
Azure OpenAI on your own dataにいくつかの機能追加がありました。
ベクトル検索とセマンティック検索が追加されたことによって日本語の精度が向上していますので、この記事ではベクトル検索とセマンティック検索の追加機能を中心にご紹介いたします。
- Azure OpenAI on your own dataのおさらい
- Azure OpenAI on your own dataの追加機能
- デプロイ
- 検索のテスト
- Webアプリのデプロイ
- 検索比較
- まとめ
Azure OpenAI on your own dataのおさらい
Azure OpenAI on your own dataを使うと、簡単に社内のデータなど独自のデータを基に回答する、チャットアプリを構築することができます。
詳細はこちらの記事もご参照ください。
当初、ベクトル検索やセマンティック検索の日本語がサポートされていなかったので、日本語ベースのドキュメントでは精度が良くないことがありましたが、これらの機能が追加されたことによって日本語での精度向上が期待できます。
Azure OpenAI on your own dataの追加機能
ベクトル検索やセマンティック検索の他にも機能追加がありましたので、以下に紹介します。(2023年9月13日現在)
- ベクトル検索とセマンティック検索の追加
- 従来、日本語の検索精度はあまりよくありませんでしたが、これらの機能を使用することによって日本語の検索精度の改善が期待できます。
- プライベート エンドポイントのサポート
- OpenAIおよびAzure Cognitive Searchを仮想ネットワーク内に閉じて利用することができます。(ただしAzure OpenAI Studioはサポートされていないため、API利用のみになります)
- ドキュメントのアクセス制限
- Azure Cognitive Searchのセキュリティフィルタとセキュリティフィルタを組み合わせることによって、検索するドキュメントへのアクセス制御が可能になります。
- Power Virtual Agentsでのデプロイが追加
- Azure OpenAI Studioからアプリケーションをデプロイする際に、Power Virtual Agentsでのデプロイも追加されました。
- インデクサーのスケジュール
- 従来、Azure OpenAI StudioからAzure Blob Storageのドキュメントをソースにしてインデックスを作る際に、インデクサーが消えてしまってBlob にファイルが追加されても反映されなかったのですが、インデクサーをスケジュールすることによってファイル追加が可能になります。
