
Azure Synapse Analytics上で Azure OpenAI Service(もしくはOpenAI)のLLMを利用する方法として、今回はSynapseMLを利用した一括処理を紹介します。
はじめに
前回の記事では、Deltaテーブルを利用した逐次処理によるAzure Synapse AnalyticsでのAzure OpenAIの呼び出し方法を紹介しました。しかし、この方法ではApache Sparkの持つ分散処理能力を十分に活かせず、効率的とは言えません。
本記事では、SynapseMLを使用することでApache Sparkの分散処理能力を活かして、Azure OpenAI ServiceのLLMで大量の自然言語データを一括で処理する方法を紹介します。
SynapseMLについて
SynapseMLについて、Microsoftのドキュメントでは以下のように記載されています。
SynapseML (旧称 MMLSpark) は、大規模スケーラブルな機械学習 (ML) パイプラインの作成を簡略化するオープンソース ライブラリです。SynapseML は、テキスト分析、ビジョン、異常検出など、さまざまな機械学習タスクに対して、シンプルで構成可能な分散型 API を提供します。SynapseML は Apache Spark 分散コンピューティング フレームワーク上に構築され、SparkML/MLLib ライブラリと同じ API を共有するため、SynapseML モデルを既存の Apache Spark ワークフローにシームレスに埋め込むことができます。
つまり、機械学習タスクをApache Sparkで分散実行する際に、簡単に構成できるインターフェースを提供してくれるということです。
今回のケースでは、そのSynapseMLを用いてAzure OpenAIの処理を呼び出します。
参考
今回の内容を作成するにあたり、以下のドキュメントを参考にしました。
※ 以前はAzure OpenAI ServiceのドキュメントにもSynapseMLと統合する方法が記載されていましたが、現在は見当たりません。将来的にまた記載が復活する可能性はあります。
実践
使用方法はかなりシンプルでわかりやすいため、早速ですが実践的にSynapseMLを利用してAzure OpenAI ServiceのLLMを一括処理で呼び出す方法を紹介します。
まずは、参考ドキュメントに記載されているようなSynapseMLを使用する基本的な手順を紹介します。その後、一般的なユースケースを想定したデータの一括処理方法を説明します。
SynapseMLのインストール
まず、SynapseMLを使用するために必要なパッケージをインストールします。Synapse Notebook上で以下のコマンドを実行してください。
%%configure -f
{
"name": "synapseml",
"conf": {
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:1.0.8",
"spark.jars.repositories": "https://mmlspark.azureedge.net/maven",
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.12,org.scalactic:scalactic_2.12,org.scalatest:scalatest_2.12,com.fasterxml.jackson.core:jackson-databind",
"spark.yarn.user.classpath.first": "true",
"spark.sql.parquet.enableVectorizedReader": "false"
}
}
上記の構成では、Spark 3.4のSparkプールを使用している場合の設定です。他のバージョンを使用している場合は、公式ドキュメントを参照して適切な設定を行ってください。
また、OpenAIのPythonパッケージもインストールします。
pip install openai
SynapseMLを用いたAzure OpenAI Serviceの呼び出し
まず、Azure OpenAI Serviceのエンドポイント、デプロイメント名、およびAPIキーを設定します。
endpoint_url = "https://<Your-Resource-Name>.openai.azure.com/" deployment_name = "<Your-Deployment-Name>" # Azure OpenAIのデプロイメント名を指定 key = "<Your-Azure-OpenAI-API-Key>" # APIキーを指定
