
Meta社が次世代オープンソース大規模言語モデルLlama 2を発表しました。また先日のInspireではこのモデルがAzure Machine Learningで使えることも発表されました。
本ブログではAzure Machine LearningでLlama 2を使うまでの手順を記載します。
Llama 2とは
研究および商用向けに無償で使える大規模言語モデルのオープンソースで、以下の3つのモデルがあります。
| モデルサイズ(パラメータ数) | 事前学習 | チャット利用へのファインチューニング |
|---|---|---|
| 7B(70億) | モデルアーキテクチャ プレトレーニングトークン数:2兆 コンテキスト長::4096 |
有用性と安全性のためのデータ収集 教師ありファインチューニング:10万以上 人の好みに合わせた調整:10万以上 |
| 13B(130億) | ||
| 70B(700億) |
Llama 2 - Resource Overview - Meta AI
Llama2のデプロイ
利用できるコンピューティングインスタンスの確認とクォータ制限の引き上げ要求
初期状態のサブスクリプションではLlama2を利用できるコンピューティングインスタンス(Standard NCSv3 Family Cluster)は0なのでクォータ制限の引き上げ要求が必要です。
※Standard NCSv3 Family Clusterが24コア以上使えればLlama 2のデプロイに進んでください。
コンピューティングインスタンスの確認
コンピューティングから新規を選択します。
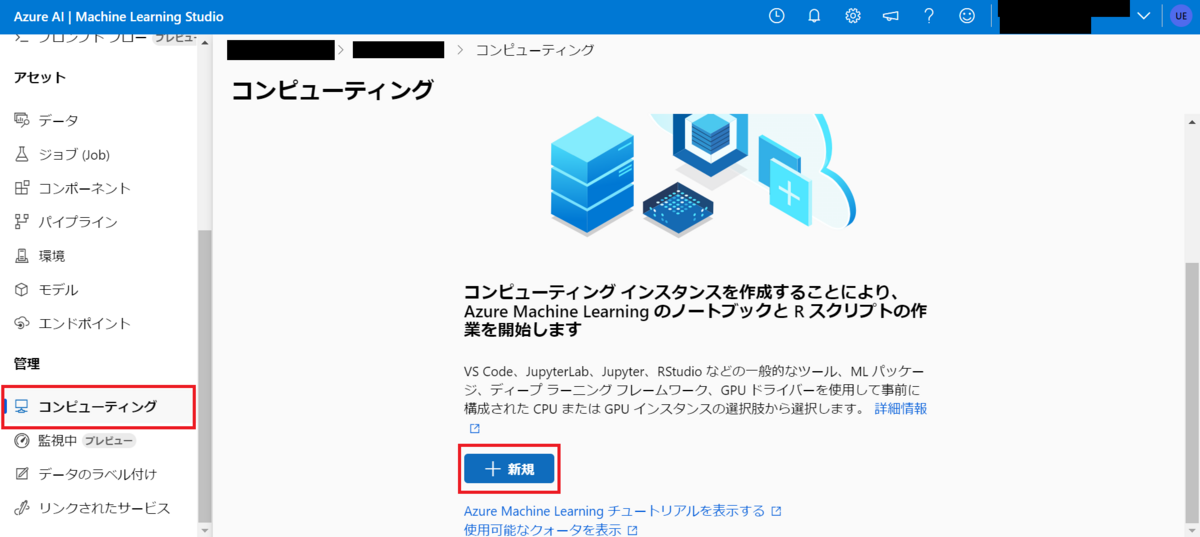
GPUを選びすべてのオプションから選択を選びます。
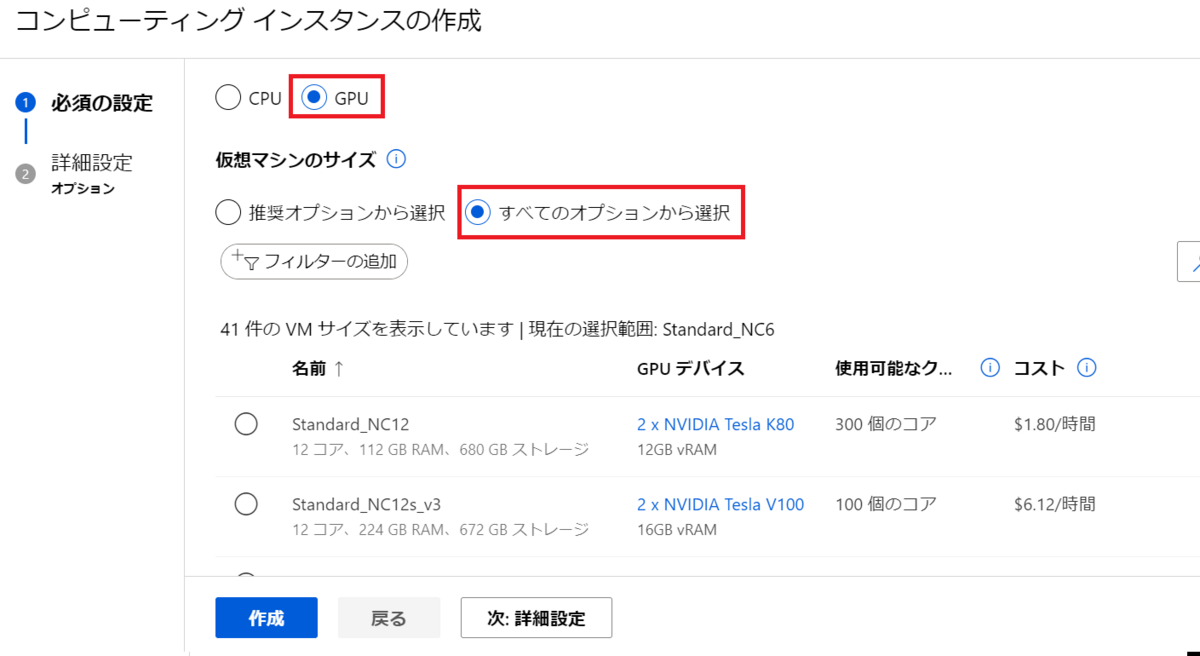
Standard NCSv3 Family Clusterが0コアであれば引き上げ要求が必要です。
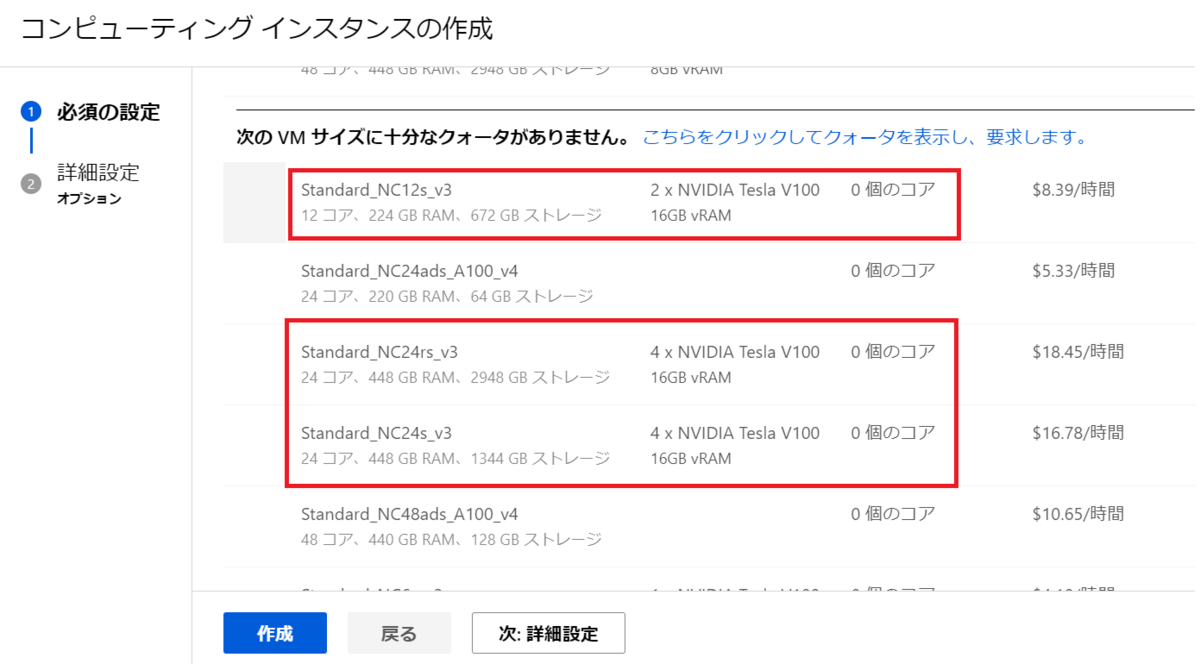