- チャット履歴の保持
- Azure OpenAI StudioからWebアプリをデプロイする際に、Azure Cosmos DBのオプションを指定することによって、チャットの履歴を保存することができるようになりました。
今回は1つ目の「ベクトル検索とセマンティック検索」の機能についてご紹介したいと思います。
ベクトル検索とは
文章をベクトル化(数値化)することで、検索したい質問との関係性を計算して類似性が高いものを選ぶことができます。
詳細はこちらの記事をご参照ください。
セマンティック検索
セマンティック検索は、Azure Cognitive Searchが言語理解を使用して検索結果を再ランク付けする機能です。
デプロイ
リソースのデプロイ
以下のリソースをAzureにデプロイします。
- Azure Cognitive Search
- Azure OpenAI
- Azure Blob Storage
データの準備
今回は、e-Govポータルからデジタル庁関連の法令と規則をダウンロードして、Blobにアップロードしました。
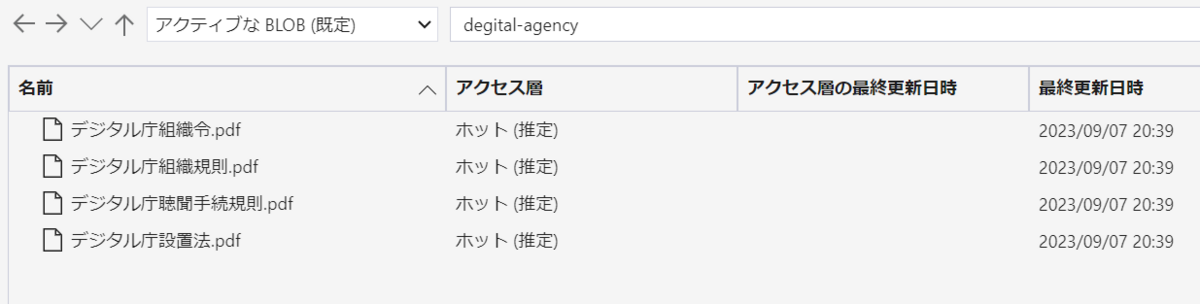
