
Azure上で音声を文字起こしするためのAIモデルが使用できるようになりました。
本記事ではAIモデル「Whisper」を使用するまでの手順を解説します。また、簡単な検証を行ったため、検証内容についても触れます。
Whisperモデルとは?
Whisperとは、OpenAI社が開発したAIモデルです。Webから収集されたデータセットを使ってトレーニングされており、多言語に対応したタスクを実行させることができます。今回は文字起こしに焦点を当てて解説します。
モデルの構造やパフォーマンス等、詳細な情報は以下のGithubをご参照ください。
Azure上ではパラメータ数1550Mのlargeサイズモデルを使用することができます。
large-v2モデルでは日本語の誤り率が5.3%とされており、英語の4.2%に次ぐ高精度で文字起こしできることが示されています。
AzureのWhisper関連サービス
Azure上でWhisperモデルを使用することができます。
モデル自体の利用は無料ですが、Azure上の基盤や計算資源を使用してデプロイされるため、サービス利用費・コンピューティングコストが発生します。
3種類のサービスからWhisperモデルを使用します。
- Azure AI Speech(音声サービス)
- Azure OpenAI Service
- Azure Machine Learning
各サービスのユースケース
3種類のサービスは、以下のようなユースケースで使い分けることができます。
| サービス名 | 概要 | サポートしているファイル |
|---|---|---|
