
Power Automate では、一般的なアクションでは取得できない情報も、REST APIを利用することで取得できる場合があります。
今回は、Power Automate上からSharePointサイト内のドキュメント閲覧数を取得する方法についてご紹介します。
実装イメージ
本記事では、以下のようなフローを作成します。
このフローは、最終的にCsvファイルに"ドキュメント名","閲覧数","対象のドキュメントのリンク"が出力される実装にしています。
■フロー完成イメージ
■フロー出力結果イメージ

フローの作成
今回作成するフローは以下のトリガー・アクションで構成されています。
■トリガー
- フローを手動でトリガーする
■アクション
- 変数を初期化する(2つ)
- SharePoint に HTTP 要求を送信します
- JSON の解析
- それぞれに適用する
- それぞれに適用する -アレイのフィルター処理-(2つ)
- それぞれに適用する -配列変数に追加-
- CSV テーブルの作成
- ファイルの作成
まずは、Power Automate を開き、インスタンスフローを作成します。

トリガーには「フローでを手動でトリガーする」を選択し、[作成]をクリックします。

フローの編集画面に遷移したら準備完了です。

次はアクションを追加していきます。
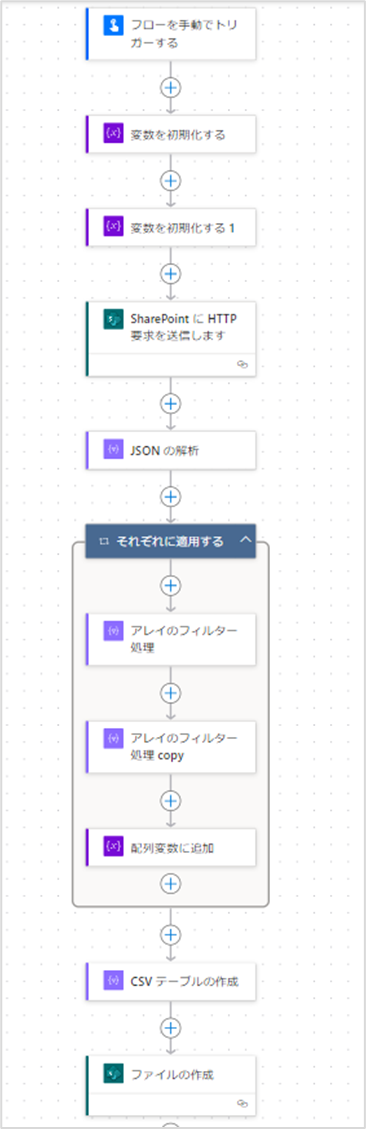
変数の初期化
まずは「変数を初期化する」アクションを追加します。
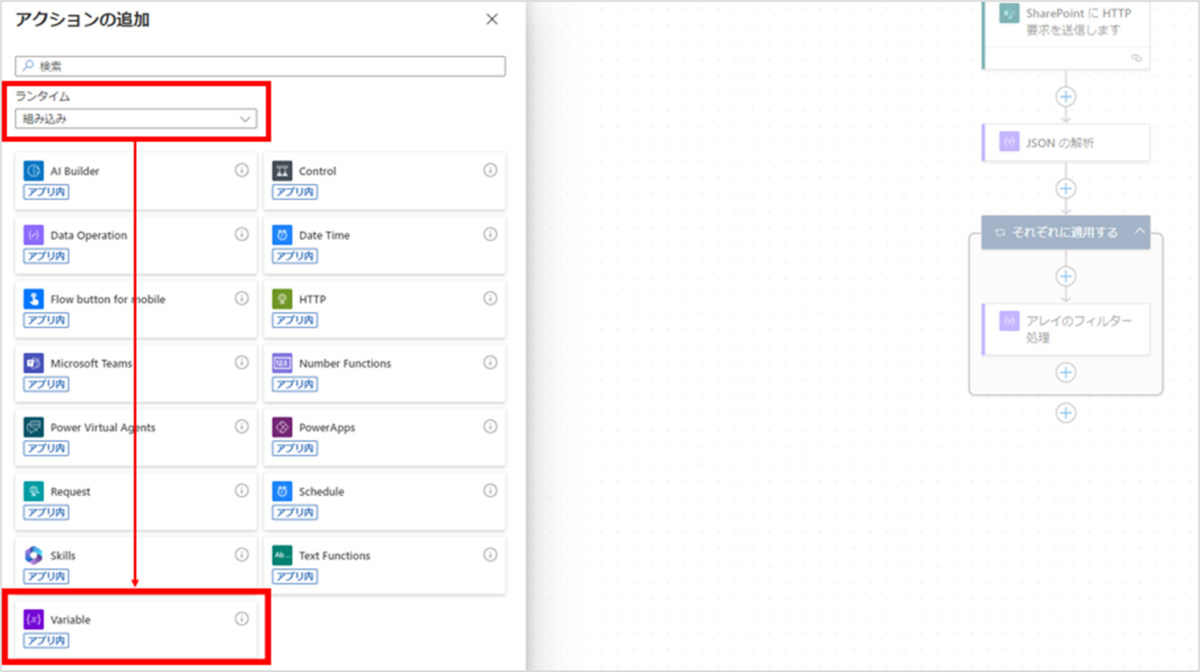
このアクションは、ランタイムを[組み込み]にし、[Variable]をクリックすると選択できます。


アクションが追加されたら、設定値を入力していきます。
今回追加したアクションには以下の値を設定してください。
- Name:strSiteUrl