出典:e-Govポータル (https://www.e-gov.go.jp)
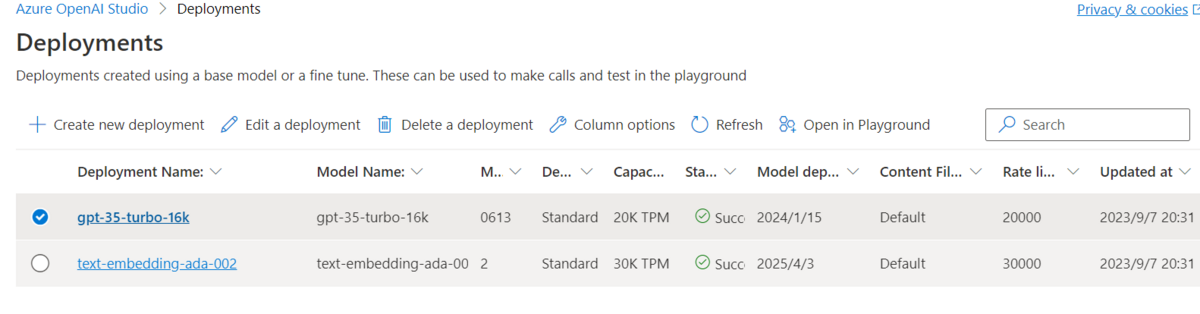
Azure OpenAIにモデルをデプロイ
Azure OpenAI on your own dataでベクトル検索するには、gpt-35-turbo-16kまたはgpt-4とtext-embedding-ada-002が必要なので、それぞれのモデルをデプロイします。
add your dataの設定
Azure OpenAI StudioのChat playgroundを選択します。
Add your dataを選択します。
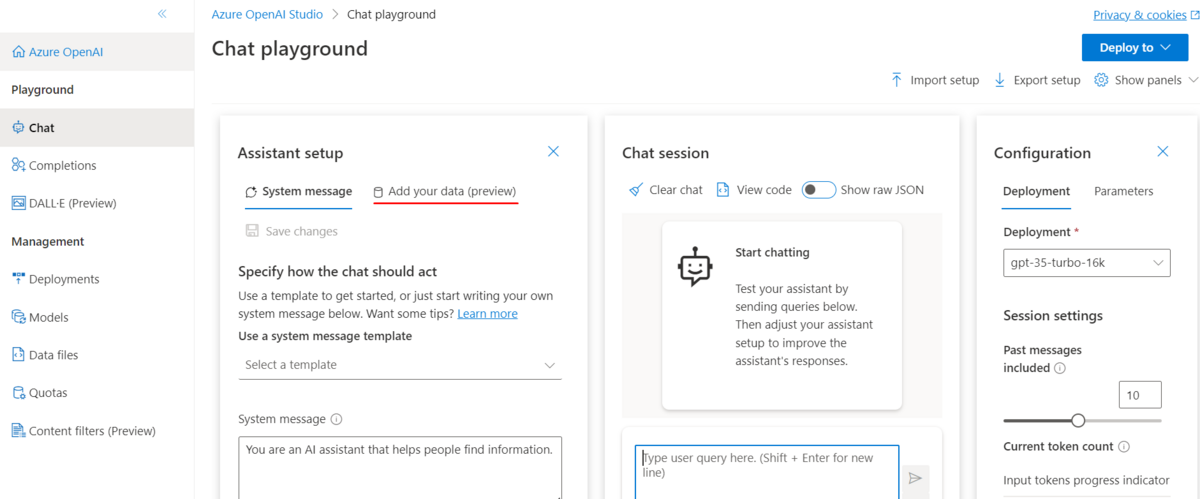
Add a data sourceを選択します。
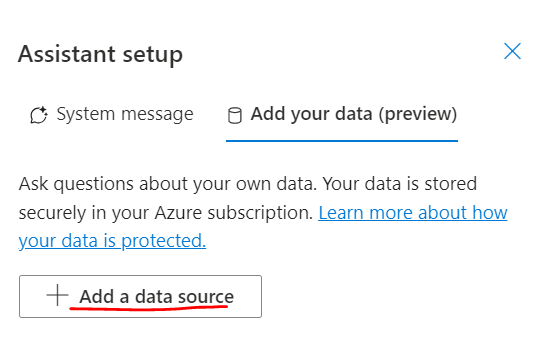
データソースでBlobを選択します。
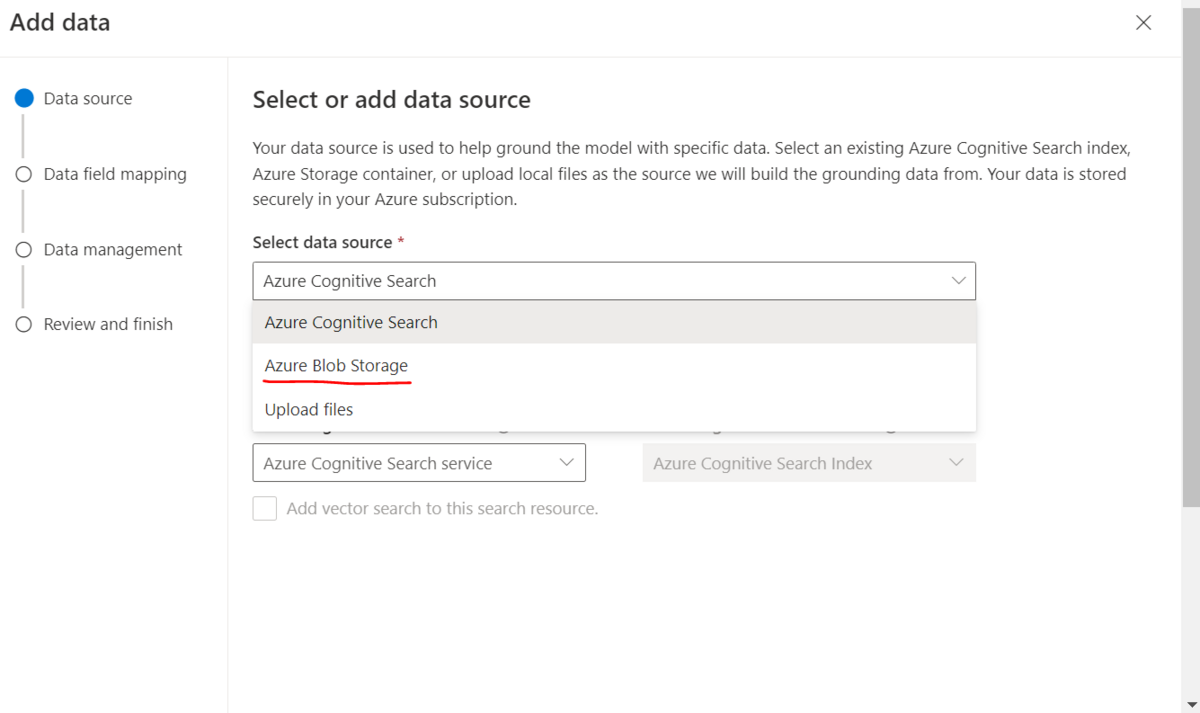
Blobのコンテナの設定で、Cognitive Searchとベクトルサーチを有効にしてembeddingのモデルを選択します。
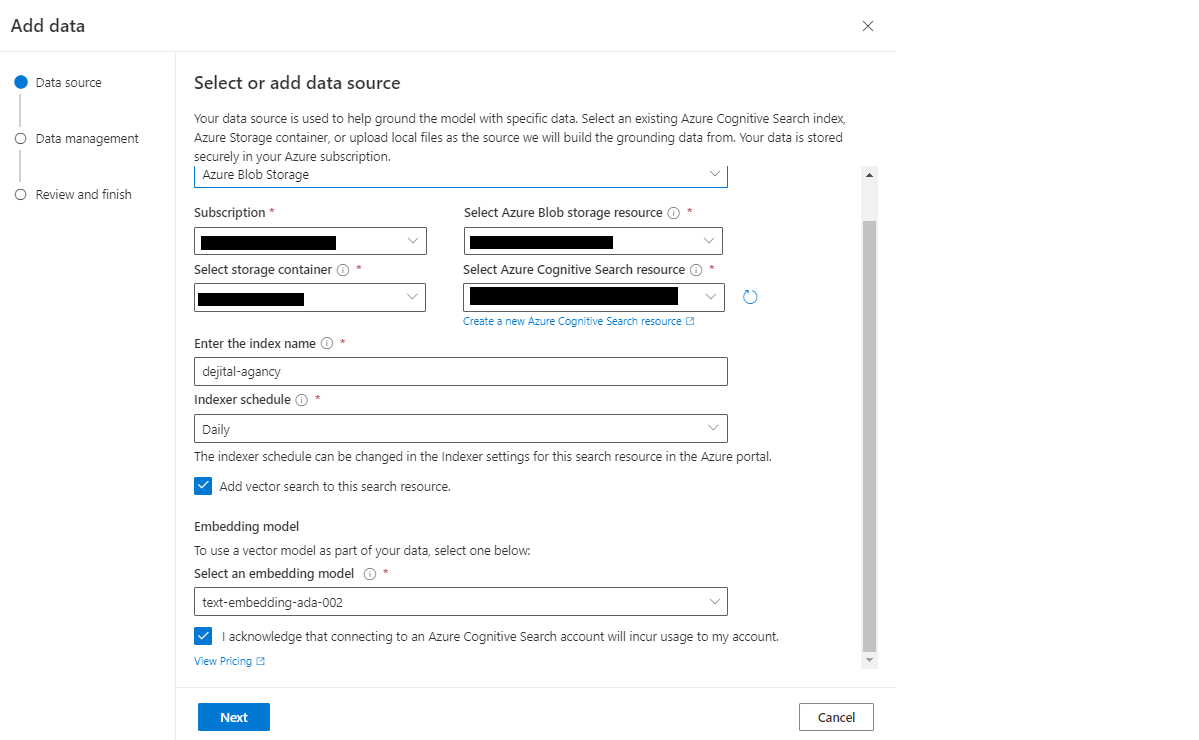