次に、必要なライブラリをインポートします。
from synapse.ml.services.openai import OpenAIChatCompletion from pyspark.sql import Row
チャットベースのプロンプトを作成するための関数を定義します。
def make_message(role, content): return Row(role=role, content=content, name=role)
サンプルのメッセージを含むDataFrameを作成します。
chat_df = spark.createDataFrame(
[
(
[
make_message("system", "あなたは優秀なアシスタントです。ユーザーの質問に簡潔に回答部分だけを返答してください。"),
make_message("user", "日本一高い山は?"),
],
),
(
[
make_message("system", "あなたは優秀なアシスタントです。ユーザーの質問に簡潔に回答部分だけを返答してください。"),
make_message("user", "日本一広い湖は?"),
],
),
(
[
make_message("system", "あなたは優秀なアシスタントです。ユーザーの質問に簡潔に回答部分だけを返答してください。"),
make_message("user", "日本一長い川は?"),
],
),
]
).toDF("messages")
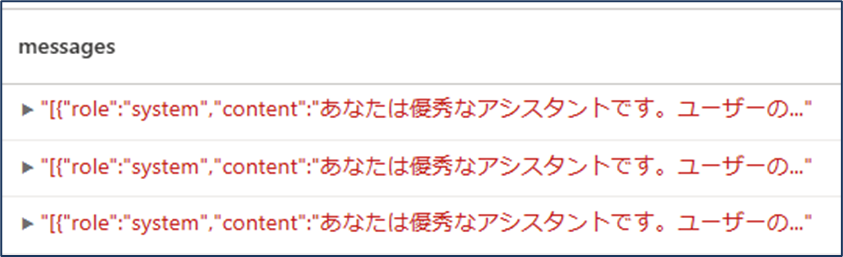
作成したDataFrameの内容を確認します。
display(chat_df)
続いて、OpenAIChatCompletionを使用して、Azure OpenAI Serviceへのリクエストを設定します。
chat_completion = (
OpenAIChatCompletion()
.setSubscriptionKey(key)
.setDeploymentName(deployment_name)
.setUrl(endpoint_url)
.setMessagesCol("messages")
.setErrorCol("error")
.setOutputCol("chat_completions")
)
上記では、messagesカラムを入力として、chat_completionsカラムに出力を取得します。
実際にリクエストを送信して、結果を取得します。
completion_df = chat_completion.transform(chat_df)
結果を表示します。
display(completion_df)
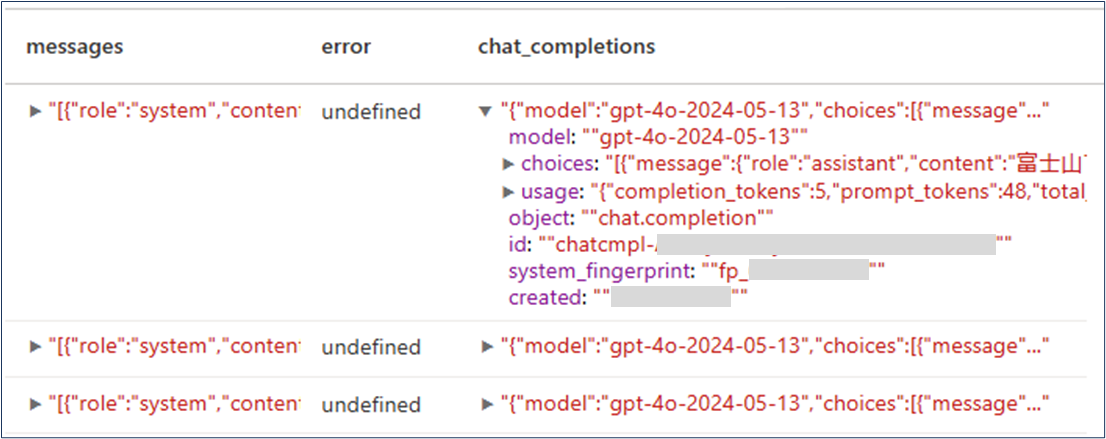
completion_dfには、各メッセージに対するLLMからの回答が含まれています。
必要に応じて、特定のカラムのみを選択して表示します。
from pyspark.sql.functions import col display( chat_completion.transform(chat_df).select( col("messages"), col("error"), col("chat_completions.choices.message.content"), ) )
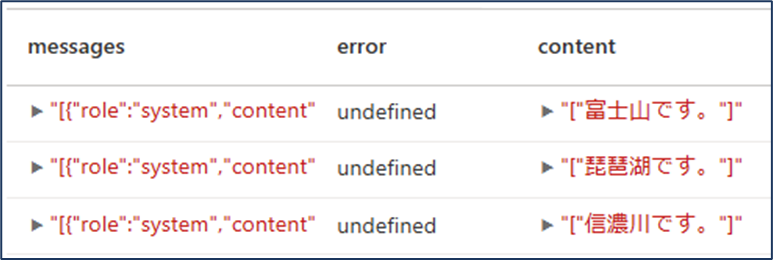
この結果、各質問に対する簡潔な回答を取得できます。
一般的なユースケースを想定した処理
上記では、手動でDataFrameを作成しましたが、実際のユースケースでは、外部データ(例えば、CSVファイルなど)からデータを読み込み、IDを付与して処理結果を識別することが一般的です。
そこで、今回はそのような状況を想定し、IDと質問のデータセットを用いたコードを紹介します。
データ準備
まず、サンプルデータとして、IDと質問を持つDataFrameを作成します。
from pyspark.sql import SparkSession # SparkSessionを取得 spark = SparkSession.builder.getOrCreate() # データを作成(IDと質問のペア) data = [ (1, "日本一高い山は?"), (2, "日本一広い湖は?"), (3, "日本一長い川は?") ] # カラム名を指定してDataFrameを作成 columns = ["id", "question"] question_df = spark.createDataFrame(data, schema=columns)