- Type:String
- Value:<閲覧数を取得したいサイトのURL>
同様に「変数を初期化する」アクションをもう一つ追加し、以下のように設定してください。
- Name:arrayOutputData
- Type:Array
- Value:<空白>

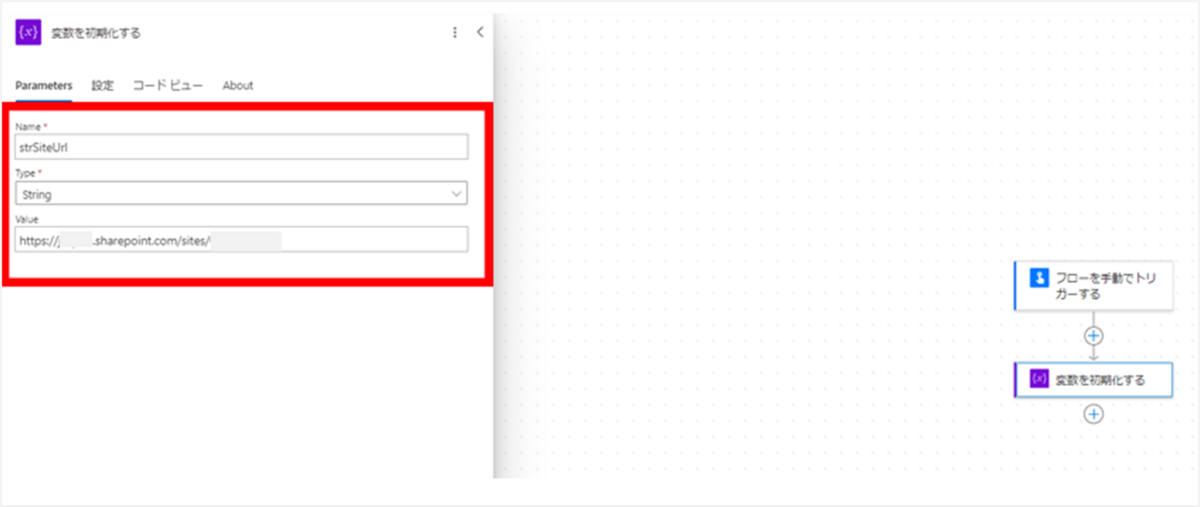
HTTP要求の設定
次は「SharePoint に HTTP 要求を送信します」アクションを追加します。
このアクションは、ランタイムを[標準]にし、[SharePoint]をクリックすると選択できます。
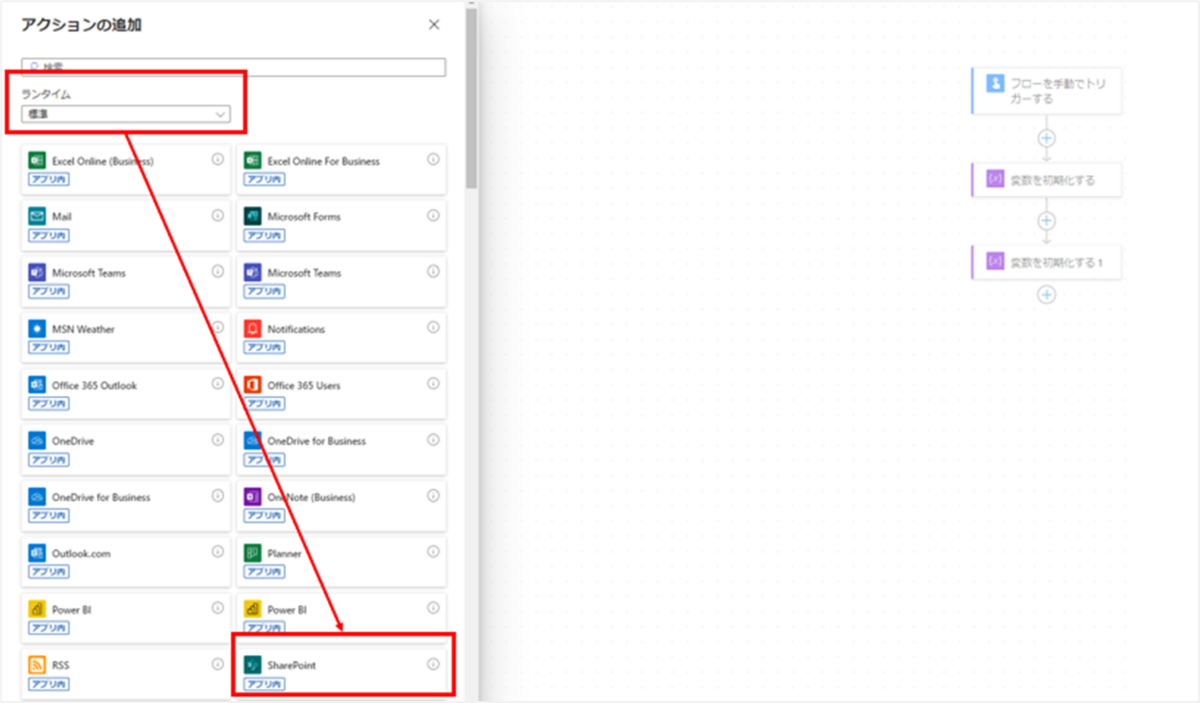

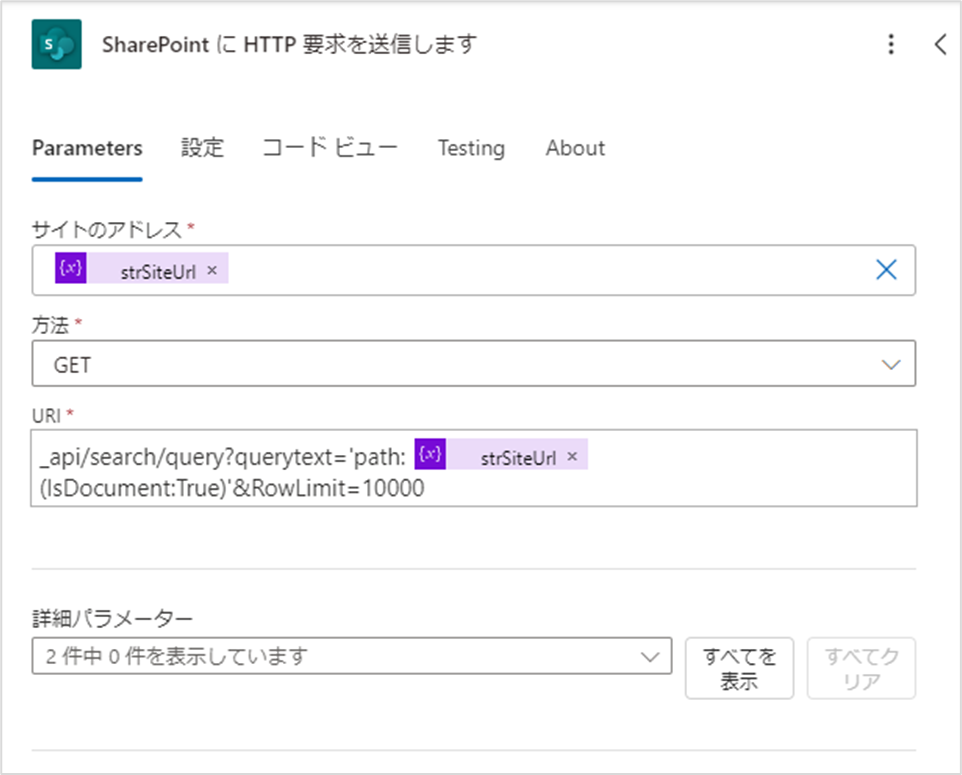
アクションが追加されたら、設定値を入力していきます。
今回追加したアクションには以下の値を設定してください。
- サイトのアドレス:@{variables('strSiteUrl')}
- 方法:GET
- URI:_api/search/query?querytext='path: @{variables('strSiteUrl')}(IsDocument:True)'&RowLimit=10000
-----------------------------------------------------
★参考
URIに設定した部分は大きく2つの要素で成り立っています。
- _api/search/query?querytext='path: @{variables('strSiteUrl')}(IsDocument:True)'
→strSiteUrl変数に設定したサイト内のドキュメントをすべて取得 - RowLimit=10000
→既定では10件しか取得しないため、明示的に最大10000件取得するように指定
