
Microsoft Syntexに、新たなカスタムモデルオプションが追加されました。
追加されたモデルオプションは、既存の「教育方法(Teaching method)」に加わる、「自由形式の選択方法(Freedom selection method)」と「Layout メソッド(Layout method)」の2種類です。
公式ドキュメントによると、それぞれ以下のような分類がされるとのことでした。
- 教育方法 – 非構造化ドキュメント処理モデルを作成します。
- 自由形式の選択方法 – 自由形式のドキュメント処理モデルを作成します。
- Layout メソッド – 構造化ドキュメント処理モデルを作成します。
今回は、追加された2つのモデルオプションのうち、3つめのLayout メソッドを使って、構造化ドキュメント処理モデルを作成してみたいと思います。*1
また、Layout メソッドを使うと、「コレクション」と呼ばれる同系統のドキュメントについて、モデルのトレーニング/抽出が可能となり、2種類以上のドキュメントについても、Layout メソッドモデル1つでカバーできる、とのことでした。*2
よって、今回は、2種類のドキュメントでトレーニングしたLayout メソッドモデルの精度についても、簡単に検証してみたいと思います。*3
前提条件
前提条件については、下記のとおりです。
- 想定ユーザーはSharePoint Online運用担当者とし、「SharePoint Syntex」ライセンスが付与されているものとします。
