
Microsoft Fabricは、データの移動や処理、変換、リアルタイム分析、レポート作成などの機能を統合した企業向けのSaaS型プラットフォームです。
今回は、試用版のMicrosoft Fabricを使用して、Microsoft Fabricに取り込んだ2つのデータ(日本のGDP成長率と失業率)を結合し、相関関係を可視化する方法をご紹介します。
データソースの準備
今回は、World Bank Groupのオープンソースデータを使用します。
上記から、GDP成長率と失業率のデータをダウンロードします。
- GDP growth(annual%)
- Unemployment, total(% of total labor force)(modeled ILO estimate)
ダウンロードしたCSVファイルを、識別しやすい任意の名前に変更します。

データソースの取り込み
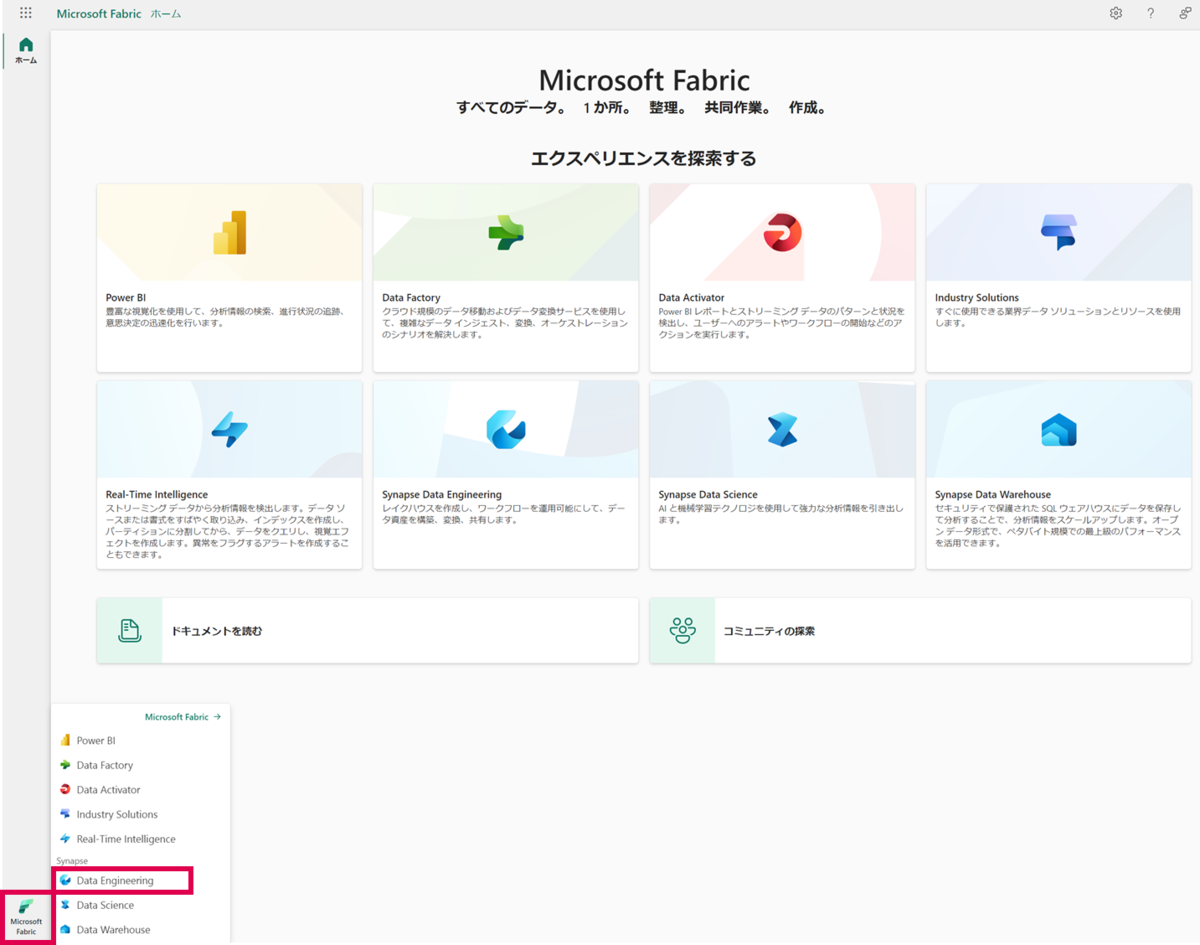
Microsoft Fabric トップページを開いて左下の「Microsoft Fabric」を選択し、メニューバーからData Engineeringを押下し、Synapse Data Engineeringホーム画面を開きます。