-----------------------------------------------------
アクションの設定ができたら、フローをテスト実行します。
フローを保存し、テストを手動実行してください。
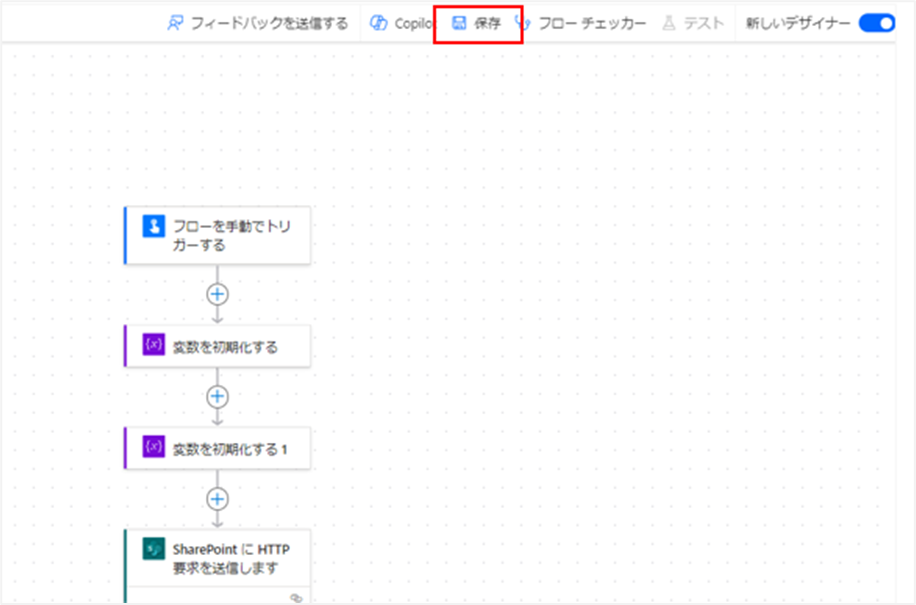
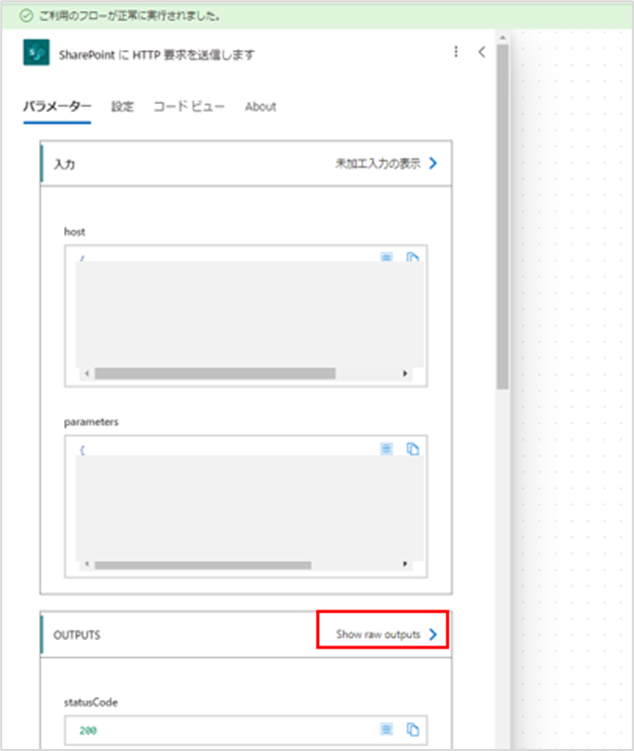
フローが正常に実行されたら、「SharePoint に HTTP 要求を送信します」アクションの実行結果を確認します。
「SharePoint に HTTP 要求を送信します」アクションをクリックすると画面右側に実行結果が表示されるので、その中のOUTPUTS > Show raw outputs をクリックします。
画面右側に出力結果が表示されるので、出力内容をクリックし、Ctrl + Fをクリックします。
出力結果内に検索バーが表示されたら「ViewsLifeTime」を入力します。
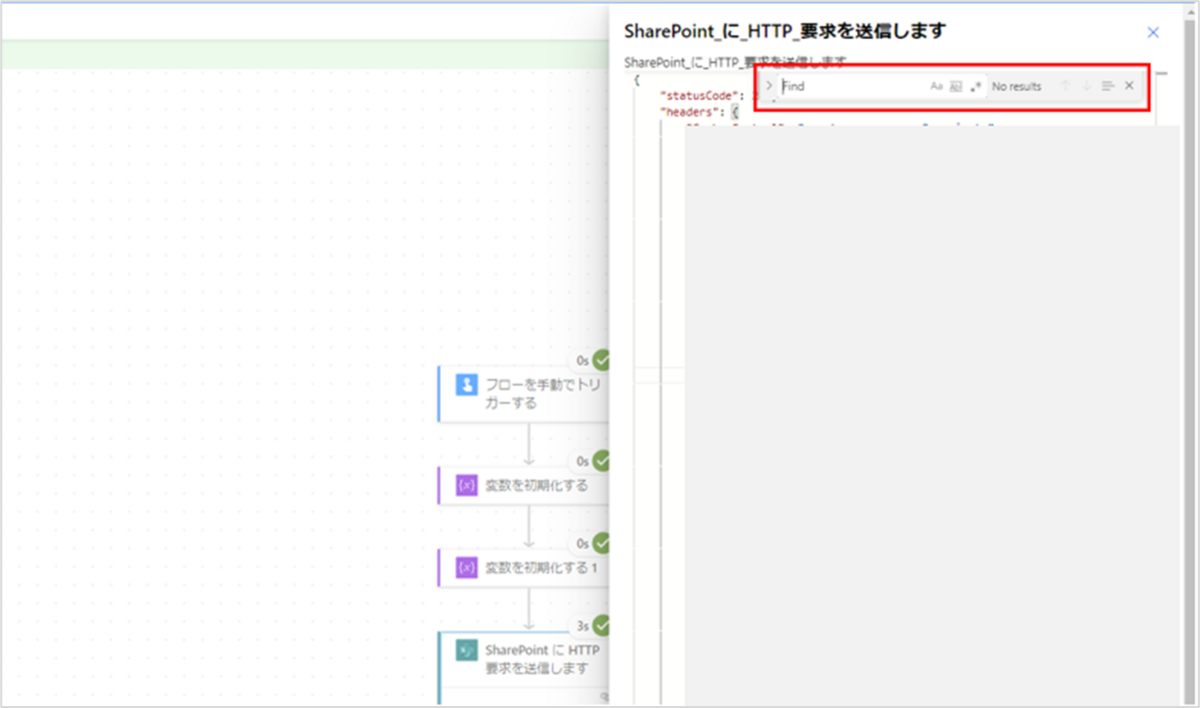
検索にヒットするものが存在していればOKです。
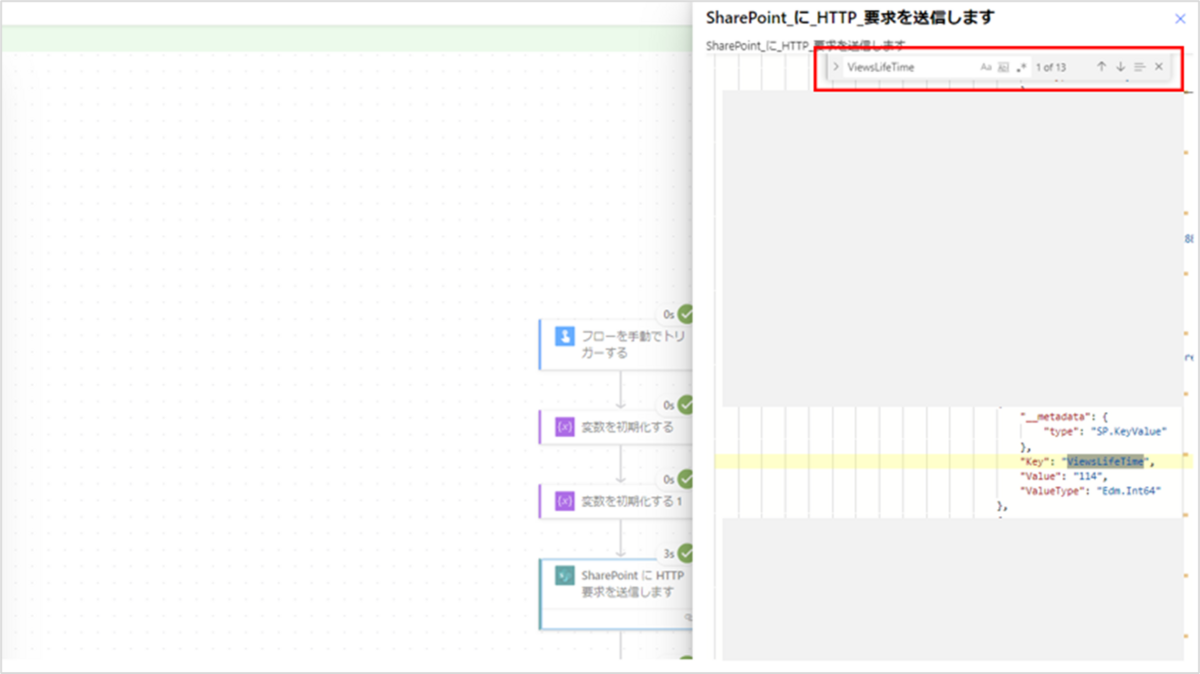
画面右側に表示されている出力結果を×で閉じ、画面左側に表示されている出力結果のOUTPUTS > bodyをコピーしてください。
※ここでコピーしたものは次のアクションで使用します。

HTTP要求の結果を取得
次は、前の操作で設定したアクションから取得できる情報をアレイ変数にためる処理を追加していきます。
まずは「JSON の解析」アクションを追加します。
このアクションは、ランタイムを[組み込み]にし、[Data Operation]をクリックすると選択できます。
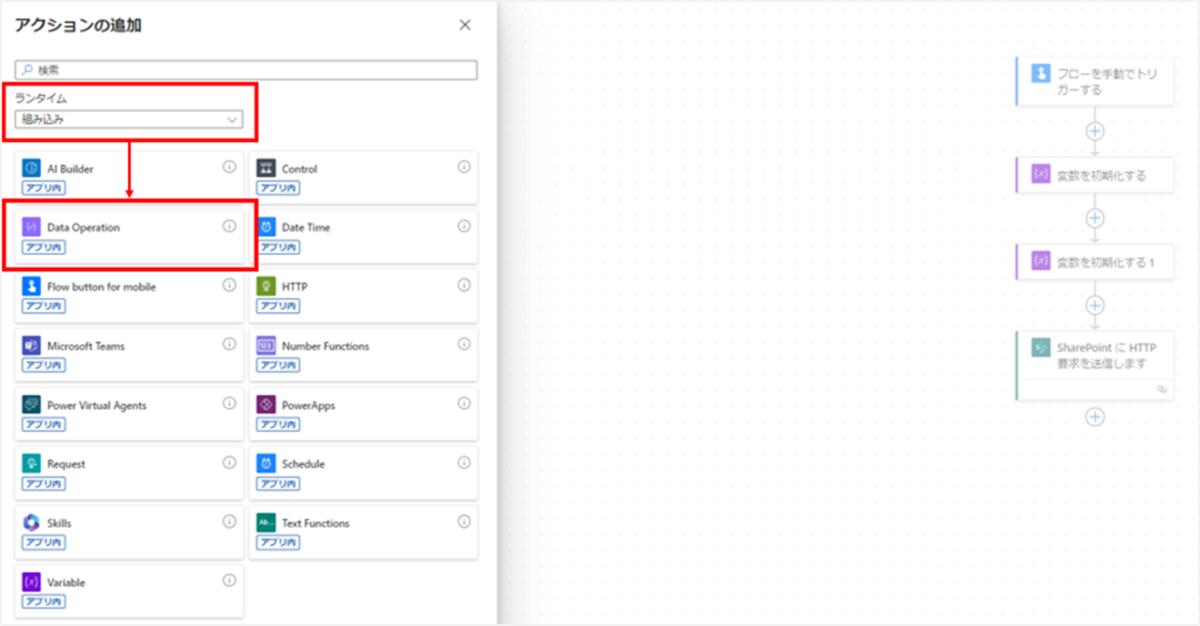
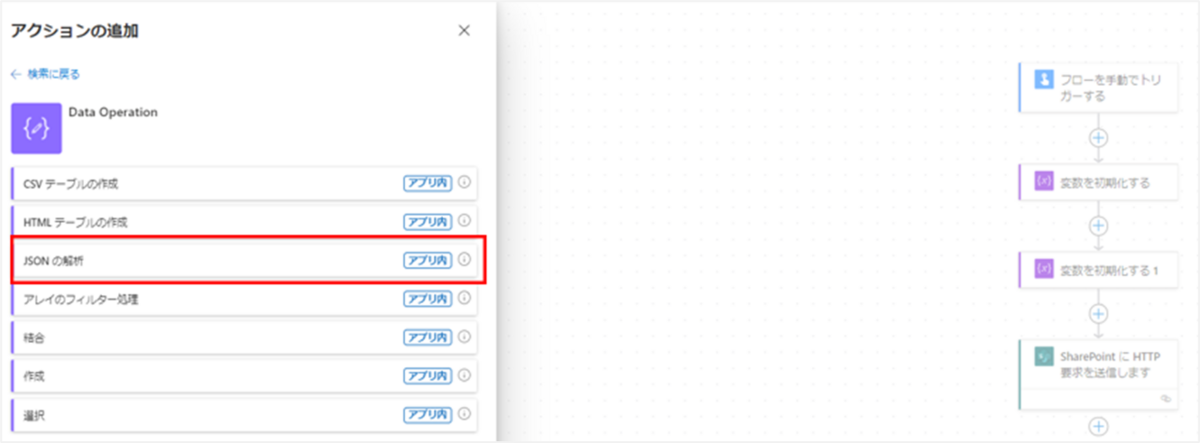
