
近年、WhisperやGPT-4 Turbo Visionなどの実装によってマルチモーダル化が進んでいます。またAzure AI Service上で使用できるモデルの種類も増加し、容易に使用できるようになりました。
今回の記事では音声系のAIを使用したチャットボットを構築します。ChatGPTを使用するためにはキーボードから文字を入力する必要がありますが、音声のみで完結する仕掛けを目指します。また、発声からレスポンスまでのユーザーの待機時間がどの程度になるのかを検証します。
概要
今回の記事では検証のため、ローカル環境上でPythonスクリプトを動作させます。Azure AI Service上のモデルにアクセスするAPIを使用して、音声アシスタントが実現できるかを確かめます。
以下のような処理を想定します。
- ユーザーの発生した音声をテキスト化する(speech-to-text)
- GPT-4でテキスト化した文章から会話を生成する(ChatGPT)
- Speech-To-TextでAIの回答を発話する(text-to-speech)
実装
前準備
Azure環境
Azure OpenAI Service
ChatGPTを使用するため、Azure OpenAI Serviceをデプロイします。今回の記事では例として、JapanEastリージョンに構築したGPT-4モデルを使用します。
Azure AI Speech Service (音声サービス)
Speech-to-TextとText-to-Speechを使用するため、音声サービスをデプロイします。
Azureポータルから「音声サービス」と検索してデプロイを進めます。
各プラン毎の利用料金は以下をご参照ください。 azure.microsoft.com
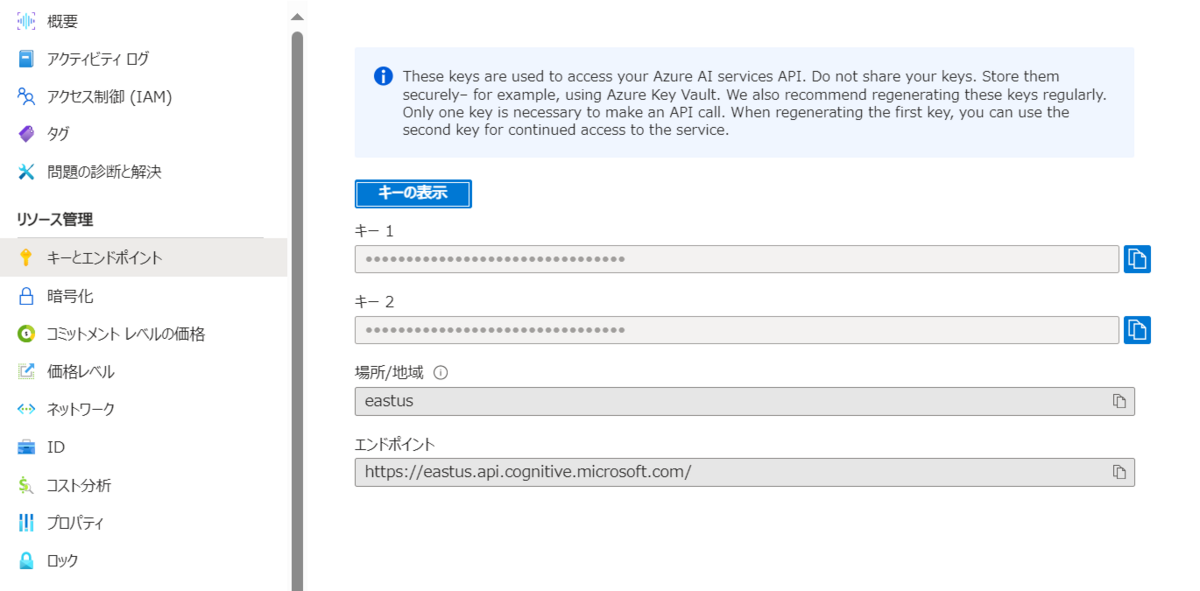
プログラムで使用するため、デプロイ後に「キー1」と「場所/地域」の値を控えておきます。エンドポイントのURLは使用しません。
ローカル環境
今回はJupyter Notebook上で検証を行うものとします。
事前にCognitive Serviceのパッケージをインストールします。
pip install azure-cognitiveservices-speech
以下のモジュールをインポートします。
import json import base64 import requests import os import openai import azure.cognitiveservices.speech as speechsdk from IPython.display import Audio
AI Speech Serviceにアクセスするパラメータをセットします。
ai_sppech_reagionとai_speech_keyには、先ほど控えておいた値を使用します。
ai_speech_region = "" ai_speech_key = "" openai.api_type = "azure" openai.api_key = API_KEY openai.api_base = RESOURCE_ENDPOINT openai.api_version = "2024-02-01"
関数を定義する
1. Speech-to-Text
音声文字起こしはOpenAIのWhisperモデルを使用することもできますが、リアルタイム変換ではAzure AI Speech モデルが推奨されているため、こちらを使用します。 learn.microsoft.com
以下のコードでマイクから音声を収集して、テキスト化します。
def recognize_from_microphone(): speech_config = speechsdk.SpeechConfig(subscription=ai_speech_key, region=ai_speech_region) speech_config.speech_recognition_language="ja-jp" audio_config = speechsdk.audio.AudioConfig(use_default_microphone=True) speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config) print("Speak into your microphone.") speech_recognition_result = speech_recognizer.recognize_once_async().get() if speech_recognition_result.reason == speechsdk.ResultReason.RecognizedSpeech: print("Recognized: {}".format(speech_recognition_result.text)) return speech_recognition_result.text elif speech_recognition_result.reason == speechsdk.ResultReason.NoMatch: print("No speech could be recognized: {}".format(speech_recognition_result.no_match_details)) return None elif speech_recognition_result.reason == speechsdk.ResultReason.Canceled: cancellation_details = speech_recognition_result.cancellation_details print("Speech Recognition canceled: {}".format(cancellation_details.reason)) if cancellation_details.reason == speechsdk.CancellationReason.Error: print("Error details: {}".format(cancellation_details.error_details)) print("Did you set the speech resource key and region values?") return None
関数が呼び出されるとマイクを使用して音声を収集し、AI Speech Serviceに送信してテキストを取得します。
音声を認識してテキストに変換する方法の詳細は、以下のドキュメントをご参照ください。 learn.microsoft.com
2. ChatGPT
以下のコードでAzureOpenAIにリクエストを送信する関数を定義します。システムプロンプトやモデル名などのパラメータは、適時書き換えてください。
system_prompt = """ あなたは親切なAIアシスタントです。 """ def req_oai(input): input.insert(0, {"role":"system","content":system_prompt}) response = openai.ChatCompletion.create( engine="gpt-4", messages=input, max_tokens=1000, temperature=0 ) return response # 疎通確認 print(req_oai_func([{"role":"user","content":"こんにちは"}]).json())
3. Text-to-Speech
次の関数で、AIの生成した文章をAI Speech Serviceで音声化してmp3ファイルに保存します。ローカル環境に保存した後にmp3ファイルを自動再生します。
def txt_to_speech(output_filename, text): speech_config = speechsdk.SpeechConfig(subscription=ai_speech_key, region=ai_speech_region) speech_config.speech_synthesis_voice_name = "ja-JP-NanamiNeural" audio_output = speechsdk.audio.AudioOutputConfig(filename=output_filename) speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_output) result = speech_synthesizer.speak_text_async(text).get() # Check result if result.reason == speechsdk.ResultReason.SynthesizingAudioCompleted: return elif result.reason == speechsdk.ResultReason.Canceled: cancellation_details = result.cancellation_details print("Speech synthesis canceled: {}".format(cancellation_details.reason)) if cancellation_details.reason == speechsdk.CancellationReason.Error: print("Error details: {}".format(cancellation_details.error_details)) return
テキスト読み上げの話者は7種類提供されており、今回の記事ではja-JP-NanamiNeuralを使用します。
learn.microsoft.com
Azure OpenAI ServiceのText-to-Speechを使用することもできますが、今回は処理速度を考慮してAI Speech Serviceを使用しました。詳細は以下の記事をご参照ください。
blog.jbs.co.jp
1~3の関数を使用して音声チャットを開始する
以下のコードからAzure AI Serviceにリクエストを送信します。 サンプルとして3回連続して会話するようにループを作成しています。
