
Microsoft Build 2023 で発表されていた「Azure OpenAI on your data」(以後 "on your data" )について、6/21あたりからパブリックプレビューとして利用できるようになっていたため、使用してみました。
「Azure OpenAI on your data」とは
「Azure OpenAI on your data」は、ChatGPT (gpt-35-turbo) および GPT-4 (GPT-4-32Kは利用不可) モデルにて、ユーザーのデータに基づいた応答を生成する機能です。REST API と Azure OpenAI Studio (GUI) にてアクセス可能な機能です。
仕組みとしては、ユーザーが入力したプロンプトを基にAzure Cognitive Search(以後 "Cognitive Search" )にてデータを取得し、取得した情報を参考に回答を返します。そして、Azure OpenAI Studio (GUI) のプレイグラウンドで試したその仕組みを、そのままWebアプリとしてすぐにデプロイできます。
この記事では、 Azure OpenAI Studio (GUI) からon your data機能を検証します。
Azure OpenAI Studio (GUI) で on your data機能を使う
Azure OpenAI Studioでは、GUIでon your data機能を使うことができます。
Azure OpenAI Studioの左ペインで「チャット」を選択し、"gpt-35-turbo" または "gpt-4" モデルのデプロイ名を選択することで、「アシスタントのセットアップ」パネルに「Add your data (preview)」という項目が出現します。

仕組み
「Add a data source」をクリックすると、データソースとして以下3種類が選択できますが、どれを選んでも最終的にはAzure Cognitive Searchのインデックスに対してデータ検索するという仕組みになっています。
- Azure Cognitive Search
- Azure Blob Storage
- Upload files
Azure Blob Storage と Upload files を選択すると、一時的に作成されたインデクサーによって自動的にインデックスが作成されます。

データソース選択肢(1) Azure Cognitive Search
データソースとして「Azure Cognitive Search」を選択した場合の検証です。
事前に作成したインデックスをデータソースとして使用します。インデックスは、子育てオープンデータ協議会が公開している「子育てAIチャットボット」普及のための「FAQデータセット」のデータを利用しています。
データソースを指定する
「Add a data source」をクリックすると現れる「Add data」モーダルウィンドウには以下の内容を入力しました。
- Data Source
データソースとなるCognitive Searchリソース名とインデックス名を指定します。

- Index data field mapping
データ検索やチャット画面の引用元表示の際に使用される、インデックス内のフィールド名を指定する箇所です。iマークとして表示される英語の説明をもとにフィールドを設定しました。
※APIでon your data機能にデータを渡す際の dataSources > parameters > fieldsMapping に相当する部分になります。
項目名 iマークで表示される英文を日本語翻訳した内容 Content data 各文書の本文を含むインデックスのフィールドを指定します。 ファイル名 オプションで、各文書の元のファイル名を含むインデックスのフィールドを指定します。 Title オプションで、各文書の元のタイトルを含むインデックスのフィールドを指定します。 URL オプションで、各ドキュメントの元のURLを含むインデックスのフィールドを指定します。 
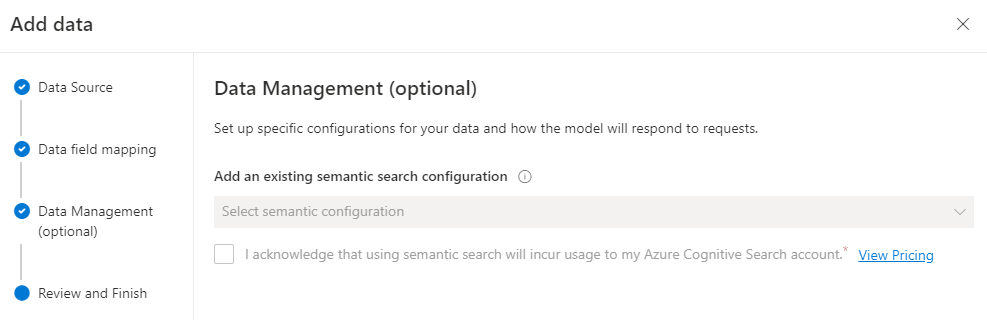
- Data Management (optional)
データ検索にセマンティック検索を利用する場合はこの項目を埋めるようですが、今回のインデックスではセマンティック検索を利用していないため、そのまま次に進みました。
- Review and Finish
最後にこれまでの入力内容を確認して、「保存して閉じる」をクリックします。

すると、設定したインデックス名などが、「アシスタントのセットアップ」パネルに表示されます。
「Limit responses to your data content」というチェック項目によって、AIからの回答をデータソースに基づいた固有な応答に制限するかを選択することができます。

