
はじめに
前回に引き続き、大変ニッチな内容となっております。
ブログの記事内の見出し要素の利用傾向を分析するために、正規表現でデータを加工するところまでやりました。今度は実際に読み込んでみたいと思います。
Excelで読み込む
テキストを読み込んでPower Queryで、と思っていたのですが、どうもテキスト内にあるテーブル情報を読みに行ってしまうらしく、思ったように読み込めませんでした。
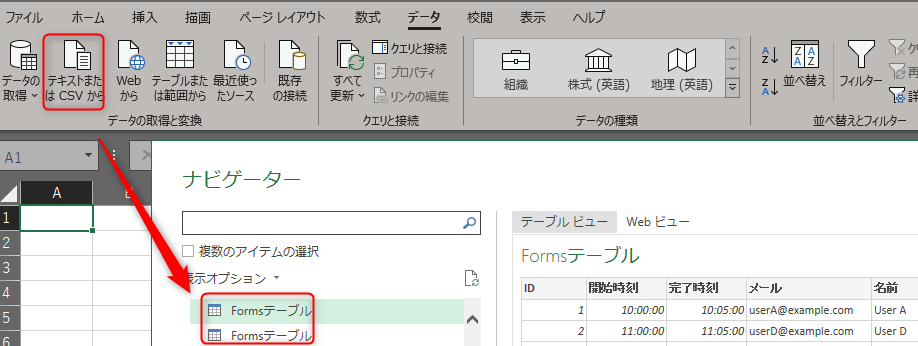
仕方がないので、一度、Power Queryを使わずにExcelで読み込みます。
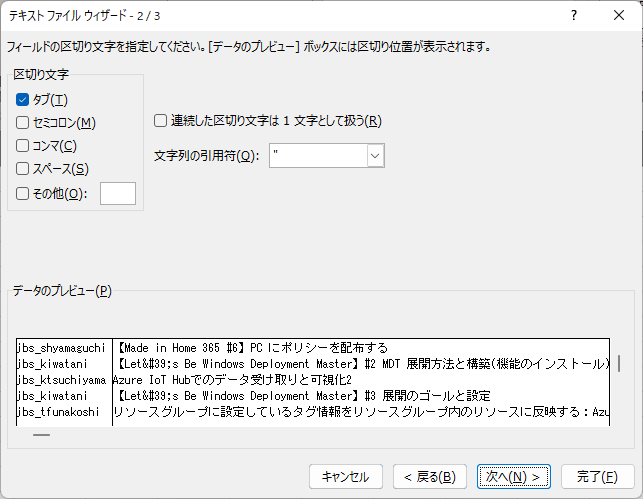
ヘッダを加えてテーブル形式にし、幅をそろえるとこうなりました。(下書きデータなども入っているのでフィルタしています)

Power Queryで分析する
データを読み込む
このままExcel関数を使って分析してもいいのですが、今回はPower Query使いたいので、このテーブルをPower Queryで読み込みます。
まず、「テーブルまたは範囲から」で読み込みます。
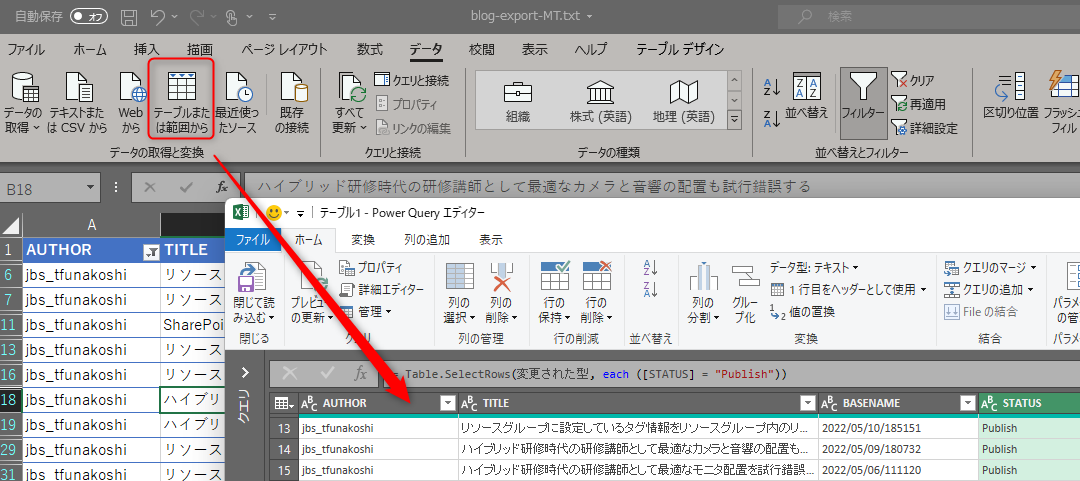
必要な列だけに絞ります。CATEGORYは手間かけたんですが実は今回は不要でした。