import time chat_history = [] output_filename = "output.mp3" # tempファイル的に上書き保存する for i in range(3): message = recognize_from_microphone() if message is None: continue else: print("processing......") chat_history.append({"role":"user","content":message}) req = req_oai(chat_history).json() response_message = req["choices"][0]["message"]["content"] print(response_message) chat_history.append({"role":"assistant", "content":response_message}) txt_to_speech(output_filename, response_message) display(Audio(output_filename, autoplay=True)) time.sleep(int(os.path.getsize('output.mp3')/1000/29.1))
動作検証
複数のモデルを組み合わせることでチャットサービスとして利用することができますが、ユーザーからの問いかけに素早くレスポンスを返す必要があります。
- Speech-To-Text : 発話待機時点から文章化までにかかった時間(ユーザーの喋っている時間が含まれます)
- ChatGPT(JapanEast,GPT-4, 1K TPM) : リクエストにかかった時間
- Text-To-Speech : 文字をmp3に変換するまでにかかった時間
以下に実際に対話してかかった処理時間の例を示します。
| 質問 | 回答 | Speech-to-Text(秒) | ChatGPT(秒) | Text-To-Speech(秒) |
|---|---|---|---|---|
| こんにちは、今日もいい天気ですね。 | こんにちは、お客様。そうですね、素晴らしい天気ですね。何かお手伝いできることがありましたら、お知らせください。 | 6.06 | 5.69 | 2.14 |
| 東京のお勧めのお出かけスポットを三つ教えてください。 | もちろんです、お客様。東京にはたくさんの魅力的な観光スポットがありますが、特にお勧めの3つをご紹介いたします。 1. 上野公園:歴史ある動物園、美術館、博物館を含む広大な公園で、四季折々の美しさを楽しむことができます。特に春の桜の季節は見物です。 2. 浅草:雷門や浅草寺、仲見世通りといった観光名所が集まるエリアで、日本の伝統的な文化と歴史を体験できます。お土産探しにも最適です。 3. 六本木ヒルズ:東京の夜景を一望できる展望台や、各種レストラン、ショップ、美術館などが集まった複合施設です。特に森美術館は現代アートの展示で知られています。 それぞれ異なる魅力を持つスポットですので、時間と興味に合わせて訪れてみてください。 |
6.01 | 13.26 | 4.82 |
| 雷門ってどんなとこ? | 雷門は東京の浅草地区に位置する、浅草寺の正門として知られる観光名所です。正式名称を「風雷神門」といいます。高さ約11.7メートル、幅約11.4メートル、奥行き約7メートルの大きな門で、「雷神」と「風神」の立像がそれぞれ左右に設置されています。 特に夜にはライトアップされ、その美しい光景は訪れる人々を魅了します。また、門の下をくぐると浅草寺や仲見世通りへと続く道に出ますので、浅草散策のスタート地点としても最適です。雷門の大きな提灯には「雷門」と書かれており、その姿を見ると東京・浅草に来たという実感が湧くことでしょう。 |
4.61 | 12.10 | 4.25 |
音声入力のテキスト化も、テキストの発話についても問題なく綺麗に読み上げてくれました。
ユーザーの入力した文字のテキスト化は非常に素早く行われており、音声化も長くて5秒程度と素早く処理することができています。
ChatGPTのレスポンスに6~13秒程度かかっているため、ユーザーの待機時間はおおむね10秒から20秒程度という結果になりました。
今回はChatGPTのTPMが低い環境で行いましたが、より高速に処理する設定・モデルを使用することで、かなり現実的な待機時間で音声チャットアシスタントが構築できる可能性があることが分かりました。
おわりに
Azure AI ServiceではChatGPTに限らず画像や音声などマルチモーダル化が進んでおり、今回は音声チャットサービスが作成できると考えて実際に試してみました。API化されていることもあって実際のプログラムは非常に簡単で、処理時間も10~20秒程度とかなり現実的な値となりました。
現状ではマルチモーダルなAIを使用したサービスが世に出始めたばかりですが、複数AIの組み合わせによって多くの課題を解決できる時代になったと実感しました。
今後も有効な活用方法を検討していきます。
