
この記事は2記事に渡るシリーズもので、Azure Synapse AnalyticsのPipeline機能(以下Synapse Pipeline)を用いて、Azure Data Lake Storage(以下ADLS)上のExcelファイルをAzure Synapse 専用SQLプール(以下専用SQLプール)にテーブルとしてロードする手順を紹介しております。
前編記事では事前に必要になるADLS、Azure Synapse Analytics ワークスペース(以下Synapseワークスペース)、専用SQLプールの作成について紹介させていただきました。
今回の後編記事では、それらを使いながらSynapse Pipelineを作成するところを紹介する予定です。
Azure Synapse Analyticsの検証中の方や導入を検討している方はぜひご参考ください!
料金についての注意事項
今回の検証には少なからず課金が発生します。主な金額発生源は以下になります。
- 専用SQLプールのコンピューティングリソース
- 専用SQLプールのストレージ料金
- ADLSのストレージ料金
特に専用SQLプールのコンピューティングを停止し忘れると高額になる可能性がありますので、検証しない際にはこまめに停止することをおすすめします。
「専用SQLプールの作成」の項で停止方法について紹介しておりますので、注意深くご確認ください。
※専用SQLプールのストレージ料金は専用SQLプールを停止しても発生し続けるので、しばらく検証しない期間がある際は削除することをおすすめします。
※専用SQLプール以外のサービスも、しばらく検証をしない期間などがある際は削除することをおすすめします。
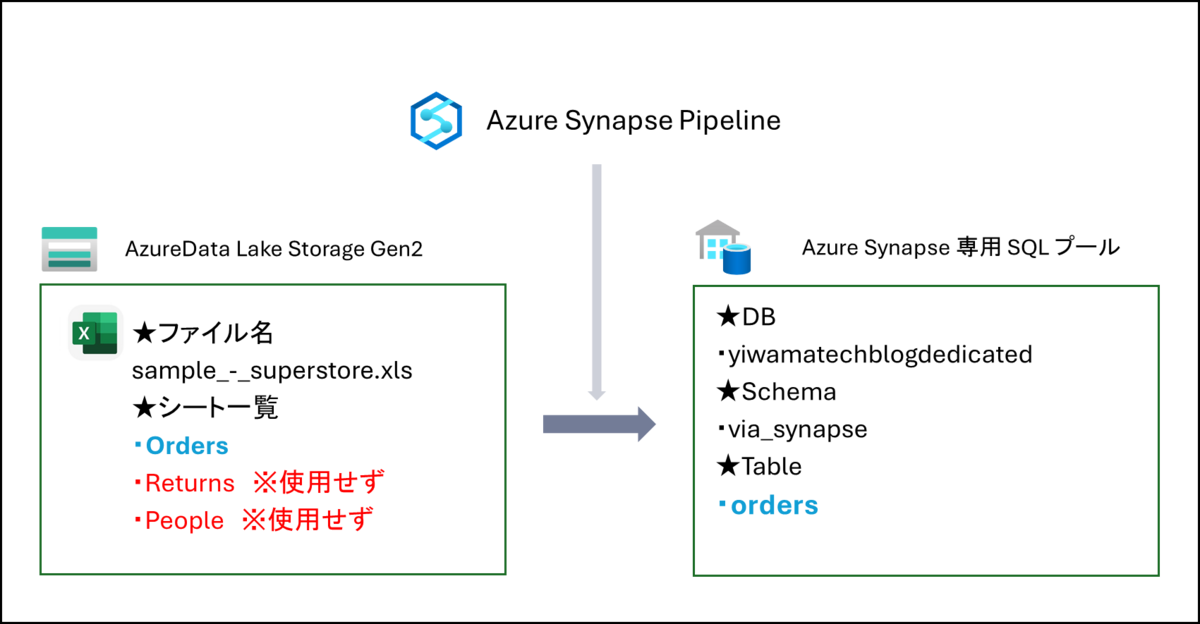
環境構成図
今回の検証ではADLS上にあるExcelファイル「sample_-_superstore.xls」の内「Orders」というシートを専用SQLプールに「orders」というテーブル名で格納します。
それを実現するSynapse Pipelineを作成していきます。
専用SQLプールの開始
まずは前回作成した専用SQLプールを開始します。
この時点から専用SQLプールのコンピューティング料金がまた発生しますのでご注意ください!
Synapse Studioを開いて、画面左ペインの鞄マークの[Manage]を開き、作成した専用SQLプールの上でカーソルを動かして[▷]をクリックします。

ポップアップ画面で[再開]を押して再開します。※私の環境では1~2分かかりました。
Synapse Pipelineの作成
専用SQLプールの開始ができたらSynapse Pipelineの作成に入ります。
まず画面左ペインのパイプロゴの[Integrate]をクリックします。そして画面左上の[+]ボタンをクリックして[パイプライン]をクリックします。

次にパイプライン名横の三点リーダーをクリックして[名前の変更]をクリックし、任意の名前に変更しておきます。私は「adls_to_synapse」という名前にしました。

その後画面中部の[>移動と変換]をクリックして[データのコピー]を画面中部の白紙の箇所にドラッグアンドドロップします。

全般の設定
[データのコピー]アクティビティを配置できたらアクティビティの名前を変更します。
[全般]タブの[名前]の項で任意の名前を入力してください。私は「Copy Orders」という名前にしました。

