一緒にAI Searchに格納します。
このときに、適切なサイズにテキストを分割して格納することが重要です。
また、SPOコンテンツに付与されているアクセス権限も取得してAI Searchに格納します。 権限取得については以下を参考にしてください。
ただし、SPOグループについての情報がMicrosoft Graph だけでは取得できないため、SharePoint REST API を使用して取得します。
以下のように、対象サイトのURLとグループIDを指定してリクエストを送ることで、SPOグループの情報を取得することができます。
https://jbsairpj.sharepoint.com/sites/{サイト名}/_api/Web/SiteGroups/GetByID({対象グループID})/Users
回答生成
AI Searchに格納されたSPOデータを質問内容に応じて検索し、その情報を元にLLMが回答を生成します。
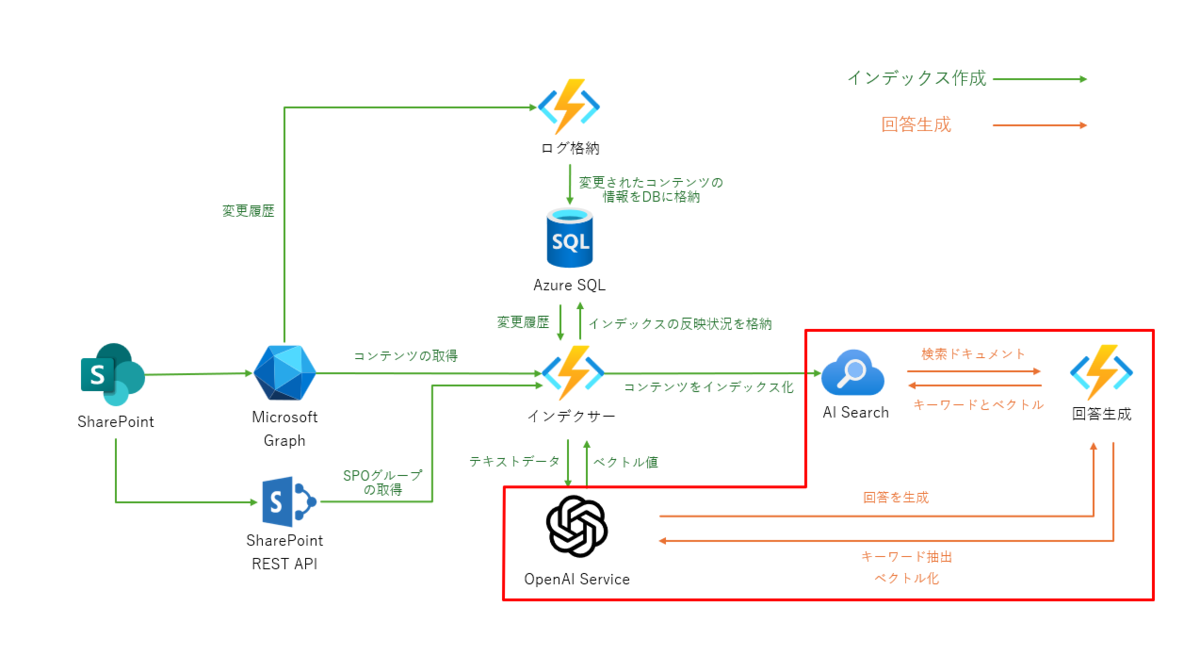
まず、質問文をAzure OpenAI Serviceを使用してキーワードとベクトルに変換します。取得したキーワードとベクトルを用いてAI Searchで検索を掛けます。
取得したテキストデータを以下のように成形し、LLMに回答を生成してもらいます。
{質問文}
Sources:
===========
file: HOGE.pdf, P1_2
title: fuga
content: テキストデータ
===========
file: HOGE.pdf, P3_4
title: fuga
content: テキストデータ
===========
file: HOGE.pdf, P10_12
title: fuga
content: テキストデータ
おわりに
本記事では、SharePoint Online(SPO)を対象としてRAGを構築する際のアーキテクチャについて解説しました。
今回はSPOを対象として解説しましたが、他のクラウドストレージでも同じようにこのアーキテクチャを流用することはできると思います。
RAGのデータソースに困っている方の参考になれば幸いです。
