
概要
Azure Machine Learningでは学習やテストに使用するデータをワークスペース上に登録して保管・共有することができます。
登録設定の際にいくつか選択肢が出てくるため、本記事で解説を行います。
本記事の内容は2023年1月時点の内容で記載しており、今後のアップデートで機能が追加される可能性があります。
リファレンス
参考にした公式リファレンスの記事です。
V2のデータセット learn.microsoft.com
V1のデータセット learn.microsoft.com
V2とV1のデータセット互換性 learn.microsoft.com
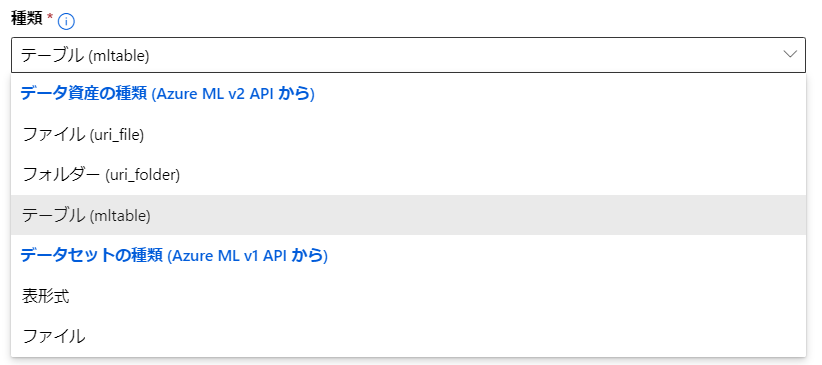
Azure Machine Learningデータセット種別
Azure Machine Learningワークスペースにデータを登録する際には複数の方法が用意されています。
- v2
- ファイル(uri_file)
- フォルダー(uri_folder)
- テーブル(MLTable)
- v1
- 表形式(Tabular)
- ファイル(File Dataset)
登録されたこれらの資産を使用して機械学習を行います。
注意点として、v2のSDKもしくはCLIからは全てのデータセットを使用することができますが、v1の機能からv2データセットを使用することができない点は覚えておく必要があります。
特にv1のSDKなどを使用する場合、v2で登録したデータセットが使用できないため注意してください。
Azure Machine Learningワークスペースの「データのラベル付け」機能ではv1形式のデータセットのみをサポートしています。

uri_file & uri_folder(v2)
主に登録したデータをPythonスクリプト上で読み込んで取り扱う、独自の解析処理を想定した登録方法です。 csvなど生の表形式のファイルや.jpgなどの画像ファイルを指定することができます。
以下の形式でアップロードが可能です。
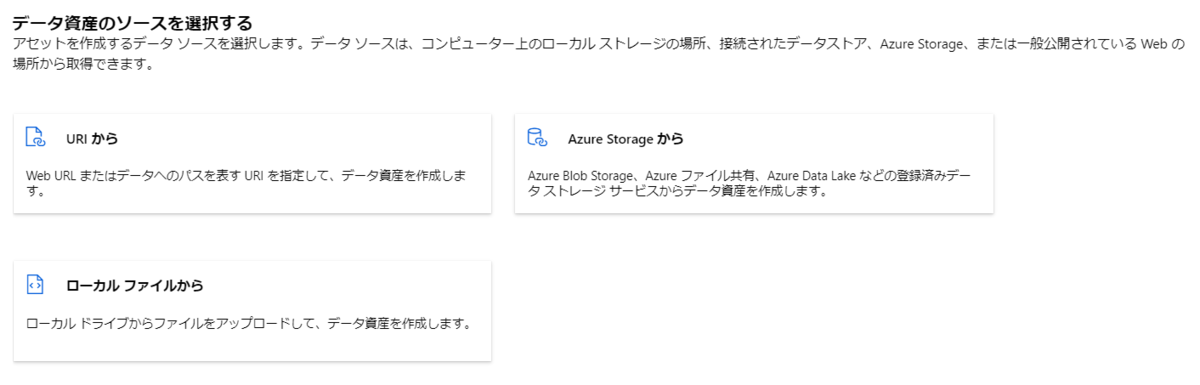
uriはUniform Resource Identifier、リソースを識別するための文字列の略称です。
アップロードもしくはデータへの参照を登録することで、ワークスペース上からデータセットにアクセスすることができるようになります。
