
概要
今回の記事では一般提供開始が開始されたAzure OpenAI Service の活用方法についてご紹介します。
最近は特にChatGPTが広く使われるようになりましたが、Azure OpenAIではチャットのような対話に限らず、より幅広い自然言語処理のタスクに応用することができます。
今回の記事では一例として、過去にご紹介した「業務メールを必要なものと不要なものに振り分ける」というタスクをGPT-3のAIに解かせてみます。
やりたいこと
前回の振り返り
過去に自然言語処理AIを用いて不要な業務メールを取り除き、必要な文章のみ検索でヒットするようなナレッジベースの構築に貢献するAIモデルを作成しました。
今回はここにAzure OpenAIのGPT-3を活用することで、必要/不要の判定精度が向上できないか試してみます。
blog.jbs.co.jp
過去の記事の内容はざっくり以下の通りです。
- 業務メールのうち必要な文章をピックアップしてナレッジベースを構築する
- 自然言語を扱うためにAIモデルを使用して分類タスクを解かせる
- 2つのモデルの組み合わせで業務メールを必要/不要に振り分ける
- 日本語→ベクトル化するモデル(FastTextもしくはDov2Vec)
- ベクトル→必要/不要に分類するモデル(Azure Machine Learning AutoML機能)
- 2つのモデルの組み合わせで業務メールを必要/不要に振り分ける
- 業務メールデータセットから作成した50次元FastTextモデル+AutoMLで最も精度が良かったモデルを採用する
その他業務メールデータセットや学習プロセスなどの詳細については、記事をご参照ください。
Azure OpenAIの導入
今回はAzure OpenAIを導入することで精度の向上を図ります。
テキスト検索埋め込みは以下の2種類のモデルが用意されています。
- text-search-XXXX-doc-001
- 検索対象のドキュメントをベクトル化するモデル
- text-search-XXXX-query-001
- ユーザーの入力した検索文字列をベクトル化するモデル
XXXXにはモデル名が入ります。
Ada、Babbage、Curie、Davinciの4種類を使用することができ、後者のモデルほど機能性が向上します。
いずれも従量課金ですが、DavinciはCurieの10倍の使用料金が発生してしまうため、今回は2番目に機能性が高いCurieを使用して検証を行います。
azure.microsoft.com
Azure OpenAI(GPT-3)で推論精度は向上するのか?
前提
過去にナレッジベースの構築に貢献するAIモデルを作成しましたが、その時は独自のデータで作成したモデルと、Wikipediaデータから作られたベクトル化モデルを使用しました。
今回の記事で、比較のために用いるモデルの詳細は以下の通りです。