- SharePoint Online運用担当者は、「グローバル管理者」の役割を付与されているものとします。
モデル準備
ドキュメントサンプル
今回の対象ドキュメントとしては、Microsoft Office公式テンプレートを元に作成した請求書ファイルを使用します。
先述した「コレクション」の条件に該当する同系統のドキュメントの内、モデルのトレーニング対象とするドキュメントは、以下の2種類としました。
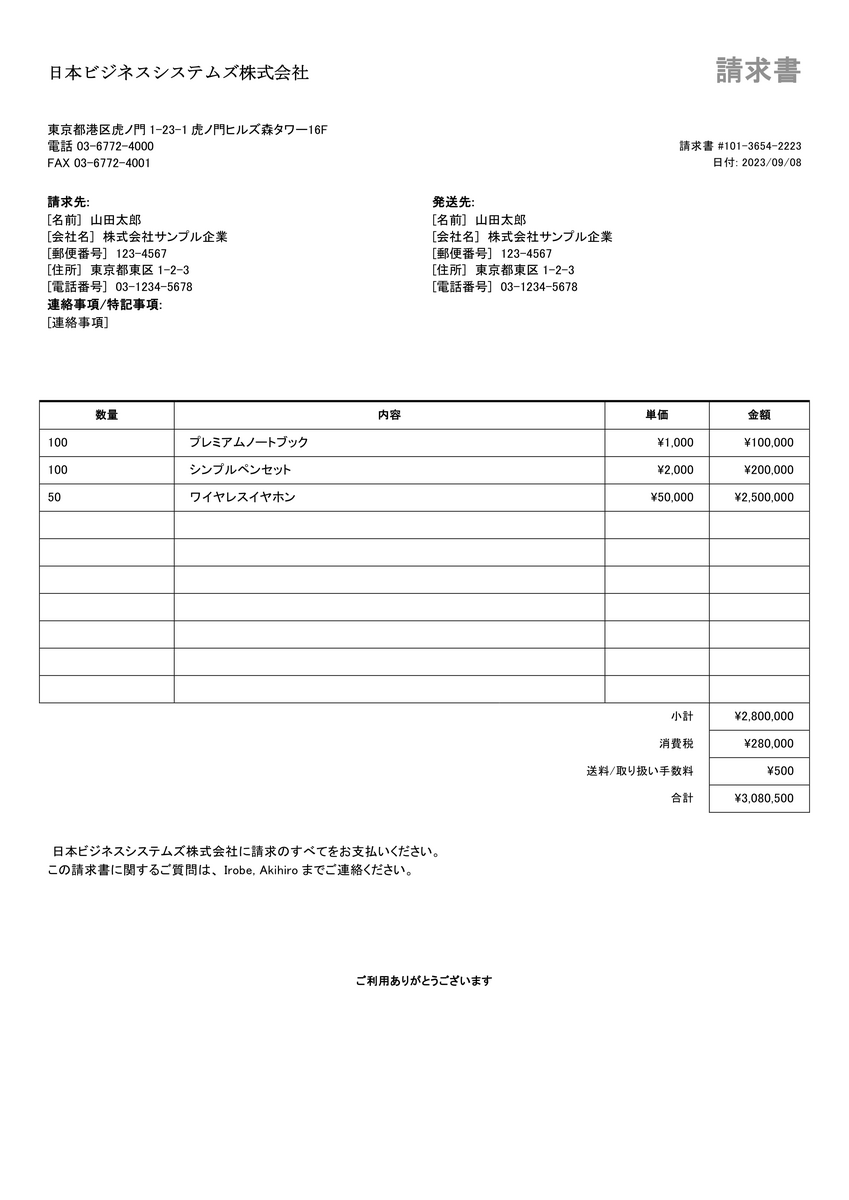

また、モデルのテスト対象は、先ほどモデルのトレーニング対象とした請求書のモノクロの方のドキュメント1種と、以下の2種類としました。
1. 構成は同じだが、言語が英語のドキュメント
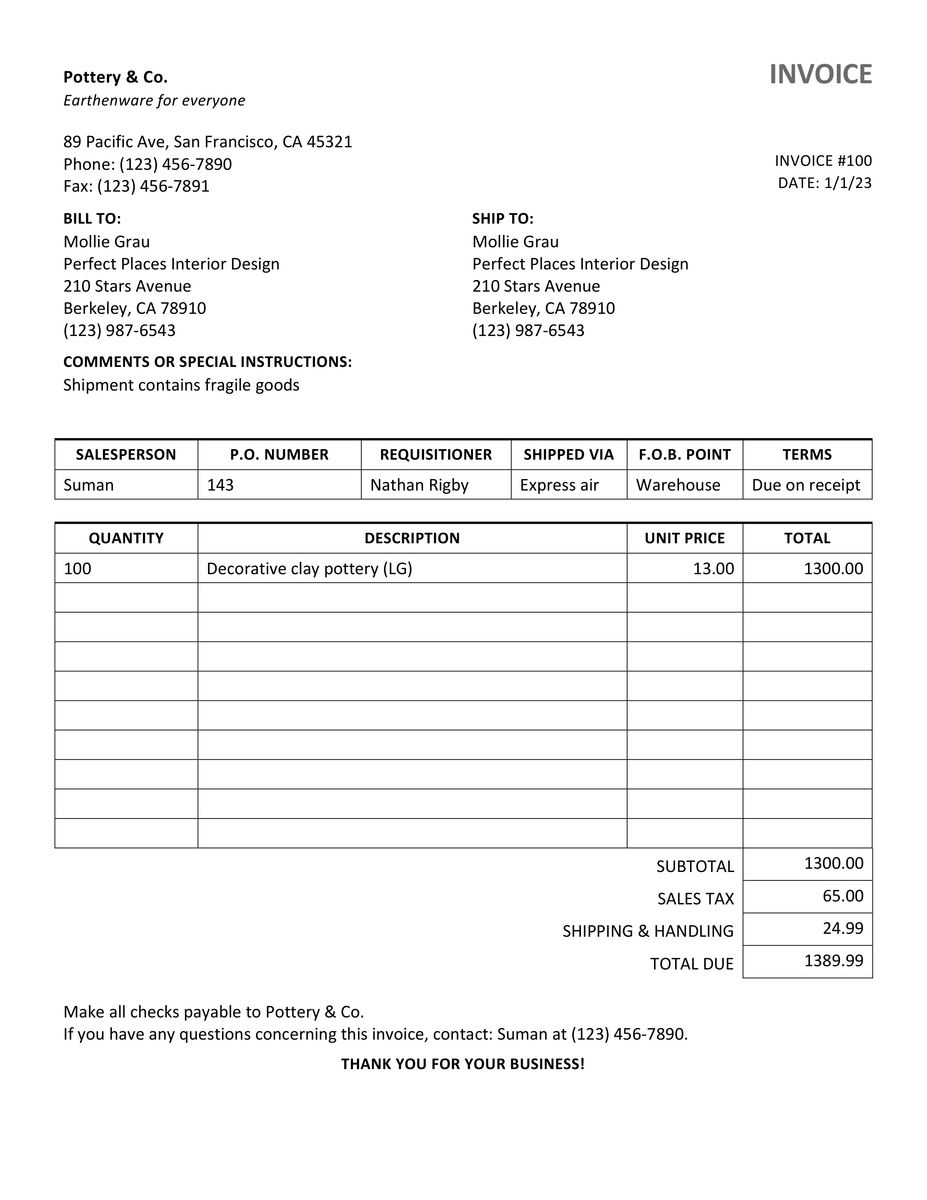
2. 構造はほぼ同じだが、構成が異なるドキュメント

なお、本記事で記載する「構造」と「構成」について、ここでは以下のように定義します。
- 構造:ドキュメントの骨組みのこと
- 構成:ドキュメントの記載項目の配置までを含めたドキュメントの骨組みのこと
モデルの作成
それでは、実際にLayout メソッドを使って、構造化ドキュメント処理モデルを作成してみましょう。
上記の前回記事までと同様、「コンテンツ センター」にアクセスし、画面左上の「+新規」>「モデル」をクリックします。