検索方法でHybrid+semanticを選択します。
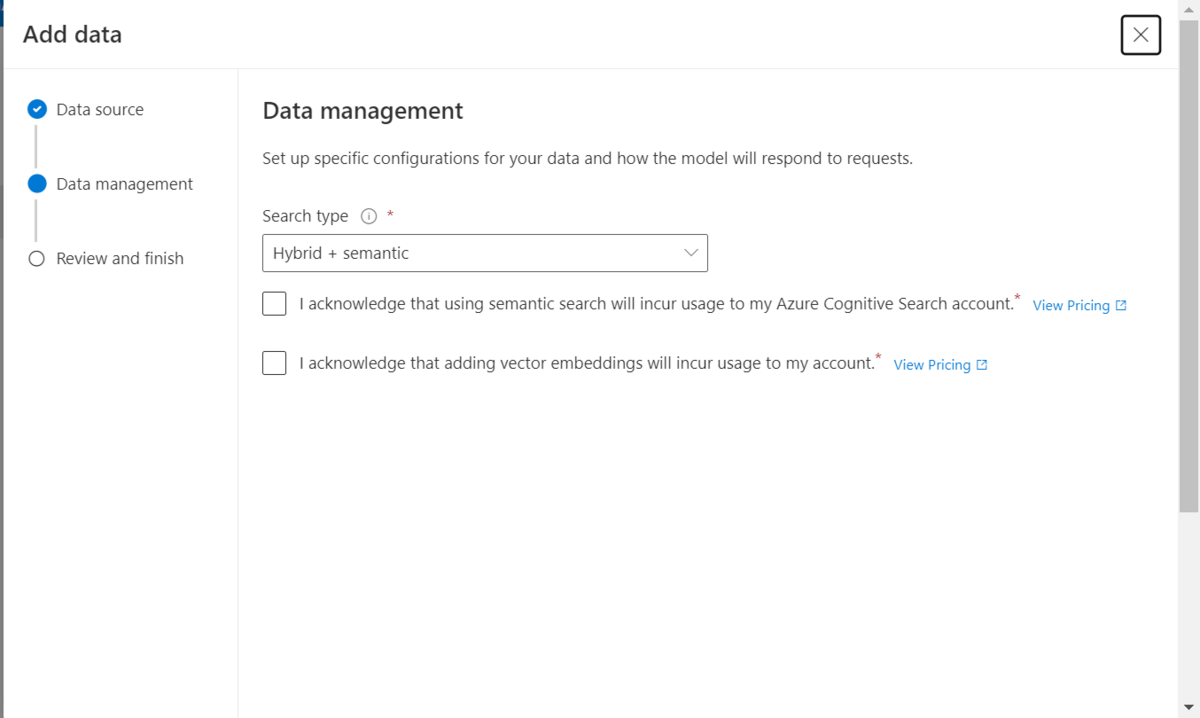
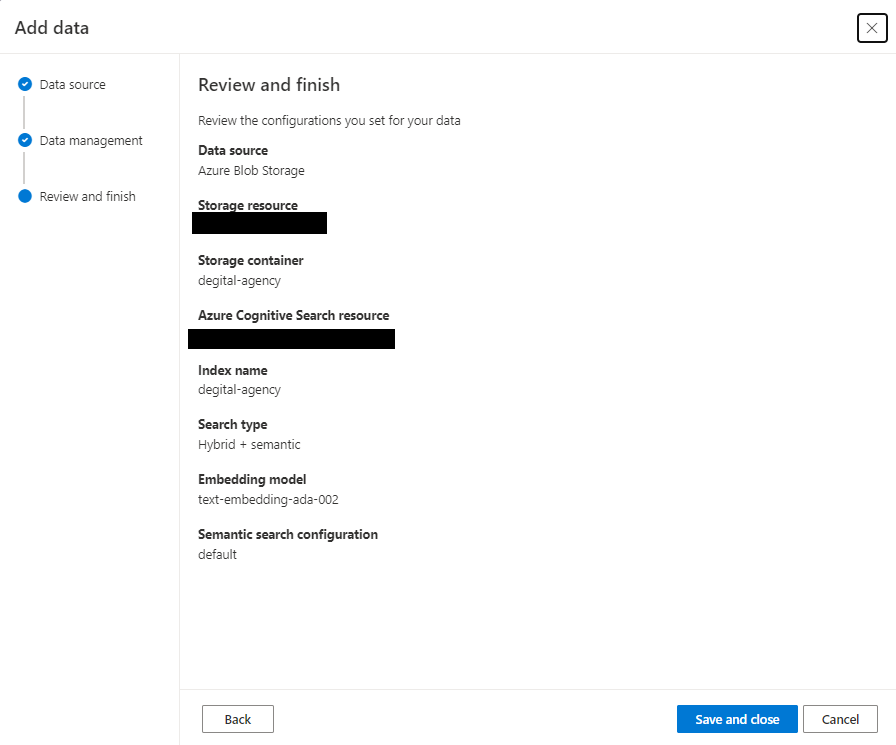
確認画面が出るのでSave and closeを選択します。
セットアップが終わるまで待ちます。
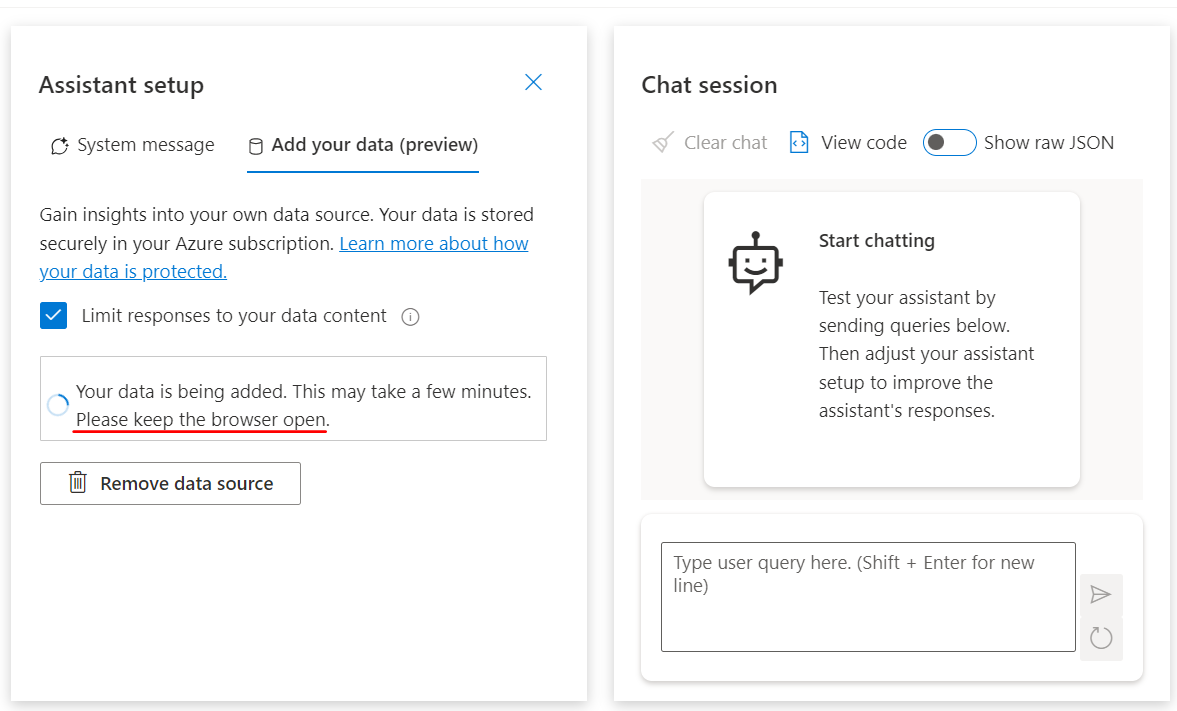
検索のテスト
Chat playgroundで質問するとエラーになります。
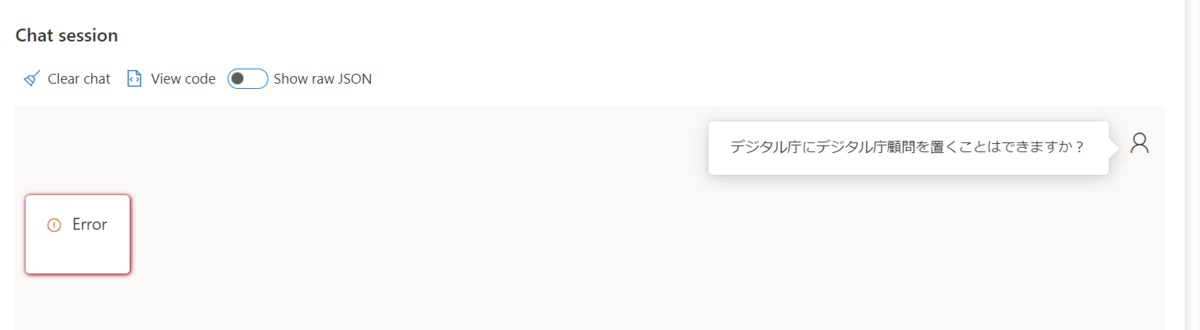
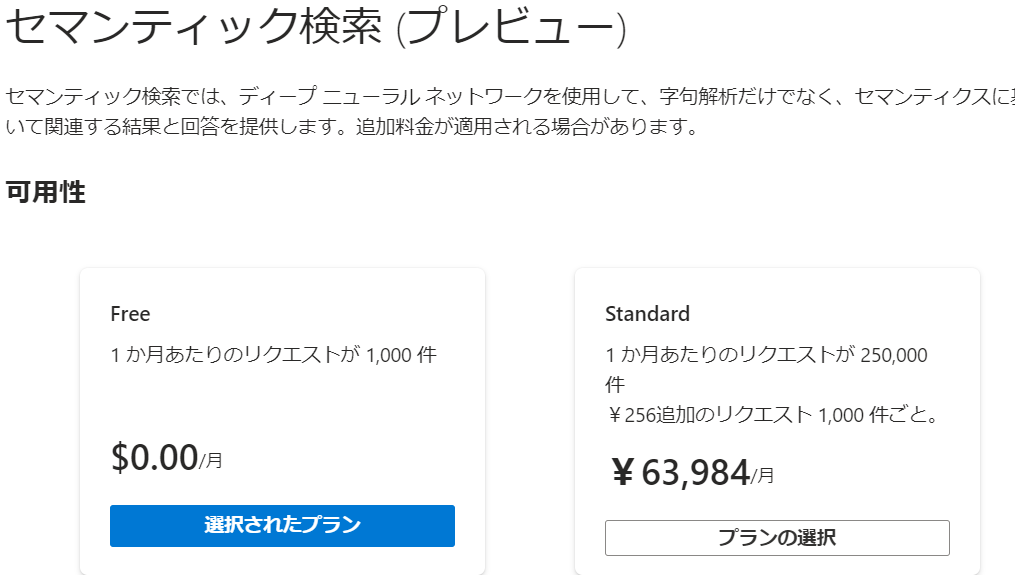
これはセマンティック検索を有効にした場合、Cognitive Searchのセマンティック検索のプランが選択されていない場合に上記のエラーになります。
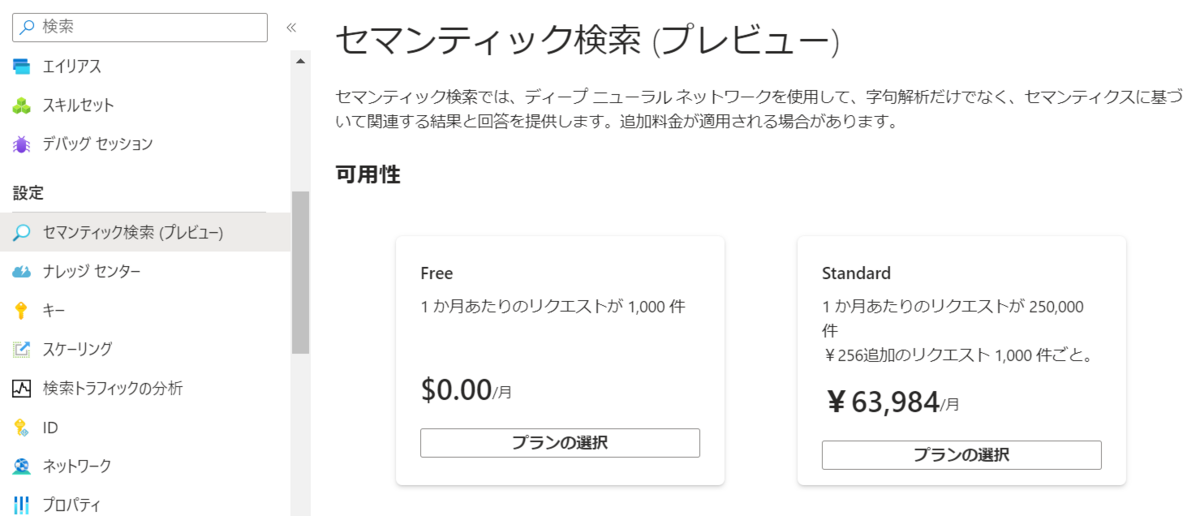
セマンティック検索の画面でFreeのプランを選択します。
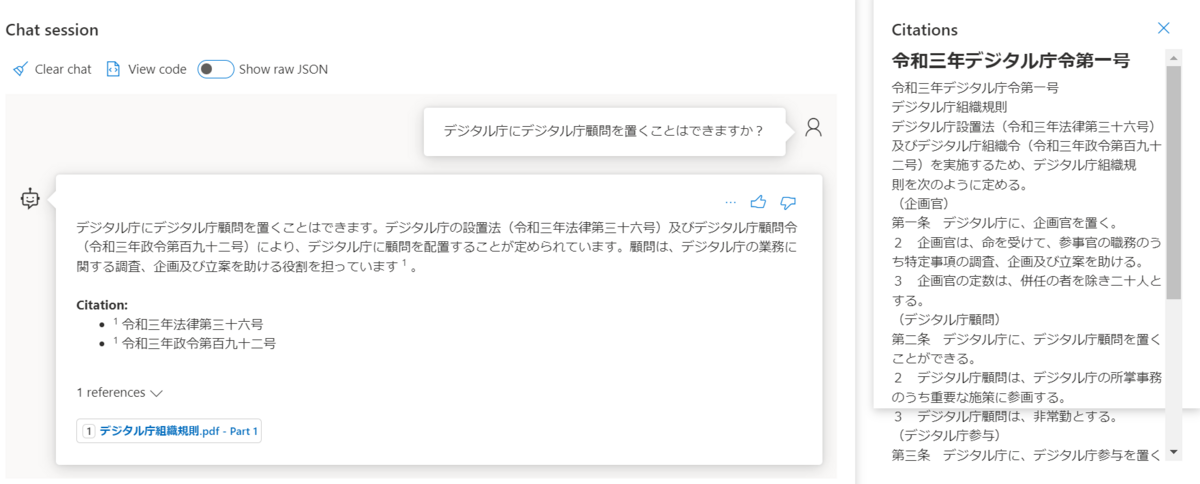
もう一度質問を送ると、引用付きで答えてくれます。