- 50次元
- 業務メールのデータセットからトレーニングしたDoc2Vec (50dim)
- 業務メールのデータセットからトレーニングしたFastText (50dim)
- Fasttext wiki wordvectors (PCA 50 dim)
- Doc2vec 日本語wikipedia dbow300d (PCA 50dim)
- 300次元
- 4096次元
今回は新たにAzure OpenAIのtext-search-curie-doc-001モデルを使用します。
また前回は主成分分析(PCA)を用いて50次元に揃えて全てのモデルを評価しましたが、前回は実施しなかった300次元のWikipediaベクトル化モデルでも学習・評価を行って結果を比較します。
Azure OpenAIの4096次元→50次元にPCAで圧縮した際の精度については、今回の記事では検証を行っていません。
作業手順
以下のチュートリアルの内容をもとにベクトル化を実施します。
基本的にデータセットのみ置き換えてこの手順をなぞることで本記事と同様にベクトル化を行うことができます。
チュートリアルでは英語のデータが使用されていますが、日本語でも問題なく動作するようです。
またチュートリアル記事では検索のためにtext-search-curie-query-001を使用しますが、今回の内容のみを実施する場合は不要です。text-search-curie-doc-001のみデプロイすれば進行できます。
learn.microsoft.com
実際に使用したリソースの画面は以下の通りです。
リクエストに必要なエンドポイントURLと認証キーはAzure Portal上から確認できます。
ベクトル化したpandas Dataframeを整形・CSVに出力して出力して、Azure Machine LearningのAutoMLで学習させました。 今回出力されるベクトルは4096次元となり規模が大きくなりましたが、問題なく学習を行うことができました。
評価方法
前回の記事と同様に、学習用データセット・テスト用データセットの文字列を各モデルでベクトル化します。
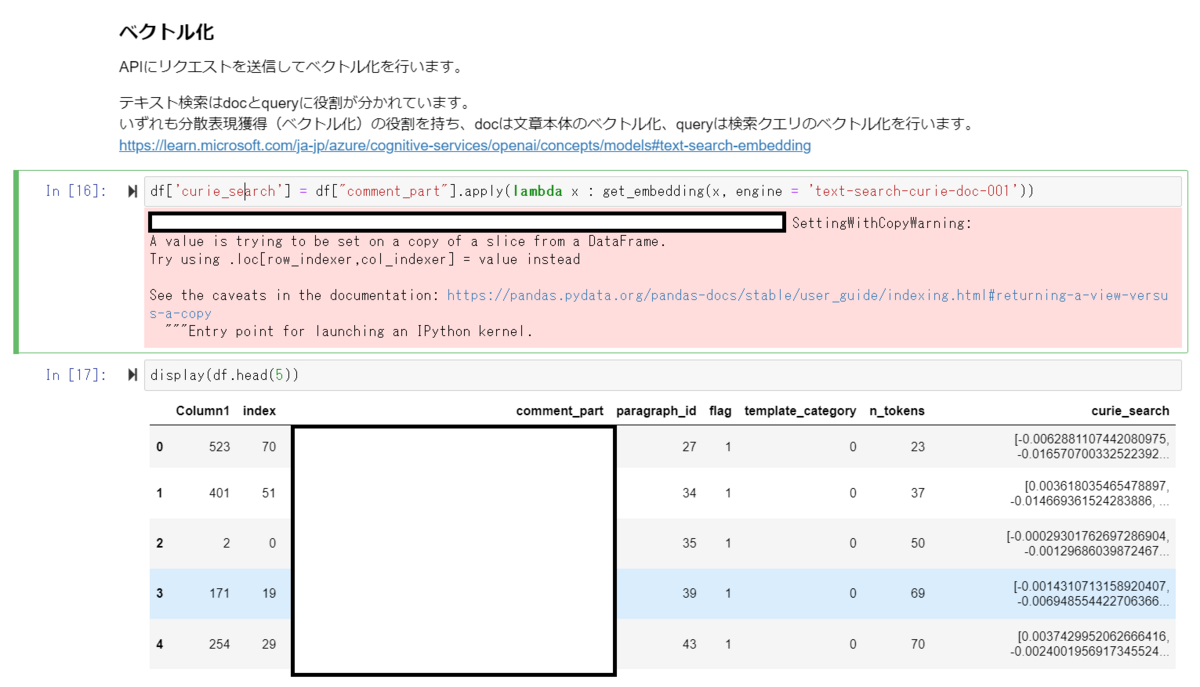
ベクトル化した学習用データセットベクトルをAzure Machine Learning AutoMLで学習して最もスコアの高かったモデルを採用します。
採用したモデルをテスト用データセットで評価して正解率・適合率を算出します。
学習結果
前回の結果に加えて、今回新たに評価を行った結果を以下の表に記載します。
赤色が最も評価値が高く、青色が最も評価値が低い箇所を示します。
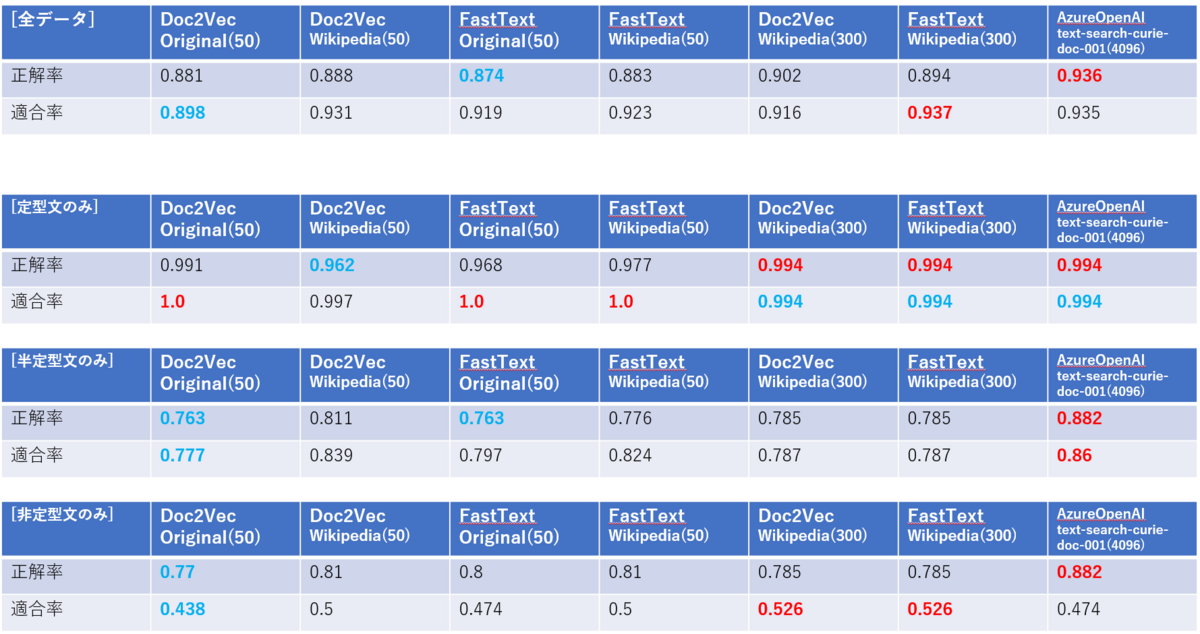
ざっくり結果は以下の通りでした。
- もともと判定精度の高い定型文については大きな変化がなかった