「モデル作成のオプション」画面で、今回は、「カスタム モデルをトレーニングする」>「レイアウト方法」を選択します。
「レイアウト方法: 詳細」画面では、「次へ」を選択します。
「レイアウト方法でモデルを作成する」画面では、入力必須の「モデル名」と、任意の「説明」を入力後、「作成」をクリックします。
画面が切り替わり、モデルのトレーニング画面に遷移するため、「+Add」を押下します。
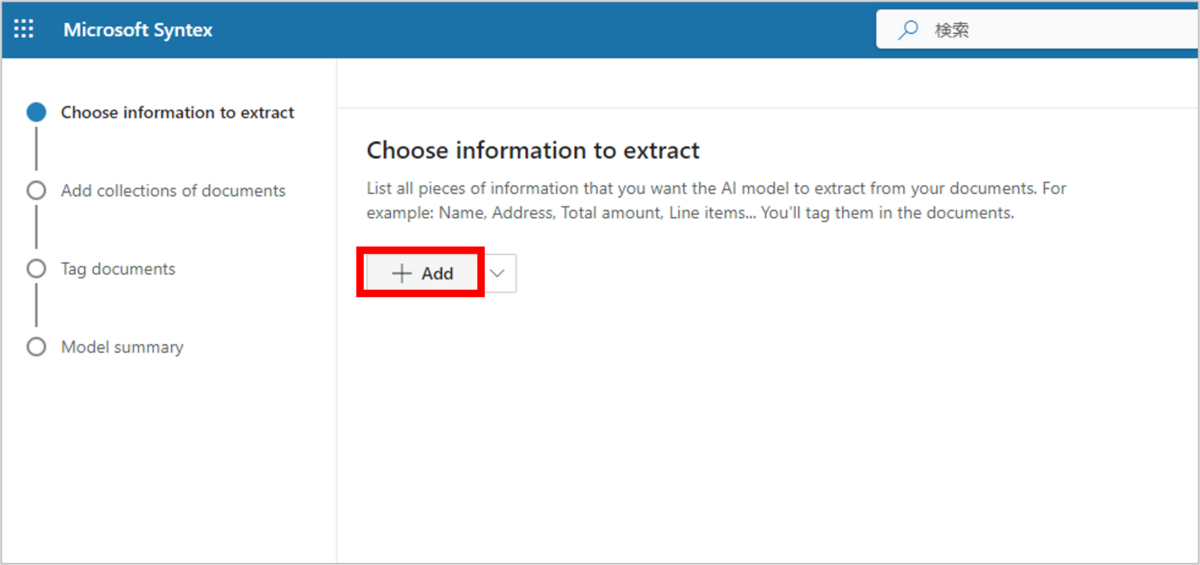
「Add」画面では、識別/抽出対象のフィールドを選択できます。*4
今回は、トレーニングおよびテスト対象の請求書ドキュメント内記載項目のうち、以下の5つを識別/抽出対象とします。
例) 識別/抽出対象 → 以下で入力するフィールド「Name」
- 請求先名前 → Billing name
- 請求先会社名 → Billing company name
- 請求先郵便番号 → Post code
- 請求先住所 → Billing address
- 請求先電話番号 → Telephone number
5項目について、一つずつ追加していきます。
抽出情報の種類を選択する画面から、ドキュメントから数字とテキストを抽出できる「Text field」を選択し、「Next」をクリックします。
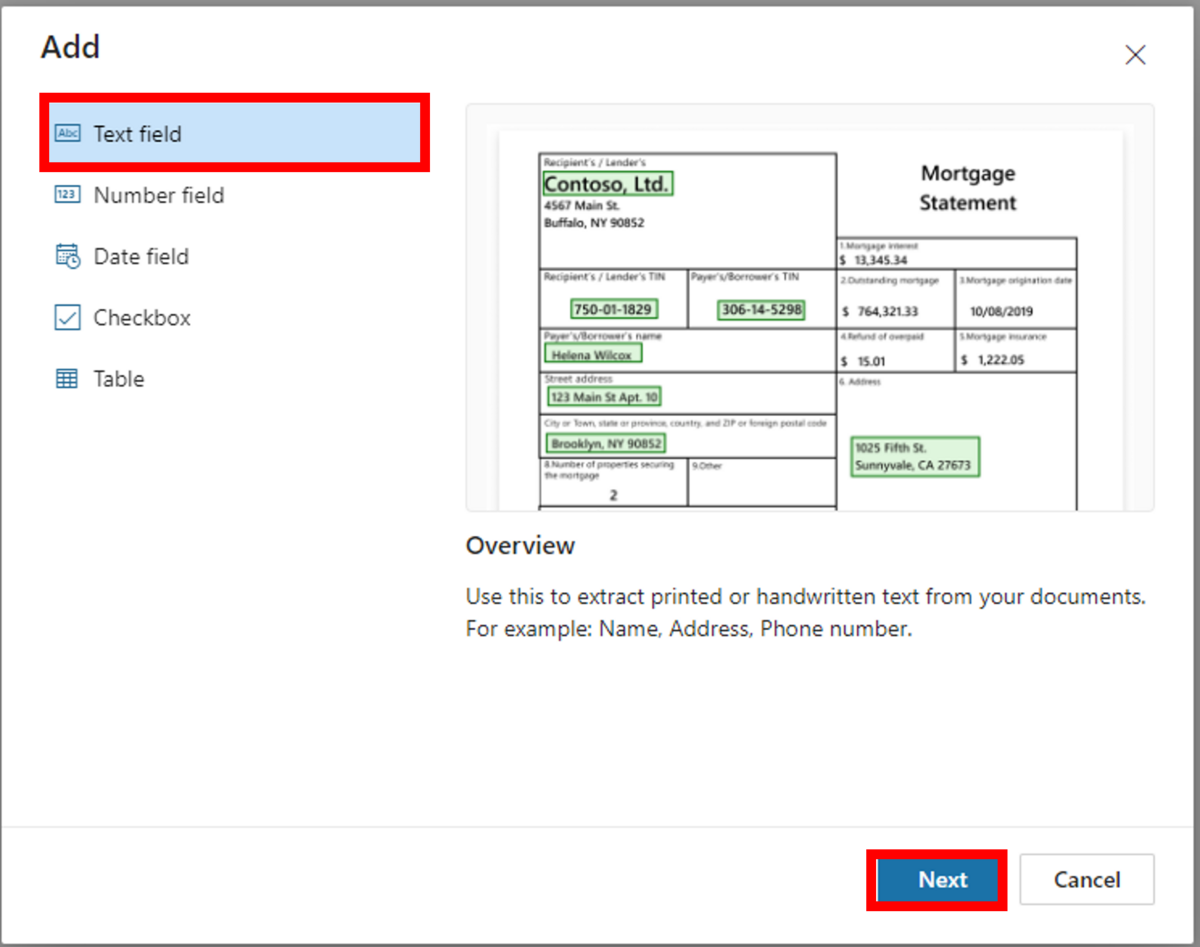
「Text field」画面に遷移したら、入力必須の上記「Name」を入力し、「Done」を押下します。
