
今回は、実際の機械学習モデルの作成の前にデータの欠損値の補完やデータの型変換を実施します。
前回の「 タイタニックの乗客生存予測モデルをFabricで作成してみた。(その1)」の続きとなります。
機械学習におけるデータ加工と前処理の必要性
以下の点から、機械学習を行う前にデータ加工と前処理が必要になります。
- データの品質向上:
- 前処理を行うことで、データの品質が向上し、分析結果の信頼性が高まります。
- アルゴリズムの性能向上:
- クリーンで整ったデータは、機械学習アルゴリズムの性能を最大限に引き出します。
- 効率的な分析:
- 前処理をしっかり行うことで、後の分析作業がスムーズに進みます。
実施することとしては、以下のようなものが挙げられます。
- データのクレンジング
- 欠損値の処理: 欠損値を適切に処理しないと、分析結果が歪む可能性があります。
- 異常値の検出と処理: 異常値を見つけて対処することで、データの信頼性を高めます。
- データの標準化と正規化
- 標準化: データのスケールを揃えることで、アルゴリズムの性能を向上させます。
- 正規化: データの分布を均一にすることで、分析の精度を高めます。
- 特徴量エンジニアリング
- 新しい特徴量の作成: 既存のデータから新しい有用な特徴量を作成することで、モデルの性能を向上させます。
- 特徴量の選択: 不要な特徴量を削除し、重要な特徴量に集中することで、モデルの複雑さを減らします。