クォータ引き上げ要求
Azure Portalに移動して「使用量+クォータ」を選択します。
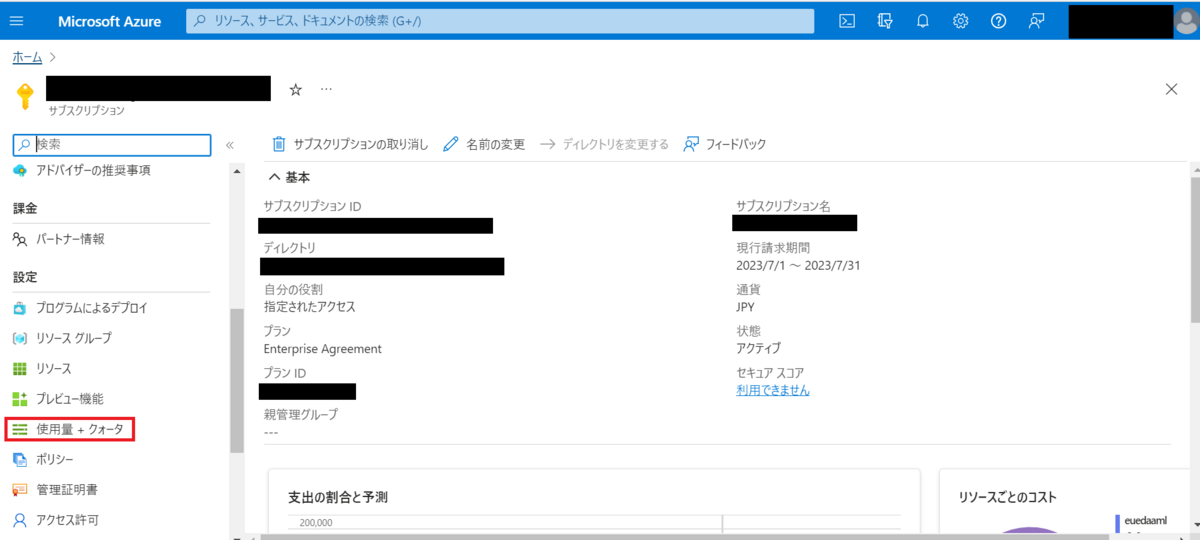
Machine learnigを選択した上でAzure Machine Learning デプロイされているリージョンを選択してNCSv3で検索します。
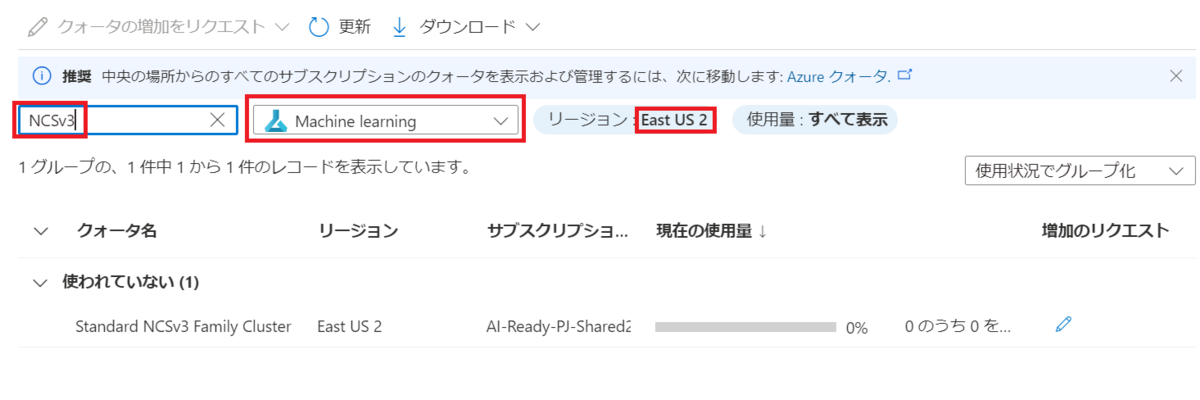
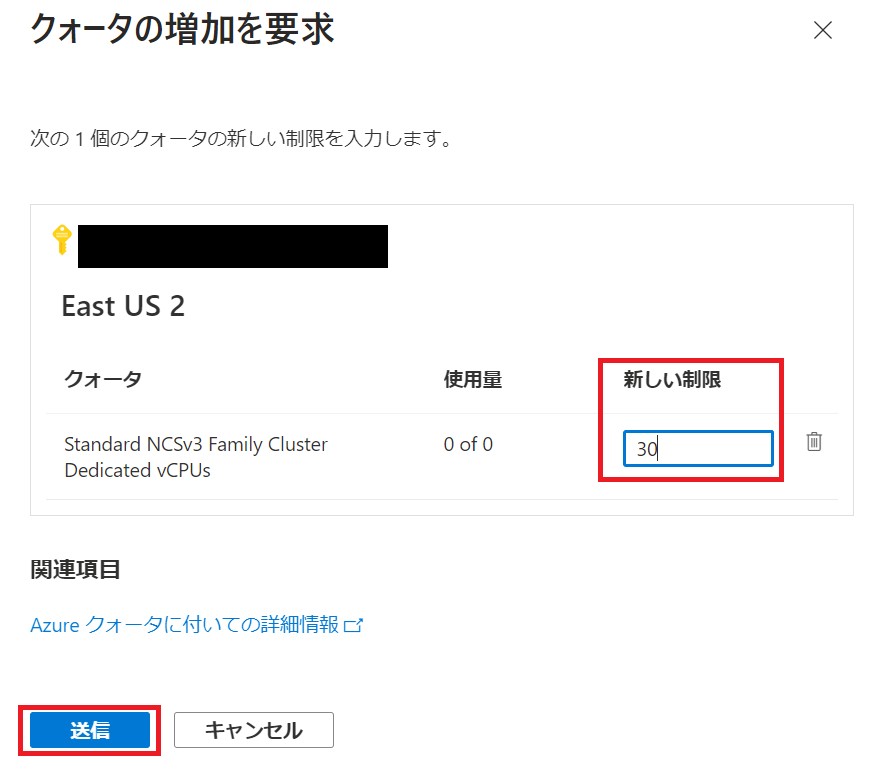
増加のリクエストを選択します。

追加のリクエストを送信します。
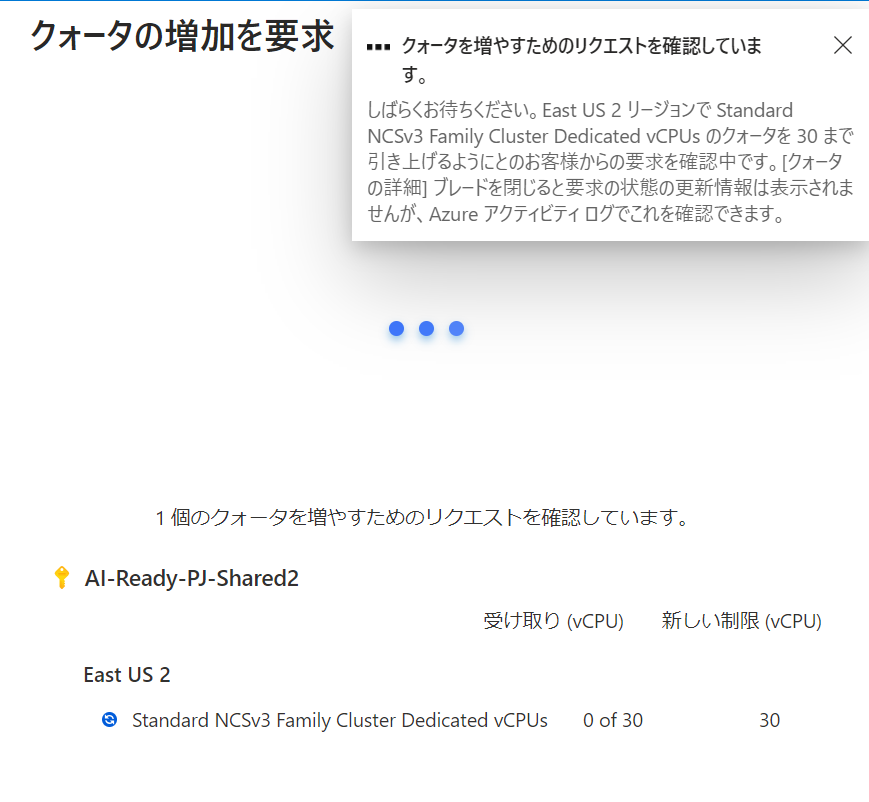
クォータのリクエスト確認画面になります。
ここは失敗しますのでサポートリクエストの作成をします。
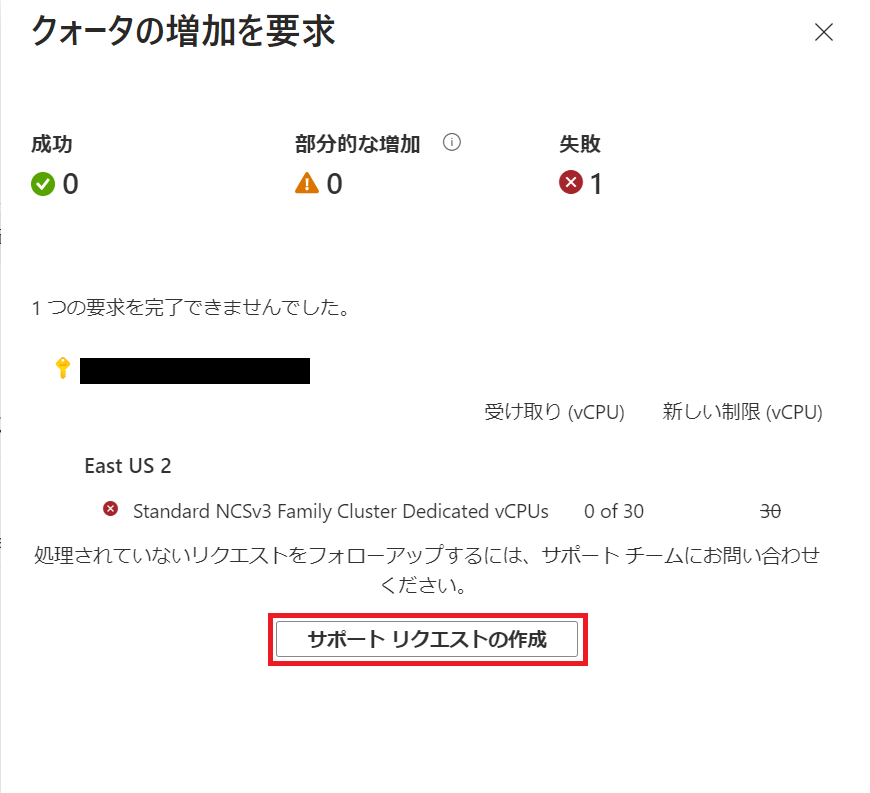
新しいサポートリクエストの作成