以下のように、5つの項目について作成が完了したら、「Next」をクリックします。
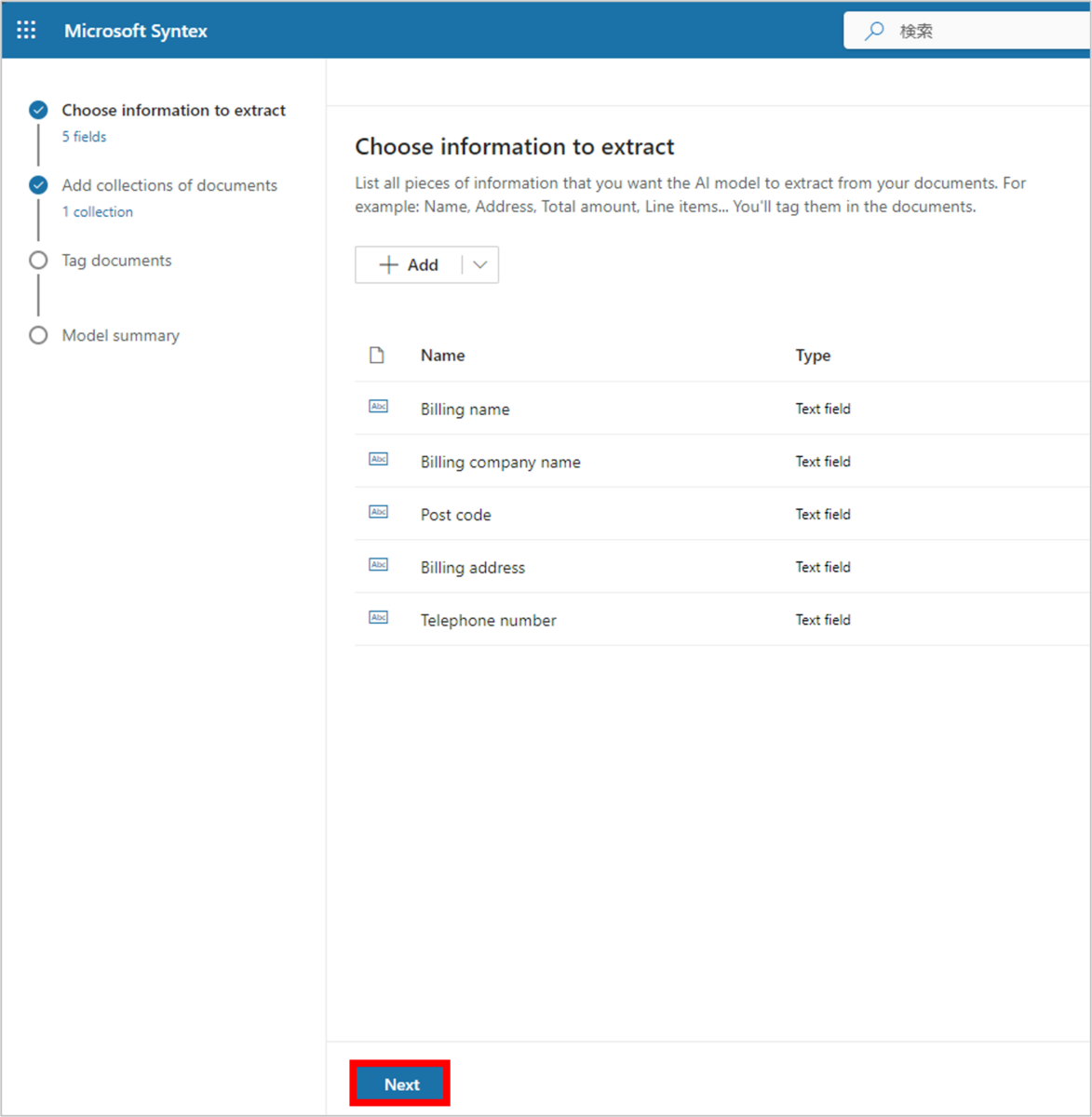
コレクションの追加
次に、先述した「コレクション」に該当するドキュメントを追加していきます。
「New collection」をクリックします。
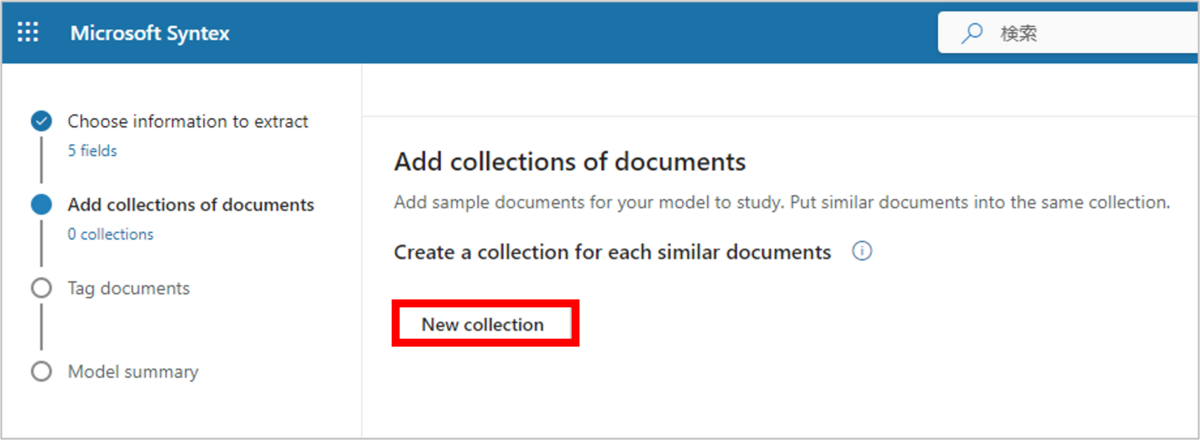
すると、「Collection 1」という新規の「コレクション」が、空の状態で払い出されます。
赤い破線の「+」をクリックし、「Add documents」を選択します。
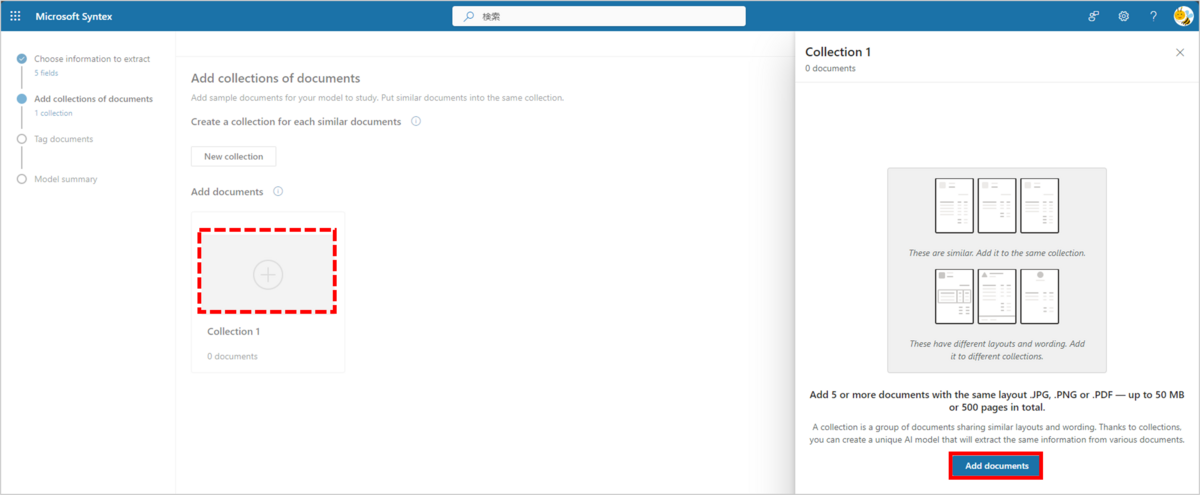
「Select source」画面が表示されるので、トレーニング対象となるドキュメントを、2種類まとめてアップロードします。
今回は、2種類のドキュメントをそれぞれ5ファイルずつ用意しました。
ドキュメントを選択後、「Upload 10 documents」をクリックします。
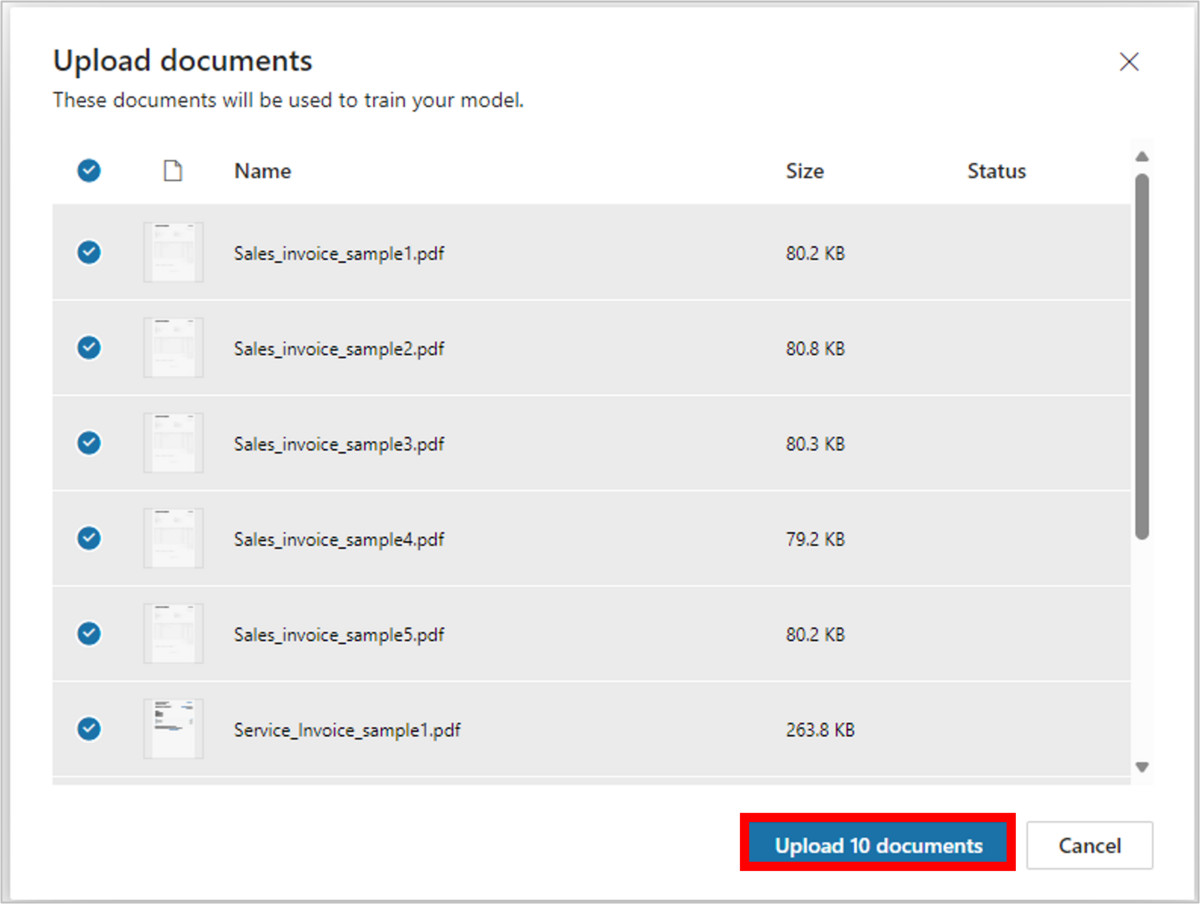
以下のような画面が表示されたら成功です。「Done」を選択します。
モデルのトレーニング画面に戻ってきました。
他の「コレクション」も追加できますが、今回のトレーニング検証については2種類のドキュメントをまとめた「コレクション」で必要十分なので、「Next」をクリックします。
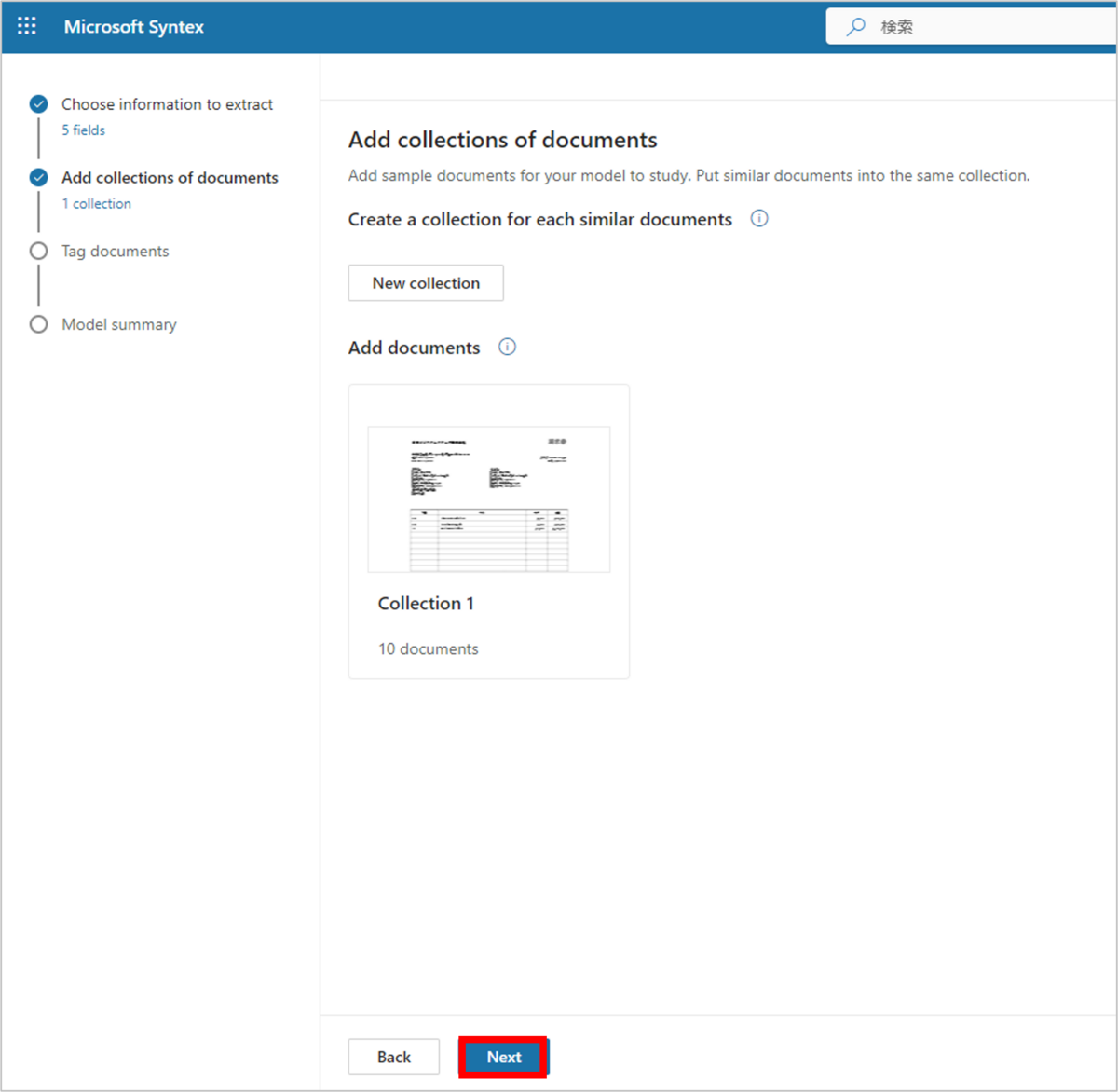