今回は以下のような流れでデータ加工と前処理を実施します。
- 特徴量の選択
- 欠損値の処理
- 新しい特徴量の作成
特徴量エンジニアリング~特徴量の選択
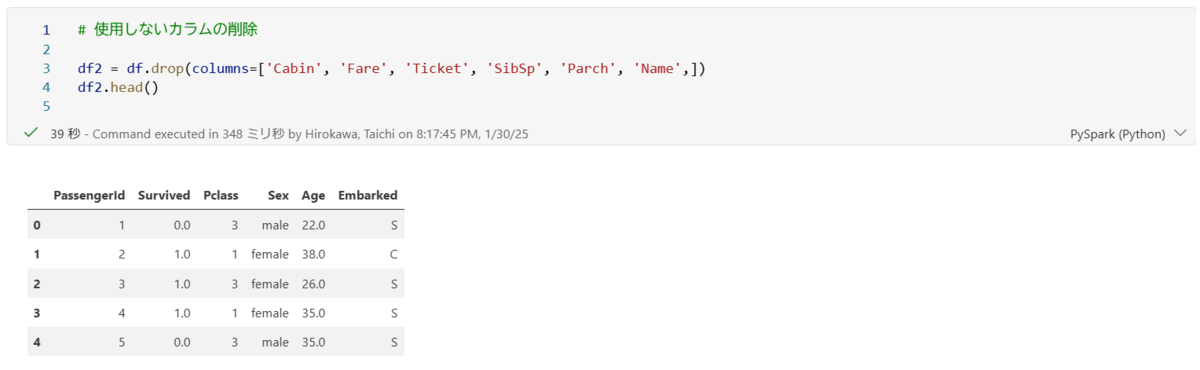
今回、特徴量として使用したいカラムは以下の項目となり、使用しないカラムを削除します。
- Pclass
- Sex
- Age
- Embarked
削除した後のデータフレームを確認したいため、headメソッドを使用します。
データのクレンジング~欠損値の処理
乗客の年齢(=Age)、出発した港(=Embarked)に欠損値が存在していました。
欠損値を削除をするのもいいですが、今回のタイタニックのテストデータはデータ数が少ないので、補完して、情報量を減らさすことなく機械学習モデルで予測できるようにしたいと思います。
出港地カラム
以下の内容で欠損値の数を確認していきます。
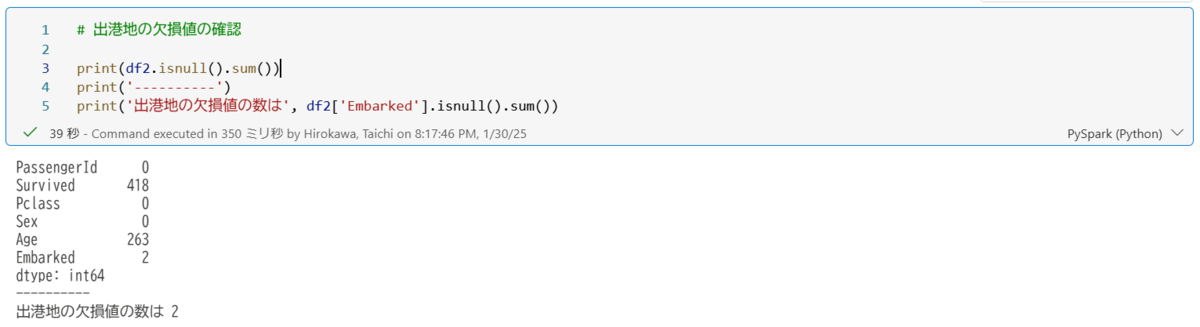
上記の通り、2人の乗客の出港地に関する欠損値が特定できたので、最も乗客の多い港で欠損値を補完していきます。
以下の内容で、乗客の多い港を確認します。

上記の通り、「S」という港に割合が多いことがわかったので、2人の欠損値を「S」で補完していきます。

年齢カラム
出港地と同様に年齢の欠損値の補完を行っていくので、初めに以下の内容で年齢の欠損値の確認を行います。