サポートリクエストの画面で次へを選択します。。
詳細を選択します。
詳細を入力します。
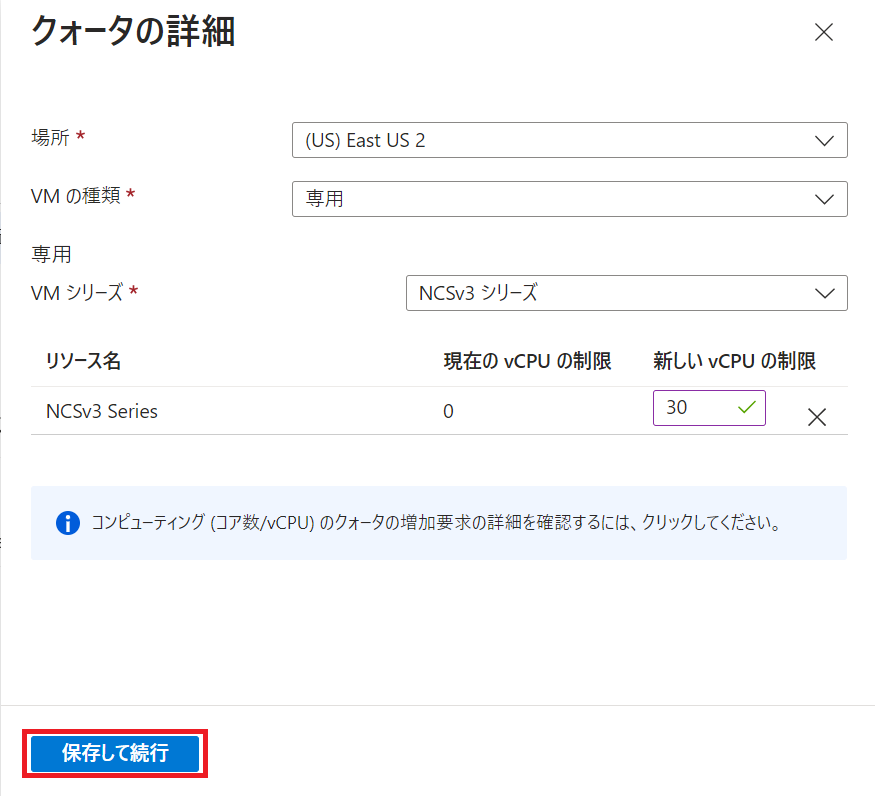
必要事項を記入し、サポートリクエストを送信します。
私の環境で今回リクエストをあげたところ1営業日で引き上がりました。
Llama 2のデプロイ
Azure Machine LearningのモデルカタログからLlama 2のモデル表示を選択します。
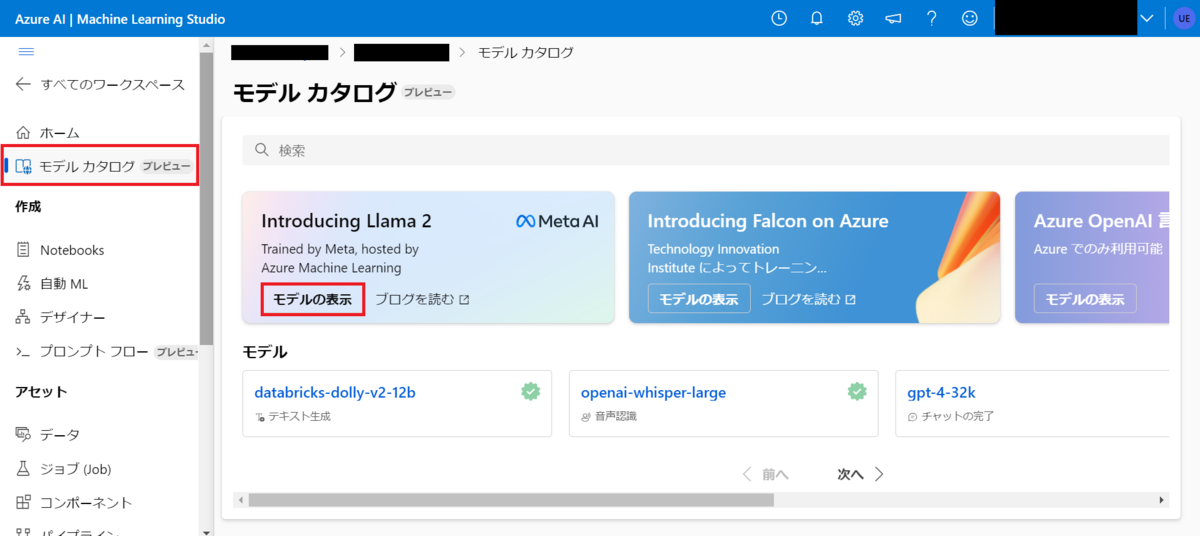
70B(Llama-2-70b-chat)は動かすインスタンスのコストが高すぎたので13B(Llama-2-13b-chat)を選択します。
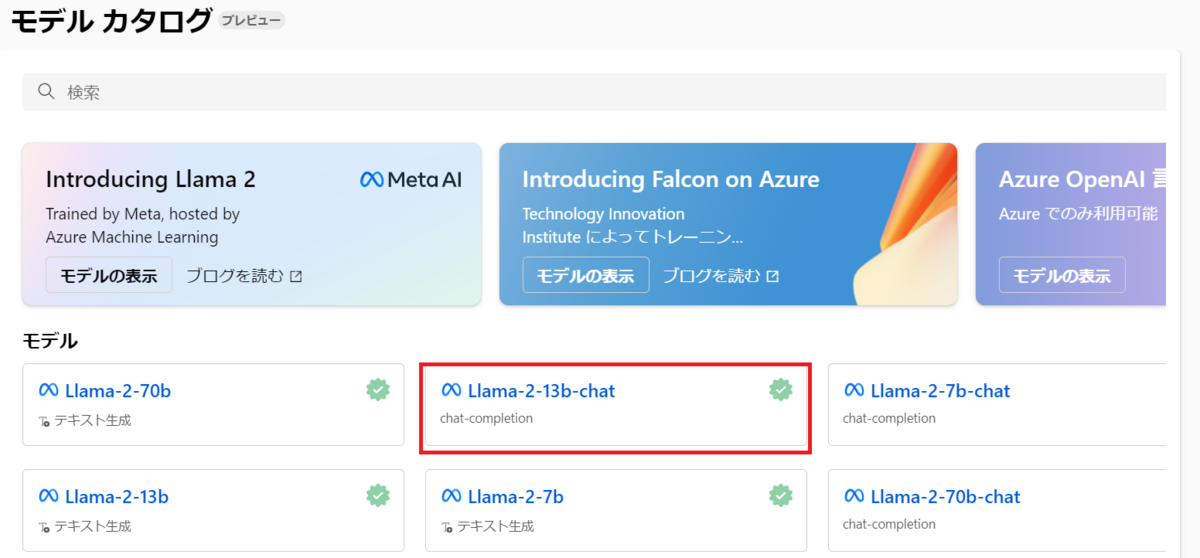
デプロイ→リアルタイムエンドポイントを選択します。
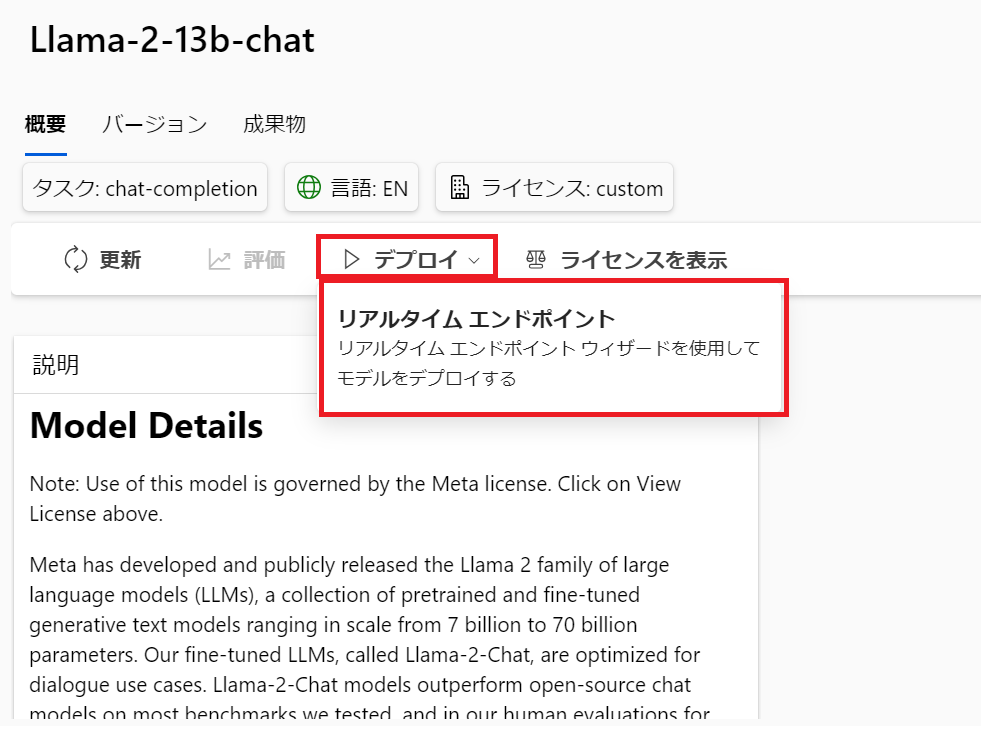