ドキュメントのタグ付け~モデルのトレーニング
続いて、ドキュメントのタグ付けです。
先ほど作成した識別/抽出対象のフィールドに対応するドキュメント内の抽出箇所を青い枠で囲み、対応するフィールドを選択します。
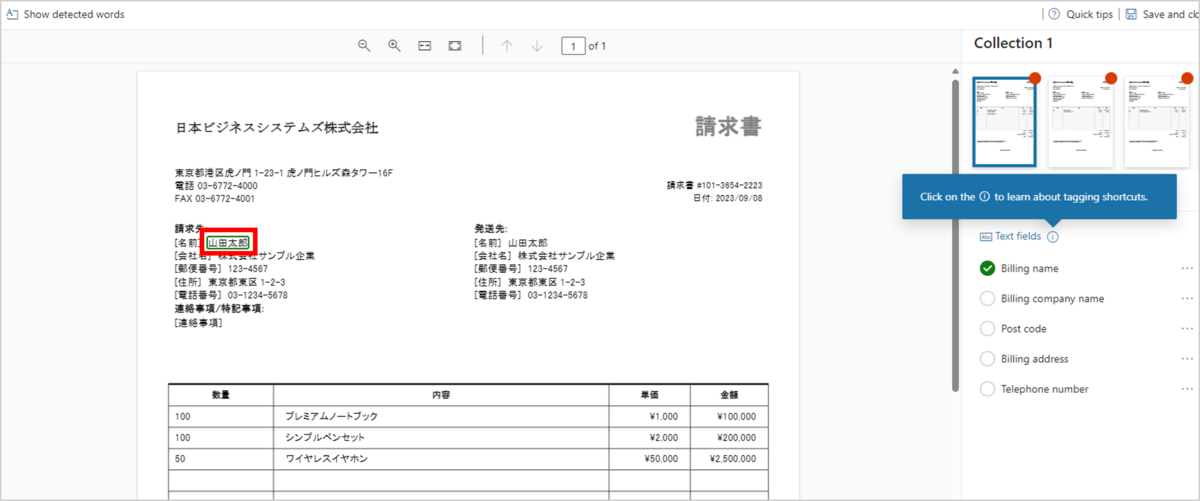
5つの対象フィールド項目すべてでタグ付けが完了すると、画面右側の対象ドキュメントにチェックマークが追加されます。
この作業を、アップロードした10ドキュメントすべてについて実施していきます。

タグ付けがすべてのドキュメントについて完了すると、以下のような画面が表示されます。
「Next」をクリックします。
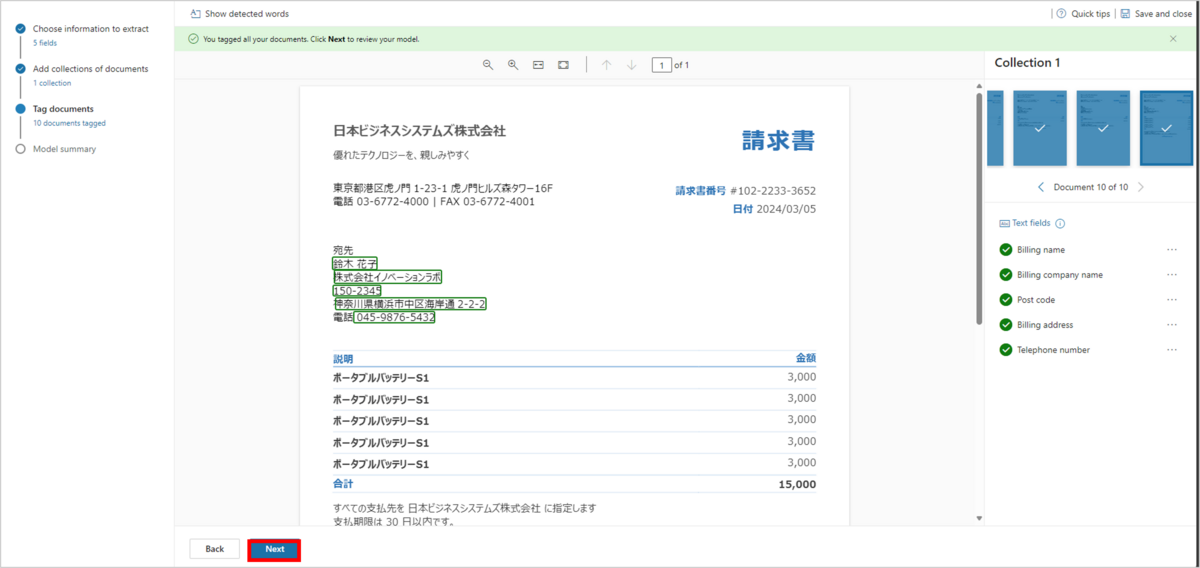
作成したモデルのサマリが表示されます。
問題がなければ、「Train」をクリックして、トレーニングを実行します。
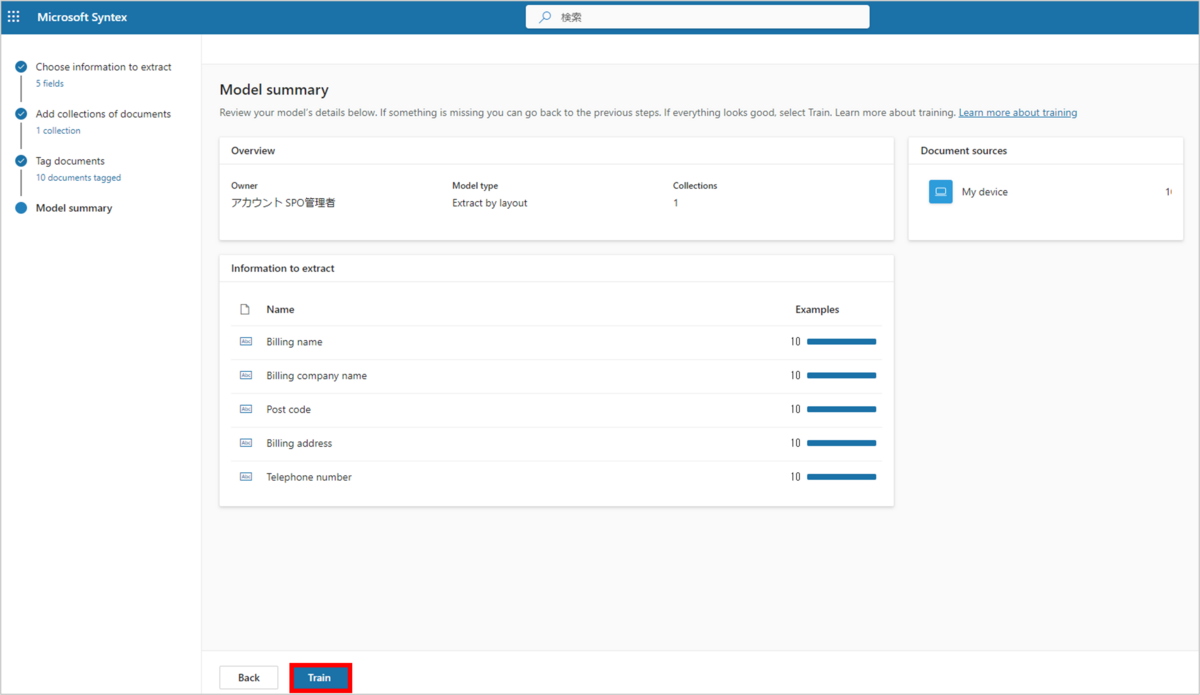
モデルのトレーニングが始まります。
今回のトレーニング量だと、トレーニングは2-3分で完了しました。
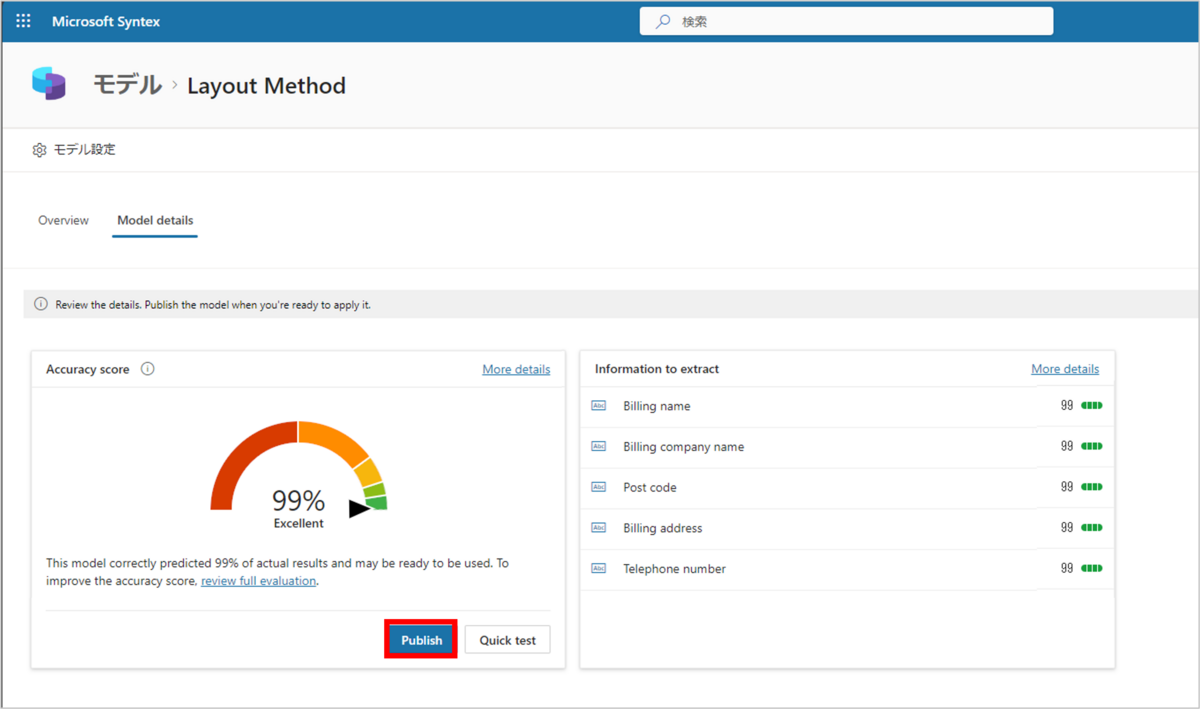
トレーニング結果は以下のようになりました。
「Publish」をクリックすると、モデルが発行されます。
モデル実行
適用
モデルの発行が完了すると、モデルの適用先ドキュメントライブラリが求められます。