欠損値の数が特定でき、出港地に比べて欠損値が多いことが把握できました。
補完する前に、ヒストグラムを使用して年齢の分布を把握していきます。グラフで最小値、最大値を把握したいので以下のようなコードを記載していきます。
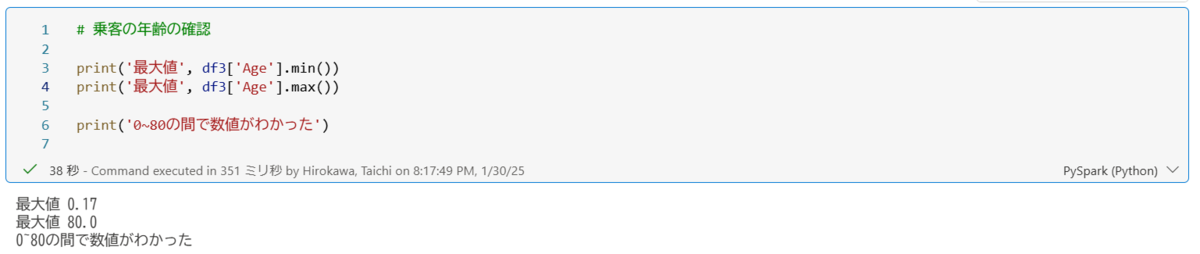
上記の通り、最小値が0,最大値が80ということがわかります。
最小値、最大値から、乗客の年齢を8分割したほうがわかりやすそうだったので、以下の内容でヒストグラムを作成していきます。
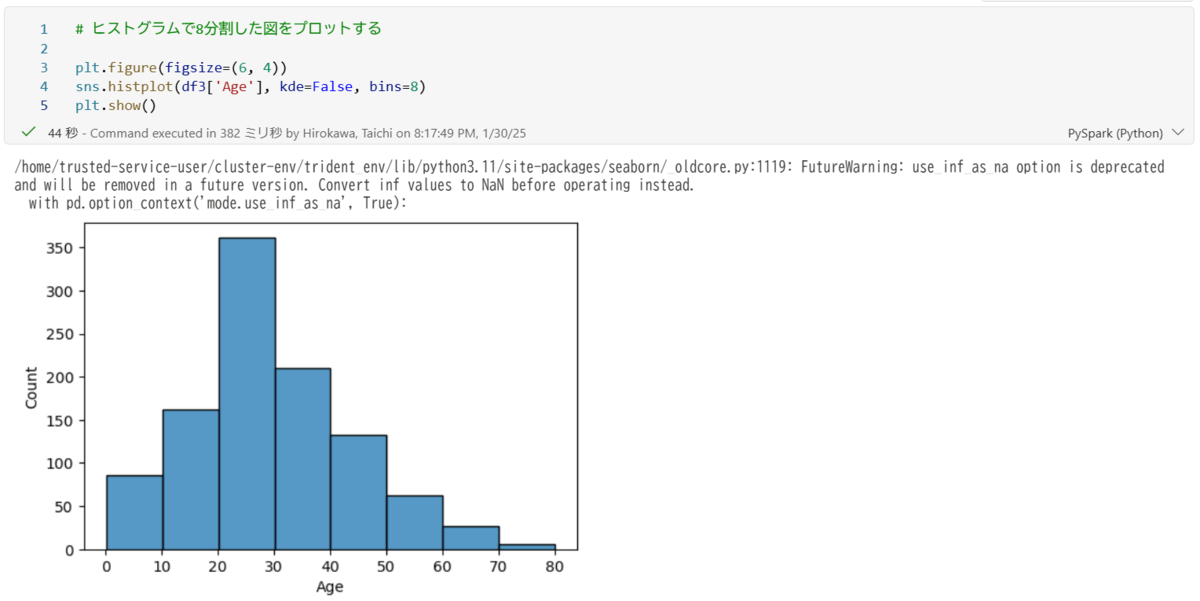
上記のように年齢の分布を可視化することができ、以下のことがわかりました。
- 20~30代の分布が多いこと
- 平均値より中央値を使用したほうがよさそうなこと
- 0~20より、30~80の値が多いため、平均値を使用すると後者の年齢に数値が偏りそうなこと
以下の内容で平均値と中央値を確認していきます。
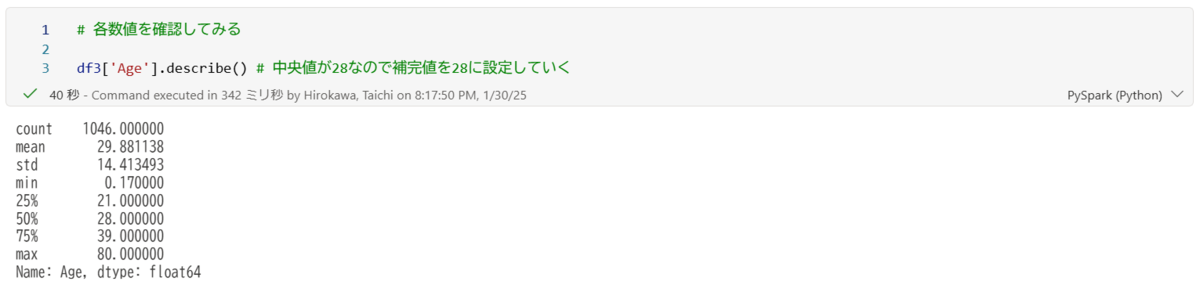
すべての値を28に補完することは正確ではありませんが、今回は中央値の28歳で補完していきます。
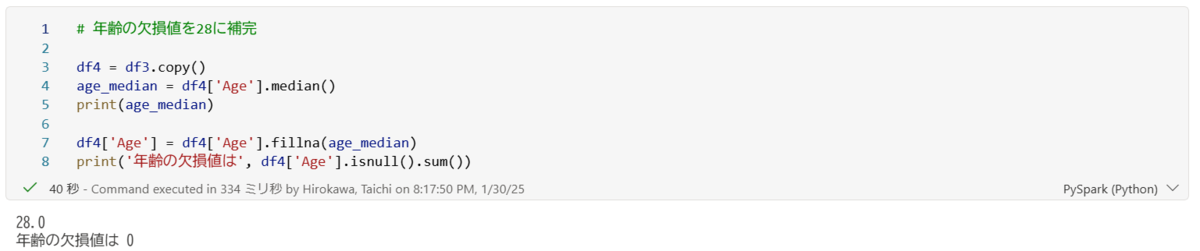
上記の結果でわかる通り、年齢欠損値を28で置き換えて、df4にて保管した後のデータを確認すると、欠損値を補完することができました。