| Azure AI Speech(音声サービス) | サイズの大きい音声ファイルを使用する場合、複数人が話している音声を使用する場合など ※公式リファレンス |
mp3,wav,ogg |
| Azure OpenAI Service | 手早くモデルを試す場合、個々の音声ファイルを高速に処理する場合など | mp3,mp4,mpweg,mpga,m4a,wav,webm |
| Azure Machine Learning | バージョンを指定してモデルを使用したい場合、コンピューティングリソースを管理したい場合、公開するAPIの詳細を細かく定義したい場合など | m4a, wav, flac, wma, mp3, etc (HuggingFaceと同様) |
※2023/10/11時点で、Azure AI SpeechではWhisper基本モデルをカスタマイズできるアップデートが示唆されています。
Azure環境でWhisperモデルを使用する
ここからは実際にAzure上でモデルを利用するための手順を示します。
Azure AI Speech
Azure AI servicesの音声サービスをデプロイすることでWhisperモデルを使用できます。 Azureポータルから「音声サービス」と検索すると以下のリソース種別が出てくるため、新規にデプロイします。
10月6日時点では米国東部・東南アジア・西ヨーロッパリージョンのいずれか、かつ、Standardの価格レベルが必要です。
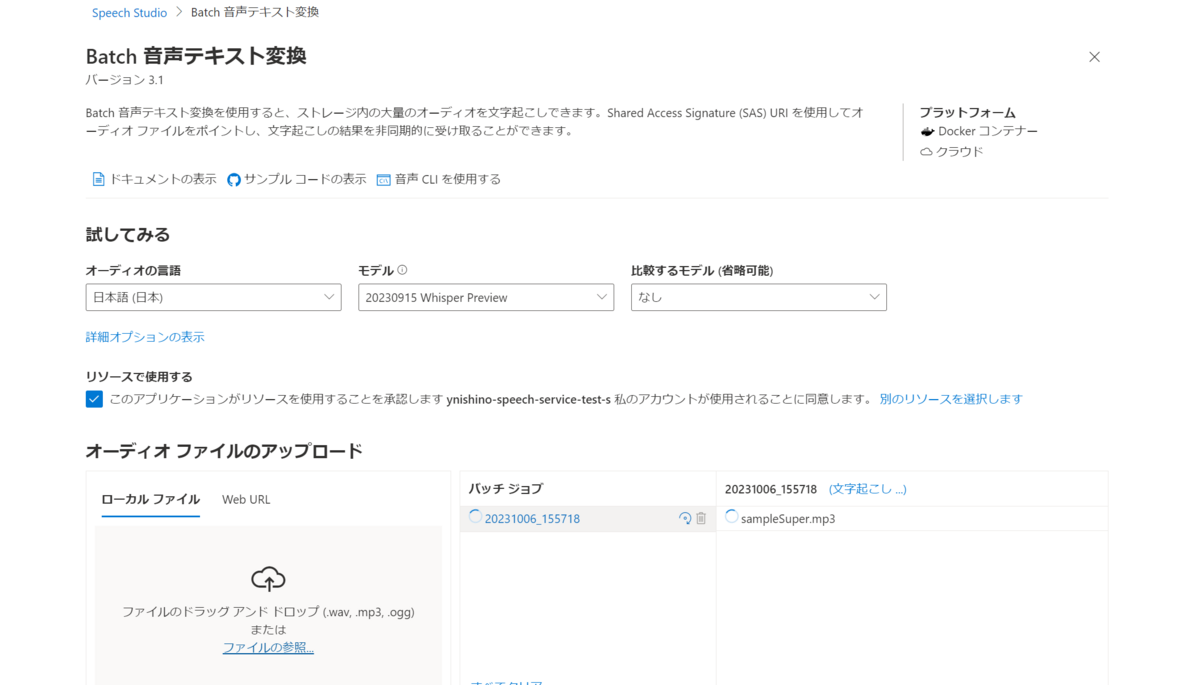
Speech Studioにアクセスして、サービス一覧の中から「Batch 音声テキスト変換」を選択します。