アクションが追加されたら、設定値に以下を入力してください。
- Content:@{body('SharePoint_に_HTTP_要求を送信します')}
- Schema:<以下を参照>
■「JSONの解析」アクションのスキーマ設定方法
Schema内にある[サンプルのペイロードを使用してスキーマを生成する]をクリックします。
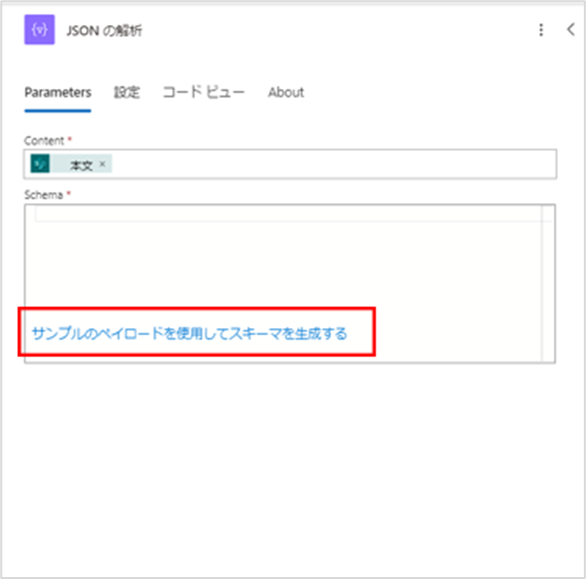
画面にサンプル入力画面が表示されたら、前手順の「SharePoint に HTTP 要求を送信します」アクションの出力結果をコピーしたしたものをここに貼り付けます。
貼り付けたら、[完了]をクリックします。
Schemaに自動で値が入力されることを確認します。

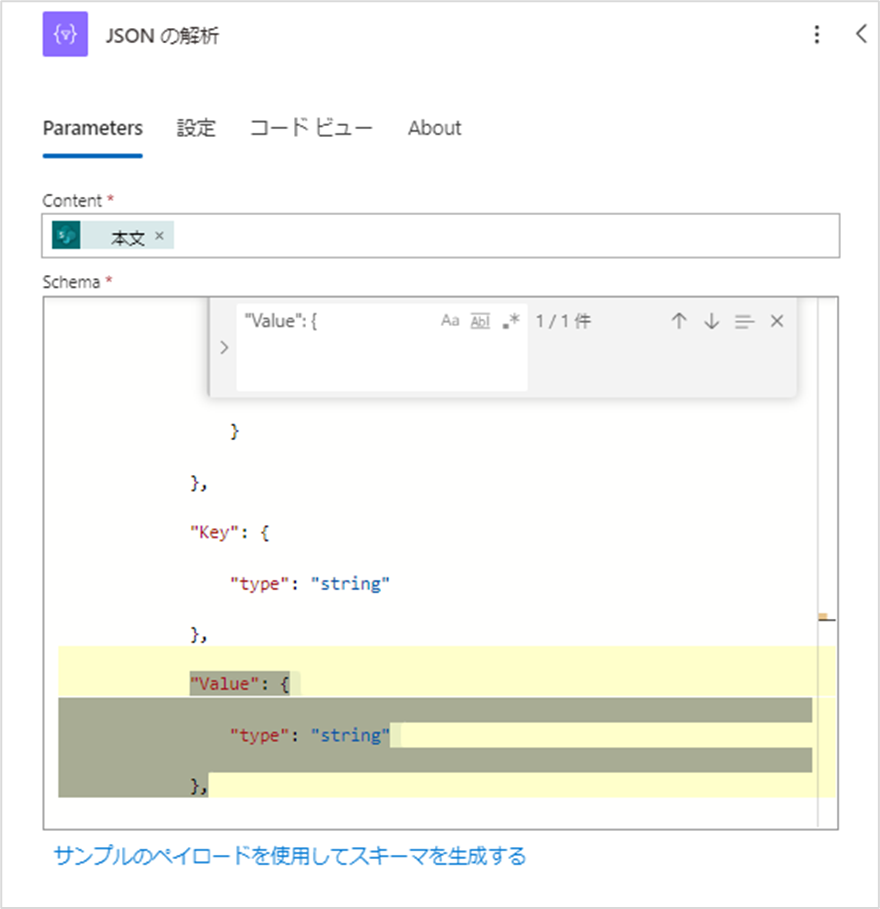
値が入力されていることが確認出来たら、Schema内にカーソルを合わせ、Ctrl + Fを押します。
検索バーに以下を入力してください。※空白も含めすべて検索バーに貼り付けてください。
"Value": {
"type": "string"
},
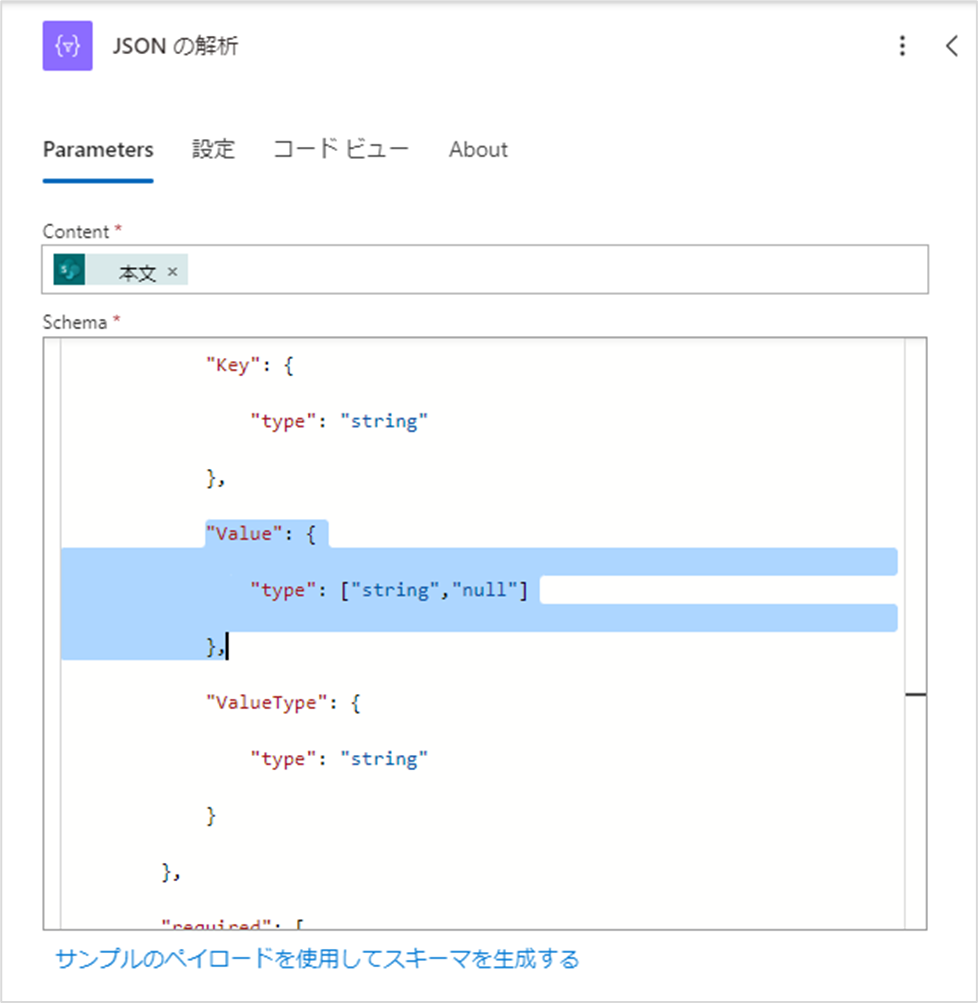
対象の文字列を検索でみつけたら、以下のように修正してください。
<修正後>
"Value": {
"type": ["string","null"]
},
「JSONの解析」アクションのスキーマ設定方法については以上です。
次に「それぞれに適用する」アクションを追加します。
このアクションは、[Control]をクリックすると選択できます。
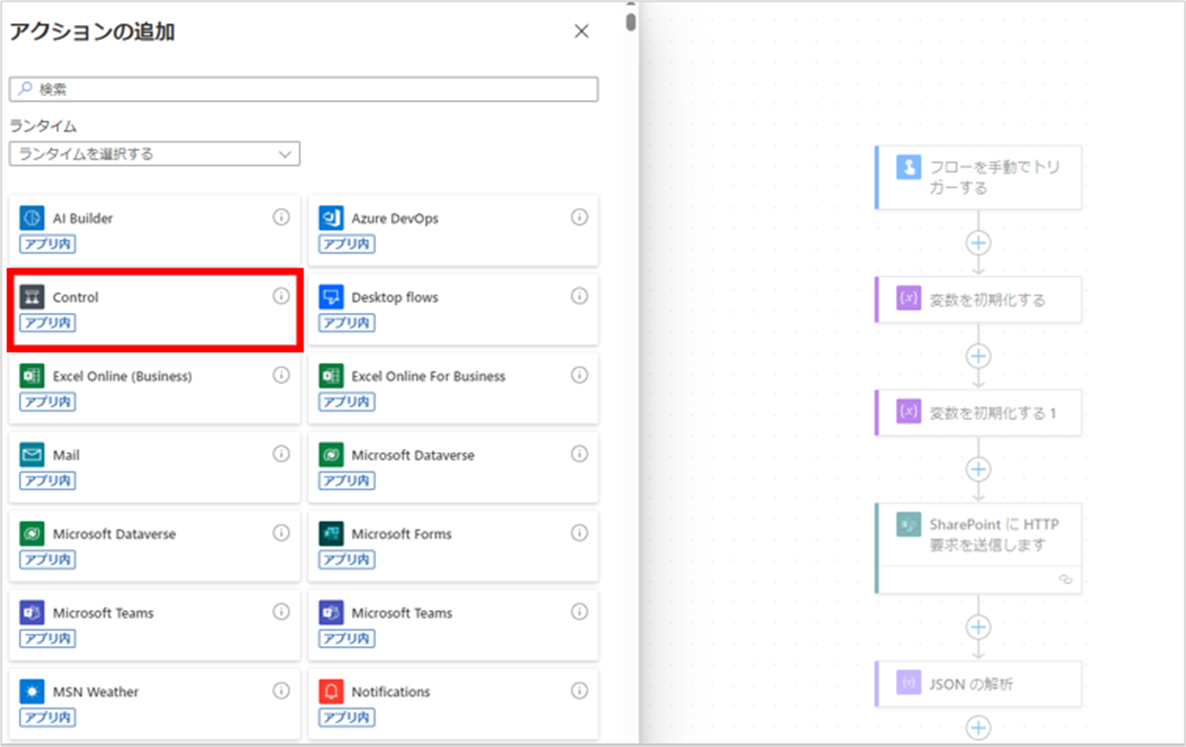
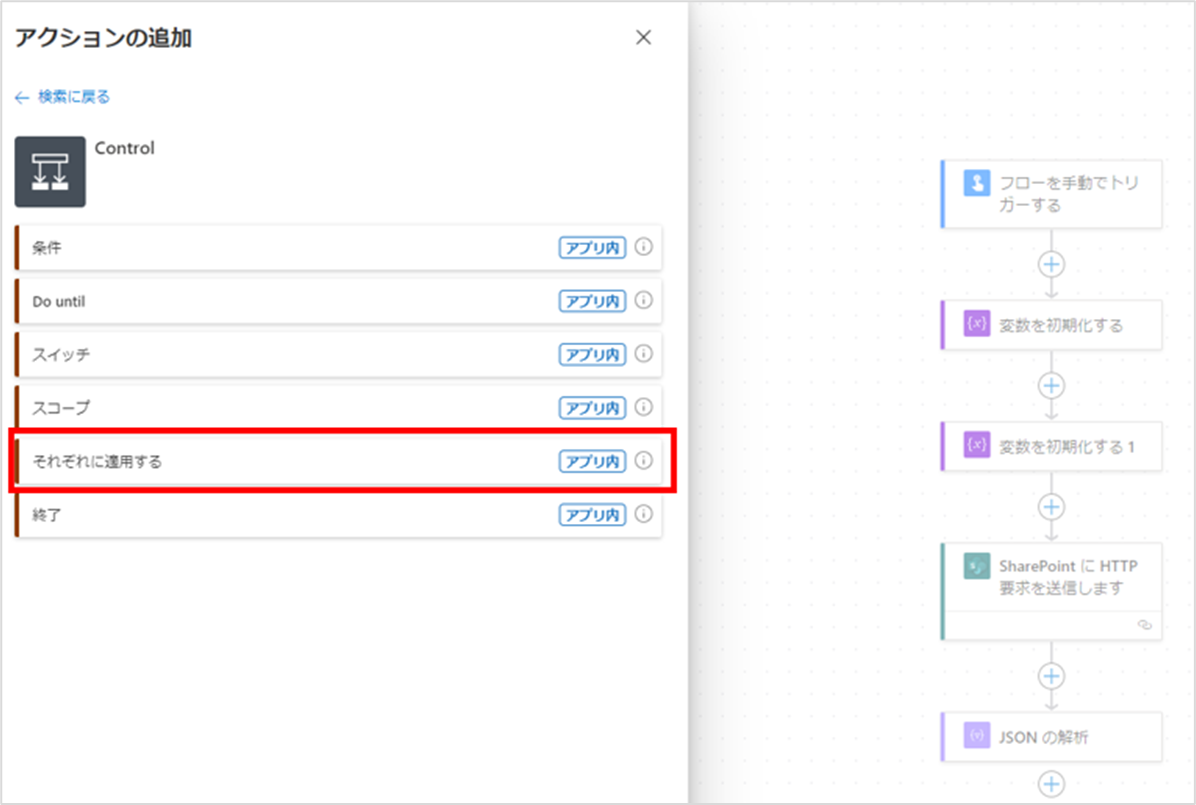
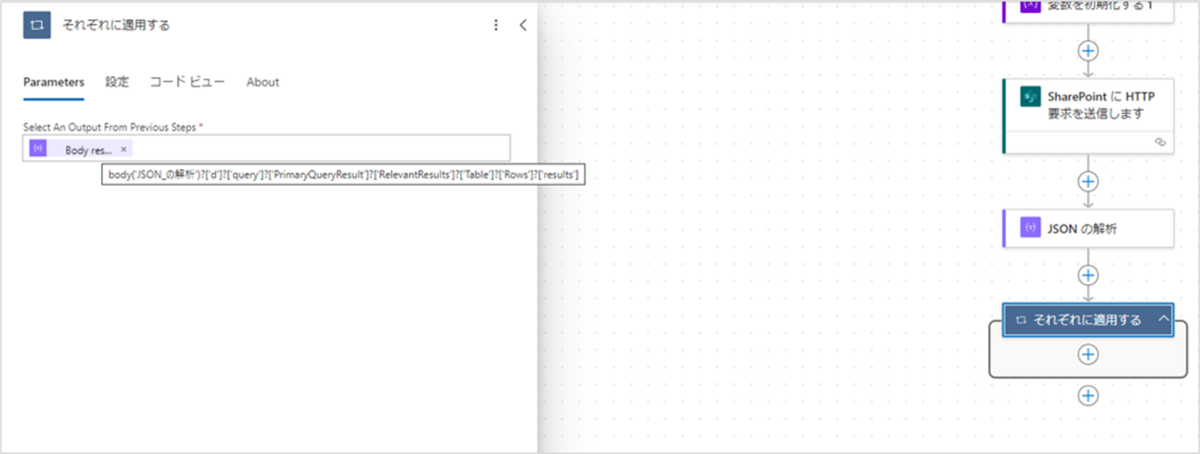
