
概要
本記事はAzure Machine LearningワークスペースをCLIv2を使って操作するチュートリアルの第2弾です。
使い方を習得すれば自動化パイプラインを自身で構築できるようになります。
やりたいこと
前回の記事でAzure Machine Learningのリソースを使って学習を実行ところまで進みました。
この段階では作成したモデルをローカル環境でしか使用することができません。公開する際には、推論エンドポイントをデプロイする必要があります。
本記事では引き続きCLIv2を使用し、Azure Machine Learningのマネージドな推論エンドポイントをデプロイする方法を紹介します。
準備
入門編1の記事をご参照ください。
こちらが完了している前提でエンドポイントのデプロイを進めていきます。
Azure CLI 拡張機能(CLIv2)による推論エンドポイントのデプロイ
学習済みモデルの登録
モデルのダウンロード
前回の手順で学習済みモデルがAzure Machine Learning上に保管されましたが、あくまでジョブとして管理されているためにモデルのバージョン管理なども行えておらず、容易に使用することができません。
モデルとして登録するため、まずは登録したジョブからモデルのみをダウンロードします。
ダウンロードに必要なjob_nameは前回「az ml job create」を実行した際の返り値のdisplay_name、またはワークスペースの実験画面から確認できます。
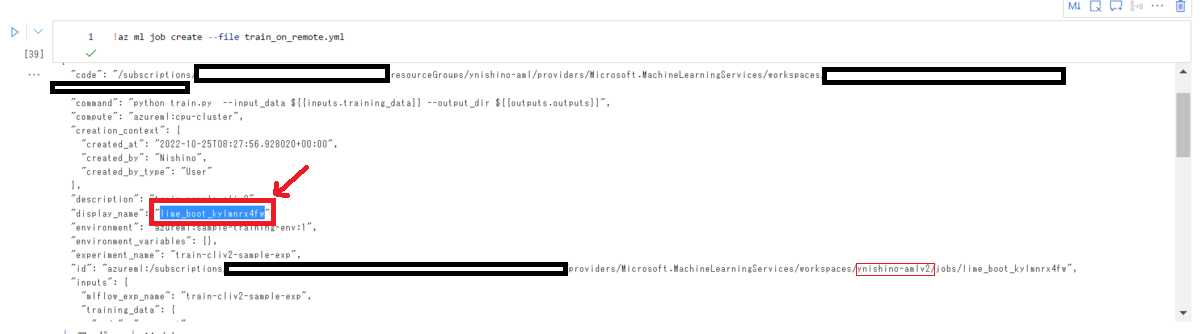
以下のコマンドを実行すると、カレントディレクトリに学習したファイルがダウンロードされます。
az ml job download --name $job_name
ローカル環境ファイルの登録
以下のコマンドでローカル環境のモデルファイルを登録します。
az ml model create --name titanic-model --version 1 --path ./artifacts/models
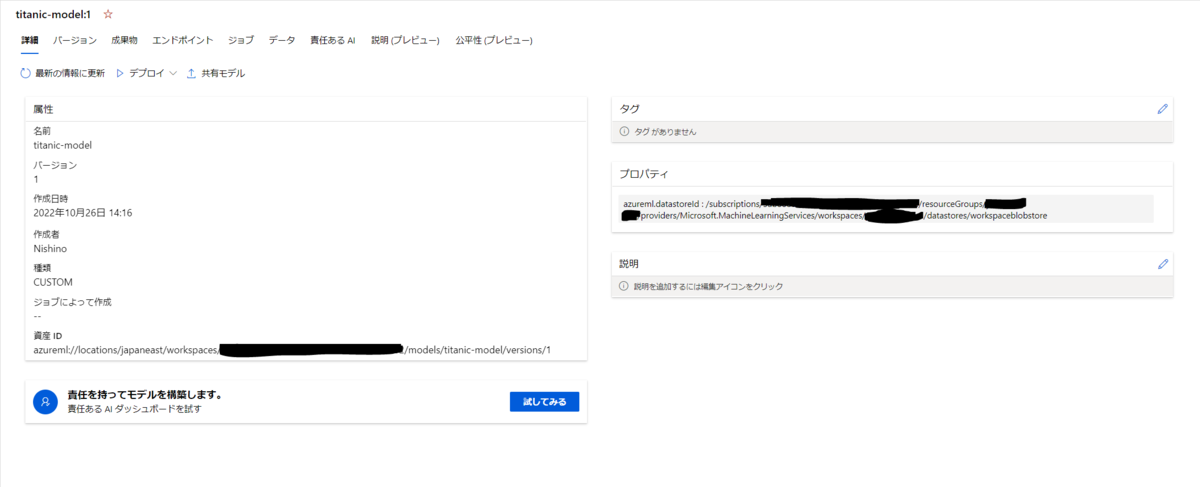
登録したモデルは、ワークスペースの画面から詳細を確認することができます。
エンドポイントの作成
エンドポイントの定義
まずは推論エンドポイントを立ち上げるための準備を行います。
キー認証方式でリソースを作成します。
managed_endpoint_create.yml
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json name: titanic-sample-endpoint auth_mode: key
yamlファイルを送信してマネージドエンドポイントを作成します。
az ml online-endpoint create --file managed_endpoint_create.yml

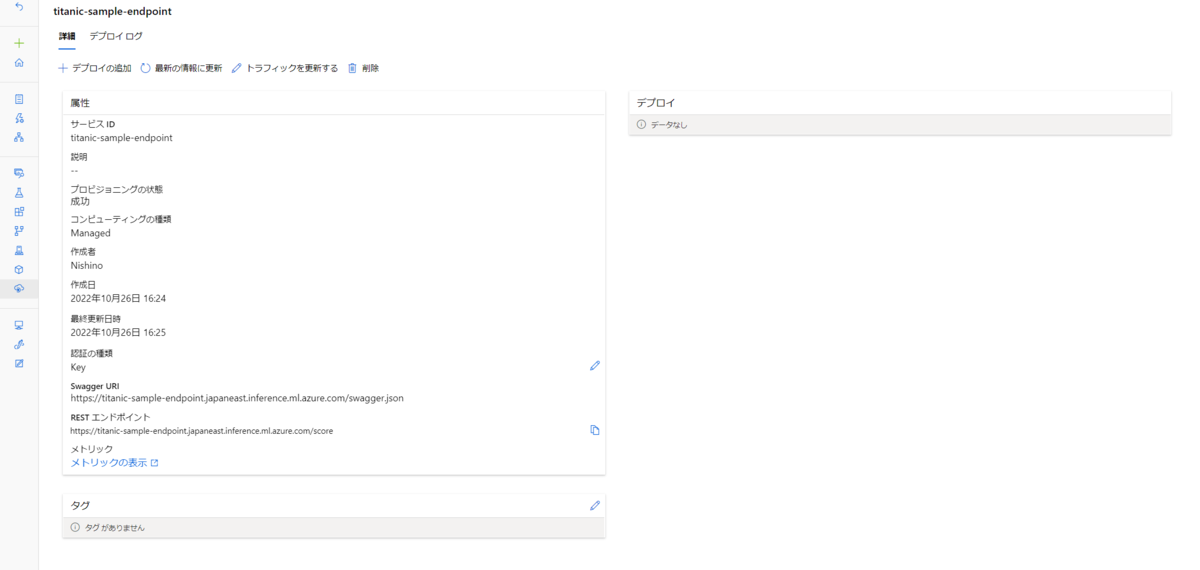