メッセージカラムの作成
questionカラムから、LLMに与えるメッセージ形式にデータを変換します。
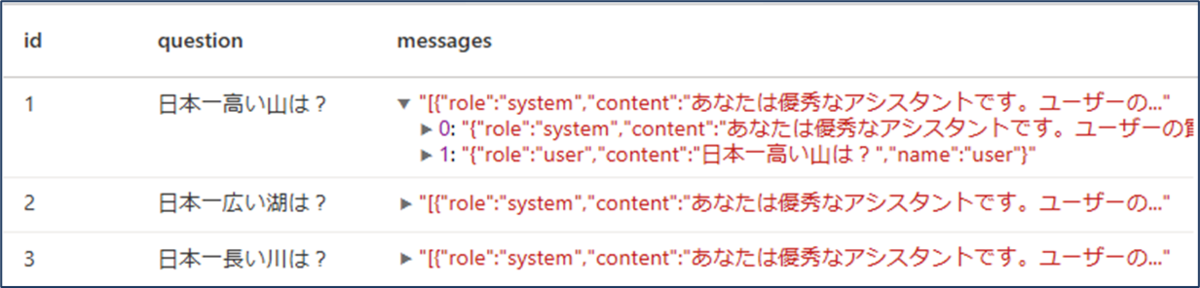
from pyspark.sql.functions import udf from pyspark.sql.types import ArrayType, StructType, StructField, StringType from pyspark.sql import Row # メッセージ作成用の関数を定義 def make_message(role, content): return Row(role=role, content=content, name=role) # 質問からメッセージリストを作成する関数を定義 def make_messages(question): # システムプロンプト system_prompt = "あなたは優秀なアシスタントです。ユーザーの質問に簡潔に回答部分だけを返答してください。" return [ make_message("system", system_prompt), make_message("user", question) ] # UDFを定義 make_messages_udf = udf(make_messages, ArrayType(StructType([ StructField("role", StringType(), nullable=False), StructField("content", StringType(), nullable=False), StructField("name", StringType(), nullable=False) ]))) # DataFrameにメッセージカラムを追加 process_df = question_df.withColumn("messages", make_messages_udf(question_df["question"])) # 結果を表示 display(process_df)
process_dfは以下のような構造になります。
データ処理
前述したOpenAIChatCompletionを使用して、一括で処理を行います。
chat_completion = (
OpenAIChatCompletion()
.setSubscriptionKey(key)
.setDeploymentName(deployment_name)
.setUrl(endpoint_url)
.setMessagesCol("messages")
.setErrorCol("error")
.setOutputCol("chat_completions")
)
process_df = chat_completion.transform(process_df)
LLMからの回答を抽出し、新たなカラムanswerとして追加します。
from pyspark.sql.functions import col # answerカラムを追加 process_df = process_df.withColumn( "answer", col("chat_completions.choices").getItem(0).getField("message").getField("content") ) # 結果を表示 display(process_df)
最終的なprocess_dfには、各IDと質問に対する回答が含まれています。

おわりに
本記事では、SynapseMLを利用してAzure Synapse Analytics上でAzure OpenAI ServiceのLLMを効率的に呼び出し、自然言語データを一括処理できる方法を紹介しました。これにより、例えば既存のAzure Synapse Analyticsのパイプラインなどに、自然言語に対する処理工程も追加できるということになります。
前回の記事で紹介した逐次処理よりも、今回の方法の方が実用的であり、特に大量データを扱う場合には強力な手法となります。
引き続きAzure Synapse AnalyticsとAzure OpenAIなどのLLMを統合する方法を検証し、紹介していきたいと思いますので、ご期待ください。