任意のワークスペースを選択し、「新規」>「レイクハウス」の順に押下します。

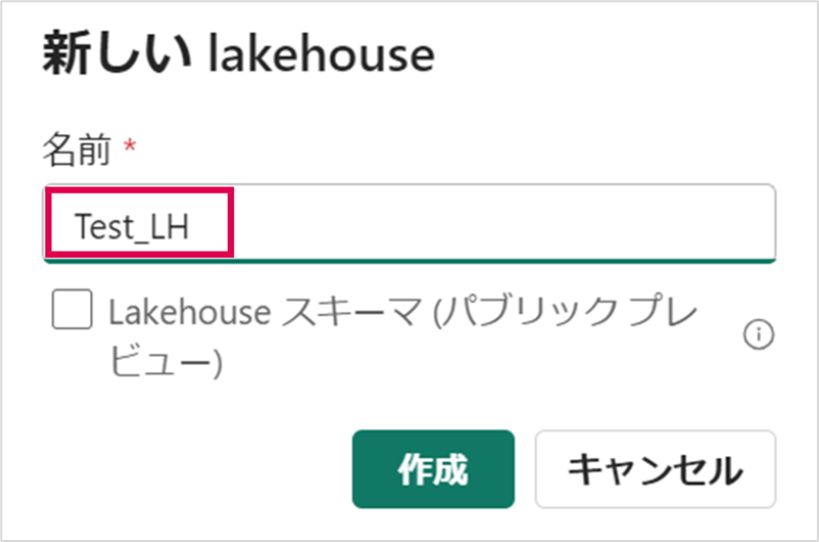
任意の名前を入力して、レイクハウスを作成します。
作成したレイクハウス(Test_LH)にデータソースを取り込んでいきます。「データの取得」>「ファイルのアップロード」の順に押下します。

取り込む2つのデータをそれぞれ指定し、アップロードを押下します。
※ 画像はGDP_growth.csvですが、Unemployment.csvも同様に行います。

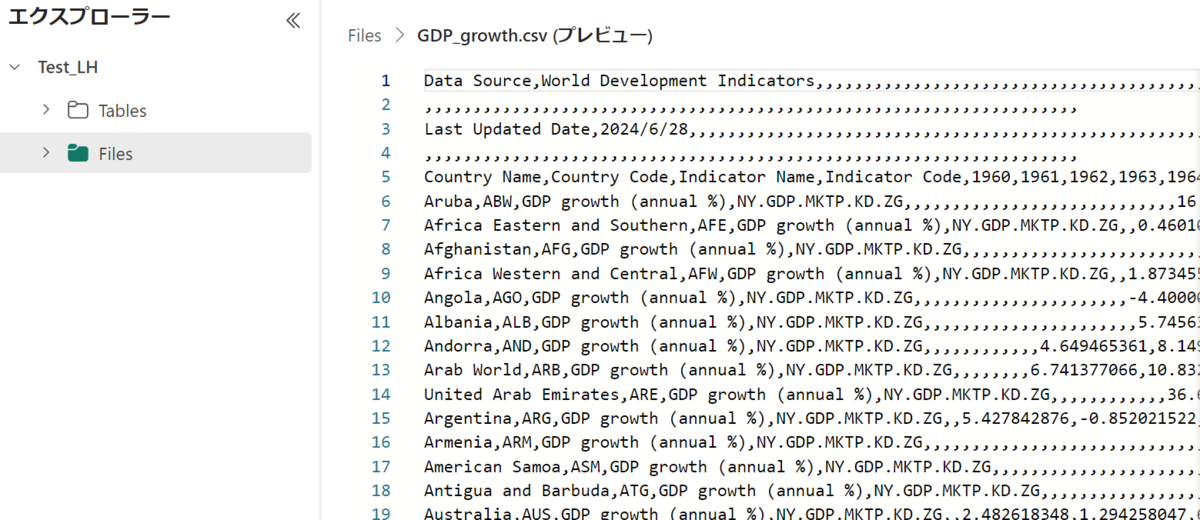
エクスプローラーの「Files」で、アップロードしたデータの確認ができます。

これで、Microsoft Fabricへのデータの取り込みが完了しました。
データの加工
生データを取り込んだだけでは、下図のように余計な行や空白があることから、データの加工が必要になります。
データフローへのインポート
データの加工は、データフローを用います。