ローカルファイルを選択するとAzure Machine Learningマネージドなストレージアカウントにアップロードされます。
画像など複数ファイルを扱う場合は、外部ストレージアカウントに専用のコンテナを作成してワークスペースとの接続を作成しておけば、コンテナ内のファイルを一括で1つのデータセットとして登録できます。
その他HTTPでファイルの場所を指定可能です。
learn.microsoft.com
uri_fileはcsvなどの単一のファイルで、uri_folderはフォルダ(複数のファイル)に対応します。
ただしuri_fileでもストレージパスで正規表現を入力した場合は、複数のファイルを対象にできることがあります。例えば*と入力するとコンテナ内の全てのファイルとなり、.jpgなどと入力するとjpgファイルのみを対象にすることができます。
筆者はこれまでに、生のcsvやjsonファイルを保存・読み出しを行ったり、Blob Storageのコンテナを対象に画像データを読み込む際に使用しました。
正規表現でパスを入力する場合、ストレージアカウントに画像が追加されると自動で登録済みデータセットにも画像が追加されるため、非常に便利です。
MLTable形式(v2)
詳細
テーブル形式で、厳密にスキーマを定義した形で読み込む必要がある場合のデータセットです。
データ追加が頻繁に行われたり、AutoMLで学習を行わせる際などにはデータセットをMLTable形式として登録する必要があります。
MLTable形式を定義できるのは以下のファイルに限られます。
- 区切りファイル (.csv、.tsv、.txt)
- Parquet (.parquet)
- JSON Lines (.json)
- Delta Lake (Data Lake Strage Gen2への参照)
MLTable定義ファイル
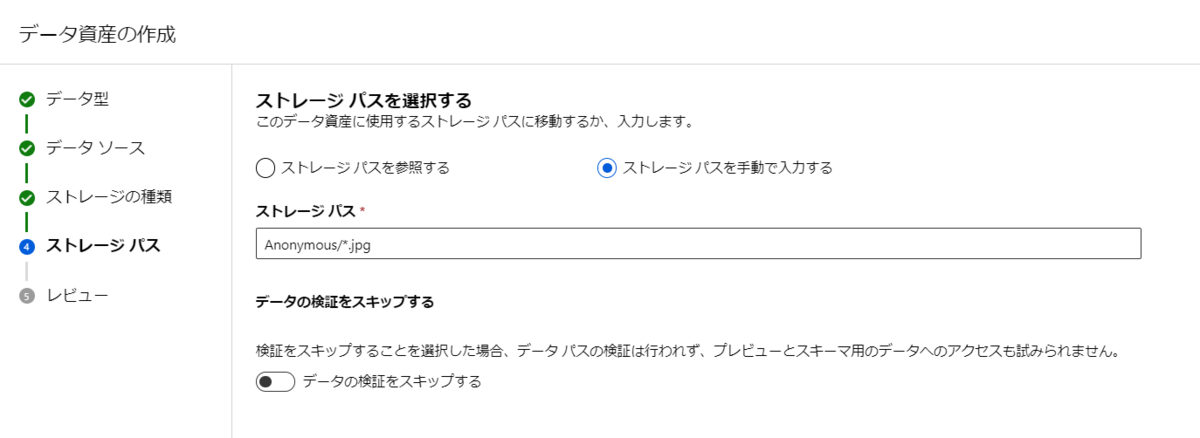
ブラウザからワークスペースを操作して、アップロードする形でMLTableを定義する場合には、選択肢さえ選んでおけばこの形式で登録ができます。
ですが例えばCLIv2などからデータセットを登録する場合や、パイプライン上のモジュールからAutoMLを用いて訓練する場合などには、この定義ファイルを自分で用意する必要があります。