アクションが追加されたら、設定値に以下を入力してください。
- Select An Output From Previous Steps:@{body('JSON_の解析')?['d']?['query']?['PrimaryQueryResult']?['RelevantResults']?['Table']?['Rows']?['results']}
次に「アレイのフィルター処理」アクションを「それぞれに適用する」アクションの中に追加します。
このアクションは、ランタイムを[組み込み]にし、[Data Operation]をクリックすると選択できます。
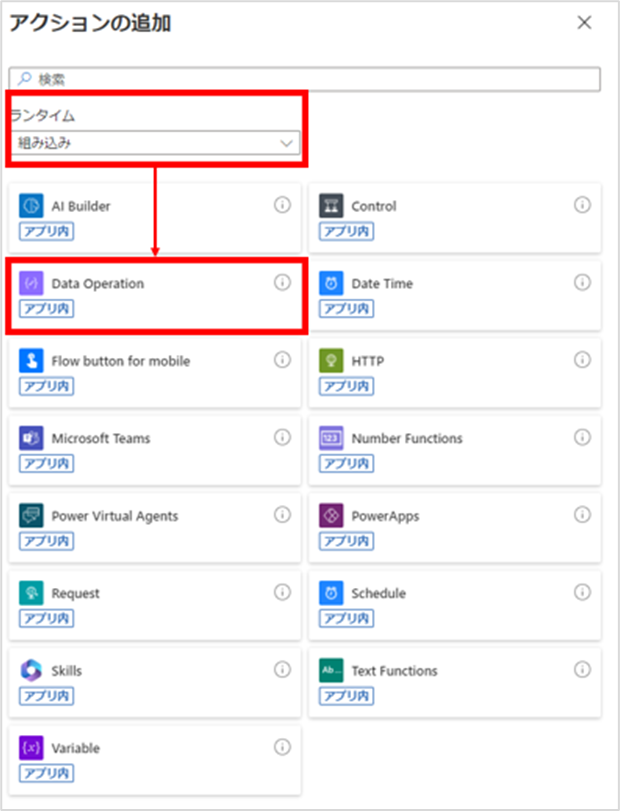
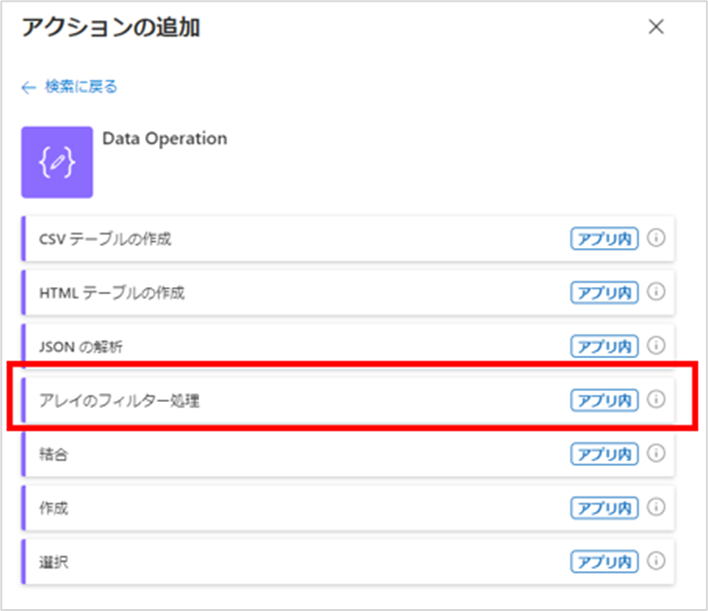
アクションが追加されたら、設定値に以下を入力してください。
- From:@{items('それぞれに適用する')?['Cells']?['results']}
- Filter Query:@item()?['Key'] is equal to ViewsLifeTime

次に、再度「アレイのフィルター処理」アクションを追加します。
前操作で作成したアクションを右クリックし、[アクションのコピー]をクリックします。
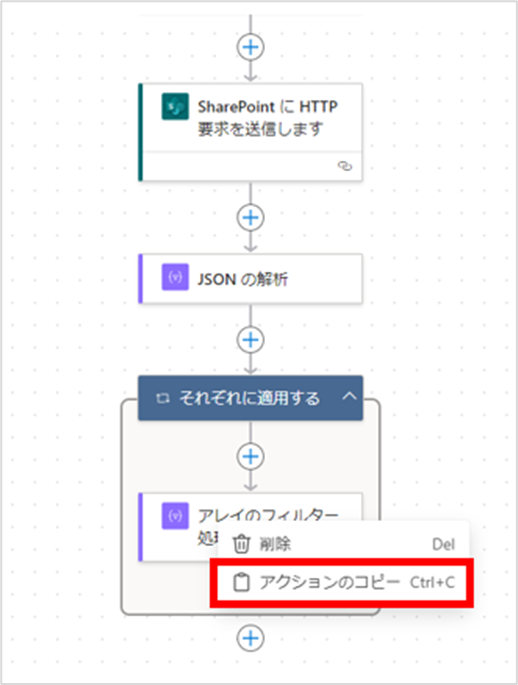
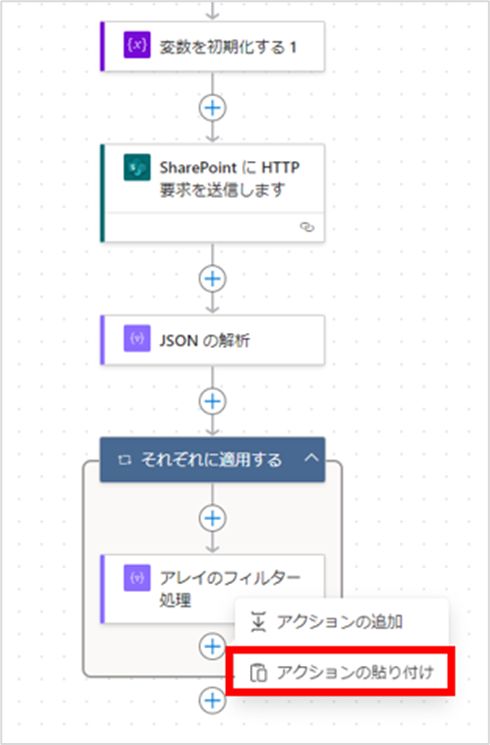
コピーしたら、「それぞれに適用する」アクション内の一番下にある+アイコンをクリックし、[アクションの貼り付け]をクリックします。
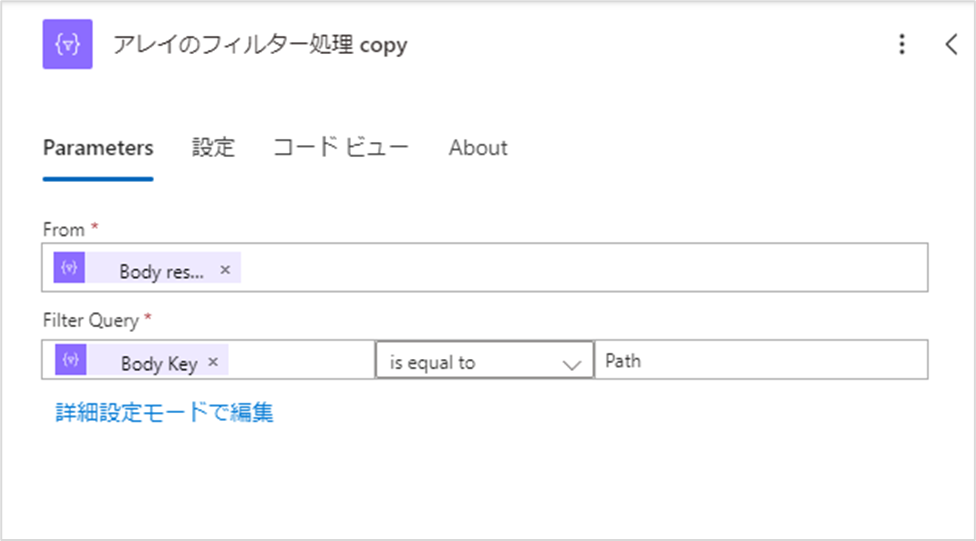
アクションが追加されたら、Filter Queryの設定値を以下のように修正します。