左メニューバーから「作成」>「データフロー」の順に押下します。

「データを取得」>「詳細」を押下します。

データソースの選択でレイクハウス(Test_LH)を選択します。
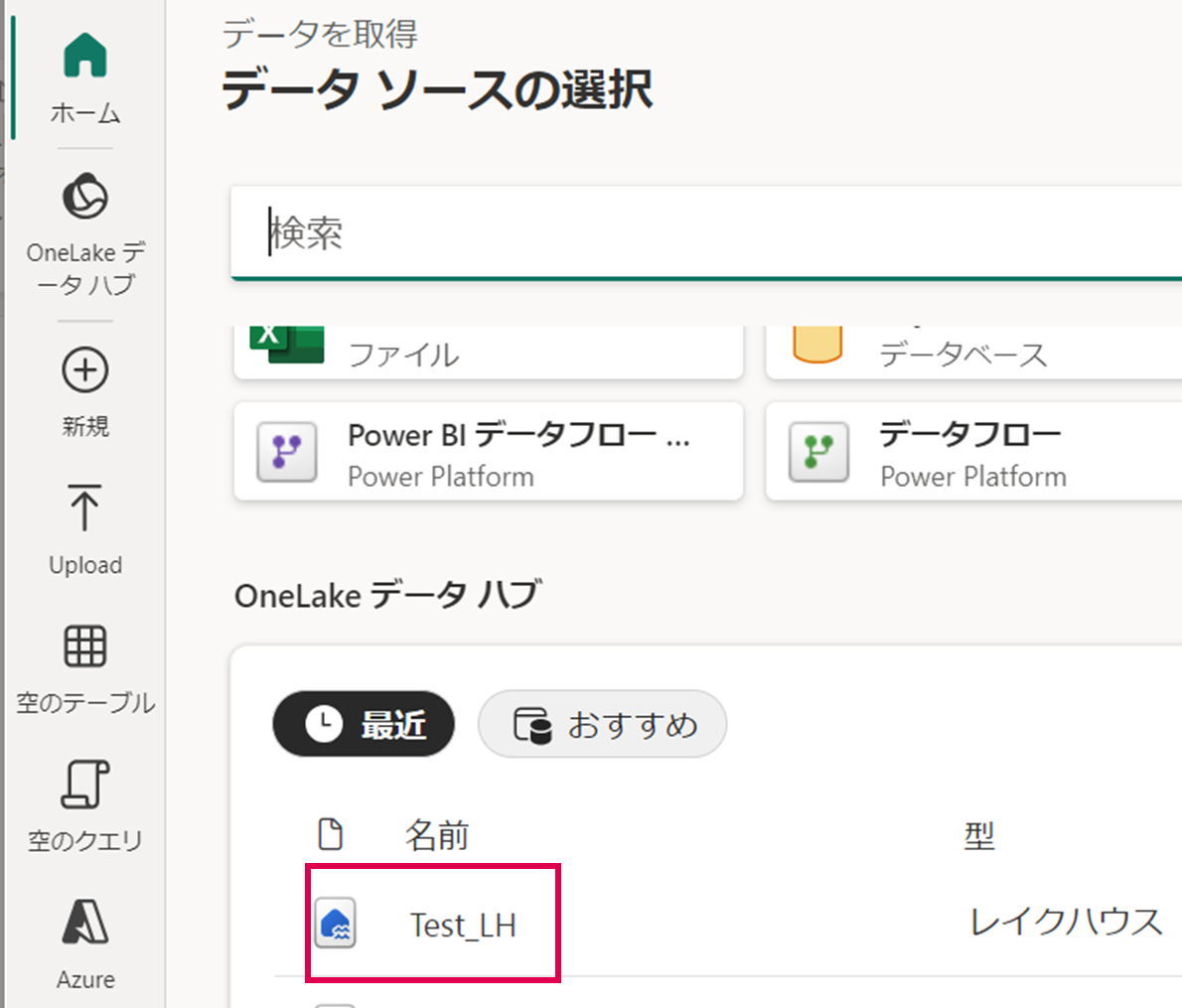
先ほど取り込んだ2つのデータにチェックを入れて、画面右下の「作成」を押下します。
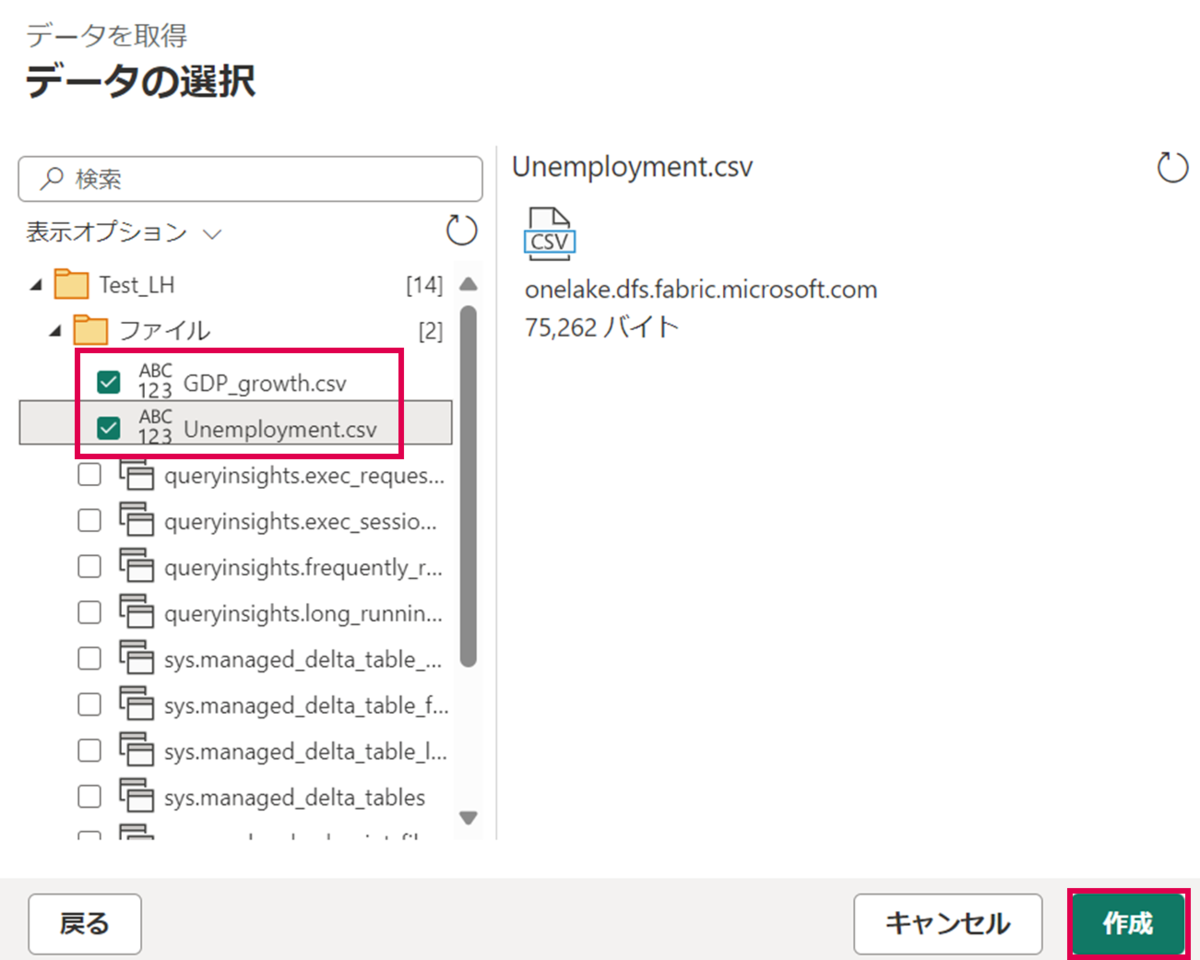
これでデータフローへ2つのデータのインポートが完了しました。
データ構造とデータ型の変換
「変換」>「入れ替え」の順に押下し、テーブルの行と列を入れ替えます。

「ホーム」>「列の管理」>「列の選択」の順に押下します。

本記事では、日本のみのデータを使用するため、年列である「Column5」と日本列である「Column125」のみにチェックを付け、「OK」を押下します。

「Column5」と「Column125」の列名では識別しにくいため、任意の名前に変更します。列名を右クリックして「名前の変更」を押下し、任意の名前を記入します。
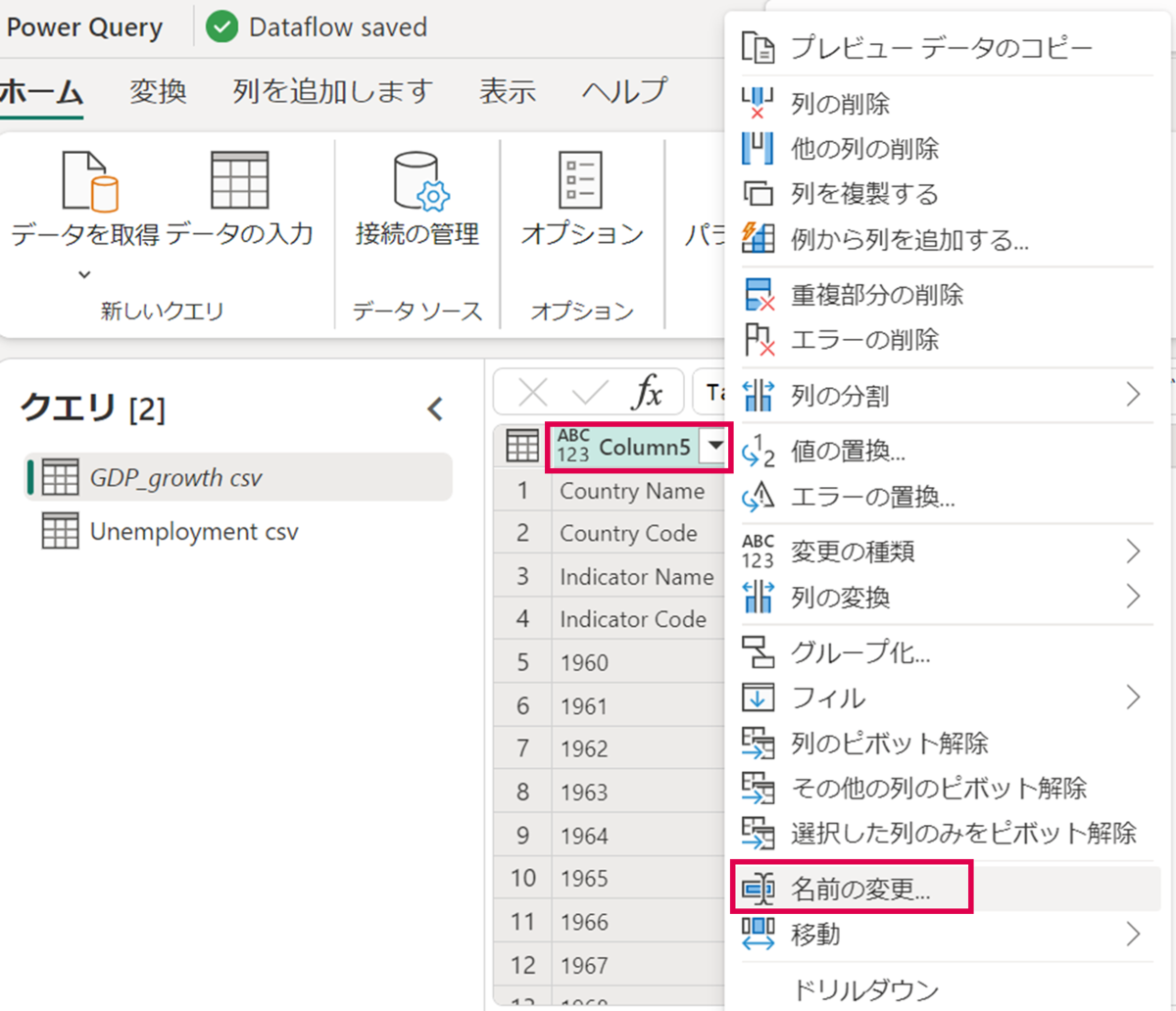