今回は、新規で作成したドキュメントライブラリを指定し、「追加する」を選択します。*5
作成したモデルが、ドキュメントライブラリに適用されました。
ライブラリに移動してみます。

対象のドキュメントライブラリに移動すると、作成したモデル名のビューの画面が表示され、モデル内で作成した「コレクション」列、識別/抽出対象のフィールド列がビューで表示されるように追加されていることが分かります。
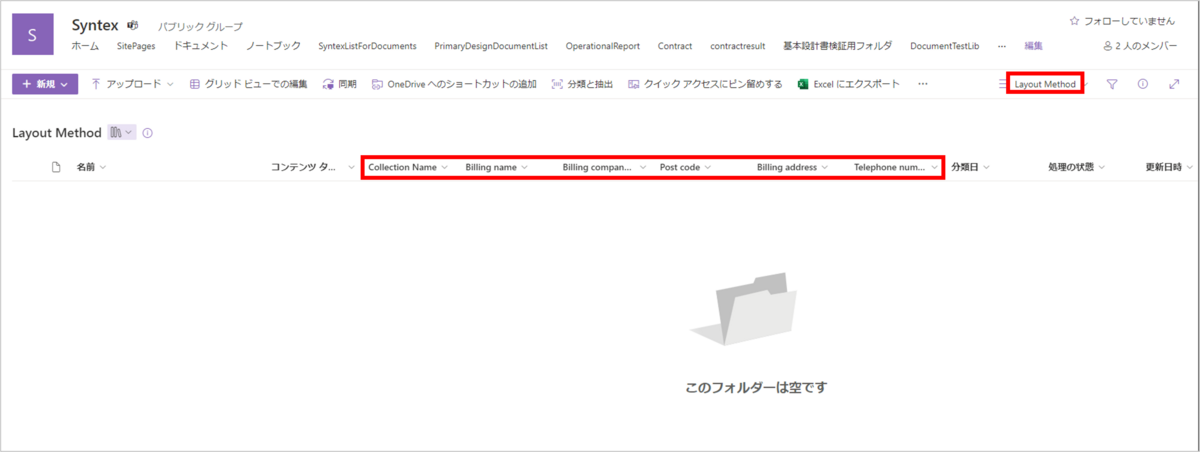
検証
モデルの適用まで完了しました。
ここでは、作成したモデルの精度がどれほどのものなのか、「モデル準備」>「ドキュメントサンプル」で提示した以下3種類のドキュメントに対して、抽出精度を確認してみたいと思います。
- トレーニングしたドキュメントと同じ構造・構成のドキュメント
- 構成は同じだが、言語が英語のドキュメント
- 構造はほぼ同じだが、構成が異なるドキュメント
ドキュメントをアップロードした後、ドキュメントを選択した状態で、「分類と抽出」をクリックします。
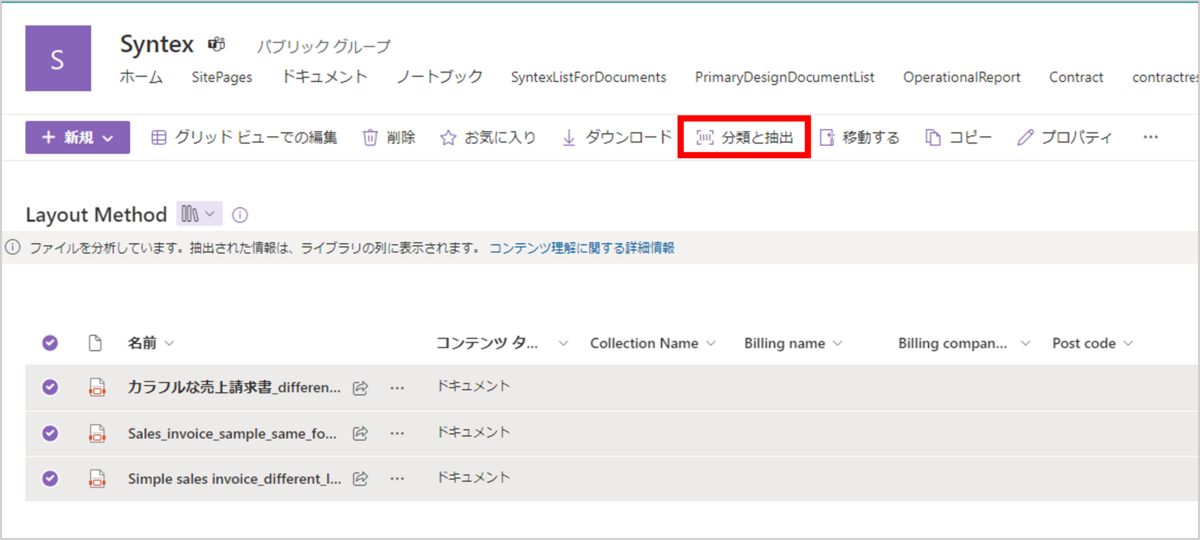
「処理の状態」列が「進行中」となるので、処理が完了するまで待ちます。
3ファイルだと、処理はだいたい3分くらいで完了しました。
モデルの抽出結果は、以下のようになりました。
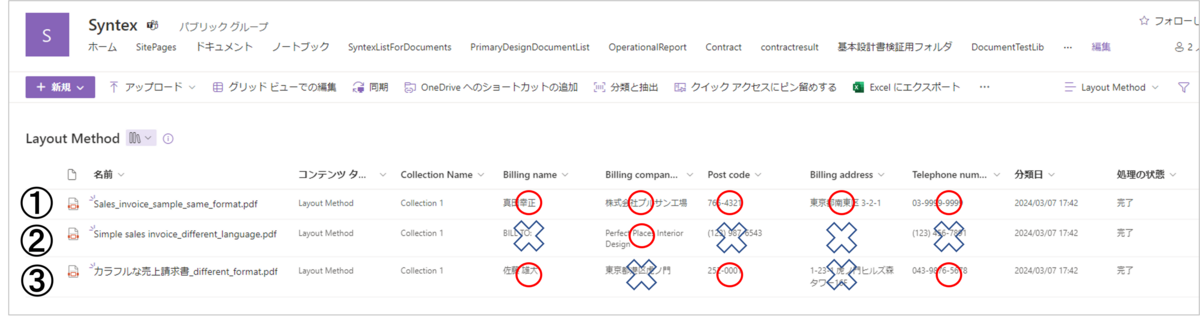
1. トレーニングしたドキュメントと同じ構造・構成のドキュメント