モデルの項目からWhisperモデルを選択します。画面上から音声ファイルをアップロードして文字起こし機能をテストします。
PythonからAPIに接続して使用することもできます。ソースコードは以下のGithubを参考にします。Azure Blob Storage上に音声ファイルをアップロードして文字起こしをするサンプルが提供されています。 github.com
Azure OpenAI Service
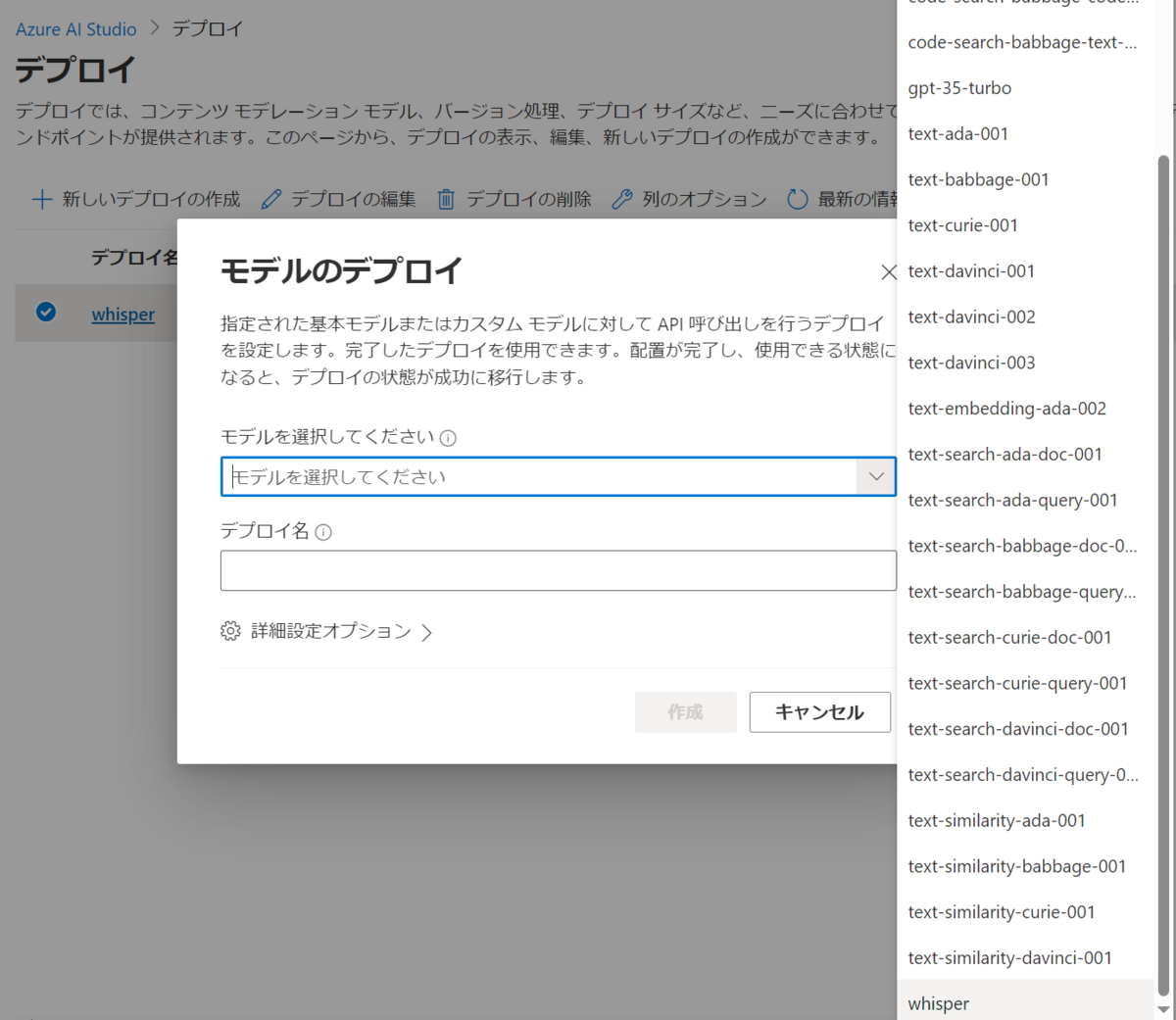
Whisperモデルのデプロイ
Azure OpenAI ServiceからWhisperモデルを使用します。
10月11日時点では、米国中北部と西ヨーロッパリージョンにデプロイされたAzure OpenAI ServiceからWhisperモデルをデプロイできます。
PythonからWhisperモデルを使用する
以下のソースコードを実行してローカル環境上の音声ファイルを文字起こしします。
Azure OpenAI ServiceのEndpointURLとアクセスキー、Whisperモデルのデプロイ名をそれぞれ入力します。
import json import requests oai_endpoint = "<Endpoint URL>" oai_api_key = "<アクセスキー>" oai_deployment = "<Whisperモデルのデプロイ名>" url = f"{oai_endpoint}/openai/deployments/{oai_deployment}/audio/transcriptions?api-version=2023-09-01-preview" headers = { 'api-key' : oai_api_key } with open(music_filepath, 'rb') as f: file_data = f.read() files = {'file': (music_filepath, file_data)} response = requests.post(url, headers=headers, files=files) print(response.json())
動作検証
検証として、以下の音声ファイルデータセットを使用します。
1.2GB程度のファイルの中からcommon_voice_ja_20704576.mp3を使用してリクエストを送信した際、どのようなレスポンスが返ってくるのかを確かめました。音声ファイルの内容はデータセットによると次の通りです。
われわれ、技術者は、最高の技術、最善の手を追求して、明け暮れしてきた。
音声ファイルを送信した結果、以下のようなレスポンスが得られました。完璧に音声を文字列に変換することができました。
{'text': '我々技術者は最高の技術、最善の手を追求して明け暮れしてきた'}
Azure Machine Learning
Azure Machine LearningワークスペースのModel Catalog機能からエンドポイントをデプロイして、Whisperモデルを使用することができます。
Whisperエンドポイントのデプロイ
Azure Machine Learningワークスペースに接続して、左の機能一覧からモデルカタログを選択します。
検索ボックスに「Whisper」と入力します。
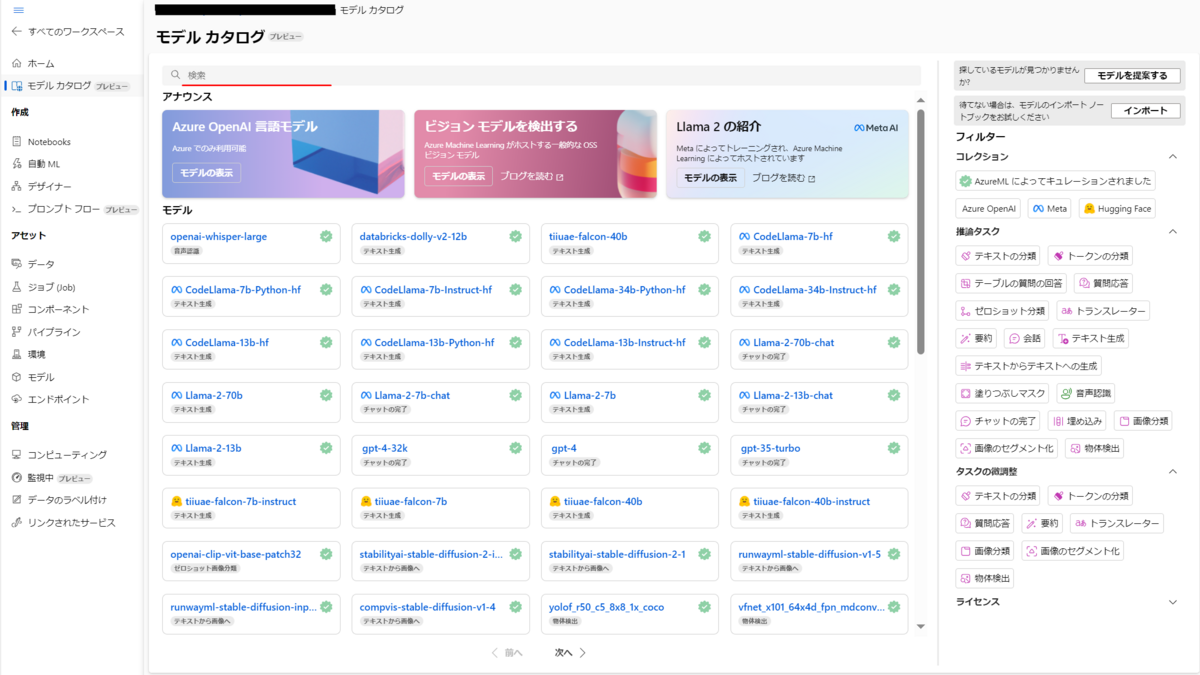
「openai-whisper-large」を選択します。
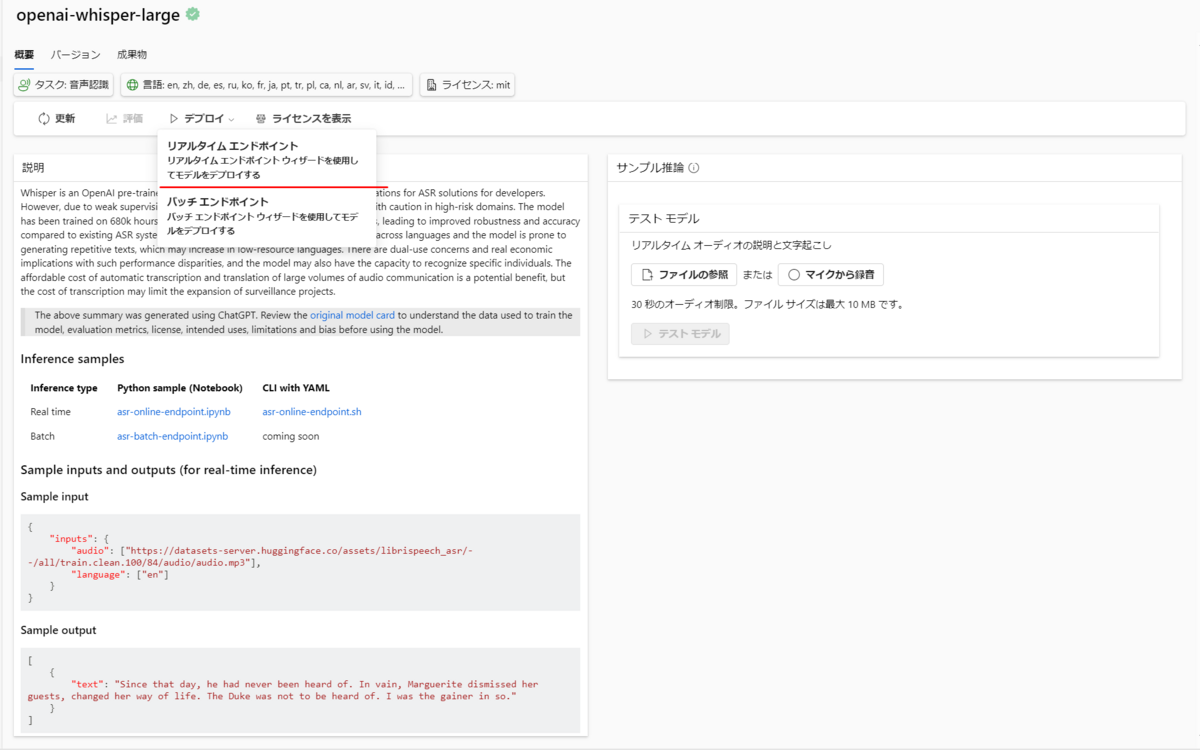
「デプロイ」を選択して、「リアルタイムエンドポイント」を選択します。
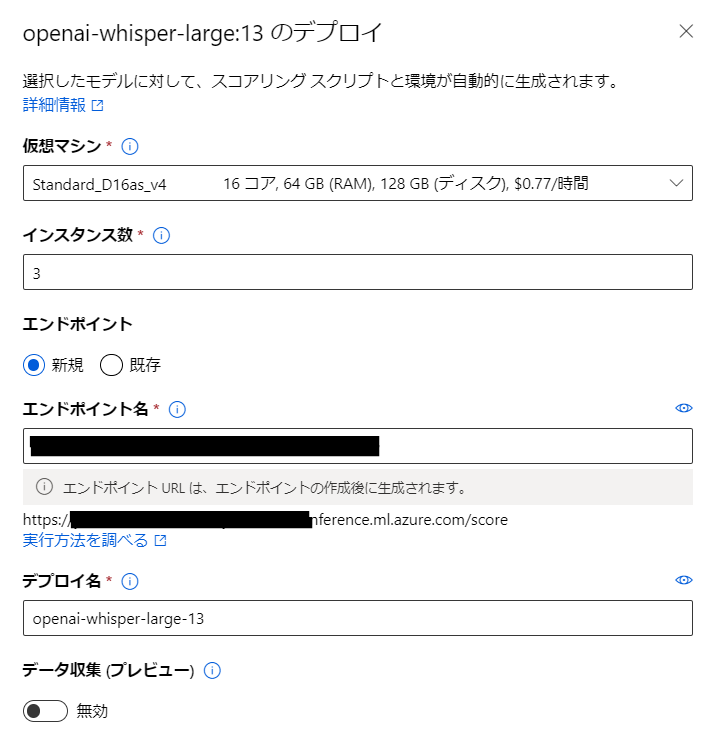
Azure Machine Learning上のエンドポイントとしてWhisperAPIをデプロイする設定を行います。時間当たりの課金が発生するため、作業の際は注意してください。
| 項目名 | 設定値 | 備考 |
|---|---|---|
| 仮想マシン | Standard_D16as_v4 | エンドポイントが存在する間は表示された価格の課金が1時間当たり発生します。このモデルが選択できない場合、他の最安のマシンを選択します |
| インスタンス数 | (初期値) | |
| エンドポイント | 「新規」にチェックする | |
| エンドポイント名 | 初期値もしくは任意の名称 | URLの一部に使用されるほか、AzureMLの「エンドポイント」機能で管理する名称になります |
| デプロイ名 | (初期値) |
エンドポイントのデプロイ作業が開始します。デプロイ完了まで、おおよそ10分程度の時間を必要とします。
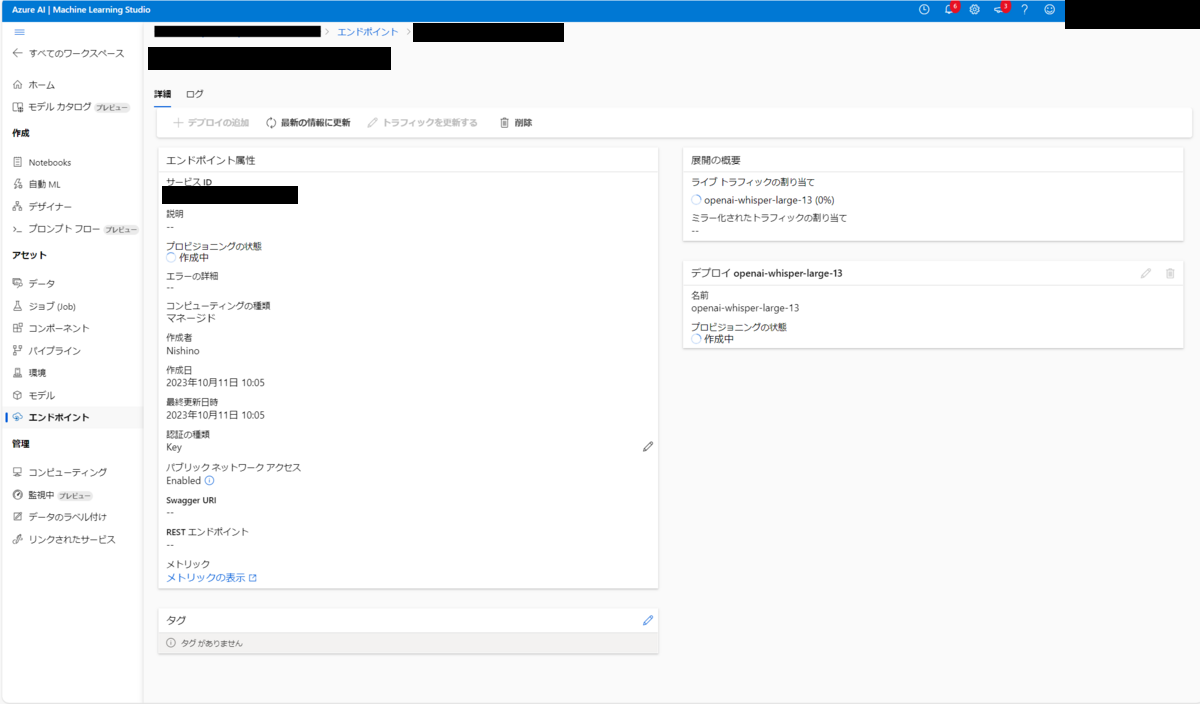
プロビジョニングの状態が「成功」になればOKです。