- Azure OpenAIから生成したベクトルは正解率が以前より大きく向上した(5~10%程度)
- Wikipediaデータで作成したベクトルは、50次元に圧縮したものに比べて正解率・適合率が向上しなかった
0.5程度にとどまっている非定型文の適合率についてはOpenAIモデルよりもWikipediaの300次元モデルの方が高く算出されました。
実際のマトリクスは以下の通りです。学習データと同様にテストデータの件数が少なく、1件の誤判定に影響を受けやすいことから、性能に大きな差はないと考えています。
- FastText wiki wordvectors(300dim)の結果マトリクス
| 正解\予測 | 必要 | 不要 |
|---|---|---|
| 必要 | 75 | 6 |
| 不要 | 9 | 10 |
- Azure OpenAIの結果マトリクス
| 正解\予測 | 必要 | 不要 |
|---|---|---|
| 必要 | 75 | 4 |
| 不要 | 10 | 9 |
※テストデータのうち2件は長文で、Azure OpenAI API送信上限トークンの2000を超えたために計算から除外しています
考察
全体的にAzure OpenAIによって算出したベクトルの結果は精度がよく、過去のベクトル化モデルよりも特徴を捉えている可能性があると感じました。
特に文章の半分程度がテンプレートの文面である半定型文については精度が大幅に向上しているため、より複雑な非定型文についても特徴を捉えてベクトル化することができそうです。学習データ数を増やすことで、過去の日本語ベクトル化モデルを使うよりも精度を向上させることができるように感じました。
今回は新たにWikipediaデータを学習したFastText、Doc2Vecの300次元モデルを使用して結果を確認しましたが、PCAで50次元に削減したモデルよりも精度が高くなるという結果にはなりませんでした。
次元削減によって情報が失われて精度が下がるよりも、入力ベクトルが圧縮されたことでモデルが特徴を捉えやすくなったのか。2つのモデルを噛ませている都合上単純な比較や考察が難しいですが、表現するベクトル次元数について検討の余地があると感じました。
今回のGPT-3モデルは4096次元ですが、今後は発展の課題として、次元削減によって精度を向上するか試してみたいと思います。
おわりに
今回はAzure OpenAIを用いて自然言語処理モデルを構築してみました。
以前は私がFastTextやDoc2Vecモデルを独自に作成しましたが、Azure OpenAIとAzure Machine LearningのAutoMLによって誰でも簡単に高精度な自然言語の分類モデルが構築できるようになりました。
今後は学習・テストデータを蓄積するための仕組み構築と定期的なモデルのアップデート(ML Ops)に主な焦点を置いて、高精度なAIモデルを作成していきます。