例えば学習用データをCLIv2から登録する場合は以下の構造でファイルを用意します。
ディレクトリ構造
┣ register_dataset.yml
┗ data
┣ MLTable
┗ train_data.csv
MLTable(拡張子なしファイル)を作成して、以下のように内容を記載します。
data/MLTable
type: mltable
paths:
- file: ./train_data.csv
transformations:
- read_delimited:
delimiter: ','
encoding: ascii
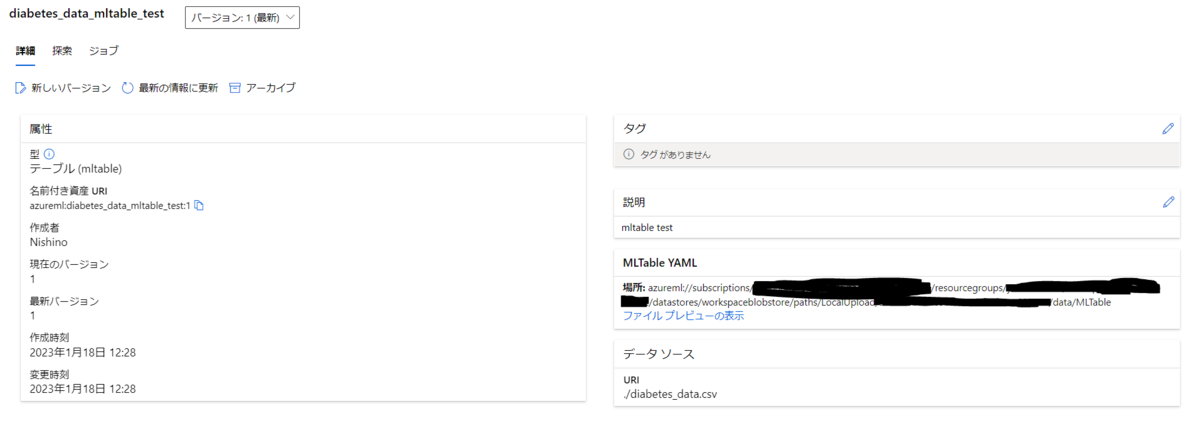
試しに今回はsklearnのDiabetes DatasetをMLTable形式で登録してみます。
データは以下のコードでダウンロードできます。
from sklearn import datasets diabetes = datasets.load_diabetes() X = diabetes.data y = diabetes.target Y = np.array([y]).transpose() d = np.concatenate((X, Y), axis=1) cols = ['age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6', 'progression'] data = pd.DataFrame(d, columns=cols) data.to_csv("data/train_data.csv", index=False)
データセットを登録するためのyamlファイルを用意します。
nameにデータセット機能に登録する名称を入力します。
register_dataset.yml
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json type: mltable name: <name_of_data> description: <description goes here> path: ./data/
全てのファイルが揃ったところでaz mlコマンドを実行します。
!az ml data create --file register_dataset.yml