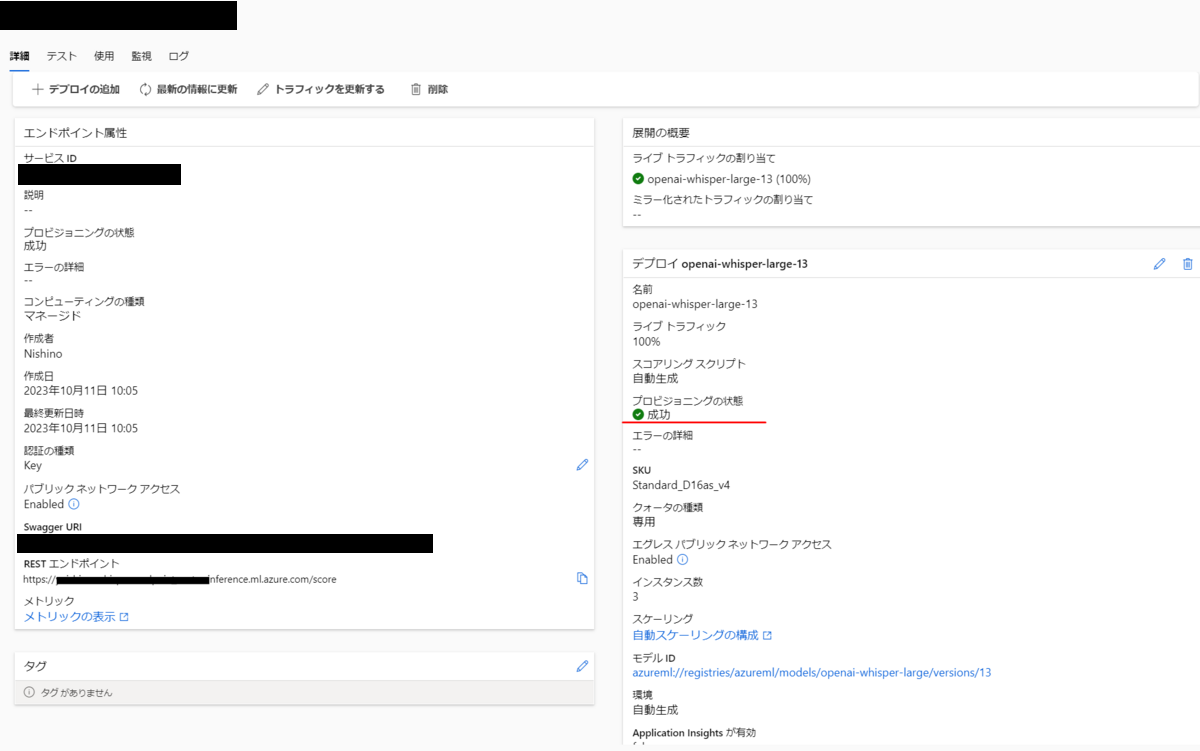
作業完了後には上の選択肢の中から削除を選択します。削除後はコンピューティングリソースが停止かつ解放されるため、課金が発生しない状態になります。
(補足)過去バージョンのWhisperモデルを使用する
デプロイする前の段階で「バージョン」タブを選択して、過去のwhisperモデルを選択することもできます。
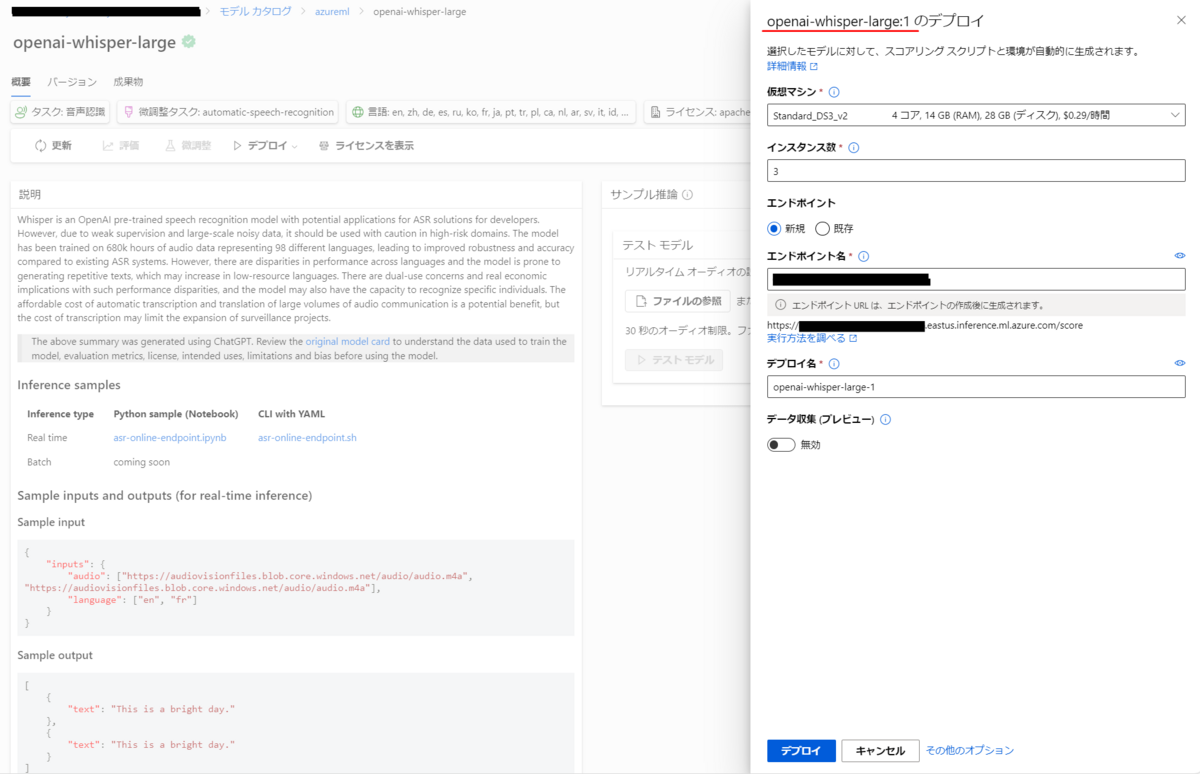
デプロイ時に「openai-whisper-large:(選択したバージョン名)」と表示されることを確認して、デプロイを実行します。
(補足)デプロイするAPIの設定を細かく定義する
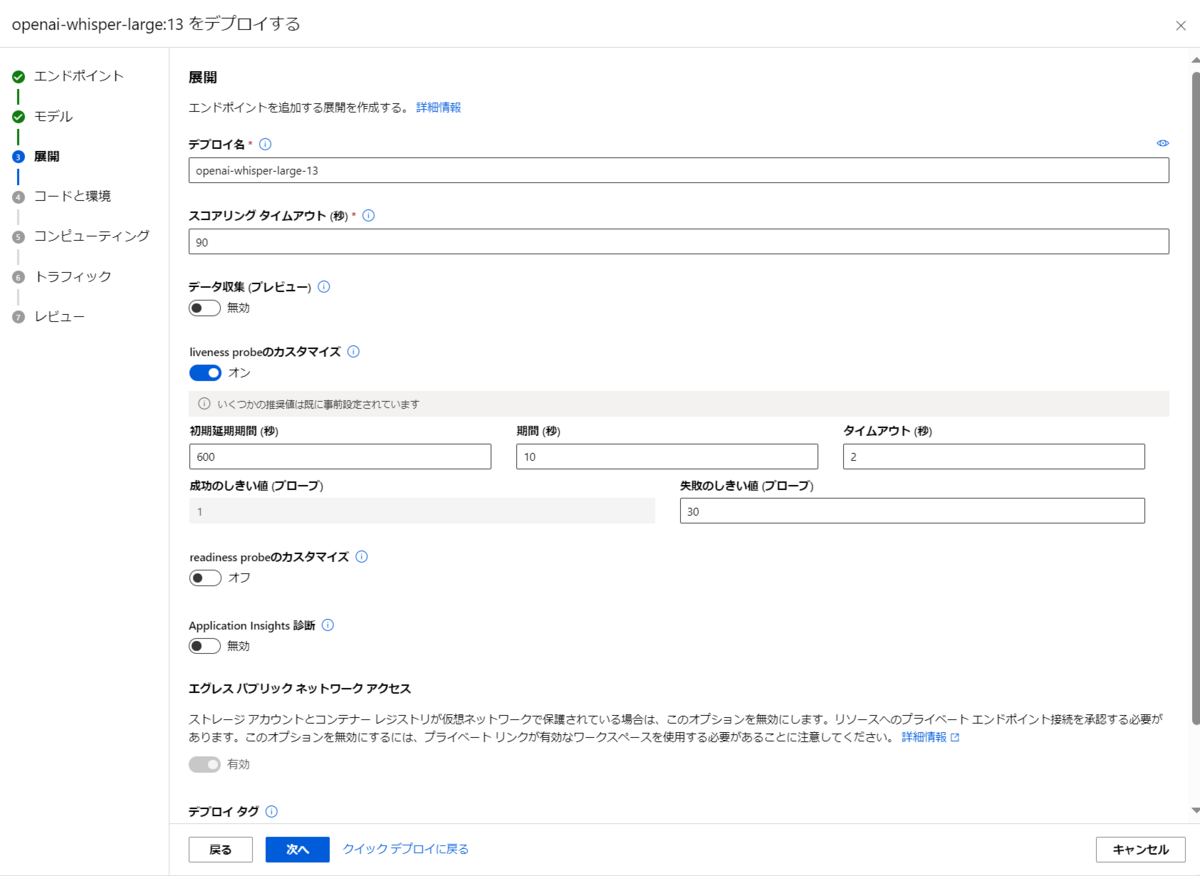
リアルタイムエンドポイントのデプロイ時、画面下の「その他のオプション」を選択します。
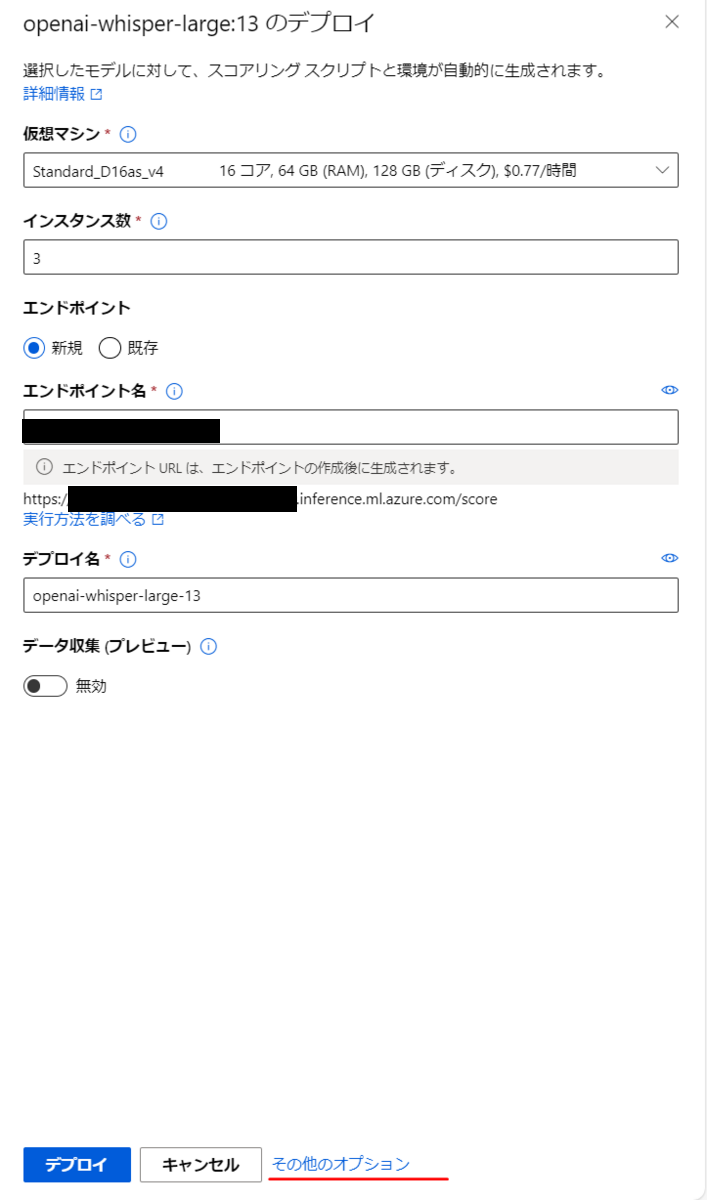
この画面でエンドポイントの設定を細かく変更することができます。スクリプトなどを書けば、Azure Machine Learningのコンピューティングリソースを使いつつ、独自の動きをするAPIをデプロイすることも可能になります。
PythonからWhisperエンドポイントを使用する
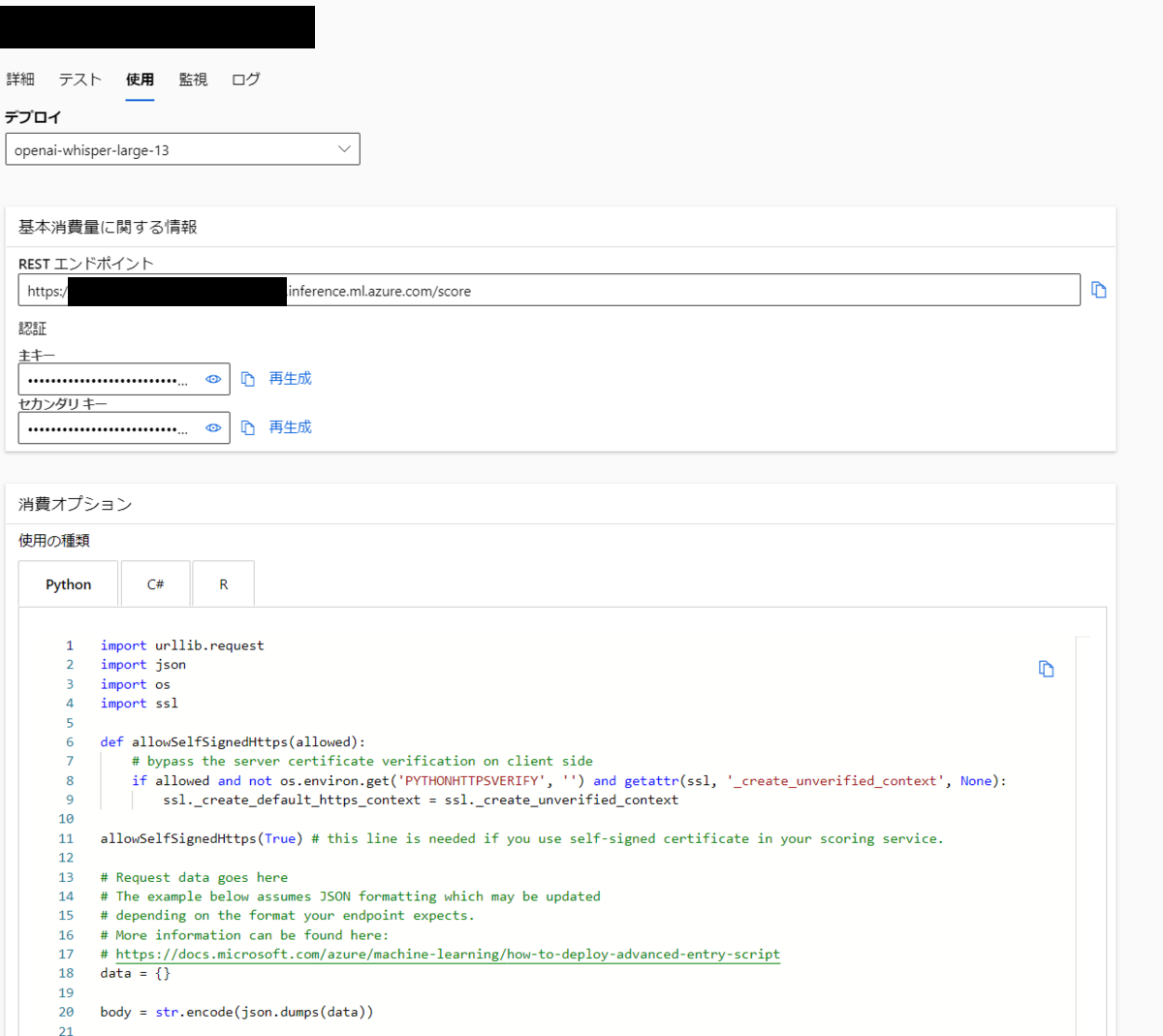
エンドポイントのURLとキーの確認
デプロイしたエンドポイントはキー認証が使用されます。