- Filter Query:@item()?['Key'] is equal to Path
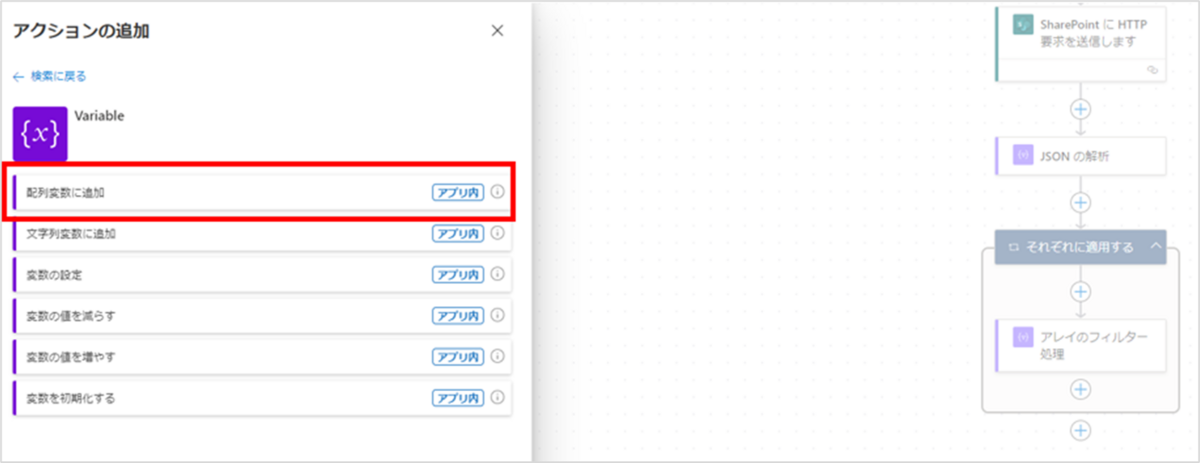
最後に「配列変数に追加」アクションを「それぞれに適用する」アクションの中に追加します。
このアクションは、ランタイムを[組み込み]にし、[Variable]をクリックすると選択できます。
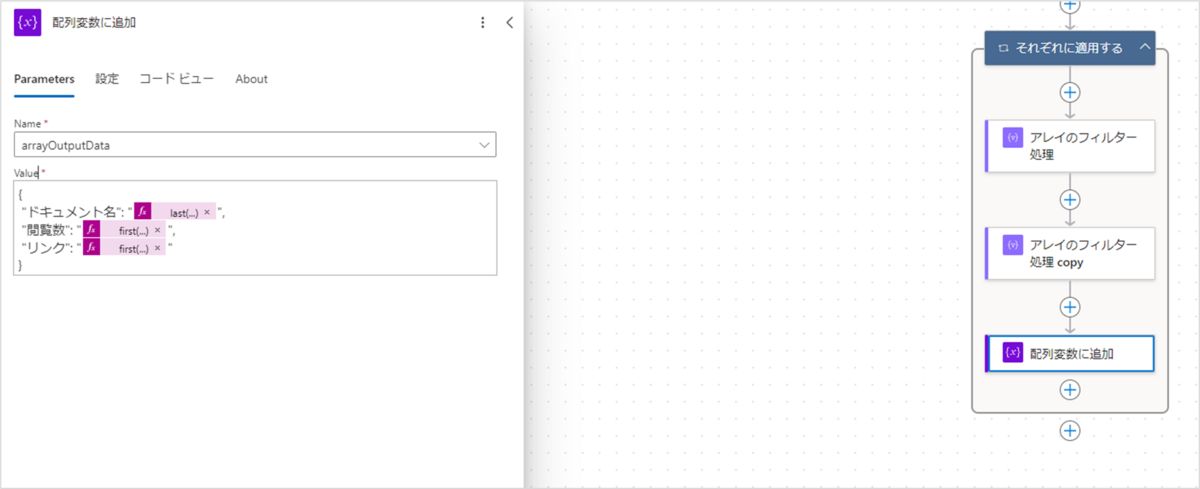
アクションが追加されたら、設定値に以下を入力してください。
- Name:arrayOutputData
- Filter Query:<以下を参照>
■Filter Queryの入力値
{
"ドキュメント名": "@{last(split(first(body('アレイのフィルター処理_copy'))?['Value'],'/'))}",
"閲覧数": "@{first(body('アレイのフィルター処理'))?['Value']}",
"リンク": "@{first(body('アレイのフィルター処理_copy'))?['Value']}"
}
Csvにファイルに出力
最後に、アレイ変数にためたものをCsvファイルに出力する処理を追加していきます。
今回は、SharePointのドキュメントライブラリにCsvファイルを出力するようにします。
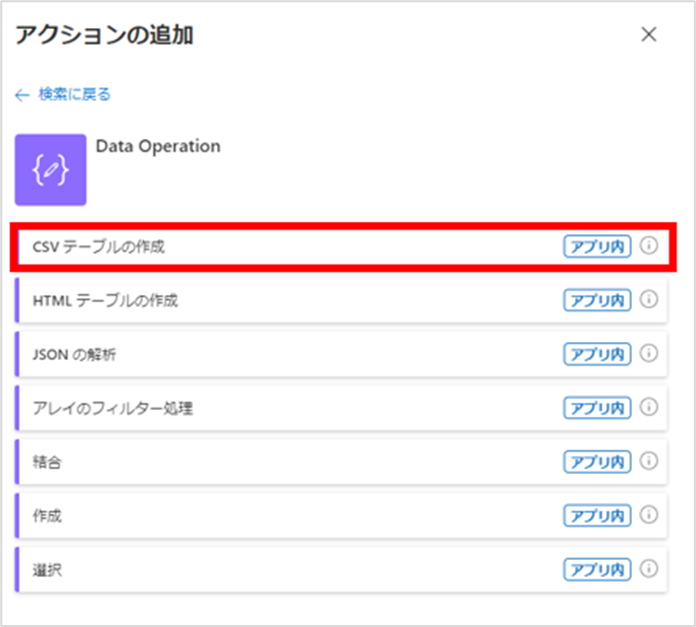
まずは「CSV テーブルの作成」アクションを追加します。
このアクションは、ランタイムを[組み込み]にし、[Data Operation]をクリックすると選択できます。
アクションが追加されたら、設定値に以下を入力してください。
- From:@{variables('arrayOutputData')}
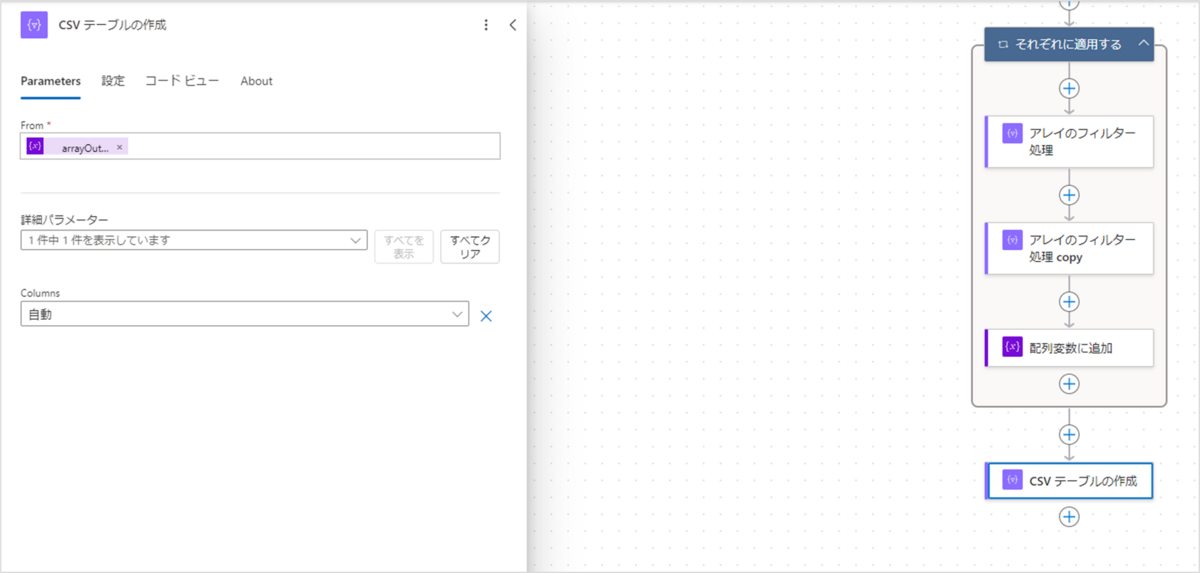