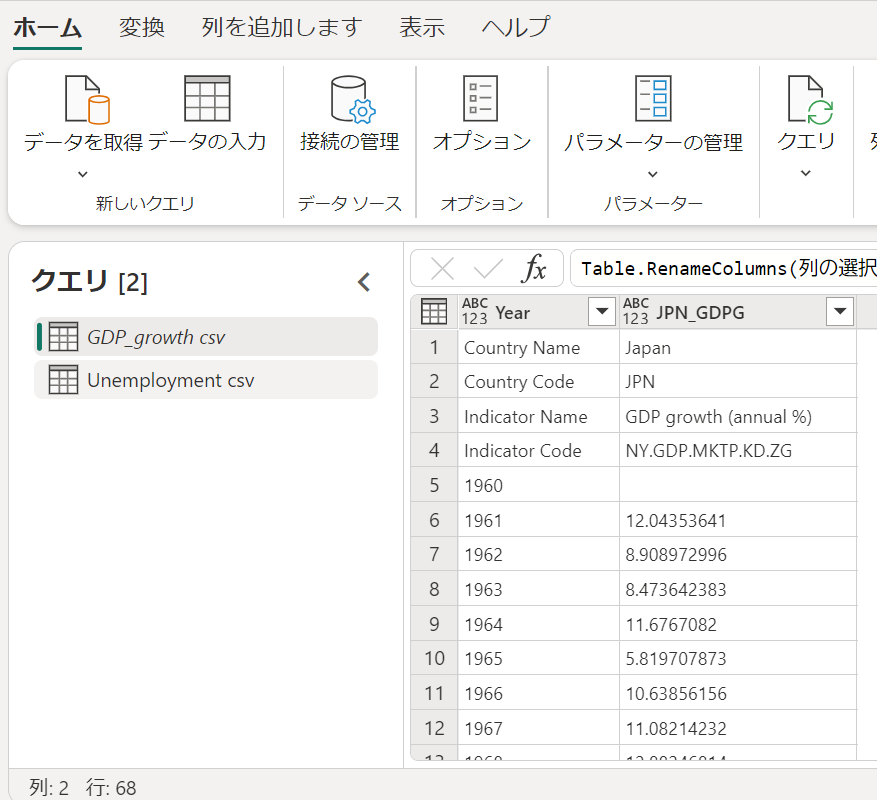
今回は、下記のように列名を変更しました。
| 変更前 | 変更後 |
| Column5 | Year |
| Column125 | JPN_GDPG |
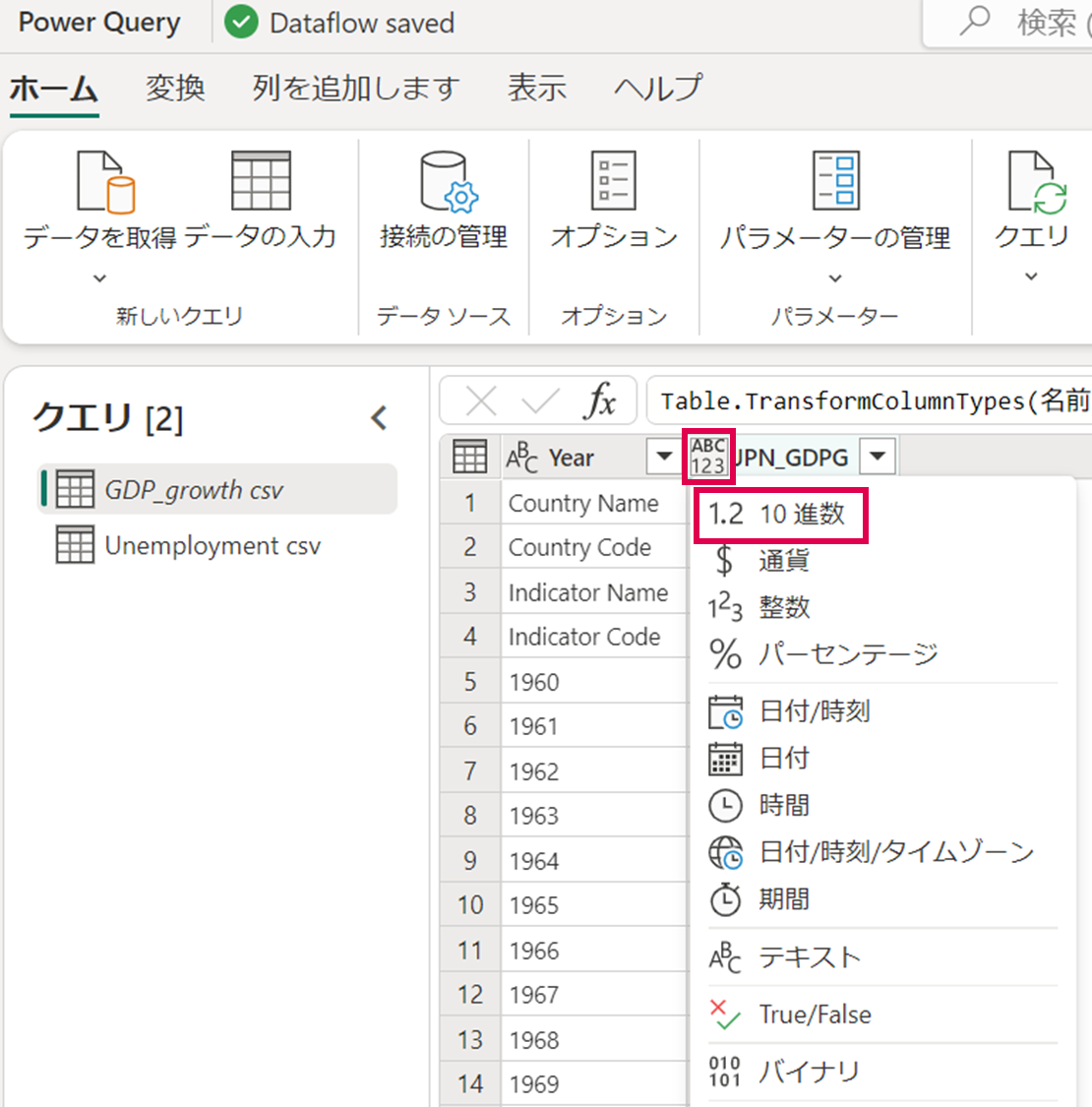
「Year」列はテキストとして扱う必要があるため、列名の左側「ABC123」をクリックし、「テキスト」を選択します。

また、「JPN_GDPG」列は数値として扱う必要があるため、列名の左側「ABC123」をクリックし、「10進数」を選択します。
エラー値と空白行の削除
「JPN_GDPG」列を選択している状態で、「行の削除」>「エラーの削除」を押下します。
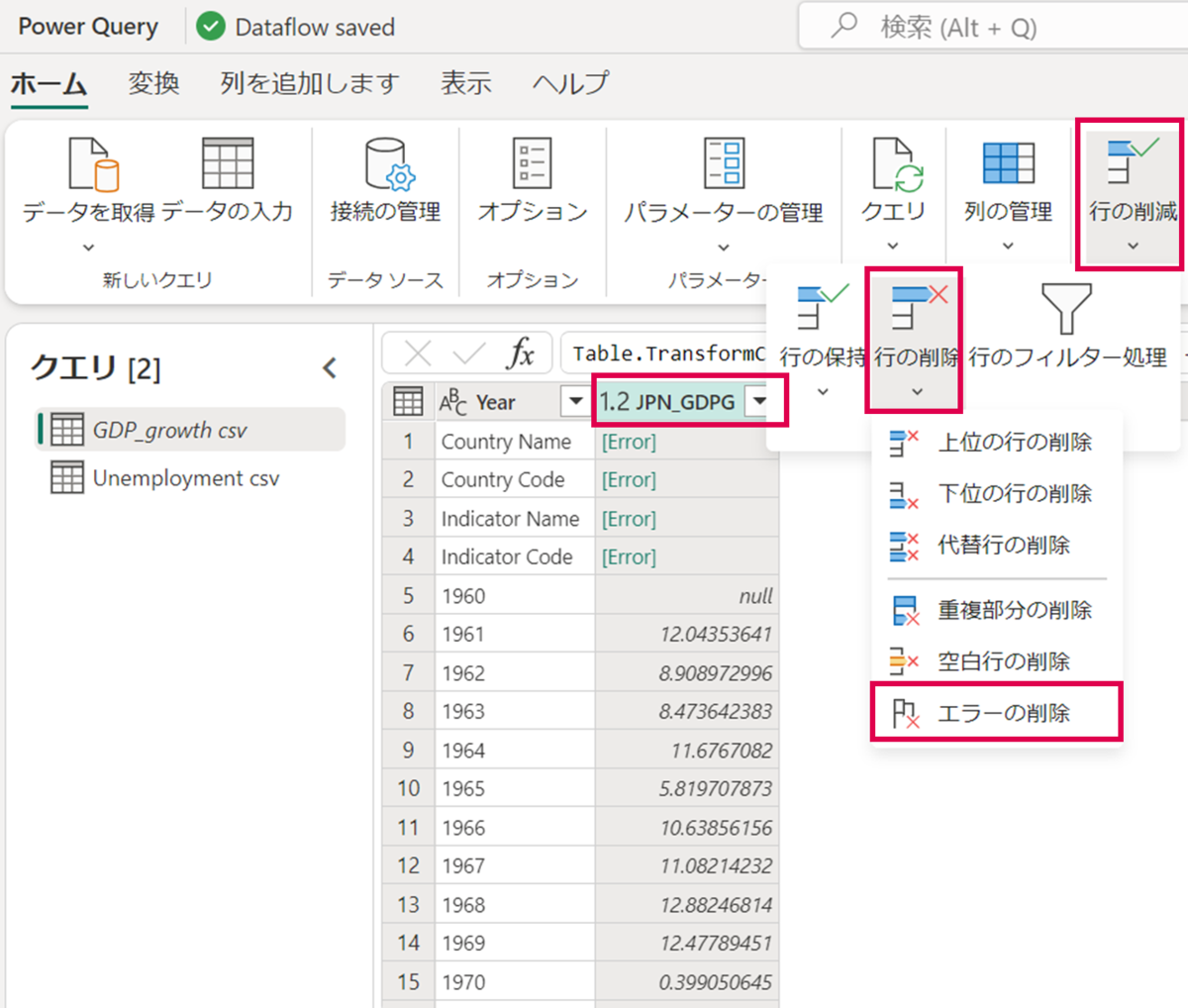
「JPN_GDPG」列の展開ボタンをクリックし、「空の削除」を押下します。

これで「GDP_growth.csv」のデータ加工が完了しました。
※「Unemployment.csv」も同様にデータ加工を行います。