Azure AI Content Saftyを使うかどうかの選択なので、今回は使わない下を選びます。
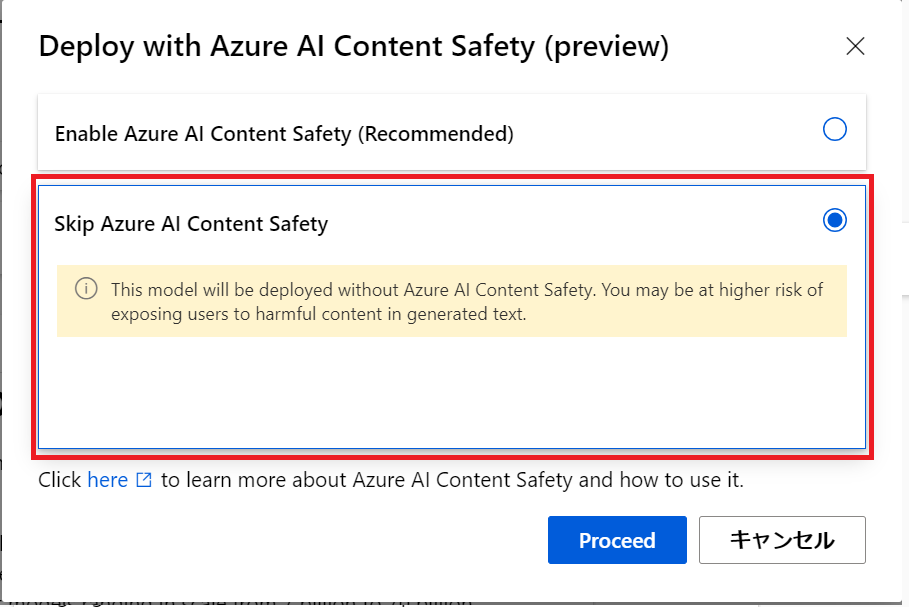
確認だけなのでインスタンス数を1にしてデプロイします。
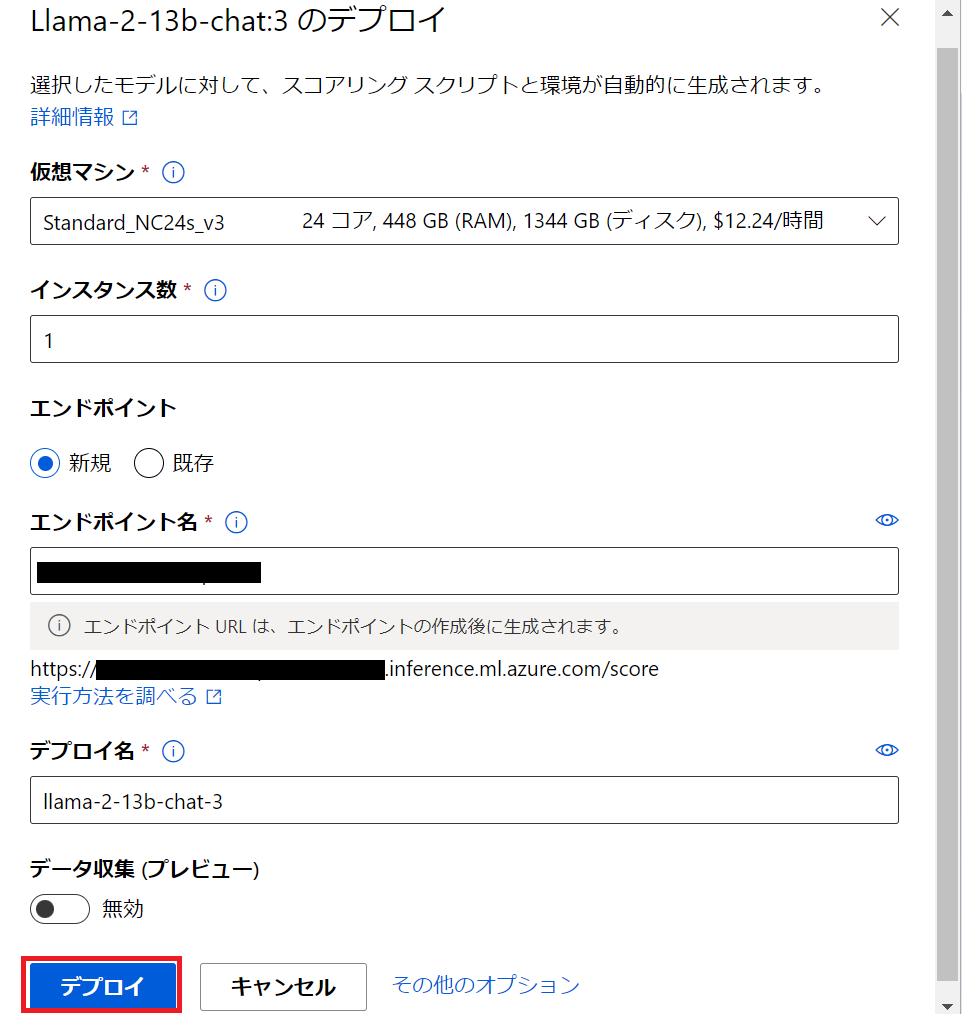
デプロイの確認
デプロイが終わるとプロビジョニングの状態が成功になります。
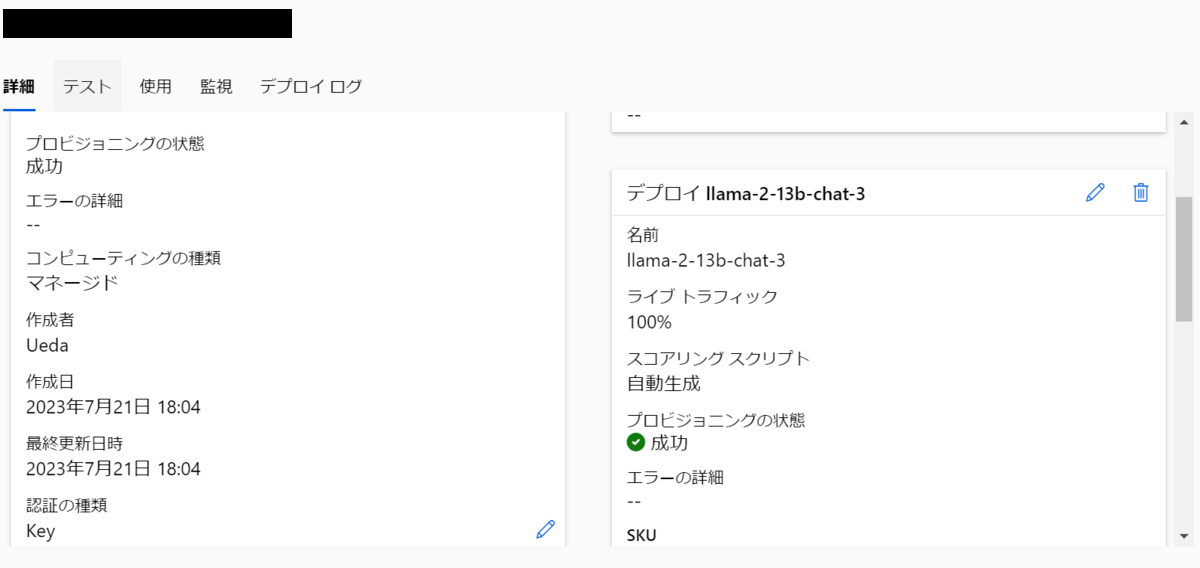
またデプロイすると機械学習オンラインエンドポイントと機械学習オンラインデプロイが自動的に作成されます。
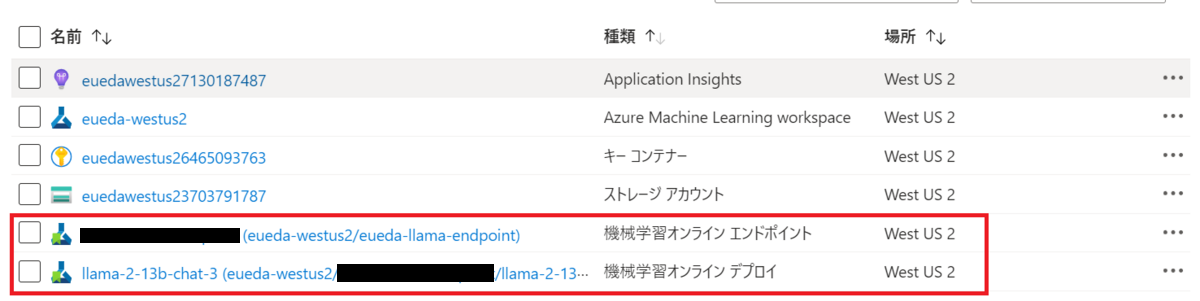
Llama2を使ってみる
Azure Machine Learningからテストする
エンドポイントから自身がデプロイしたエンドポイントを選択します。
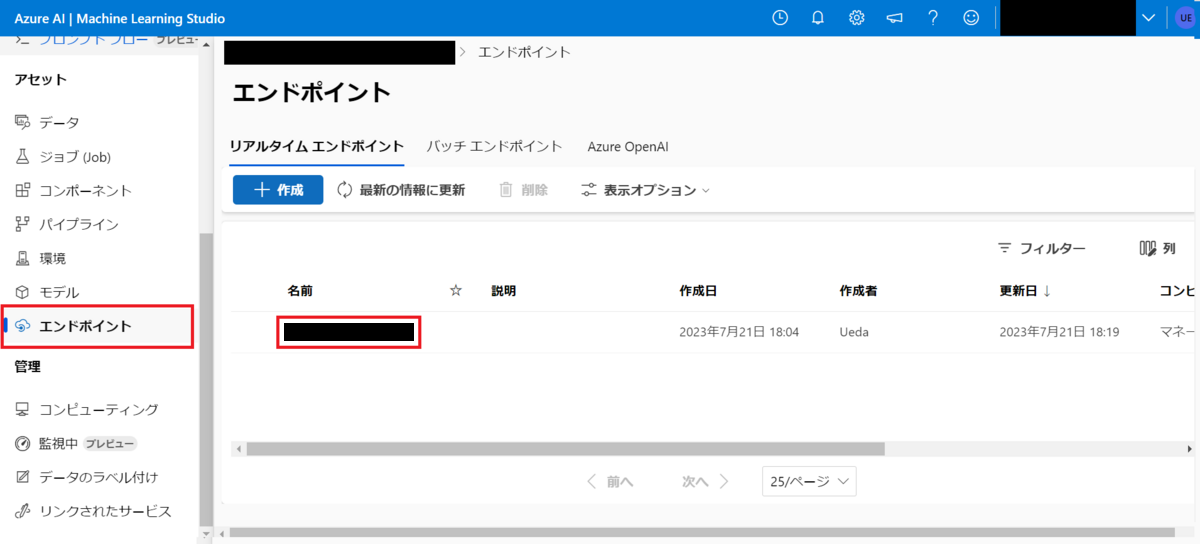
テストのタブを選択します。