登録されたデータセットの型がMLTable形式になっています。
探索タブで確認すると、表形式のプレビューが表示されます。
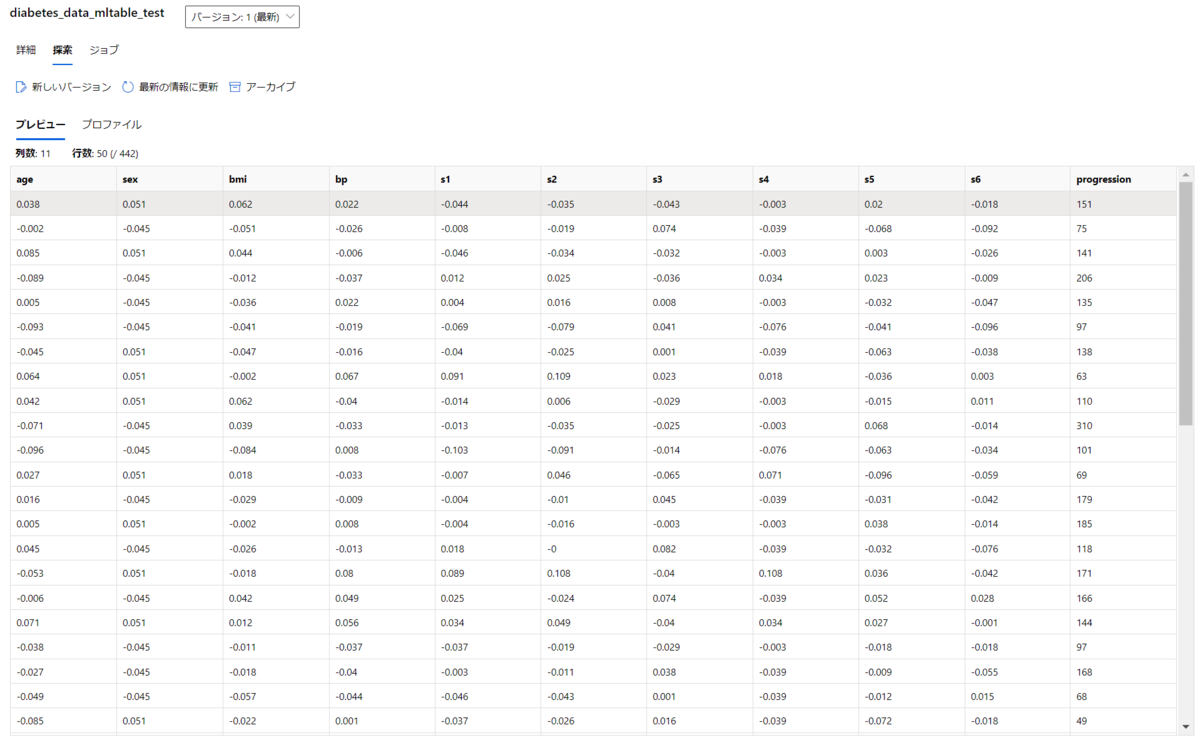
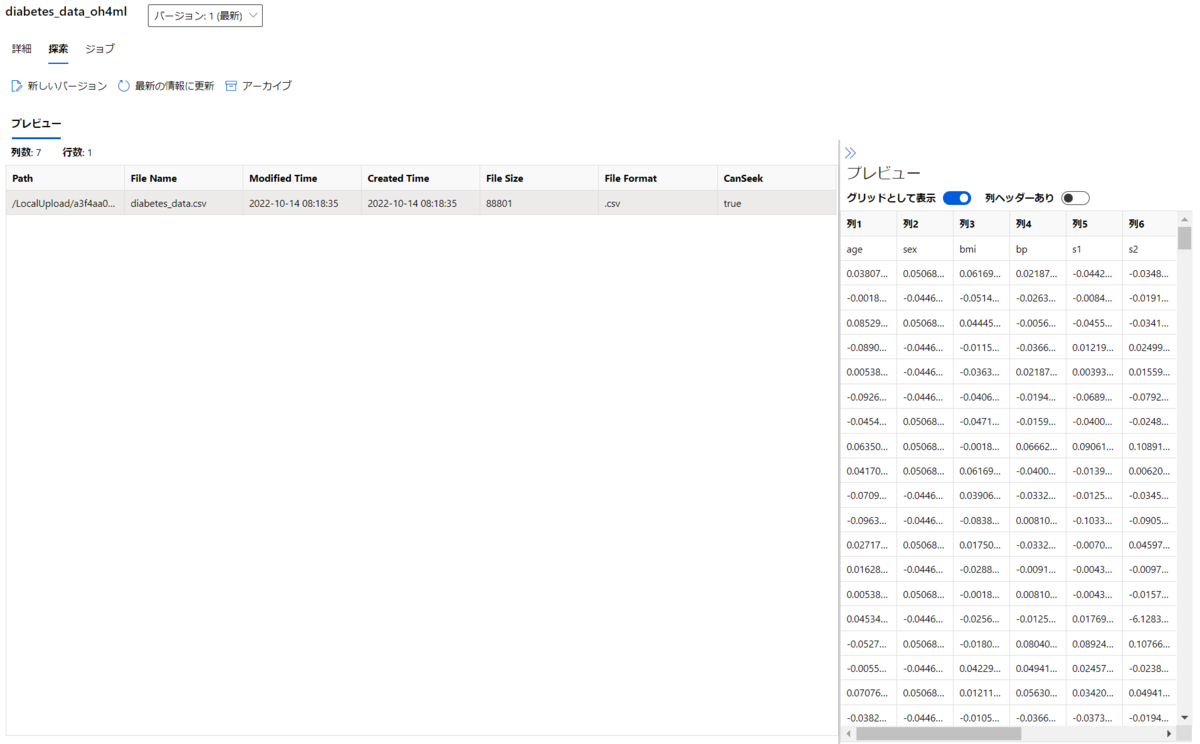
同じファイルをuri_file形式で登録した場合のプレビューは以下の通りです。
単一ファイルとして認識されているためパスやファイル名などが表示されています。右のプレビューでもファイル区切りは維持されていますが、列名などが認識されていないことが分かります。
Tabular Dataset (v1)
旧バージョンで表形式のデータセットを定義することができます。
v1系をSDKを通して登録する方法については、v1を使用する必要があります。以下のリファレンスを参照してください。
learn.microsoft.com
現時点ではSQL Databaseに接続するケースではv2ではなく本機能を使用する必要があります。
また「データのラベル付け」で作成した画像データセットもv1 Tabluar Dataset形式でアウトプットされます。
File Dataset (v1)
旧バージョンでファイル形式のデータセットを定義します。
ファイルという名前ですがv2のuri_folderと同じくフォルダ形式の定義で、作成後にはFolder(uri_folder)と表示されます。
こちらも画像データセットなど表形式以外のデータに使用します。

結論
2023年1月時点では以下の使い分けで運用しています。
- テーブルデータ
- v2のuri_fileもしくはMLTableで登録する
- AutoMLでデータを使用する場合はv2の MLTableで登録する
- SQL Databaseに接続する場合はv1のTabular Datasetで登録する
- データのラベル付けを使用する場合はv1のTabular Datasetで登録する
- 画像データ
- BLOBストレージにデータを格納してv2のuri_folderで登録する
- データのラベル付けを使用する場合はv1のFile Datasetで登録する
おわりに
Azure Machine Learning に登録できるデータセットには多くの種類があり、迷う場面も出てくるかと思います。
本記事が皆様の参考になれば幸いです。