テーブルの結合
本記事では、2つのデータの相関関係を可視化するため、テーブルデータの結合処理を行います。
「結合」>「クエリのマーク」の順に押下します。
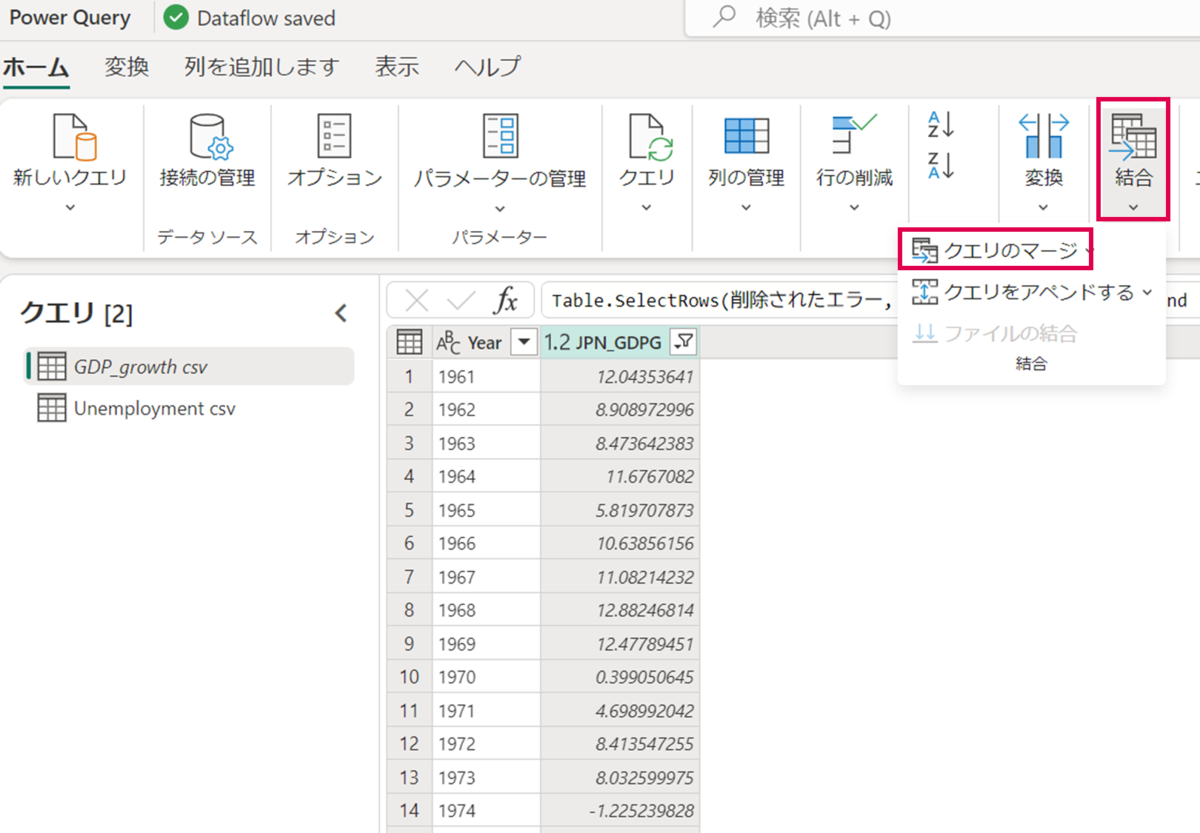
左テーブルと右テーブルそれぞれ「Year」列を結合列を選択します。結合の種類は「左外部」を選択し、「OK」を押下します。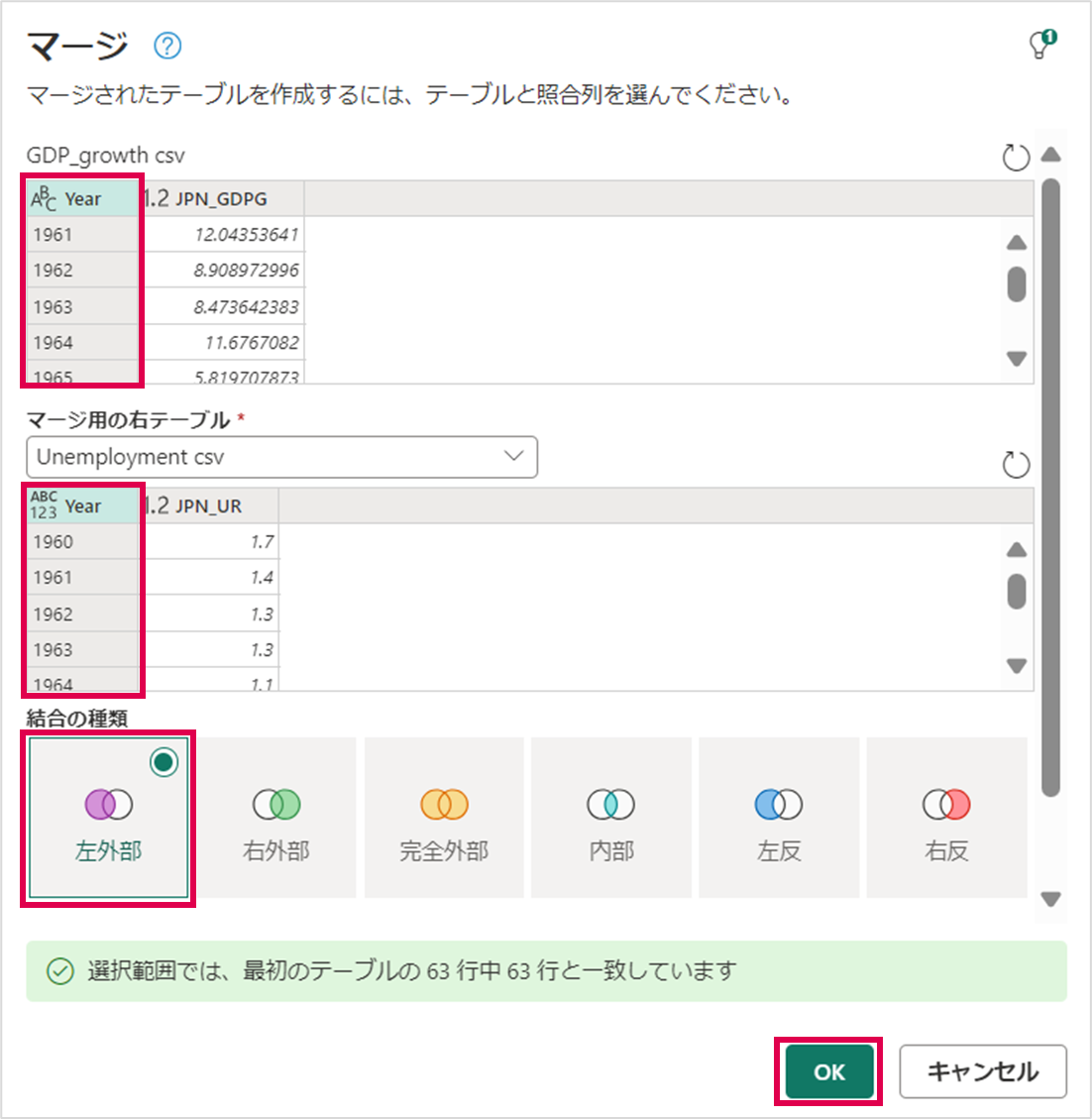
結合した「Unemployment.csv」の展開ボタンを押下し、「Year」のチェックを外し、「OK」を押下します。
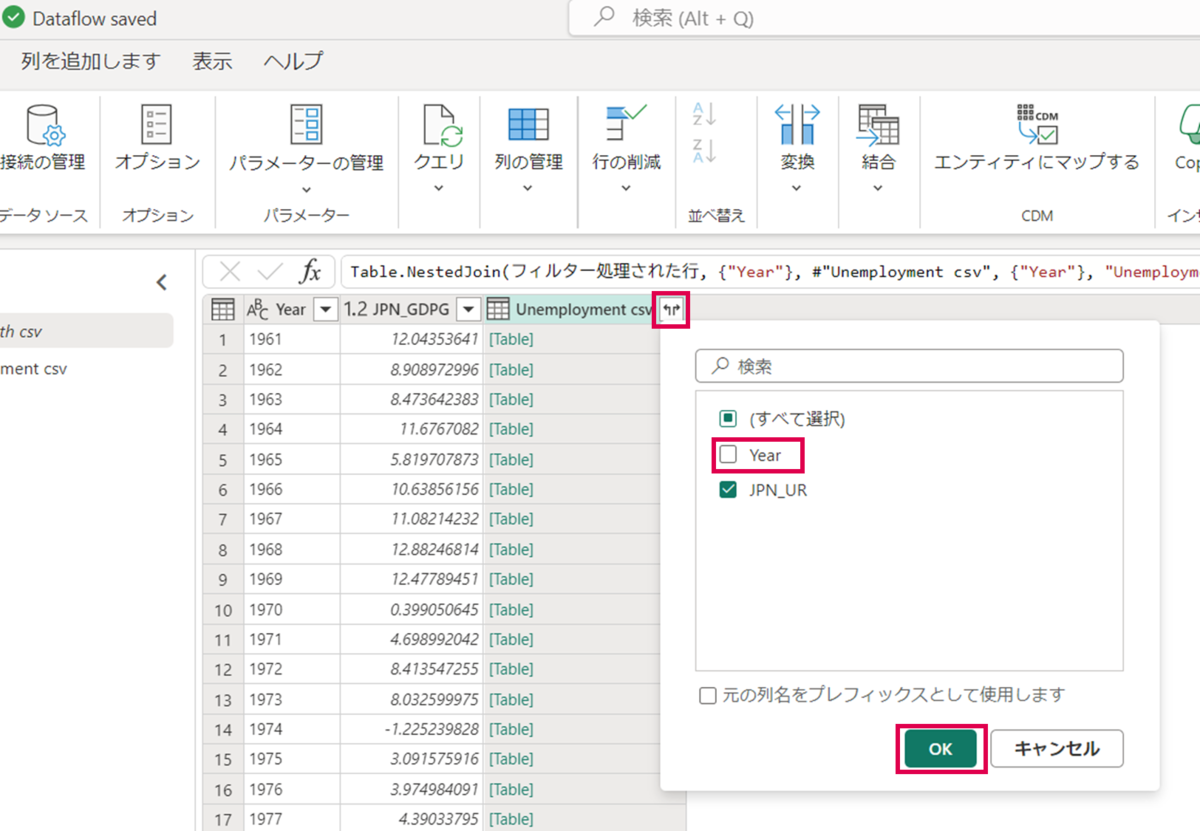
これでデータの加工が完了しました。下図が加工後のテーブルデータになります。
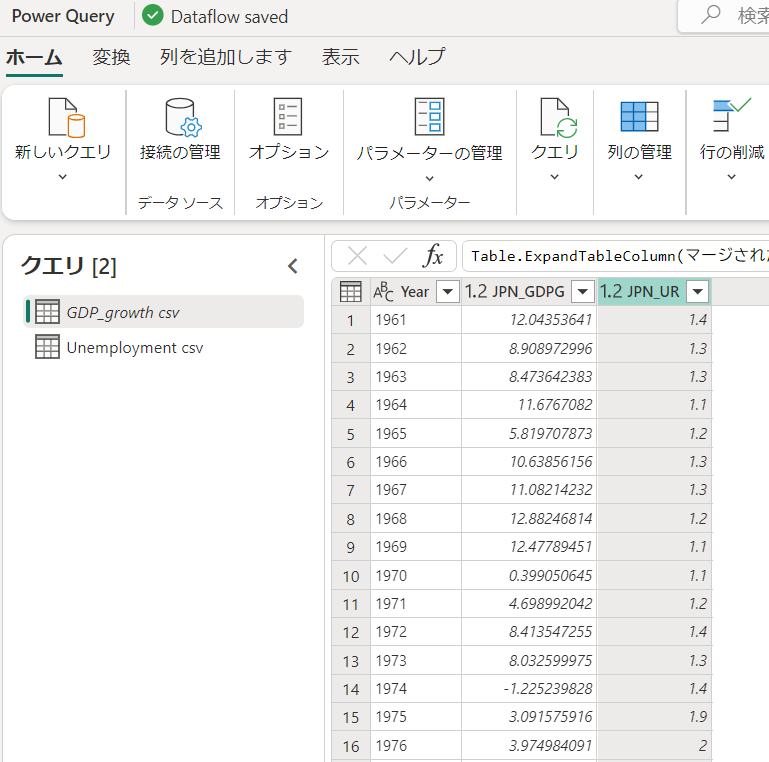
公開先の指定
加工したデータの同期先を指定します。画面右下、「データ同期先」>「レイクハウス」の順に押下します。
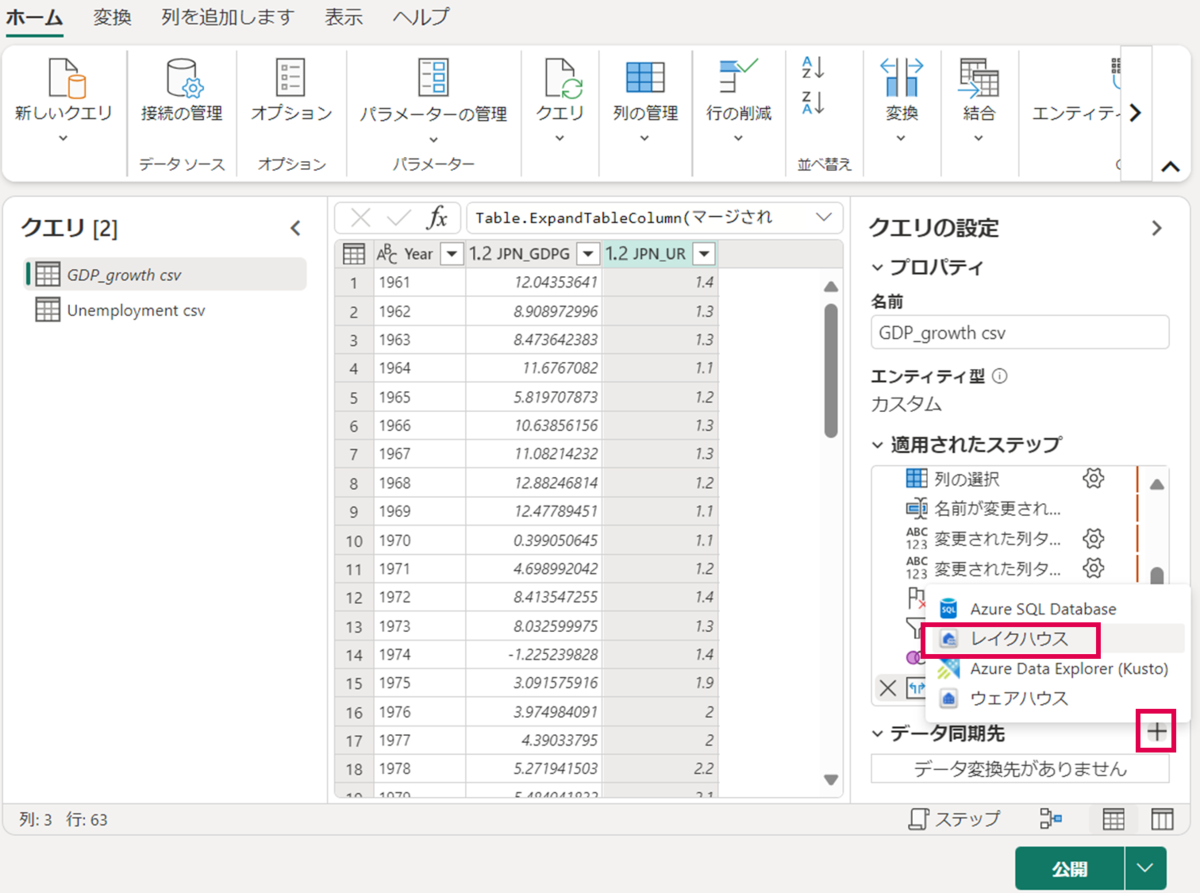
