
Microsoft Research BlogにGraphRAG 1.0をリリースしたとの記事があったので、試してみました。
Moving to GraphRAG 1.0 - Streamlining ergonomics for developers and users - Microsoft Research
構築環境の説明
構築は主にNotebookから実行します。
今回は、以下のような環境でGraphRAGを構築していきたいと思います。
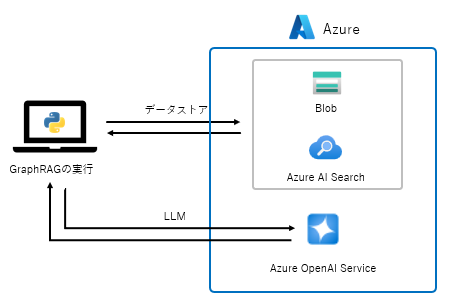
なお、Azure Open AI Service、Azure AI Search等のAzure環境のデプロイ、設定は割愛させていただきます。
実装
インストール
以下のコードを実行します。graphragがインストールされます。
pip install graphrag
なお、今回インストールされたバージョンはV1.2.0でした。
初期化
以下のコードを実行します。
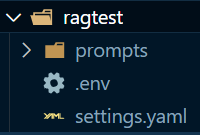
!graphrag init --root ./ragtest
コードを実行すると、ragtest配下に以下のファイルとディレクトができます。
設定
.envファイル
.envファイルを開き、以下の設定をします。
GRAPHRAG_API_KEY="<Azure Open AI ServiceのAPIキー>" AOAI_API_BASE="https://<Azure Open AI Service名>.openai.azure.com/" AZURE_BLOB_STORAGE_CONNECTION_STRING="<ストレージアカウントの接続文字列>" STORAGE_ACCOUNT_BLOB_URL="https://<ストレージアカウント名>.blob.core.windows.net" AI_SEARCH_ENDPOINT="https://<Azure AI Search名>.search.windows.net" AI_SEARCH_API_KEY="<Azure AI SearchのAPIキー>"
settings.yamlファイル
settings.yamlについていくつかピックアップして記載します。
encoding_modelとllmの部分については以下のように設定します。
encoding_model: o200k_base llm: api_key: ${GRAPHRAG_API_KEY} # set this in the generated .env file type: azure_openai_chat # or openai_chat model: gpt-4o-mini model_supports_json: true # recommended if this is available for your model. # audience: "https://cognitiveservices.azure.com/.default" api_base: ${AOAI_API_BASE} api_version: "2024-10-21" # organization: <organization_id> deployment_name: gpt-4o-mini
embeddingsの部分については以下のように設定します。
embeddings: async_mode: threaded # or asyncio vector_store: type: azure_ai_search url: ${AI_SEARCH_ENDPOINT} api_key: ${AI_SEARCH_API_KEY} # db_uri: 'output\lancedb' container_name: graphrag overwrite: true llm: api_key: ${GRAPHRAG_API_KEY} type: azure_openai_embedding model: text-embedding-3-small api_base: ${AOAI_API_BASE} api_version: "2024-10-21" # audience: "https://cognitiveservices.azure.com/.default" # organization: <organization_id> deployment_name: text-embedding-3-small
inputの部分については以下のように設定します。
input: type: blob file_type: text # or csv base_dir: "input" file_encoding: utf-8 file_pattern: ".*\\.txt$" connection_string: ${AZURE_BLOB_STORAGE_CONNECTION_STRING} storage_account_blob_url: ${STORAGE_ACCOUNT_BLOB_URL} container_name: graphrag
cache、reporting、storageの部分については以下のように設定します。
cache: type: blob base_dir: "cache" connection_string: ${AZURE_BLOB_STORAGE_CONNECTION_STRING} storage_account_blob_url: ${STORAGE_ACCOUNT_BLOB_URL} container_name: graphrag reporting: type: blob base_dir: "logs" connection_string: ${AZURE_BLOB_STORAGE_CONNECTION_STRING} storage_account_blob_url: ${STORAGE_ACCOUNT_BLOB_URL} container_name: graphrag storage: type: blob base_dir: "output" connection_string: ${AZURE_BLOB_STORAGE_CONNECTION_STRING} storage_account_blob_url: ${STORAGE_ACCOUNT_BLOB_URL} container_name: graphrag
ファイル準備
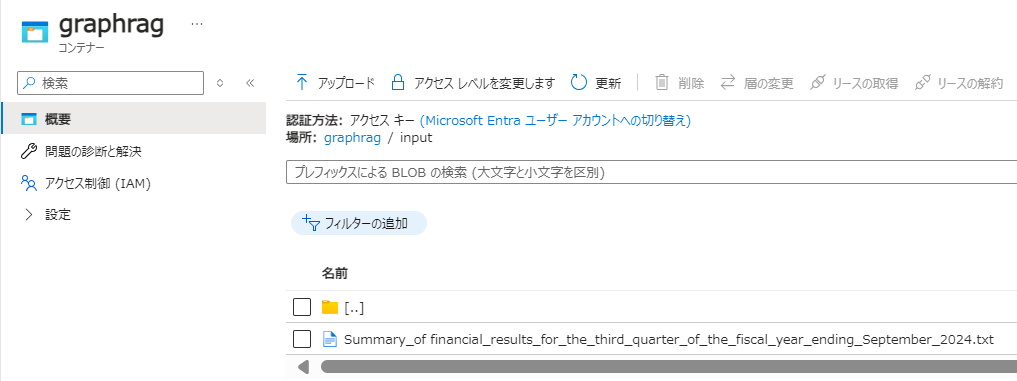
今回は、JBSがIR情報として公開している「2024年9月期 第3四半期決算短信」をテキストにしたファイルを試しに使用します。
上記のファイルをBlobにアップロードします。
インデックス作成
以下のコード実行し、indexを作成していきます。
ライブラリをインポートします。
import graphrag.api as api from graphrag.index.typing import PipelineRunResult from graphrag.config.create_graphrag_config import create_graphrag_config import yaml import pandas as pd from pprint import pprint
settings.yamlを読み込みます。
settings = yaml.safe_load(open("ragtest/settings.yaml"))
GraphRagConfigオブジェクトを生成します。
graphrag_config = create_graphrag_config(
values=settings, root_dir="ragtest"
)
インデックスを作成します。