この時点でリソースが作成されるものの、まだ空の状態です。
次の項目で使用するコンピューティングリソースや動作の中身を決定します。

エンドポイントの環境構築
エンドポイントの中身を作成します。
まずは推論APIの動作を定義する、スコアリングスクリプトを作成します。
score.py
import os import json import logging from mlflow.pyfunc import load_model def init(): global model logging.info("AZUREML_MODEL_DIR: " + os.environ["AZUREML_MODEL_DIR"]) model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "models") model = load_model(model_path) logging.info("Init complete") def run(mini_batch): logging.info(f"run method start: {__file__}, run({mini_batch})") input = json.loads(mini_batch)["data"] logging.info(f"input: {input}") predictions = model.predict(input) logging.info('Predictions:' + str(predictions)) logging.info("Request processed") return predictions.tolist()
エンドポイントのデプロイを定義するために必要な情報をyamlで定義します。
pythonの環境は前回の記事で学習用環境として作成したtraining-env.ymlをそのまま使用します。
モデルは上記で登録した「titanic-model」を使用するように設定します。
managed_endpoint_deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json name: titanic-endpoint endpoint_name: titanic-sample-endpoint model: azureml:titanic-model@latest code_configuration: code: ./scripts scoring_script: score.py environment: conda_file: ./environments/training-env.yml image: mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04 instance_type: Standard_DS2_v2 instance_count: 1
定義した情報でデプロイを実行します。