見出しを分析する列を作る
Text.Containsを使います。
こんな感じですね
Text.Contains([BODY],"<h1")
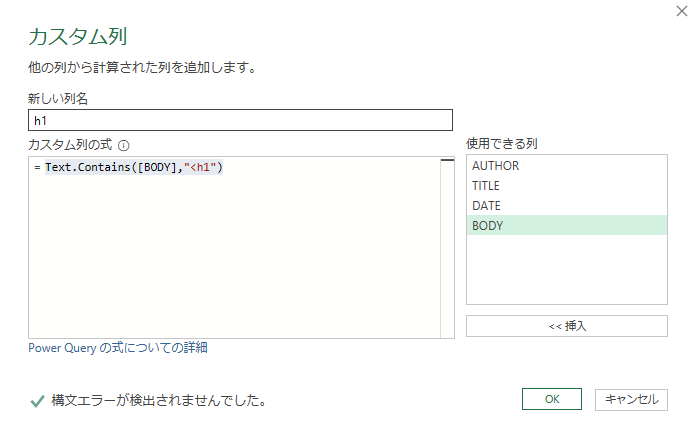
同じようにh2-h6まで作ります。
こんな感じになりました。

これでいったんPower Queryは終わりにして、Excelでフィルタしながら確認してみたいと思います。
Excelのフィルタで確認する
前提
今回、見出しのルールとしては以下のようなものを作るつもりです
- 見たまま編集に合わせて、h3, h4, h5を利用する*1
- 見出しを使うときはh3,h4,h5の順で使う(h3,h5など途中を抜かない)
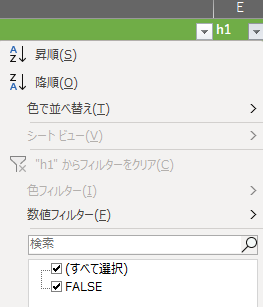
h1要素の確認
h1は使われていませんでした。
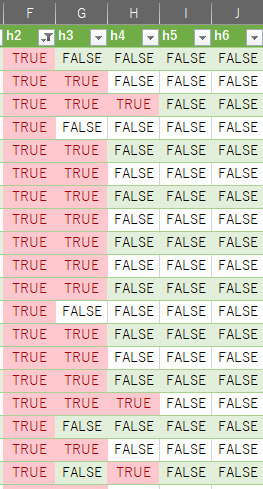
h2要素の確認
h2は結構使われてました*2。また、中にはh2とh4、といったものもありました。
記事を修正する
後は修正するだけなんですが、ここは近道がないので、絞り込んだデータを見ながら手動で修正をかけます。*3
おわりに
ということで何とか分析をすることができました。
もちろん見出し以外にもできると思いますが、記事全部をHTMLレベルで分析する機会が果たしてどれくらいあるかは疑問です。
もしも誰かの役に立てたのであれば幸いです。

舟越 匠(日本ビジネスシステムズ株式会社)
人材開発部に所属。社内向けの技術研修をしつつ、JBS Tech Blog編集長を兼任。Power AutomateやLogic Appsが好きで、キーマンズネットでPower Automateの記事を書いたり、YouTubeのTechLIVE by ITmediaチャンネルでPower Automateの動画に出演したりもしています。好きなアーティストはZABADAKとSound Horizon。
担当記事一覧