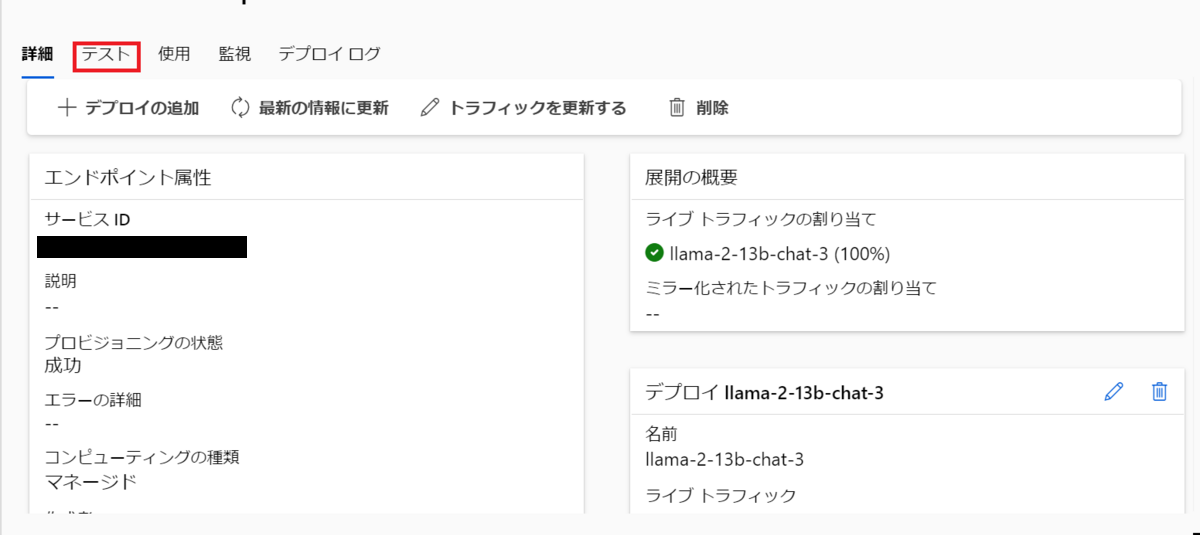
モデルカタログの概要にサンプルインプットがあるのでそれをコピーします。
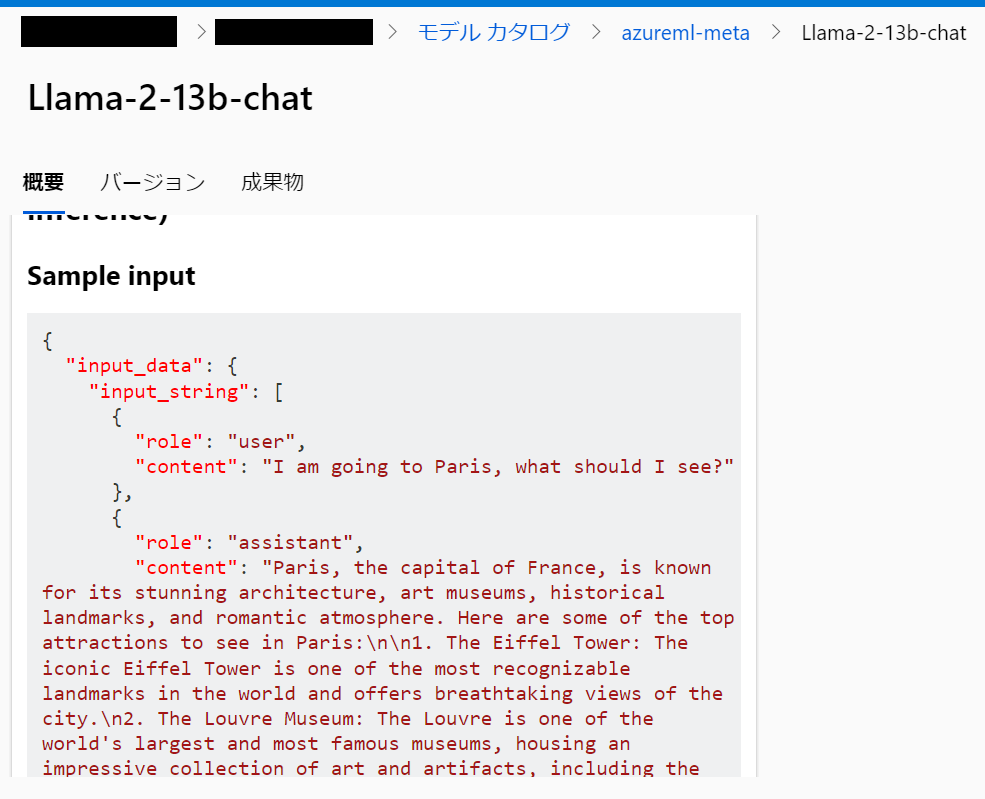
ひとまずそのまま張り付けてみます。内容はパリの観光の話のようです。JSONはOpenAIに似ています。
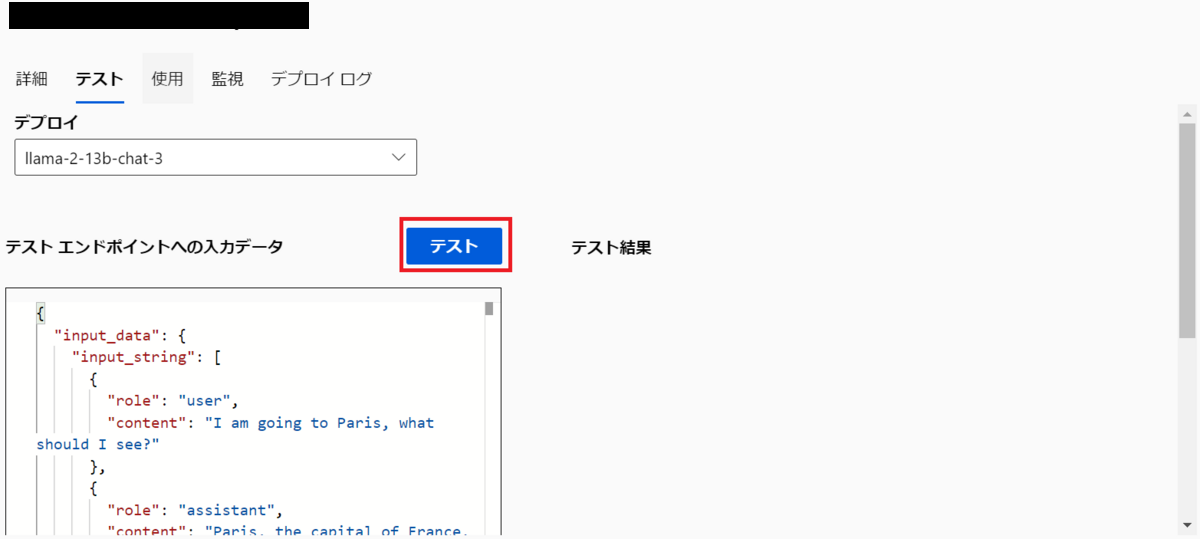
返ってくることが確認できました。
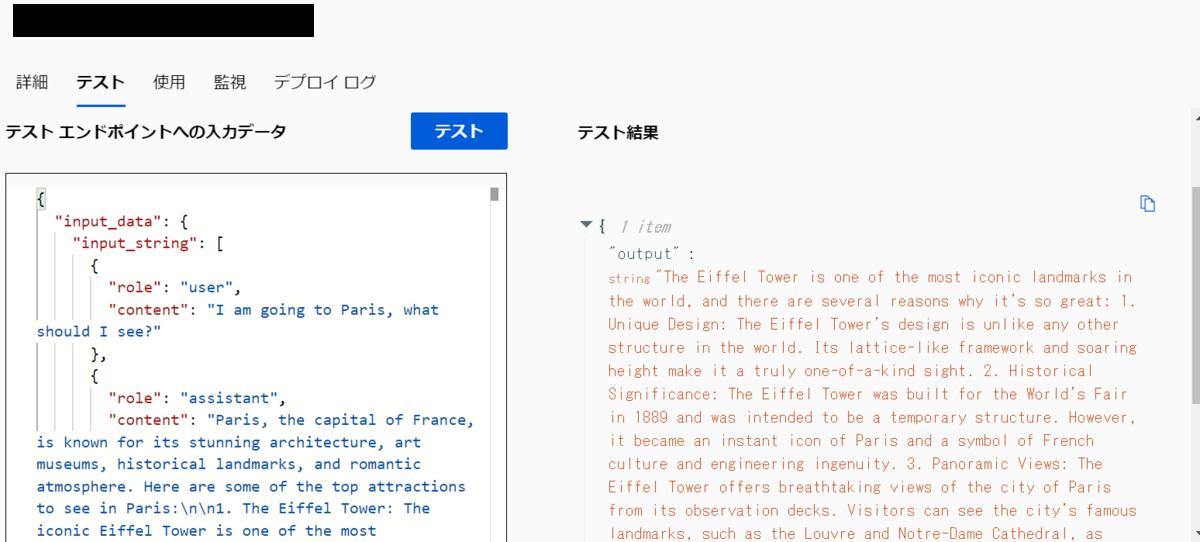
日本語のテスト
日本語でwindows10のサポート期限を聞いてみました。日本語で答えてくれますが途中で切れてしまいました。
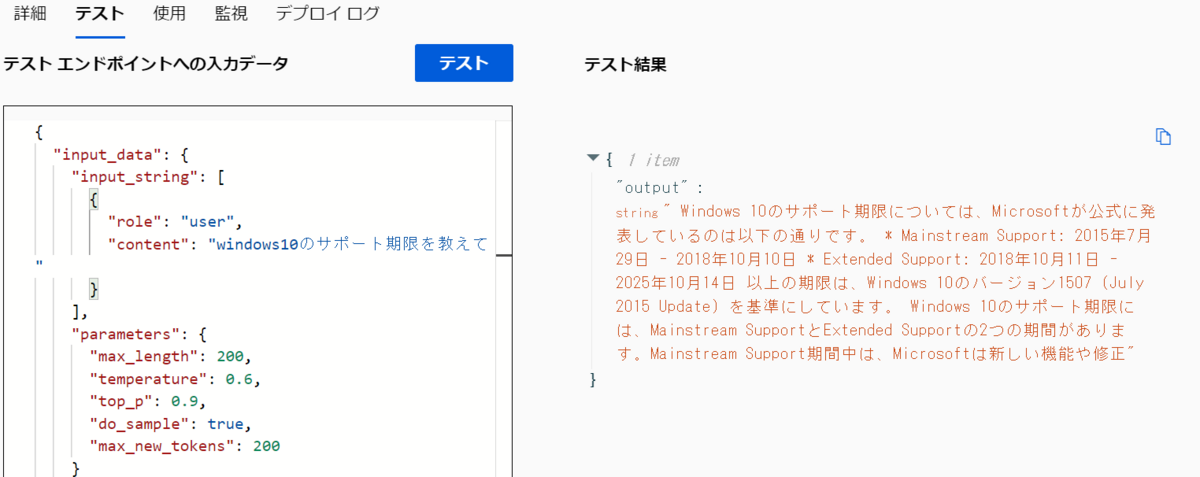
max_new_tokensを変更して再度実行すると最後まで答えてくれました。

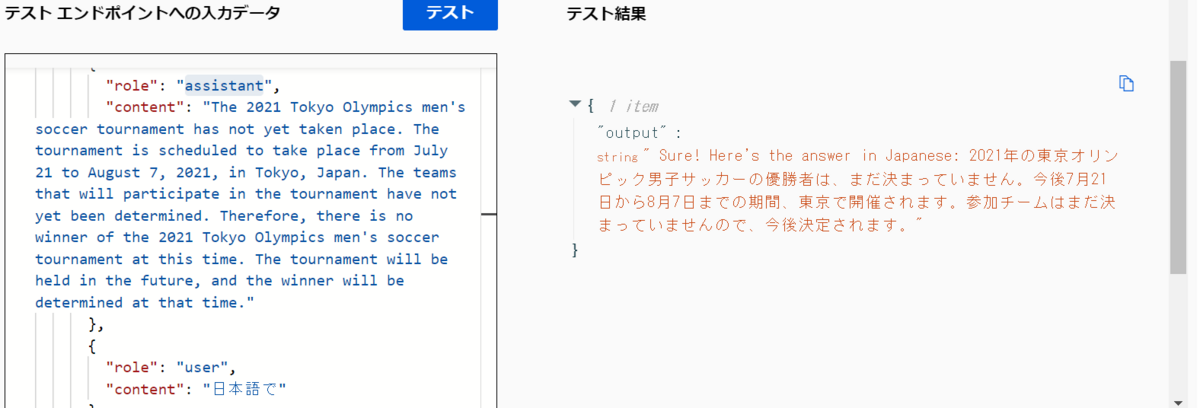