az ml online-deployment create --file managed_endpoint_deployment.yml \ --all-traffic
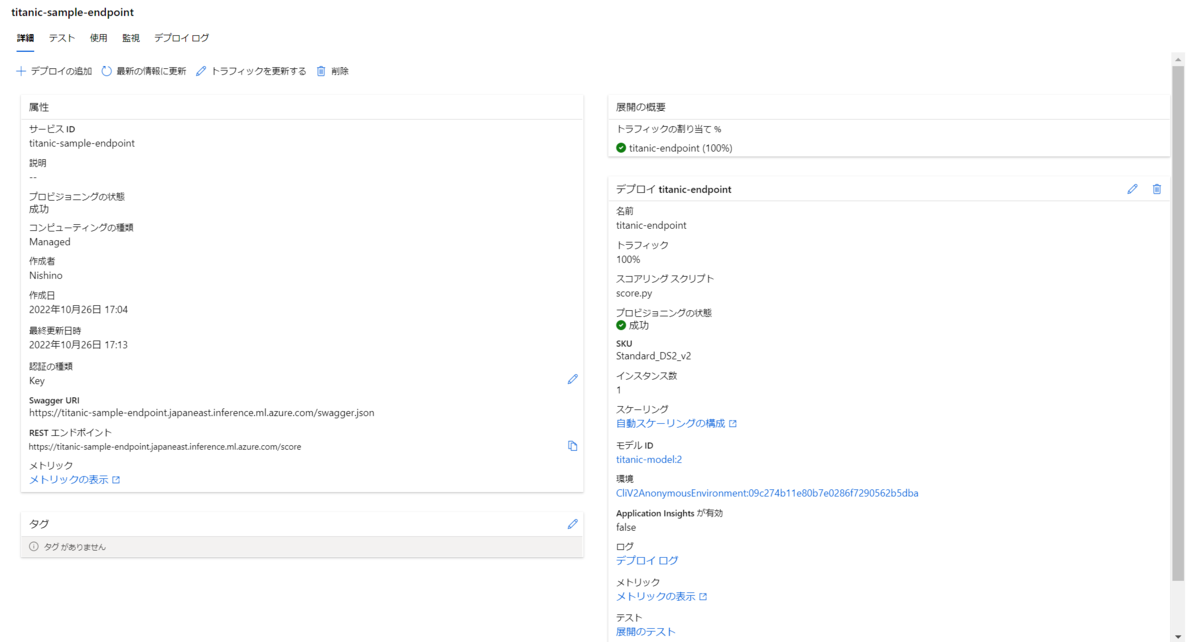
成功するとエンドポイントの画面が右のように変化し、詳細情報が表示されます。
Webサービスのテスト
デプロイしたWebサービスが正常に動作するかを確認します。 まずはエンドポイントのURLを把握します。 ワークスペース画面からも確認できますが、以下のコマンドでも詳細を確認できます。
az ml online-endpoint show \ --name $endpoint_name \ --query scoring_uri
エンドポイントをキー認証で定義したため、アクセスに必要なキーを取得します。
以下のコマンドでプライマリキーとセカンダリキーを取得できます。
az ml online-endpoint get-credentials \ --name $endpoint_name
デプロイしたエンドポイントのテストを行います。
URLとAPIキーを入力してリクエストを送信して結果を確認してください。
import requests import json SERVING_URI = "" API_KEY = "" #Pclass, Sex, Age, Fare input = [[1, 0, 20, 10.5], [1, 1, 20, 10.5]] # Invoke web service ! headers = { 'Content-Type':'application/json', 'Authorization':('Bearer '+ API_KEY) } values = json.dumps(input) input_data = "{\"data\": " + values + "}" print(input_data) http_res = requests.post( SERVING_URI, input_data, headers = headers) print('Predicted : ', http_res.text)
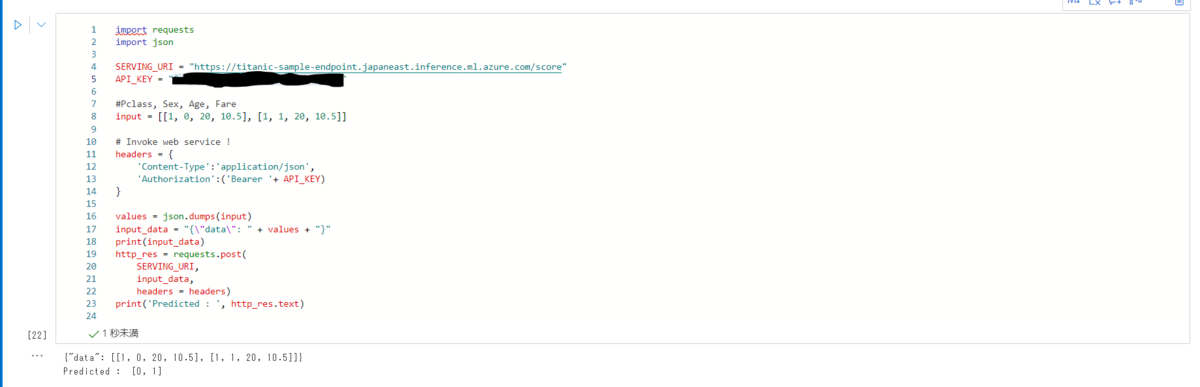
実際に送信してみた結果を示します。
今回対象としたタイタニック号データの生存状況(Survived)には性別が大きく関わっていることで知られていますが、今回のモデルも結果が変化していることが分かります。
エンドポイントが不要になった場合は、以下のコマンドで削除できます。
az ml online-endpoint delete \ --name $endpoint_name \ --yes
おわりに
CLIv2を使用して推論エンドポイントのデプロイまでを行う方法を紹介しました。
今回までで学習から推論までの一連の流れを実装したため、次回からは応用編として自動化基盤の作り方を紹介します。
本記事の続きはこちらをご覧ください。