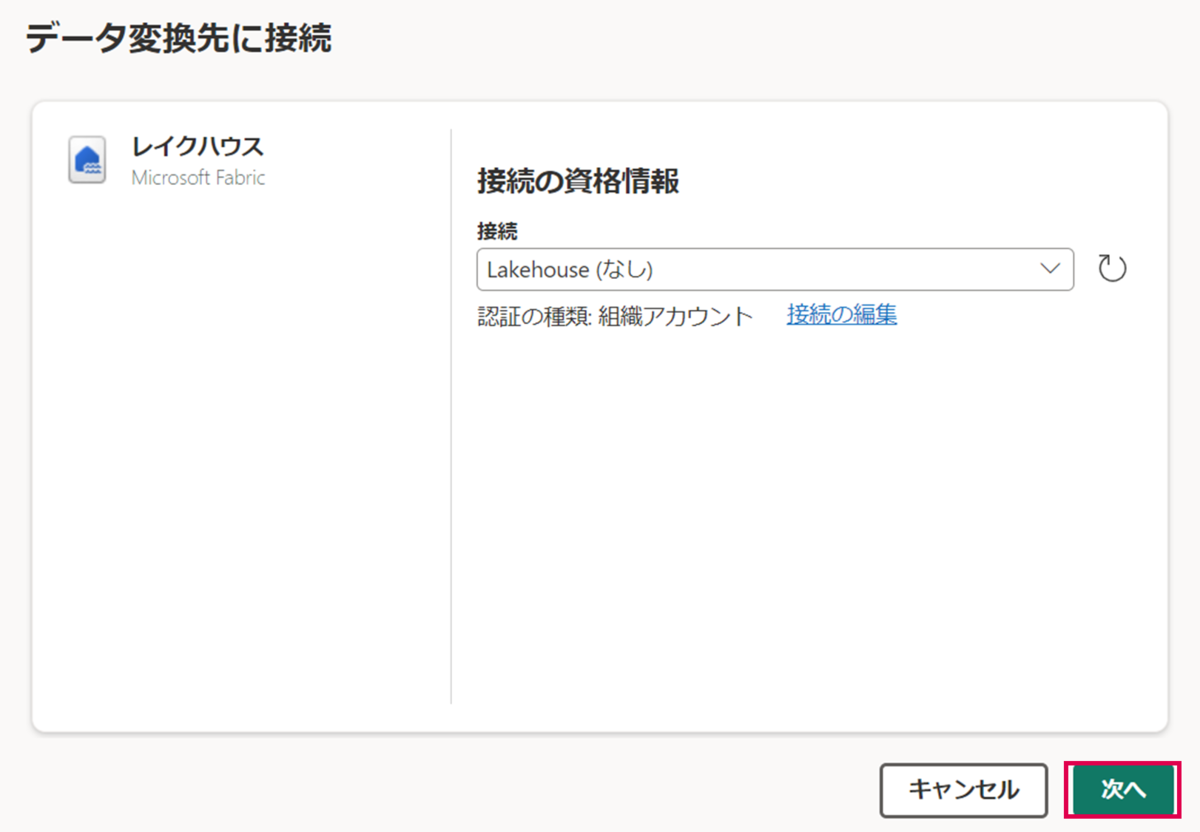
「次へ」を押下します。
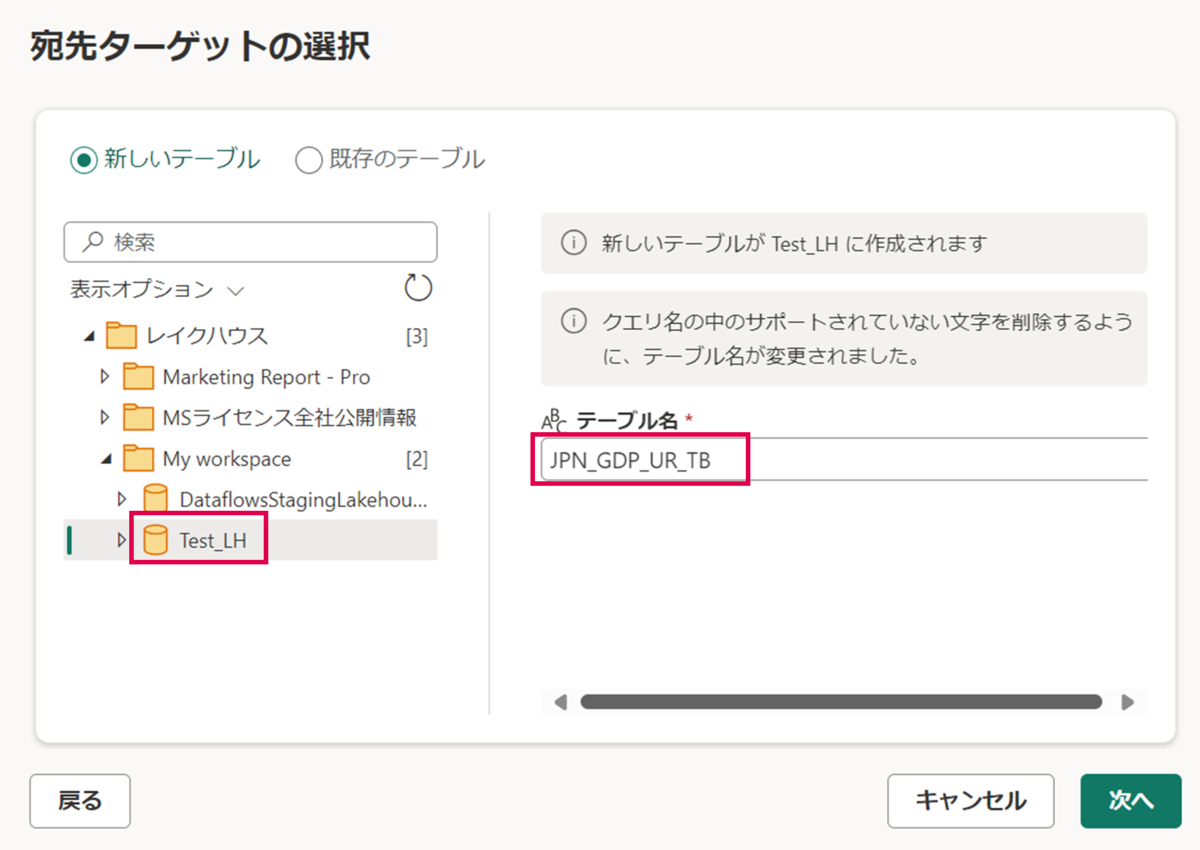
任意のテーブル名を入力し、レイクハウスの「Test_LH」を同期先として指定し、「次へ」を押下します。
「設定の保存」を押下します。
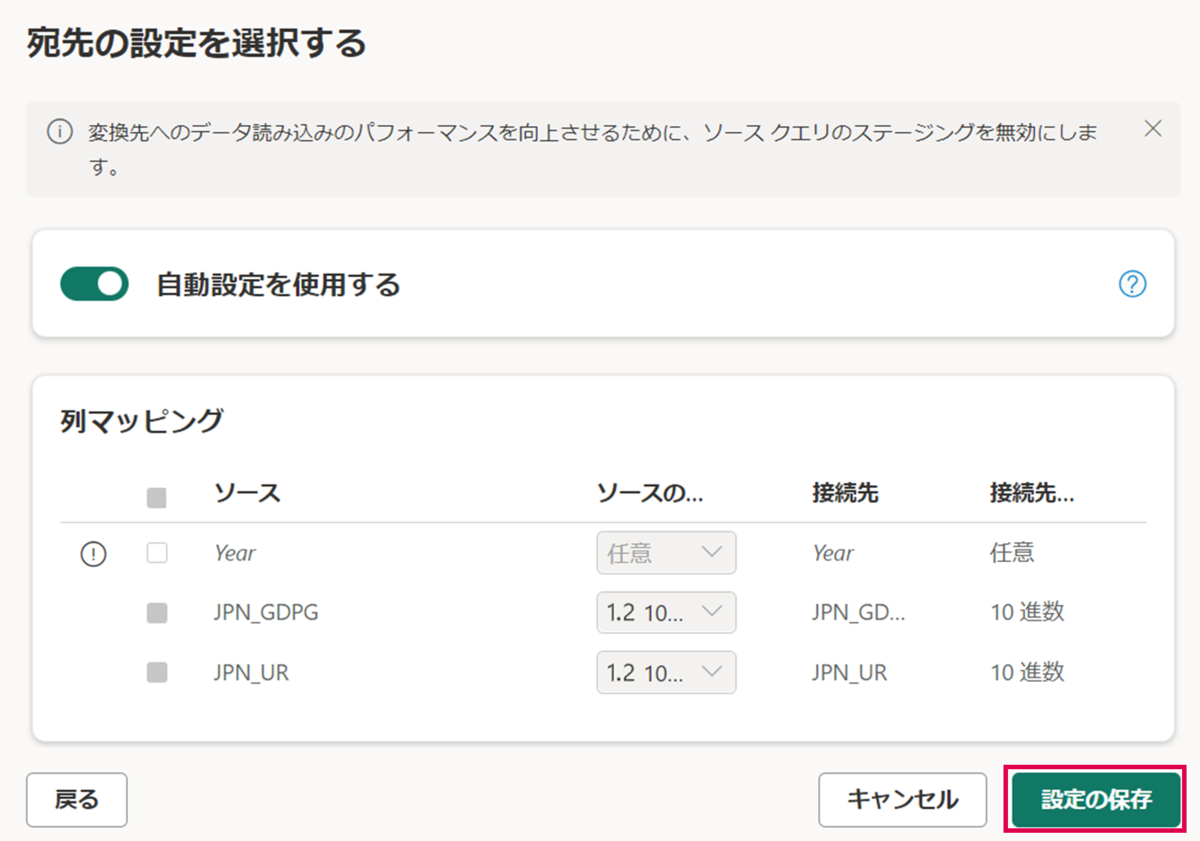
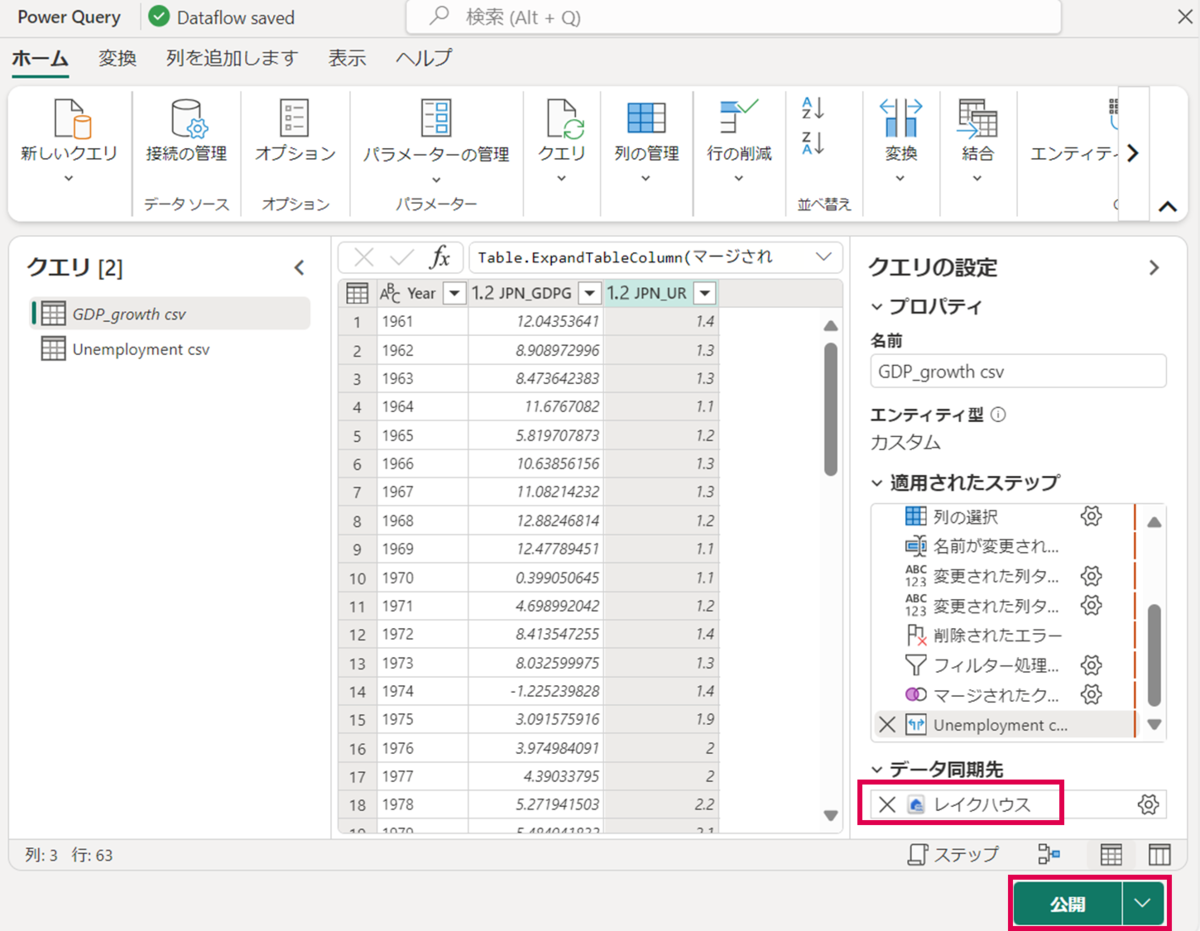
データ同期先に「レイクハウス」が選択されていることを確認し、「公開」を押下します。
My Workspaceからレイクハウス(Test_LH)を押下し、加工後のテーブルデータ(JPN_GDP_UR_TB)が作成されていることを確認します。
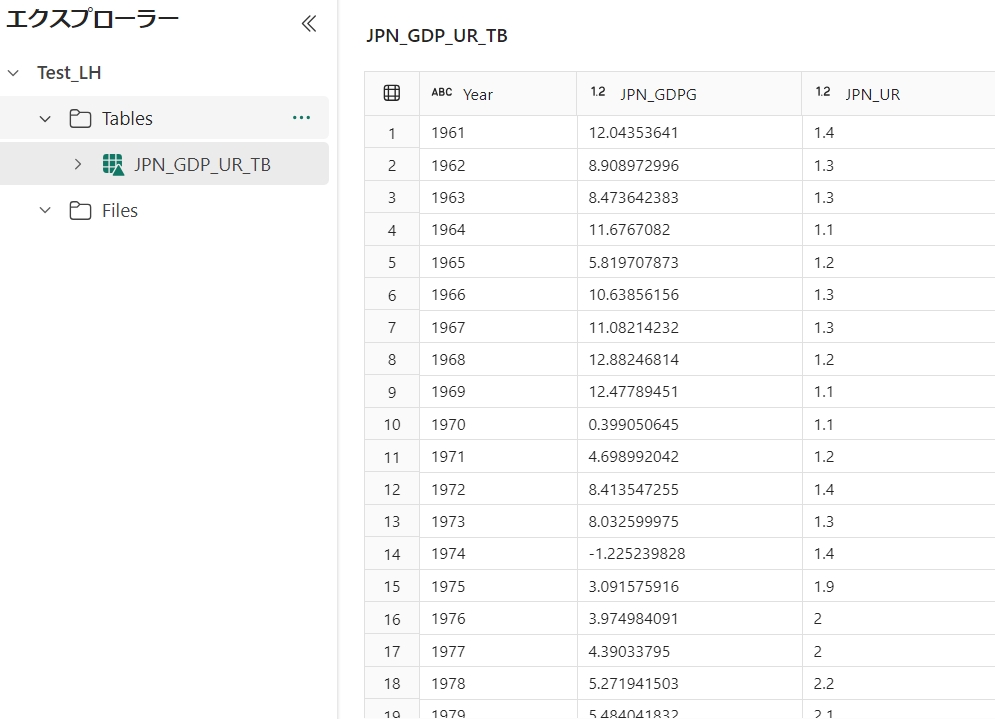
これで、加工したテーブルデータのレイクハウスへの反映が完了しました。
データの可視化
データフローで加工したテーブルデータをもとにレポートを作成し、GDP成長率と失業率の相関関係を可視化します。