最後に「ファイルの作成」アクションを追加します。
このアクションは、検索バーに[ファイルの作成]を入力し、検索結果の中にあるSharePointコネクタの[ファイルの作成]をクリックすると追加できます。
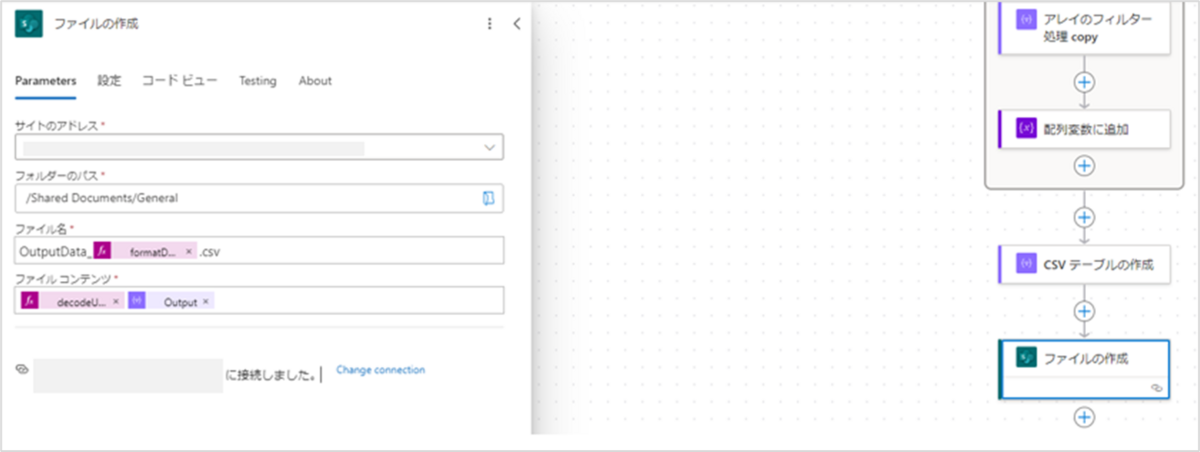
アクションが追加されたら、設定値に以下を入力してください。
- サイトのアドレス:<ファイル出力先のサイトURL>
- フォルダーのパス:<ファイル出力先のパス>
- ファイル名:<ファイル名>.csv ※1
- ファイルコンテンツ:@{decodeUriComponent('%EF%BB%BF')}@{body('CSV_テーブルの作成')} ※2
※1:以下の例では「OutputData_@{formatDateTime(addHours(utcNow(),9),'yyyyMMddhhmmss')}.csv」を入れています。
※2:csvファイルを出力する際、文字化けしてしまうため「decodeUriComponent('%EF%BB%BF')」を先頭に入れています。
実行結果の確認
まずはフローを保存します。
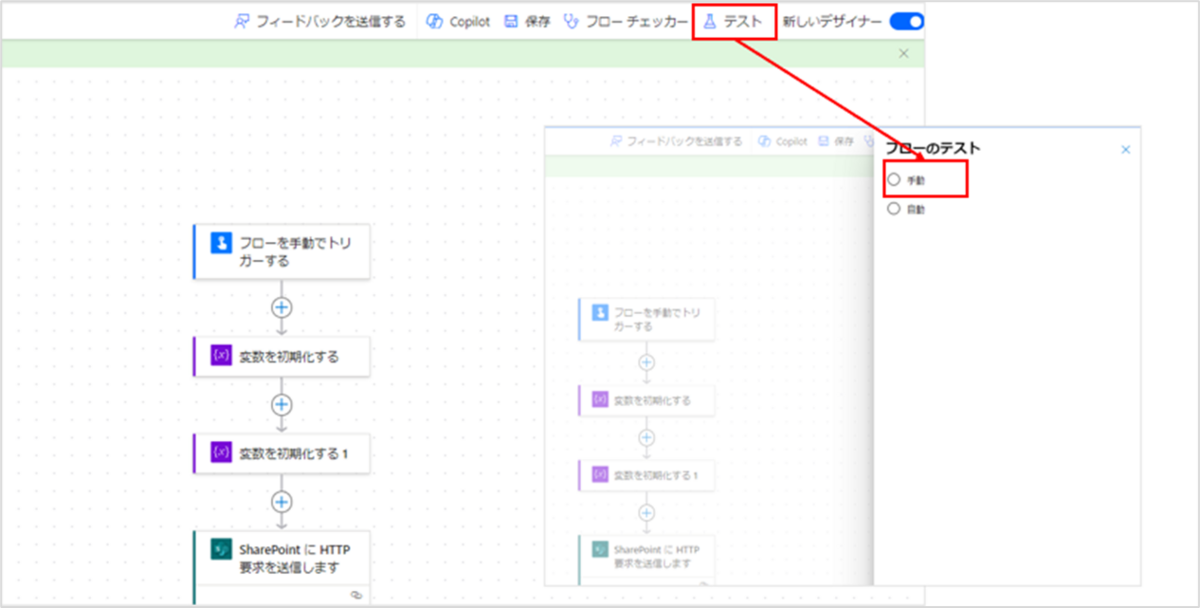
正常に保存できたら、[テスト]をクリックします。
[手動]を選択した状態で、[テスト]をクリックします。
フロー実行確認画面が表示されたら、[フローの実行]をクリックします。
フローが正常に終了したことを確認します。

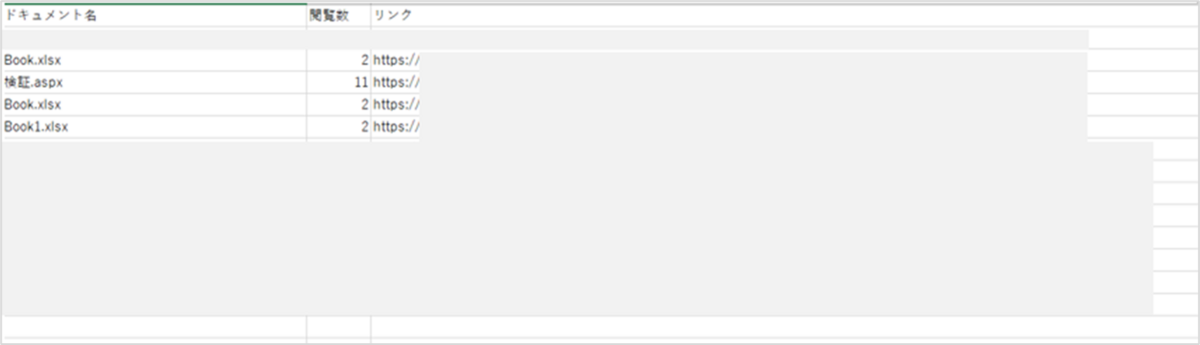
出力されたCsvファイルも確認します。
文字化けせず、値が入っていることが確認出来たら完了です。
さいごに
今回は、SharePointサイト内のドキュメントの閲覧数を取得し、Csvファイルに出力する方法を紹介しました。
REST APIをうまく使えば、通常のアクションでは取得できない情報も取得できるので、これをきっかけにぜひ使ってみてください。