ソースの設定
名前が設定出来たら次は[ソース]タブでソースデータセットを設定します。
[ソースデータセット]の項の右側の[+新規]を押して、右側に作成用の画面ポップアップがでるのを確認します。
そこで[新しい統合データセット]としてADLSを選択して[続行]をクリックし、次に[形式の選択]でExcelを選択して[続行]をクリックします。

すると[プロパティの設定]画面に遷移するので、[名前]に任意の内容を入力して、[リンクサービス]の項で[+新規]をクリックします。

その後[新しいリンクサービス]画面に遷移するので、また[名前]に任意の内容を入力します。
そして[アカウントの選択方式]の項で[From Azure subscription]を選び、[サブスクリプション]と[ストレージアカウント名]に以前作成したものを選択します。

入力が完了したら右下の[テスト接続]をクリックして、接続成功になったら[作成]をクリックします。
作成が完了すると画面が遷移するので、ここで取り込みたいExcelファイルを指定していきます。
[ファイルパス]の項のフォルダアイコンをクリックして、testフォルダをクリックし、[sample_superstore.xls]を選択します。その後[OK]をクリックします。
[OK]をクリック後はまた画面が戻ってくるのでそこでExcelファイルの中で取り込みたいシート「Orders」を[シート名]の項に記入して、[先頭行をヘッダーとして]にチェックを入れます。
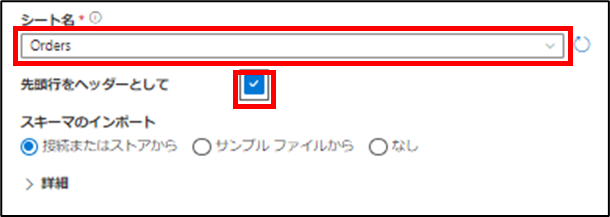
これら作業ができたら画面右下の[OK]をクリックします。
シンクの設定
次に[シンク]タブに移動して、[シンクデータセット]の項の右の[+新規]をクリックします。
[新しい統合データセット]の項に移動するので、[Azure Synapseの専用SQLプール]を選択して[続行]をクリックします。
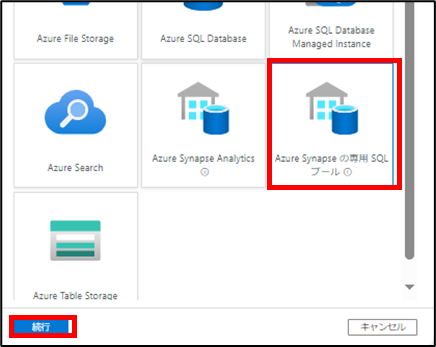
その後[プロパティの設定]画面に遷移するので、任意の名前を設定します。
そして[SQLプール]に以前作成した専用SQLプールを選択し、[手動で入力]にチェックをいれて、[テーブル名]の項に任意のスキーマ名とテーブル名を入力します。私は「test.orders」と設定しました。

その後画面下の[OK]をクリックすると画面が戻ってくるので、[Copyメソッド]に[Bulk Insert]を設定、[一括挿入テーブルロック]を[No]、[テーブルオプション]に[テーブルの自動作成]を設定します。

パイプラインの発行
上記すべての設定が完了したら、画面左上の[すべて発行]をクリックします。

画面右側にポップアップがでるので、[続行]をクリックします。
Synapse Pipelineの実行
発行が完了したらそのまま画面左にあるデータベースアイコンをクリックし、画面右上の更新アイコンをクリックします。

画面左側の[Workspace]タブの[SQLデータベース]の項に以前作成した専用SQLプールが表示されているはずなので、テーブルとスキーマを展開し、ここに作成予定の「testスキーマ」と「ordersテーブル」が表示されていないことを確認しておきます。

その後、画面中部の[トリガーの追加]をクリックして[今すぐトリガー]をクリックします。画面右側にポップアップが出るので[OK]をクリックするとそのままパイプラインが実行されます。
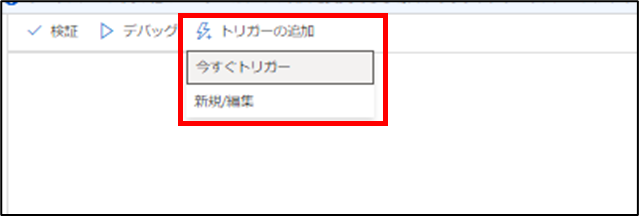
パイプラインの実行完了後、再度先ほどと同じ画面右上の更新ボタンを押して、画面左側の[Workspace]タブを確認すると作成した[testスキーマ]と[ordersテーブル]が確認できるかと思います。

まとめ
今回の記事ではSynapse Pipelineを作成してデータ取り込みする方法を紹介させていただきました。前回の記事と併せて読んでいただくことで、より具体的に作業のイメージがしやすくなるかと思います。ぜひご一読ください!
また、繰り返しにはなりますが今回作成した環境を放置しておくと利用料金が高額になる可能性がありますので、専用SQLプールをこまめに停止したり環境を削除することをおすすめします。

岩間 義尚(日本ビジネスシステムズ株式会社)
2021年度新卒入社後、Hadoopを中心に複数のデータ基盤の開発/運用を経験。 現在はSnowflakeやAzureでのデータエンジニアリングをメインに担当しています。
担当記事一覧