レイクハウス(Test_LH)の画面右上の「Lakehouse」>「SQL分析エンドポイント」の順に押下し、SQL分析エンドポイントに切り替えます。
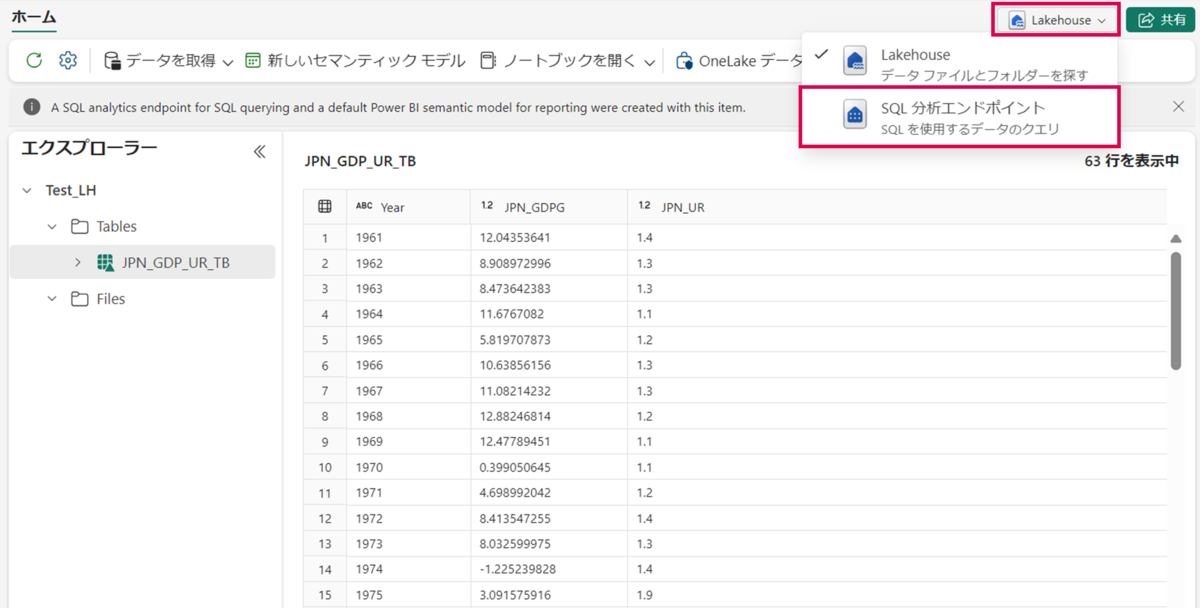
テーブル(JPN_GDP_UR_TB)を選択し、「既定のセマンティック モデルに追加」を押下します。
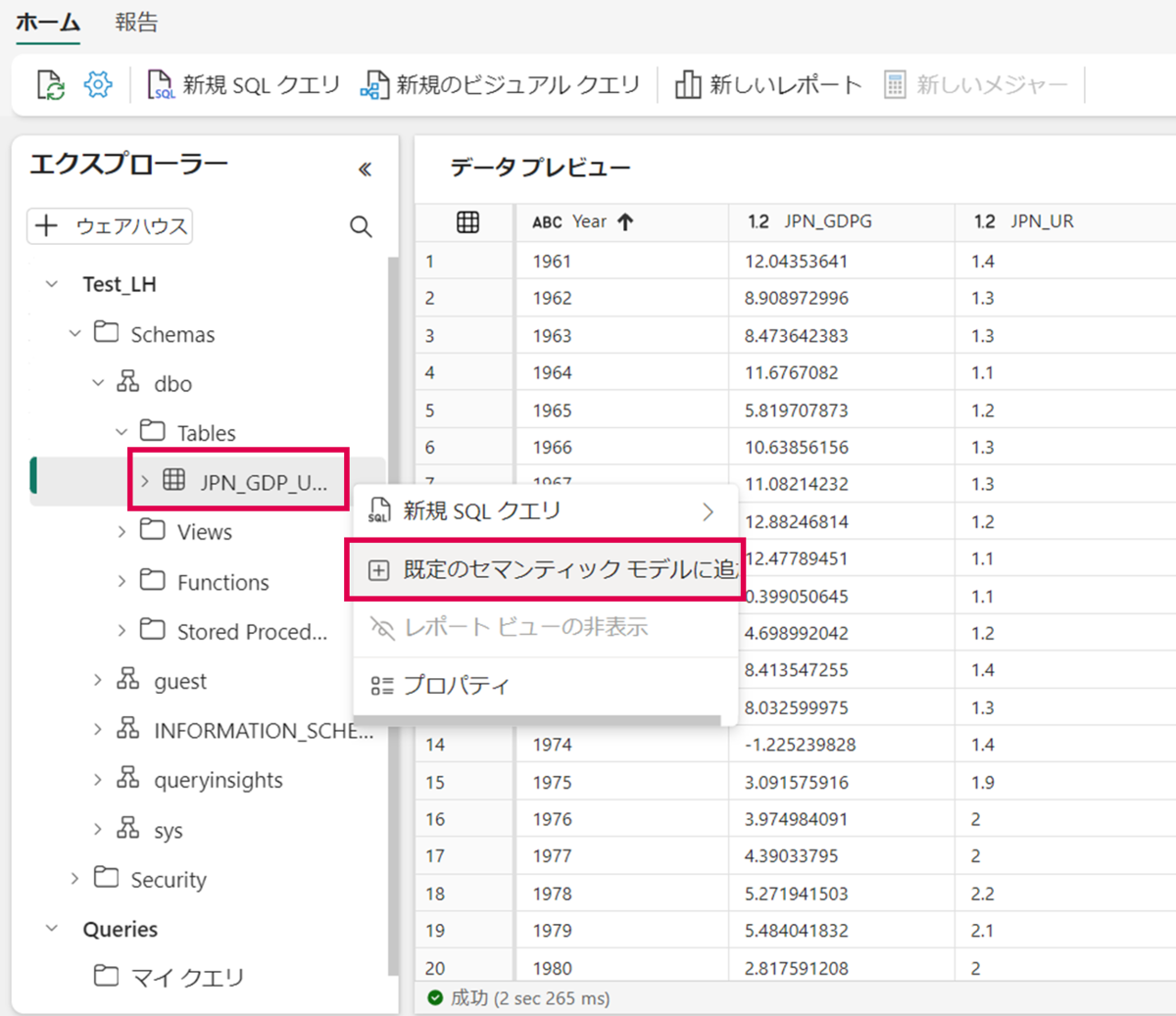
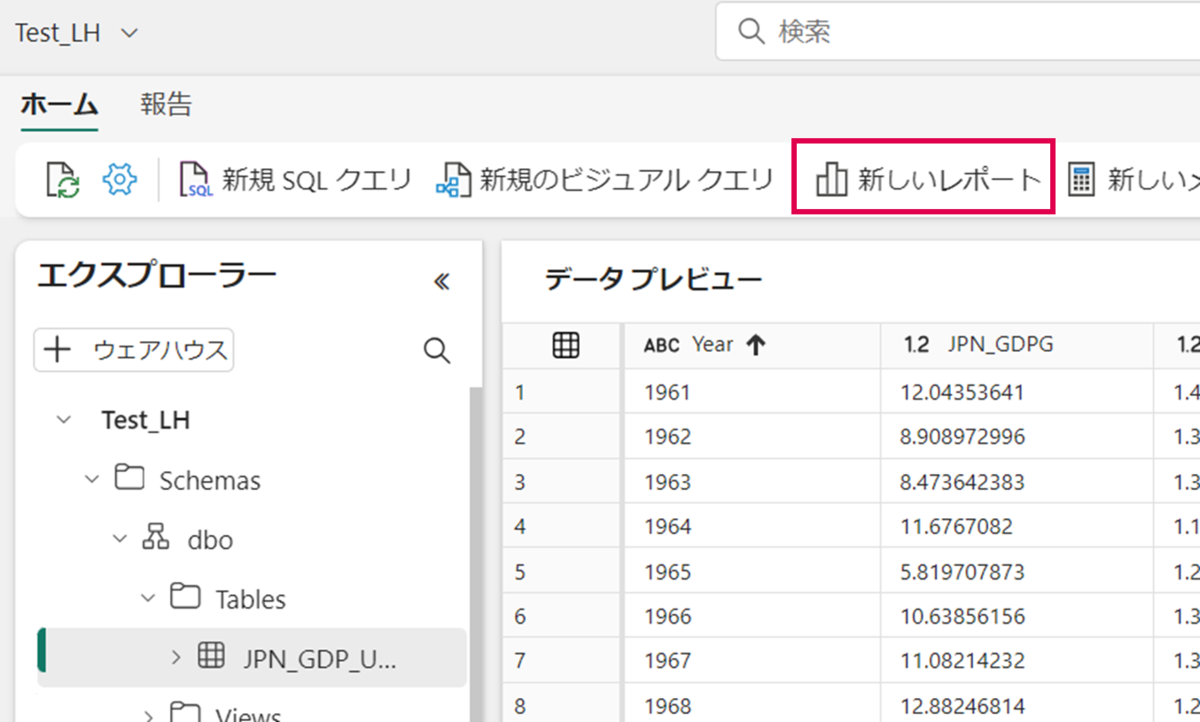
「新しいレポート」を押下します。
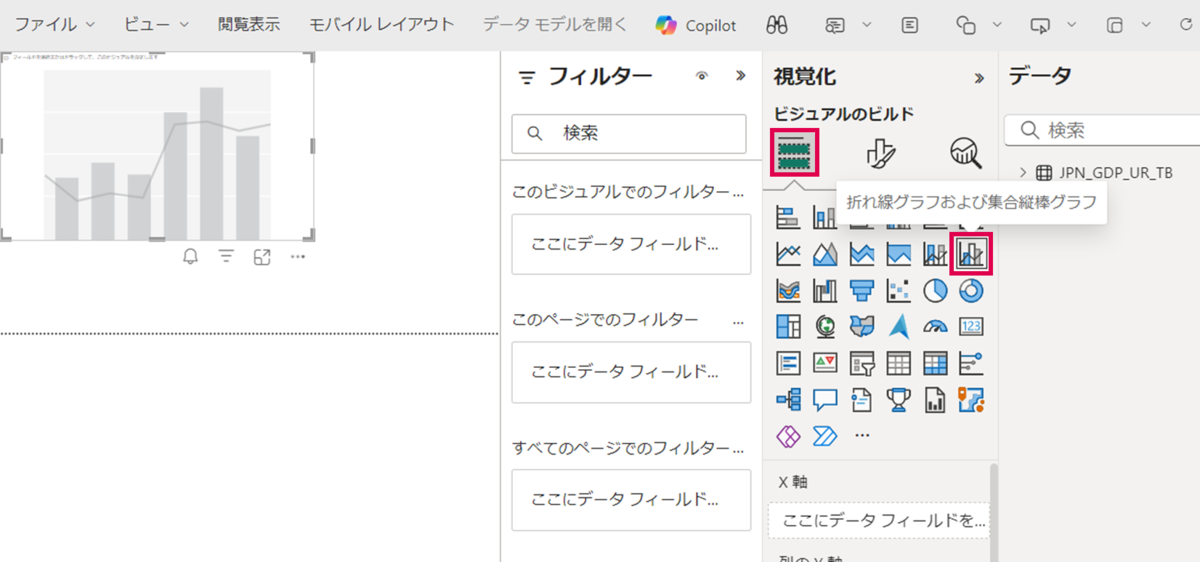
「ビジュアルのビルド」から「折れ線グラフおよび集合縦棒グラフ」を選択します。
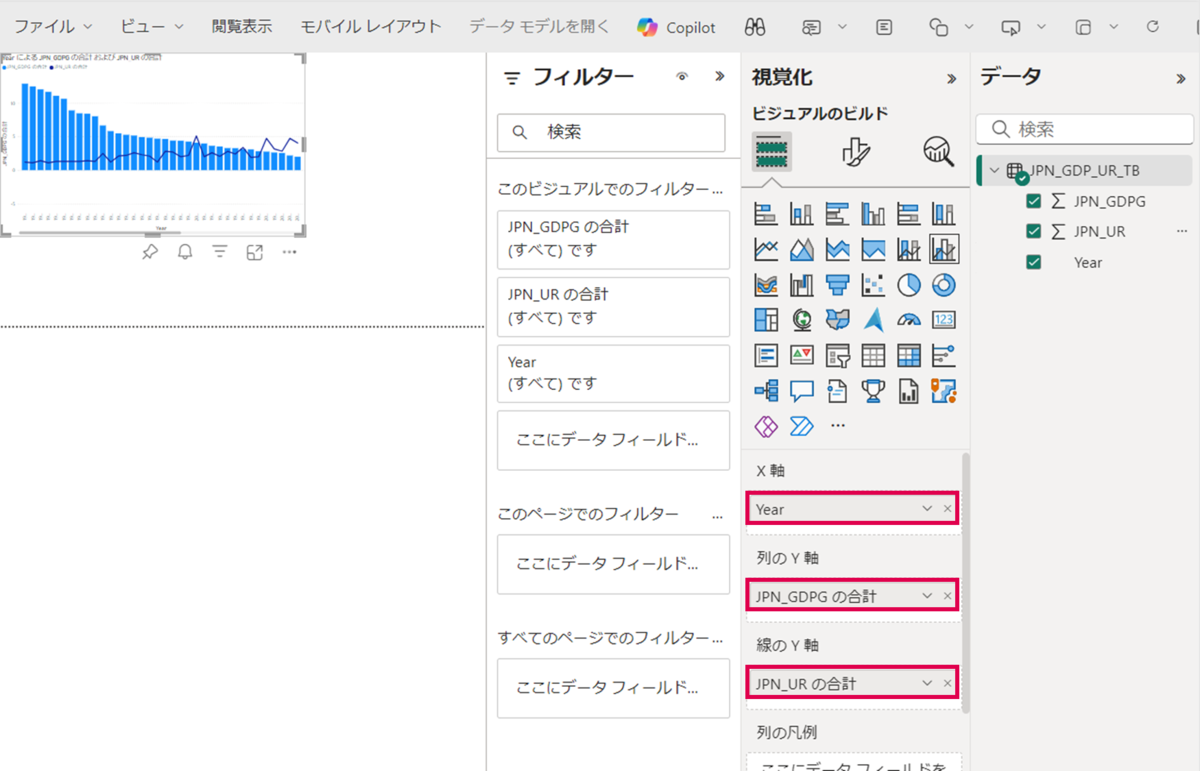
X軸に「Year」、列のY軸に「JPN_GDPG」、線のY軸に「JPN_UR」とします。
※ 設定するとY軸は自動的に「~の合計」となります
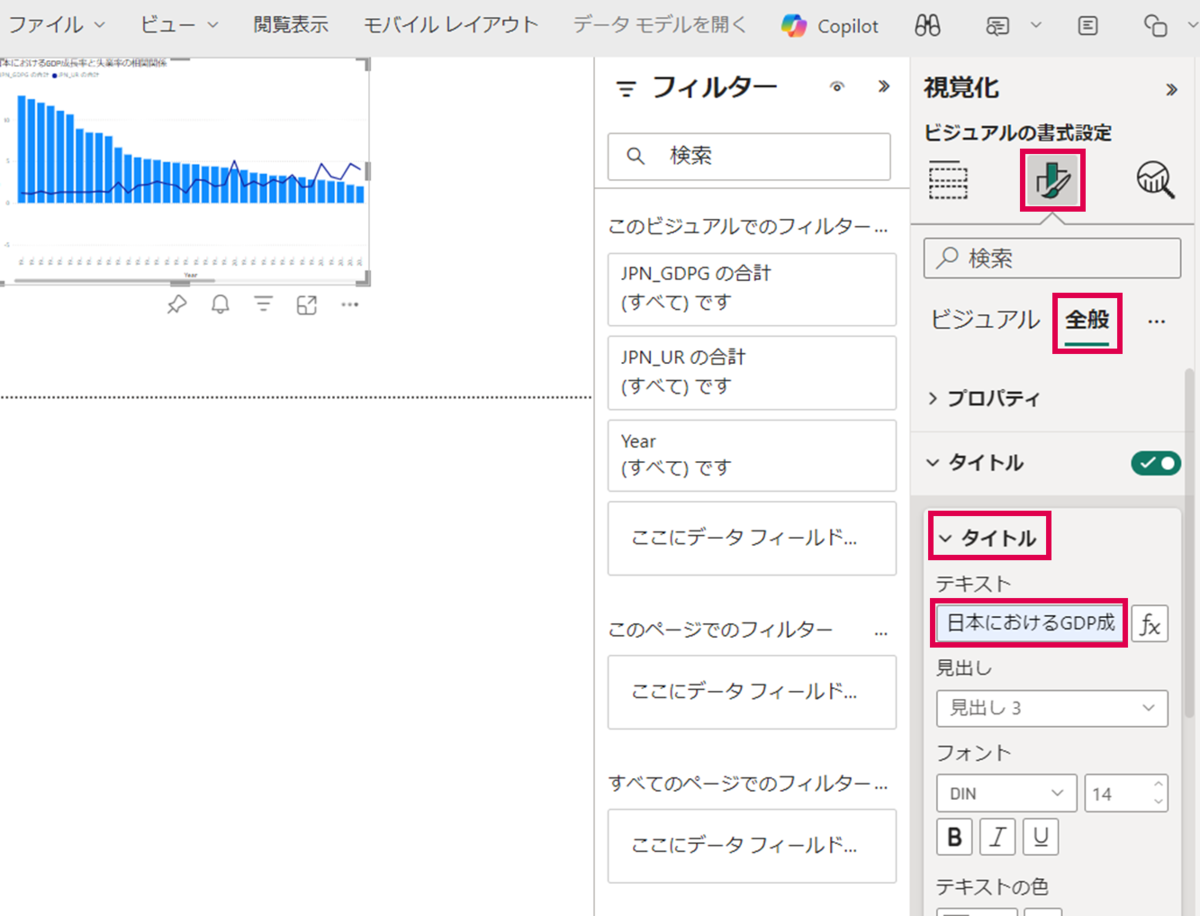