チャットを試す
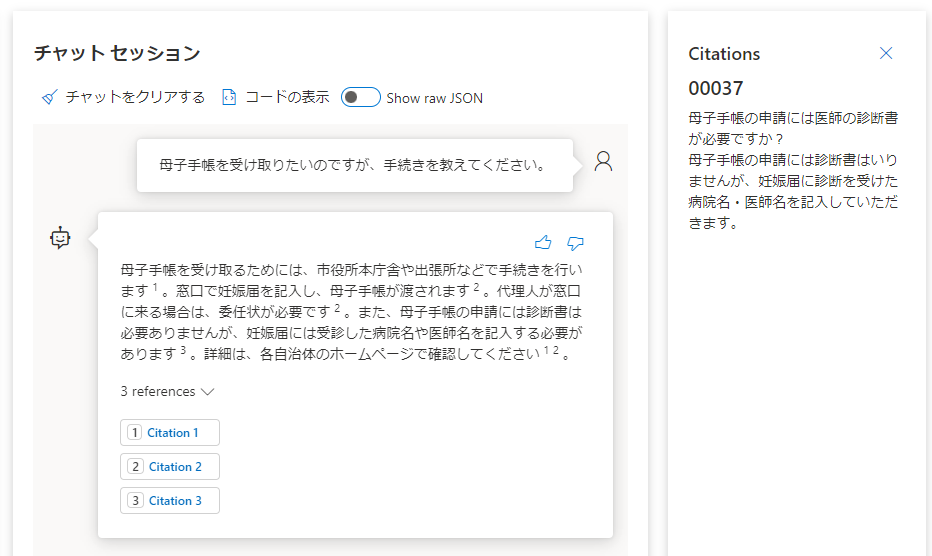
早速質問を投げてみましたが、回答が文字化けしていました。

システムメッセージにて日本語で回答することを記載したところ、日本語で応答が返ってきました。
回答内容の正確性に関しては、データソースに存在しない情報である「出産予定日から14週間以内に、市区町村役場の窓口で申請する必要があります」などの回答内容があり、データソースにある情報だけで回答することができていないようです。

モデルを"gpt-4"に変更すると、参照したデータの内容をうまくまとめて回答していました。
データソース選択肢(2) Azure Blob Storage
データソースとして「Azure Blob Storage」を選択した場合の検証です。
子育てオープンデータ協議会が公開している「子育てAIチャットボット」普及のための「FAQデータセット」をcsvファイル化したものを、Blobストレージにあらかじめ保存します。
「Add data」モーダルウィンドウでは、データの置いてあるBlobストレージや、インデックスを作成する対象のCognitive Searchリソースの入力が求められます。以下の内容を入力しました。
後の注意事項に記載しましたが、on your dataでサポートされているユーザデータのファイル形式は6種類あり、csv形式は含まれていません。ただ、ここで特にエラーは発生しませんでした。おそらく、「Update files」の方でローカルからアップロードできるファイルの種類の制限だと考えられます。

設定が完了すると、以下のインデックスがCognitive Searchに自動的に作成されていました。
csvのデータ構造は認識せず、一連のテキストとして630文字程度でチャンク化(分割)しているようです。

データソースとして「Azure Cognitive Search」を選択した場合と同様に、日本語で回答する旨のシステムメッセージを設定すると、それなりの回答は返してくれることを確認しました。参照元情報(Citations)が適当にチャンク化されたテキストのため、見にくい形になっています。

データソース選択肢(3) Upload files
データソースとして「Upload files」を選択した場合の検証です。
「Add data」モーダルウィンドウでは、ローカルにあるファイル、そのファイルをアップロードするBlobストレージ、作成するインデックス名などを指定します。
今回は以下のような架空の会社の100件の社内ナレッジをGPTで自動作成し、100件のテキストをユーザデータとしてアップロードしました。

on your dataのデータソースとしての設定完了後、設定画面で選択したBlobストレージを確認するとtxtファイルが保存されていました。

また、Cognitive Searchに自動作成されたインデックスでは、テキストファイルごとにデータがチャンク化されていました。contentにはテキストファイルの全文が、filepathにはファイル名が、titleにはテキストの1行目が入っています。

実際にチャットで質問すると、うまく回答できていないケースもありましたが、以下のようにユーザデータからしか得られない情報を的確に回答してくれました。
また、参照元データがテキストファイル単位で分割されているため見やすいです。