index_result: list[PipelineRunResult] = await api.build_index(config=graphrag_config) # index_result is a list of workflows that make up the indexing pipeline that was run for workflow_result in index_result: status = f"error\n{workflow_result.errors}" if workflow_result.errors else "success" print(f"Workflow Name: {workflow_result.workflow}\tStatus: {status}")
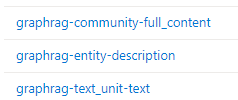
処理が完了すると、Blob上にフォルダーが、フォルダーの中にファイルが作成されます。

Azure AI Searchには3つのインデックスが作成されます。
検索実行
検索方法として以下の3種類があります。
- Local search
- Global search
- DRIFT Search
今回は、実行することができたLocal searchと Global searchについて記載します。
データ読み込み
検索を実行する前にデータを読み込みます。
connection_string = "<ストレージアカウントの接続文字列>" storage_options = {"connection_string": connection_string} final_communities = pd.read_parquet("abfs://graphrag/output/create_final_communities.parquet", storage_options=storage_options) final_community_reports = pd.read_parquet("abfs://graphrag/output/create_final_community_reports.parquet", storage_options=storage_options) final_documents = pd.read_parquet("abfs://graphrag/output/create_final_documents.parquet", storage_options=storage_options) final_entities = pd.read_parquet("abfs://graphrag/output/create_final_entities.parquet", storage_options=storage_options) final_nodes = pd.read_parquet("abfs://graphrag/output/create_final_nodes.parquet", storage_options=storage_options) final_relationships = pd.read_parquet("abfs://graphrag/output/create_final_relationships.parquet", storage_options=storage_options) final_text_units = pd.read_parquet("abfs://graphrag/output/create_final_text_units.parquet", storage_options=storage_options)
Local Search
Local Searchは、ドキュメント内の特定項目に関する質問に適した検索方法です。
response, context = await api.local_search( config=graphrag_config, nodes=final_nodes, entities=final_entities, community_reports=final_community_reports, text_units=final_text_units, relationships=final_relationships, covariates=None, community_level=2, response_type="Multiple Paragraphs", query="クラウドインテグレーション事業の売上はいくらですか?" )
回答結果を確認します。
print(response)
なお、今回のデータでは以下の回答が得られました。
## クラウドインテグレーション事業の売上 日本ビジネスシステムズ株式会社のクラウドインテグレーション事業は、2024年6月30日までの第3四半期において、売上高が17,174百万円であることが報告されています。この数字は前年同期比で3.4%の増加を示していますが、一部の案件における納期変更や長期化によりコストが増加したため、セグメント利益は2,069百万円で、前年同期比で12.0%の減少となっています [Data: Reports (0); Entities (31); Relationships (25)]。 このように、クラウドインテグレーション事業は旺盛なクラウド需要を背景に成長しているものの、コストの増加が利益に影響を与えていることがわかります。今後の市場動向や企業の戦略が、さらなる成長にどのように寄与するかが注目されます。
回答生成する際に使用したコンテキストは以下で確認ができます。出力結果は多くなるので、省略します。
pprint(context)
Global Search
Global Searchは、データセット全体を理解するための質問に適しています。
response, context = await api.global_search( config=graphrag_config, nodes=final_nodes, entities=final_entities, communities=final_communities, community_reports=final_community_reports, community_level=2, dynamic_community_selection=False, response_type="Multiple Paragraphs", query="この決算書は何を一番言い表していますか?", )
回答結果を確認します。
print(response)
なお、今回のデータでは以下の回答が得られました。
## 決算書の主なポイント この決算書は、日本ビジネスシステムズ株式会社の2024年9月期の財務パフォーマンスに関する予測を示しており、特に第3四半期の結果が全体の業績に与える影響を強調しています。これにより、投資家や利害関係者は会社の成長可能性を評価することができるでしょう [Data: Reports (4, 1, 3)]。 ## 財務結果とその影響 さらに、決算書は2023年度の業績や配当情報を含む重要な財務結果を提供しており、これが株価や投資家の信頼にどのように影響するかを示しています。特に、配当情報は投資家にとって重要な要素であり、企業の健全性を示す指標となります [Data: Reports (3, 4)]。 ## 財務健全性の指標 また、決算書は会社の財務健全性を示す指標として、総資産や純資産の関係を明らかにしています。これらの指標は、投資家の意思決定に与える影響が大きく、企業の長期的な成長に対する信頼を高める要因となるでしょう [Data: Reports (1, 3)]。 ## 結論 総じて、この決算書は日本ビジネスシステムズ株式会社の財務パフォーマンス、特に第3四半期の結果、2023年度の業績、配当情報、及び財務健全性の指標を通じて、投資家や利害関係者に対して重要な情報を提供しています。これにより、彼らは企業の成長可能性や投資判断を行うための基盤を得ることができるでしょう。
まとめ
GraphRAGについて検証をしてみました。
検索方法でドキュメントの特定の項目について質問したり、データセット全体について質問することもできました。
また、Azure上のストレージを活用する事例が少ないため、今回はBlobやAzure AI Searchを使用してみました。
今後、DRIFT Searchが動作する状態になれば、また機会を見つけて試してみたいと思います。