→5項目中5項目すべてが正確に抽出できており、100%正確に抽出できていることが確認できました。
2. 構成は同じだが、言語が英語のドキュメント
→5項目中1項目のみ正確に抽出できていたので、20%程度の精度となりました。
やはり、ドキュメント内の言語がトレーニング時と異なる場合は、構成が同じであっても、項目を識別して抽出することが難しいようです。
よって、構成が同じであっても、アップロードするドキュメントの言語を対象としたトレーニングが追加で必要となりそうです。
3. 構造はほぼ同じだが、構成が異なるドキュメント
→5項目中3項目が正確に抽出できていたので、60%程度の精度となりました。
2項目については間違って抽出していますが、トレーニングするドキュメントの量や「コレクション」の種類を増やすことで、構成がやや異なるドキュメントについても、抽出精度の改善は期待できそうです。
おわりに
今回は、従来Power AppsやPower Automateで使われていたモデルのオプションであり、Microsoft Syntexのカスタムモデルの作成オプションに最近追加されたLayout メソッドを使って、カスタムモデルの作成と精度の検証を行いました。
簡単な検証に済ませてしまったため、精度向上に向けた検証の深堀りができていないことは悔やまれますが、改善策としては、以下のようなものが考えられます。
- 識別/抽出対象のフィールド列を、オールアラウンダーな「Text field」でなく、該当する種類に合わせる形で作成する。