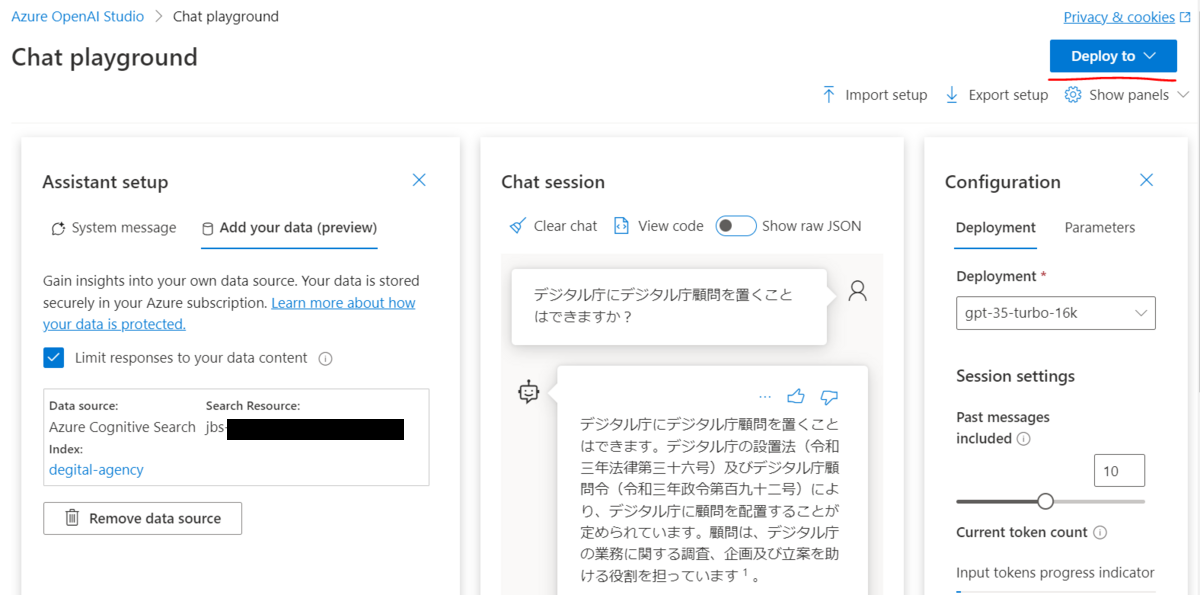
Webアプリのデプロイ
Deploy toのボタンを押します。
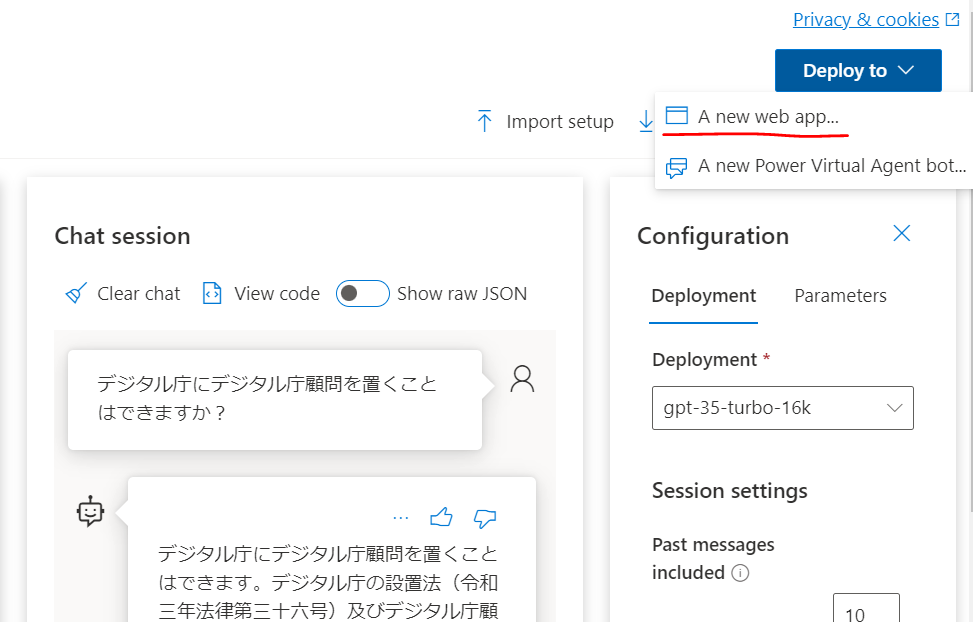
A new web app...を選択します。
デプロイしたいWebアプリの名前やサブスクリプションなどの設定を入力してDeployを押します。
Deploying web appと表示されるのでしばらく待ちます。
Web app deployedと表示されればデプロイ完了です。
Launch web appを押すとWebアプリが開けます。
Webアプリにアクセスすると認証画面になるので承諾を押します。
この画面が表示されれば完了となります。
検索比較
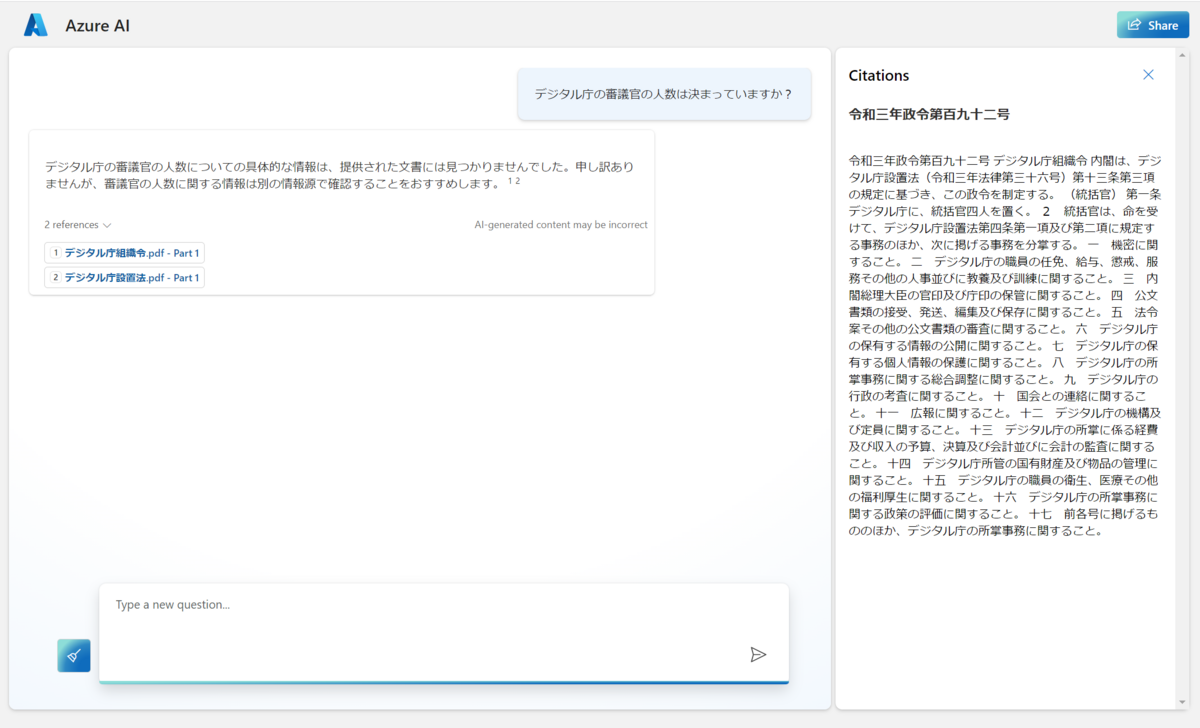
デジタル庁審議官の定数を聞く質問をしてみました。
正解の回答としては「デジタル庁組織令」の第二条に5人と書いてあります。
※ 引用元:デジタル庁組織令 | e-Gov法令検索
少し意地悪に「デジタル庁の審議官の人数は決まっていますか?」という質問を「キーワード検索」と「ベクトル検索+セマンティック検索」でそれぞれ試しました。
キーワード検索
キーワード検索の結果です。文章から見つからないと返ってきました。