データソース選択肢「Azure Blob Storage」と「Upload files」に関しては、手軽なものの自由度が低く、インデックスの作成方法を制御しにくいため、簡単な検証を行う際に利用する機能という印象でした。
Webアプリのデプロイ機能を試す
データソースを指定した状態で画面右上の「Deploy to…」ボタンを押すと、「チャットセッション」パネルで行っていたチャット機能を独立したWebアプリとしてデプロイすることできます。
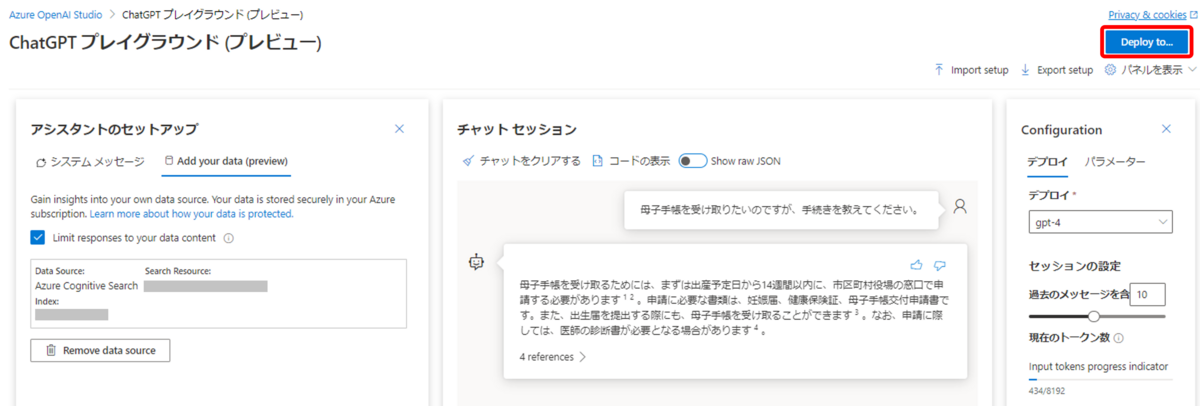
Webアプリをデプロイするための最低限の情報を入力します。
以前にこの方法でWebアプリをデプロイしている場合は、「Update an existing web app」を選択することで、現在の「ChatGPTプレイグラウンド」画面で設定している内容でWebアプリを更新することができます。
「Deploy」ボタンを押すと、Webアプリがデプロイされます。

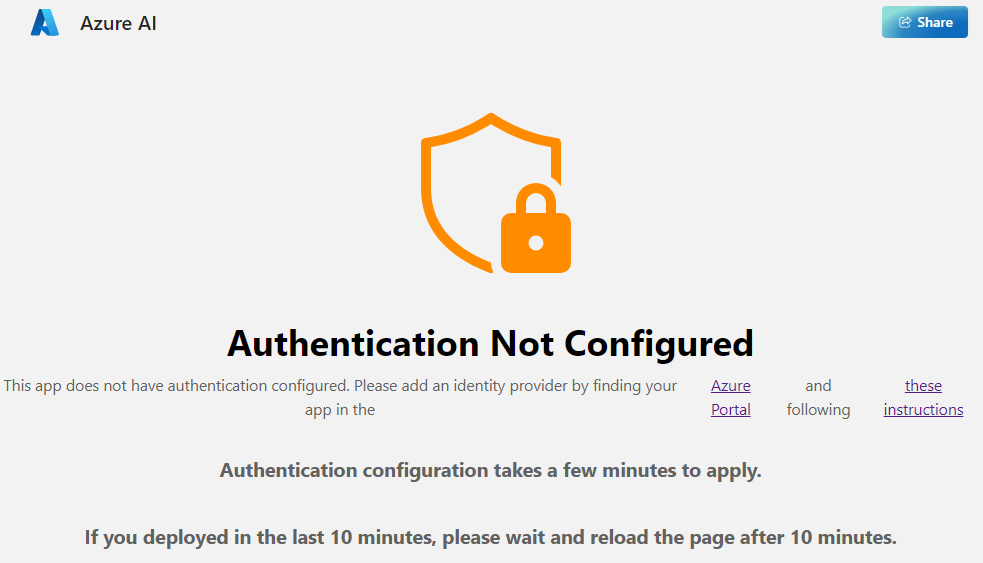
デプロイされたWebアプリにすぐにアクセスすると、以下の画面になりアクセスできません。しかし、10分ほど経ってからアクセスすると、AzureADのアクセス許可の承諾を求める画面が表示され、承諾することでアプリにアクセスできるようになります。
優れたUIのアプリ画面で、先ほどプレイグラウンドで行ったものと同様なチャットをすることができます。