- 1つの「コレクション」の内で、類似するドキュメントの種類を増やして、モデルのトレーニングを行う。
- 「コレクション」内の類似するドキュメントの種類は2-3種類にとどめて、複数作成した「コレクション」を含むモデルとして、トレーニングを行う。
また、構成が異なるドキュメントについては、特に日本語の抽出対象で間違って抽出しているケースが多く散見されたため、今後の多言語対応アップデートに期待したいと思います。
*1:「自由形式の選択方法」が英語のみ対応のため。
*2:なお、「同系統」という言葉は曖昧なので、「構造」と「構成」と「言語」の3点いずれかで共通しているドキュメントを、ここでは「同系統のドキュメント」として定義したいと思います。特に「構造」と「構成」の定義については、「ドキュメントサンプル」の箇所で記載しています。
*3:なお、本来のLayoutメソッドは、フィールドやテーブルから情報を抽出することで精度を最大限発揮できるとのことですが、本検証では、実際に使用されるケースの多いテーブルなしの請求書情報を検証対象としています。
*4:「識別/抽出対象のフィールド」は、「抽出器」と同義です。
*5:詳細設定については、既定のままで問題ないです。

色部 晟洋(日本ビジネスシステムズ株式会社)
SharePoint Onlineサイト構築・Microsoft365移行等でプリセールス・PMを経験後、AI等の先端技術を扱う部門に異動。好きな映画は『風立ちぬ』です。
担当記事一覧