 続いて、グラフタイトルを変更します。「ビジュアルの書式設定」>「全般」>「タイトル」>「テキスト」の順に押下し、任意のテキストを入力します。
続いて、グラフタイトルを変更します。「ビジュアルの書式設定」>「全般」>「タイトル」>「テキスト」の順に押下し、任意のテキストを入力します。
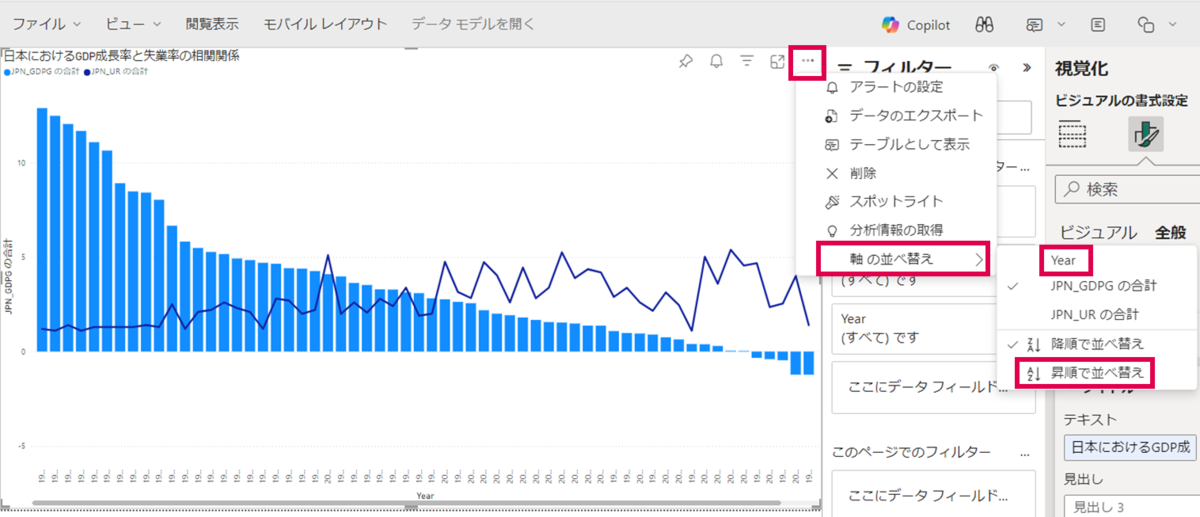
また、データが年代順になっていないため、軸の並べ替えを行います。グラフの「その他のオプション」>「軸の並べ替え」>「Year」>「昇順で並べ替え」の順に押下します。
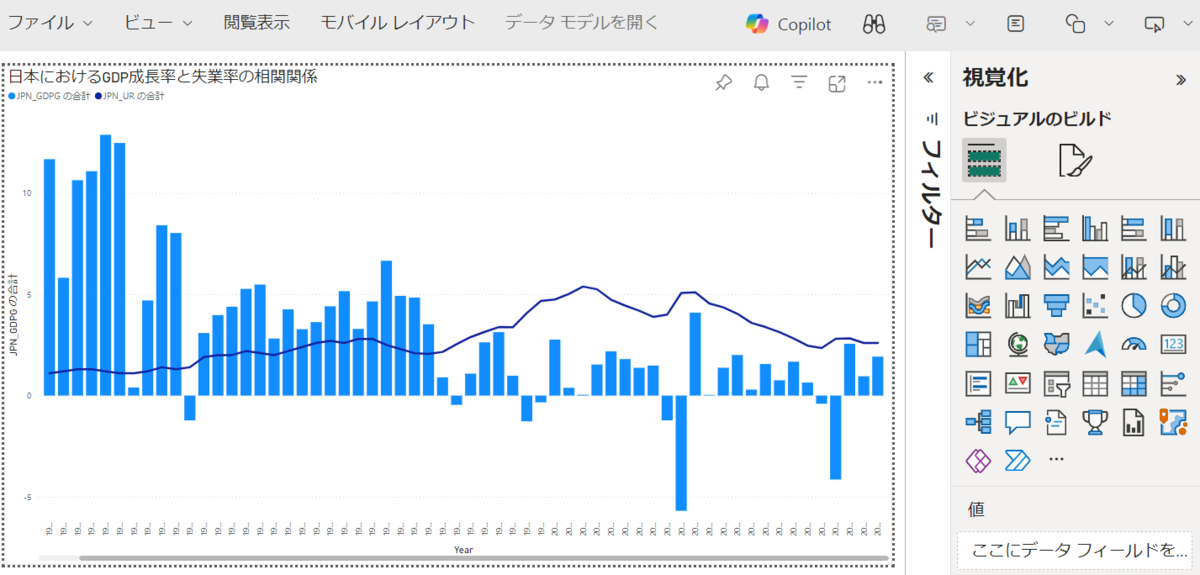
下図のようにレポートが作成され、2つのデータ(GDP成長率と失業率)の相関関係を可視化することができました。
まとめ
Microsoft Fabricを使用した2つのデータを結合し、相関関係を可視化させる手順について紹介しました。
本記事では、簡単なデータ分析の一例として相関関係の可視化を行いましたが、他にもリアルタイム分析や機械学習モデルの構築などもMicrosoft Fabricで行うことが可能です。
目的や用途に合わせて柔軟なデータ活用を行うことができそうです。