ここまでで、使用したい特徴量の欠損値はすべて補完できました。
※注意:欠損値を今回は簡単に設定しましたが、本来であれば慎重に決めないと精度の高い機械学習モデルは作成できません。ですので、欠損値を決める際は、様々なデータを見て予測を立てて、値を慎重に決めることをお勧めします。
特徴量エンジニアリング~新しい特徴量の作成
ここでは、数値で表せない特徴量を、カテゴリ変数を使用して数値に変換していく作業を行っていきます。
機械学習では数値しか理解できないため、カテゴリ変数を使用して数値に起こしていく作業を行っていきます。
カテゴリ関数変換
ここでは以下のカテゴリ変数変換を使用していきます。
- ワンホットエンコーディング
- カテゴリカルデータをバイナリベクトルに変換する方法です。
- 各カテゴリは、0と1の組み合わせで表現されます。
- ラベルエンコーディング
- カテゴリカルデータを整数値に変換する方法です。
- 各カテゴリは一意の整数で表現されます。
出港地のワンホットエンコーディング
出港地カラムに、以下の内容でワンホットエンコーディングを行っていきます。
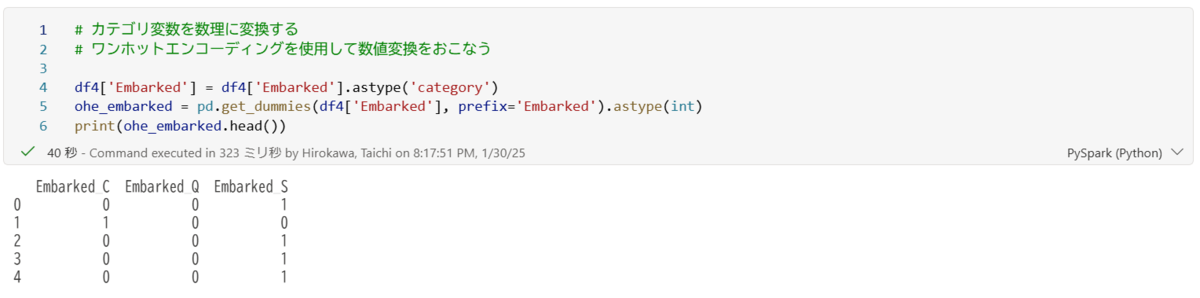
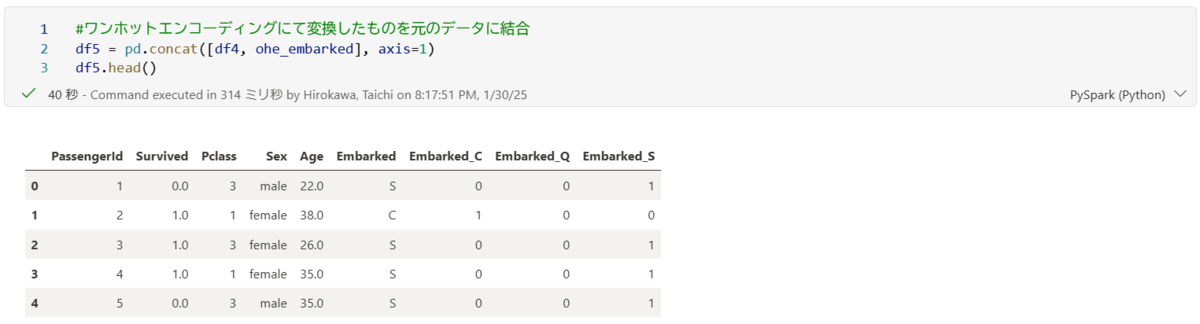
上記よりワンホットエンコーディング変換ができたので、元のデータフレームへ連結していきます。