Appendix
出力対象を絞り込む方法
本記事では、サイト内のすべてのドキュメント情報を取得する方法を紹介しましたが、補足として、指定した拡張子のドキュメントだけを取得する方法を紹介します。
例えば、「.pptx」と「.docx」のみを取得したい場合です。
フローの編集画面を開き、フロー内で作成した「SharePoint に HTTP 要求を送信します」アクションのURIの部分を以下のように修正します。
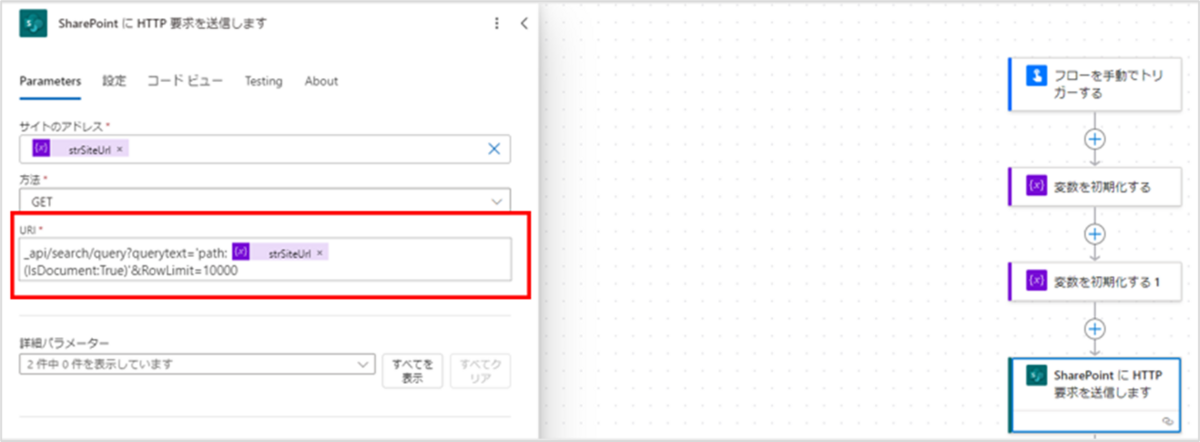
■修正前
URI:_api/search/query?querytext='path: @{variables('strSiteUrl')}(IsDocument:True)'&RowLimit=10000
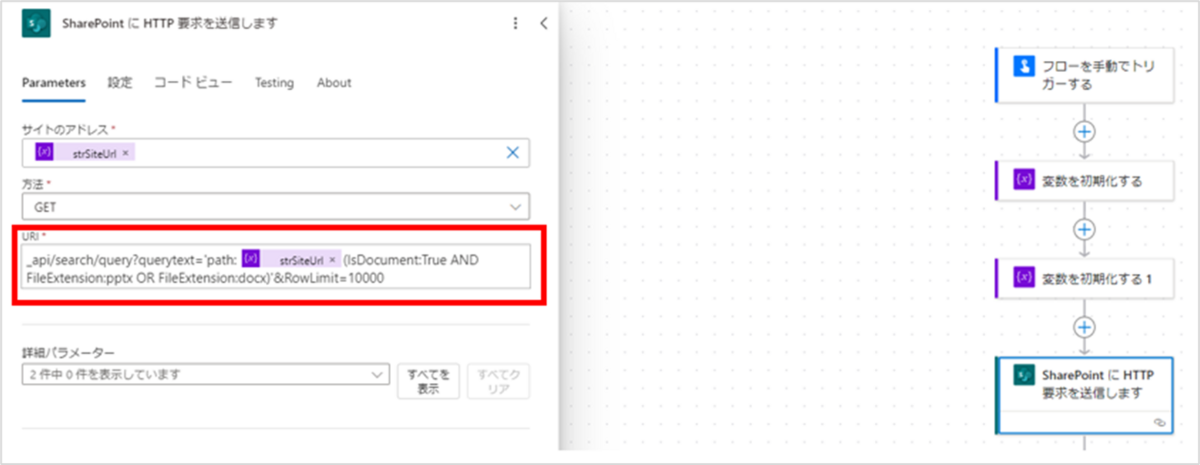
■修正後
URI:_api/search/query?querytext='path: @{variables('strSiteUrl')}(IsDocument:True AND FileExtension:pptx OR FileExtension:docx)'&RowLimit=10000
修正したらフローを保存し、実行します。
出力されたCsvファイルを確認すると、以下のように「.pptx」と「.docx」のみのデータが出力されていることがわかります。

このように、URIを少し変えることで絞り込みなどもできますので是非試してみてください。
▼参考リンク

茶谷 亮佑(日本ビジネスシステムズ株式会社)
クラウドソリューション事業本部に所属。 現在はPower Platform(特にPower Apps、Power Automate)を活用したアプリ開発業務に従事しています。好きなアーティストは星野源です。
担当記事一覧