エンドポイントの詳細画面から「使用」タブを選択して画面を切り替えると、このエンドポイントを使用するためのコードが表示されます。ここで「REST エンドポイント」と「主キー」の2つをコピーして手元に控えておきます。
base64への変換
ローカル環境に音声ファイルを用意します。
音声ファイルを直接エンドポイントに送信することはできないため、base64形式に変換して文字列として送信します。
import base64 music_filepath = "<ローカルの音声ファイルパス>" with open(music_filepath, "rb") as audio_file: encoded_audio = base64.b64encode(audio_file.read()).decode('utf-8')
リクエストの送信
以下のコードで、Azure Machine Learningにデプロイしたエンドポイントにbase64に変換した音声ファイルを送信して推論を実行します。
以下headerの中に「openai-whisper-large-13」と記載している箇所がありますが、デプロイしたモデルのバージョンによって数値を変更してください。
import requests import json url = "<RESTエンドポイント>" api_key = "<主キー>" data = { "inputs": { "audio": [encoded_audio], "language": ["ja"] } } headers = { 'Content-Type': 'application/json', 'Authorization': 'Bearer ' + api_key, 'azureml-model-deployment': 'openai-whisper-large-13' } response = requests.post(url, data=json.dumps(data), headers=headers) result_str = response.text data = response.json() print(data)
動作検証
上記と同じデータセットのうちcommon_voice_ja_20704576.mp3を使用してリクエストを送信しました。
われわれ、技術者は、最高の技術、最善の手を追求して、明け暮れしてきた。
レスポンスは以下の通りです。
[{'text': ' We, the technicians, have been pursuing the best of the best in the field of the best technology.'}]
headerで"language": ["ja"] としたのですが、英文に変換されてしまいました。一方で内容自体はほぼ意図したものが出力されました。
米国東部と東日本リージョンのAzure Machine Learningで検証を行いましたが、出力される結果は同じ英文でした。
まとめ
今回はAzure基盤上でWhisperモデルを使用するユースケースと、実際にデプロイして使用するまでの具体的な方法について解説しました。また簡単に検証を行い、精度の高い文字起こし処理ができることが分かりました。
今後もAI分野ではアップデートが続くため、引き続き情報を追っていきたいと思います。