デプロイされるWebアプリの仕組みを簡単に説明します。
- 指定したリソースグループに、指定した名前のApp Service (Azure WebApps) と、WebAppsをホストするApp Service プランが作成されます。
- Webアプリのソースコードは、GitHubのパブリックレポジトリのコードを引用しています。
- Azure OpenAI Studioで設定したソースデータやチャットパラメータの内容は、WebAppsの「アプリケーション設定」に保存されています。
- アプリの認証はAzureADで行っています。WebAppsと同名のAzureADアプリが登録されていることが確認できます。同じAzureADテナント内のユーザーであればデプロイしたWebアプリにアクセスすることができます。
- 複数のリソースやAzureADアプリの作成を伴うので、適切な権限を有している場合のみWebアプリはデプロイできます。
機能や用途は限定されるものの、ナレッジ検索できるチャットアプリをほんの数分で作成できてしまうのは驚きです。
注意事項
最後に、on your data機能を利用する際の注意事項です。
データソース選択「Upload files」でサポートされているファイル形式
こちらには、on your dataではユーザーデータとして以下ファイル形式がサポートされていることが記載されています。データソース選択「Upload files」にてローカルからアップロードできるファイルの種類を指していると考えれます。
- テキスト(.txt)
- マークダウン(.md)
- HTML(.html)
- Wordファイル(.docx)
- PowerPointファイル(pptx)
- PDFファイル(.pdf)
Cognitive Searchでのセマンティック検索やベクトル検索
on your data機能におけるCognitive Searchでの検索方法は、基本的にはキーワード検索です。
セマンティック検索機能については、現時点では英語のデータ対してのみサポートされているようです。また、ベクトル検索は対応していません。
参照するドキュメントの言語
on your dataで接続するドキュメントの言語に関しては、データが日本語であれば検索クエリも日本語である必要があり、システムメッセージでAIモデルに対してデータの言語を適切に伝えることが大切なようです。
複数言語のドキュメントがある場合は、言語ごとにインデックスを作成し、それぞれをAzure OpenAI に接続すること推奨されています。つまり、複数言語のドキュメントをまとめて参照して回答を返すことはon your dataでは現状は難しいようです。
参考:Azure OpenAI Service で独自のデータを使用する - Azure OpenAI | Microsoft Learn
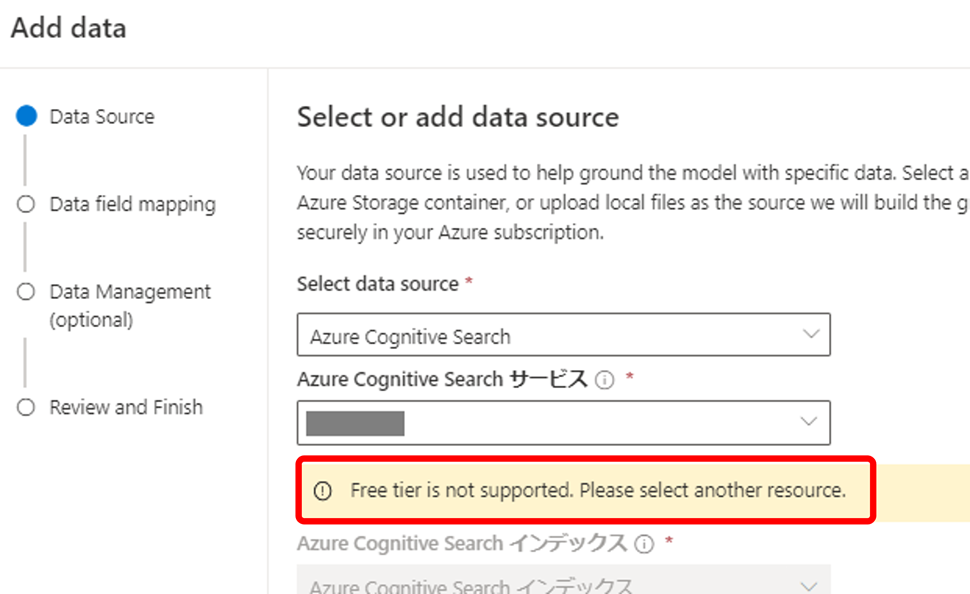
使用できるCognitive Searchの価格レベル
on your dataで利用できるCognitive Searchの価格レベルはBasic以上です。
FreeプランのCognitive Searchリソースは、検索対象として利用できないのでご注意ください。
まとめ
- 「Azure OpenAI on your data」は開発者向けの機能で、Cognitive SearchとChatGPTを連携したアプリの検証に利用できます。
- on your dataにおけるユーザーの制御できる範囲は狭いですが、データさえ用意できていればAzure OpenAI Studioで手軽に利用でき、そのままWebアプリとしてデプロイできます。検証用途や期待値が高くない場面で役立ちそうです。
- 回答精度に関しては、インデックスの作成方法、AIモデル選択、システムメッセージの設定等で、ある程度の向上は見込めます。回答の正確性をより高く求めるならば、on your data機能を使うのではなく、アプリとして作り込んで精度を高めてしていくしかないでしょう。
参考
- Azure OpenAI Service で独自のデータを使用する - Azure OpenAI | Microsoft Learn
- Azure OpenAI サービスで独自のデータを使用する - Azure OpenAI | Microsoft Learn
- microsoft/sample-app-aoai-chatGPT: [PREVIEW] Sample code for a simple web chat experience targeting chatGPT through AOAI. (github.com)