headメソッドで連結されていることを確認します。
エンコーディングされたカラムだけあれば大丈夫なので、元の文字が含まれた「Embarked」のカラムを削除します。
headメソッドで削除されたことを確認できました。
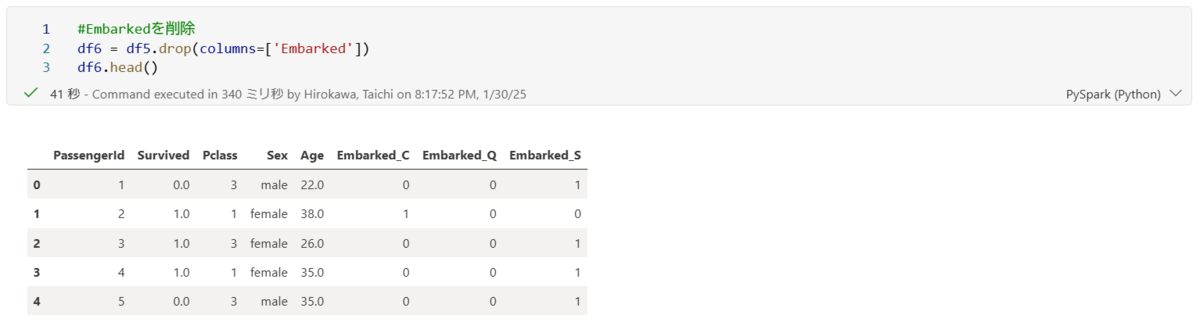
以上で、出港地のカテゴリ変数変換により、数値変換ができました。
性別のラベルエンコーディング
次に、性別カラムに以下の通りにエンコーディングしていきます。
headメソッドで性別がラベルエンコーディングされていることがわかります。
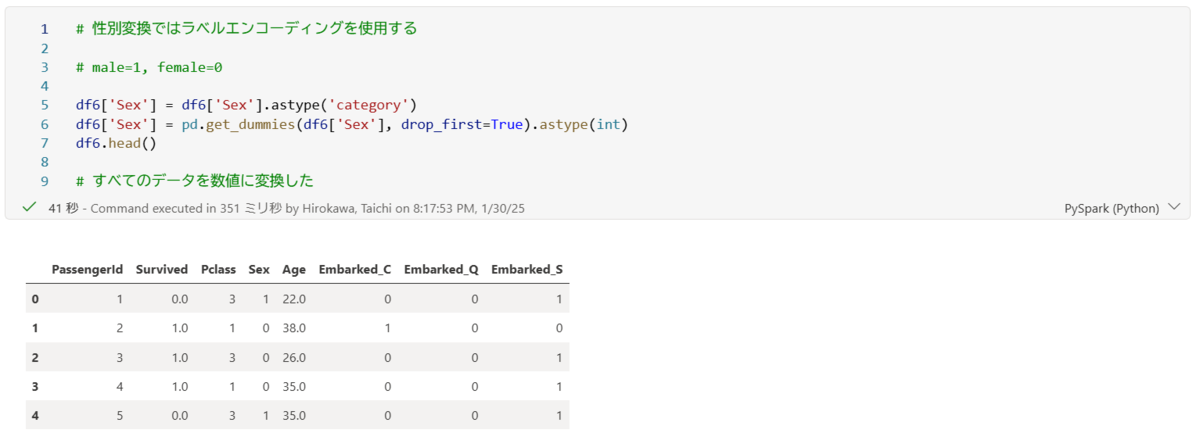
以上より、すべてのカラムが数値データに変換することができました。
まとめ
今回は、欠損値の補完と、すべてのカラムデータを数値に変換することができました。
機械学習モデル作成には、以上のようなことが必須となってきます。
次回からは、機械学習モデルを作成して、タイタニック号の乗客が生存するか否かを予測していく流れとなります。

廣川 太一(日本ビジネスシステムズ株式会社)
クラウドテクノロジーサービス事業本部Data&AIプラットフォーム部Dataソリューション1グループ所属 Microsoft Fabric、SnowflakeのデータをAIに連携し誰でもデータ探索ができるよう活動中。 新潟出身の優しい筋肉。
担当記事一覧