Citations(引用)を見ると、デジタル庁組織令は参照しているものの、審議官の人数の文章にたどり着いていないようです。
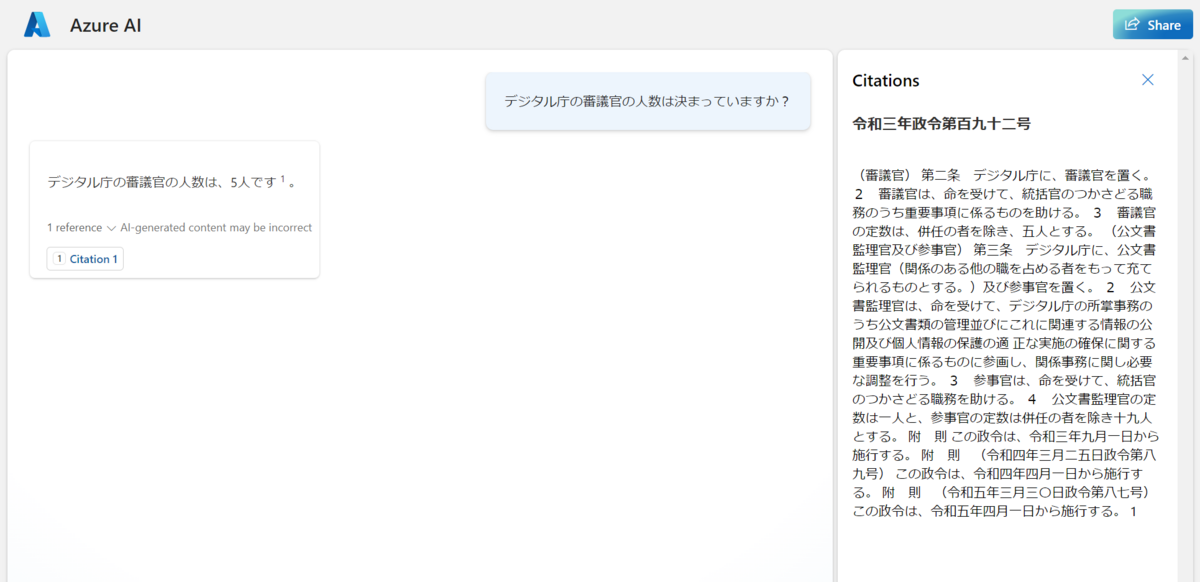
ベクトル検索+セマンティック検索
ベクトル検索+セマンティック検索を試したところ、引用付きで5人と回答してくれました。
検索結果が異なる理由
検索結果が異なる理由の前に、検索の仕組みを軽く説明したいと思います。
データ準備
- Azure Cognitive Searchのインデクサー(クローラー)が長いドキュメントをChunk(分割)する
- Azure Cognitive SearchのインデクサーがchunkしたドキュメントをAzure OpenAIを使ってベクトル化
- Azure Cognitive Searchのインデクサーが分割したドキュメントとベクトルデータなどでインデックス(DB)を作成
チャット
- 入力されたチャット内容のキーワードでAzure Cognitive Searchを検索
- 入力されたチャット内容のベクトルでAzure Cognitive Searchを検索(ベクトル検索)
- 検索結果をAzure Cognitive Searchのセマンティック検索がソート(セマンティック検索)
- 上位の文章をAzure OpenAIが取得して回答を生成
チャットの質問を「デジタル庁の審議官の定数は決まっていますか?」にすれば、「デジタル庁」、「審議官」、「定数」というキーワードで1のキーワード検索でも回答していた可能性があると思います。
ただ、今回は「人数」という単語だったので、定数の部分のドキュメントがうまく検索上に来なかったようです。
ここに、ベクトル検索とセマンティック検索を追加することによって、Azure OpenAIが必要な文章を取得して正確な回答ができたと考えます。
まとめ
Azure OpenAI on your own dataはpreviewなのでまだまだな部分はありますので、実際の業務で使うには難しい部分もありますが、Azure OpenAI on your own dataのAPIなどを活用することによってアプリの幅が広がる可能性があります。
また、今回はご紹介できなかった他の更新情報についてもお知らせできればと思います。

上田 英治(日本ビジネスシステムズ株式会社)
エンジニアとしてインフラ構築、システム開発やIoT基盤構築等を経験し、現在はクラウドアーキテクトとして先端技術の活用提案や新規サービスの立ち上げを担当。
担当記事一覧