いつまでのデータに答えられるか気になったので2021年の東京オリンピックのことを聞いてみますが、回答が英語な上にまだ開催されていないと返ってきています。

いろいろやってみましたが、英語で返ってくることが多いです。ChatCompletionのようにuserとassistantロールを入れて日本語でと入れれば会話ができます。
概要のData Freshnessにはプレトレーニングのデータは2022年9月まで、また2023年7月までの最新のデータでtuningをしていると記載がありますが、実際に質問をすると2020年くらいまでは答えられて2021年は怪しいという状態でした。
日本語での回答に関してですが、日本語は学習データの0.1%しか含まれていないそうなので、そのあたりも日本語での回答に影響していると考えます。
またインターネットでSystemRollをつけているsampleを見たのですが、SystemRollをつけるとエラーになってしまいました。
Pythonのノートブックからの確認
使用のタブにPythonのサンプルコードがあるのでコピーします。
ノートブックに貼り付けます。
使用タブのキーをコピーします。
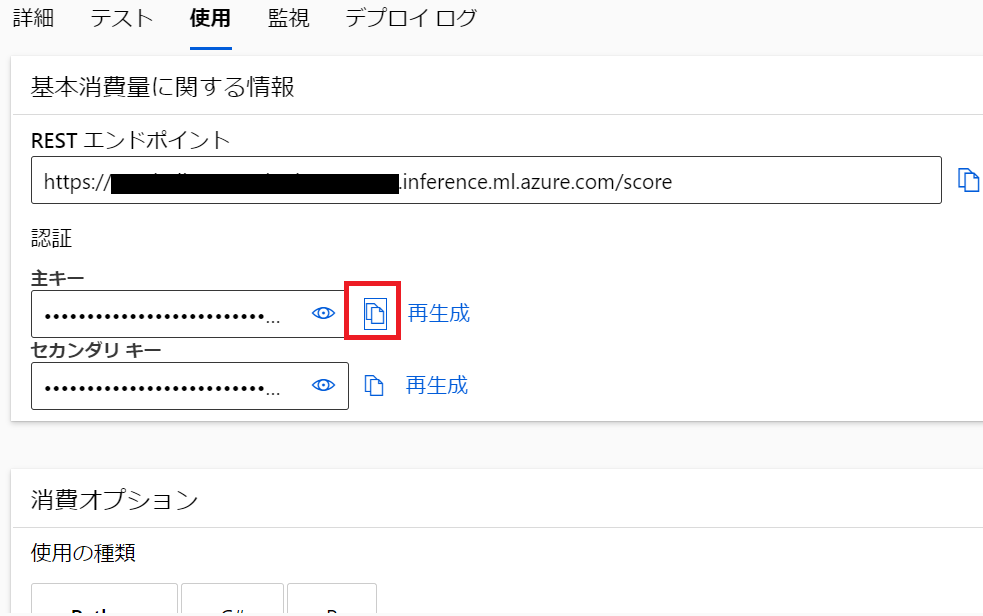
api_keyに貼り付けます。
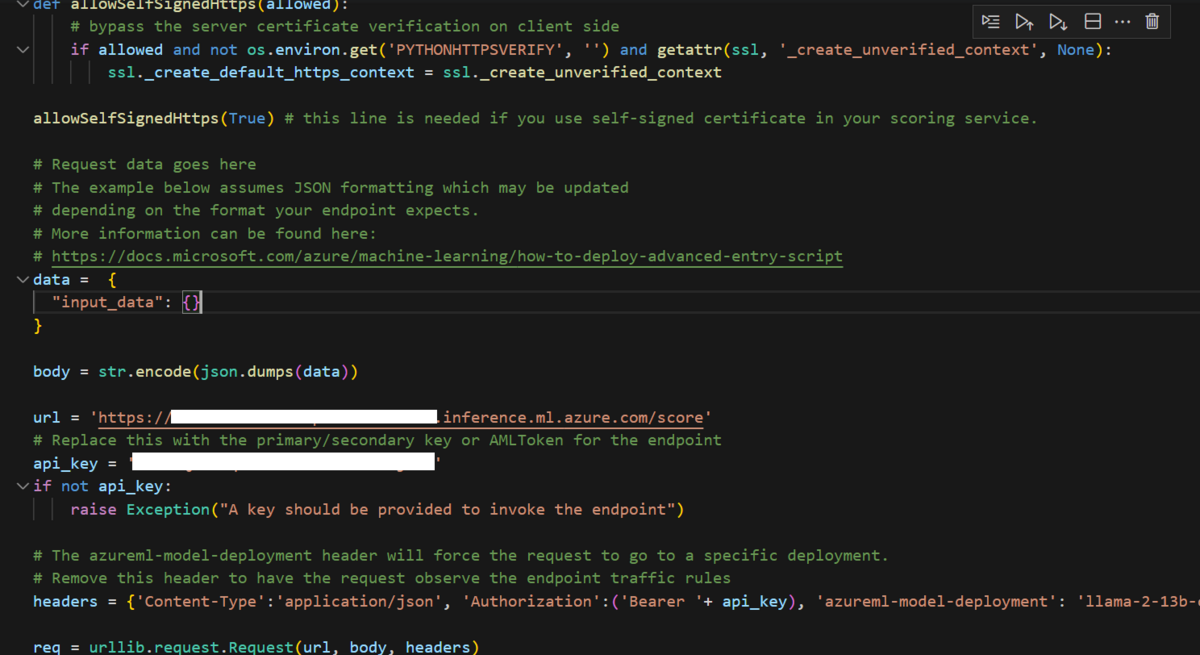
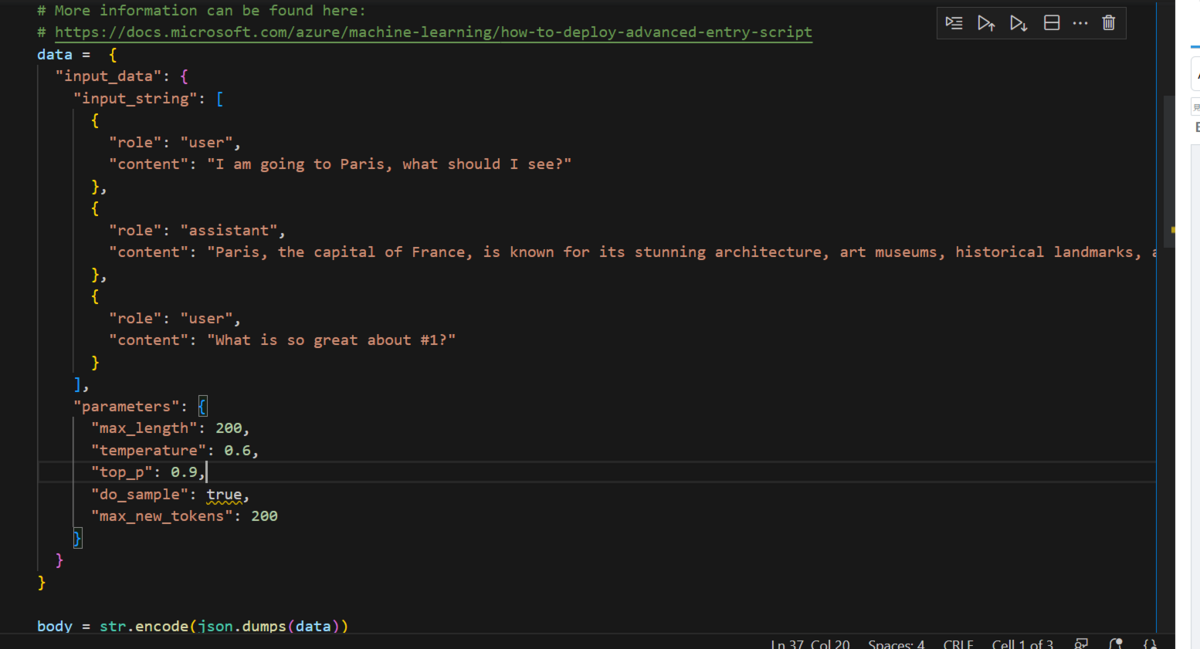
dataに先ほど使ったJSONをコピーします。
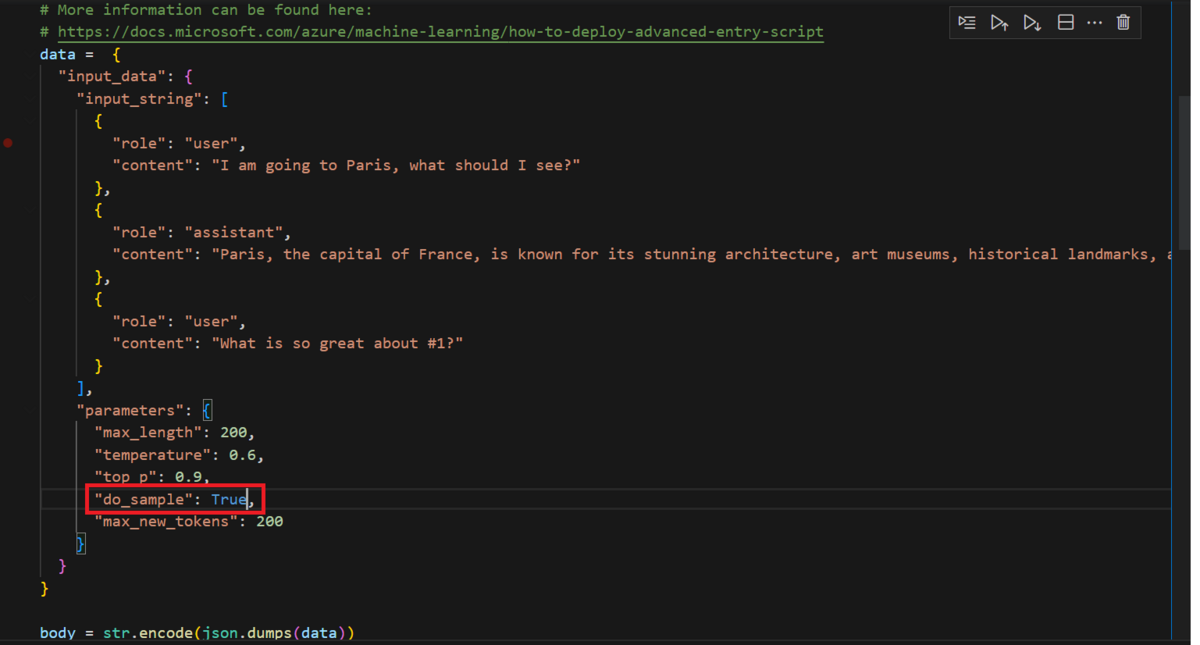
"do_sample": trueがエラーになっているので"True"に直します。
レスポンスを確認できました。

RestAPIで確認する
Pythonのコードを参考にリクエストを投げます。
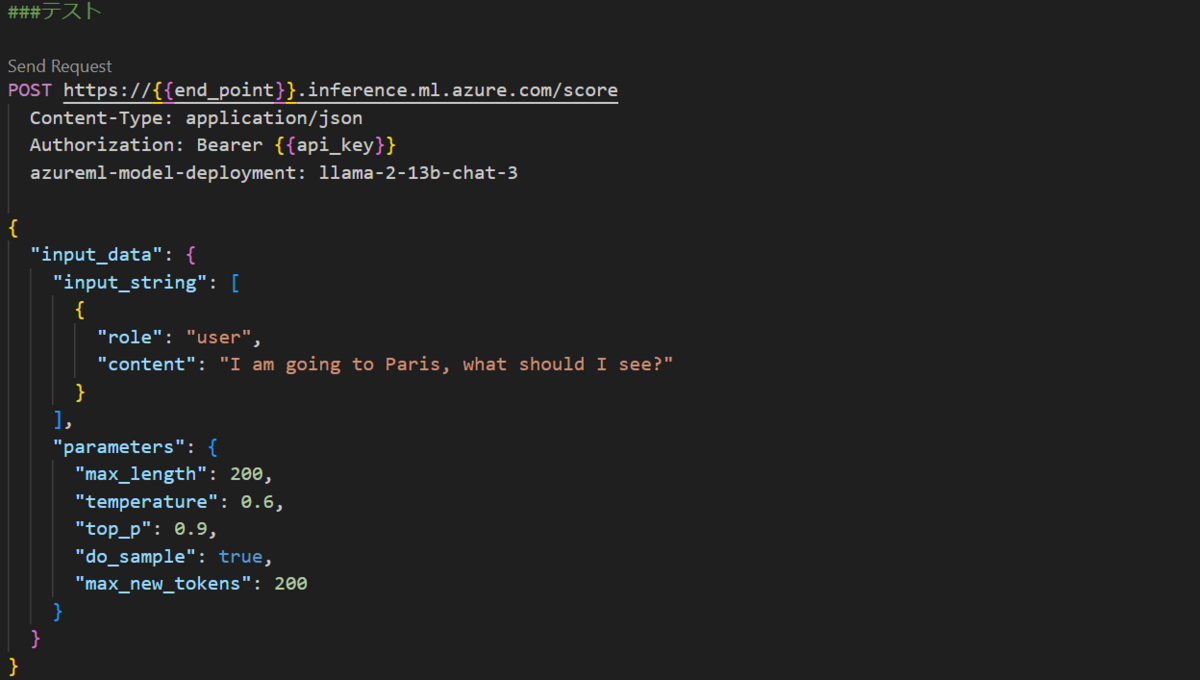
200で正常に返ってくることが確認できました。
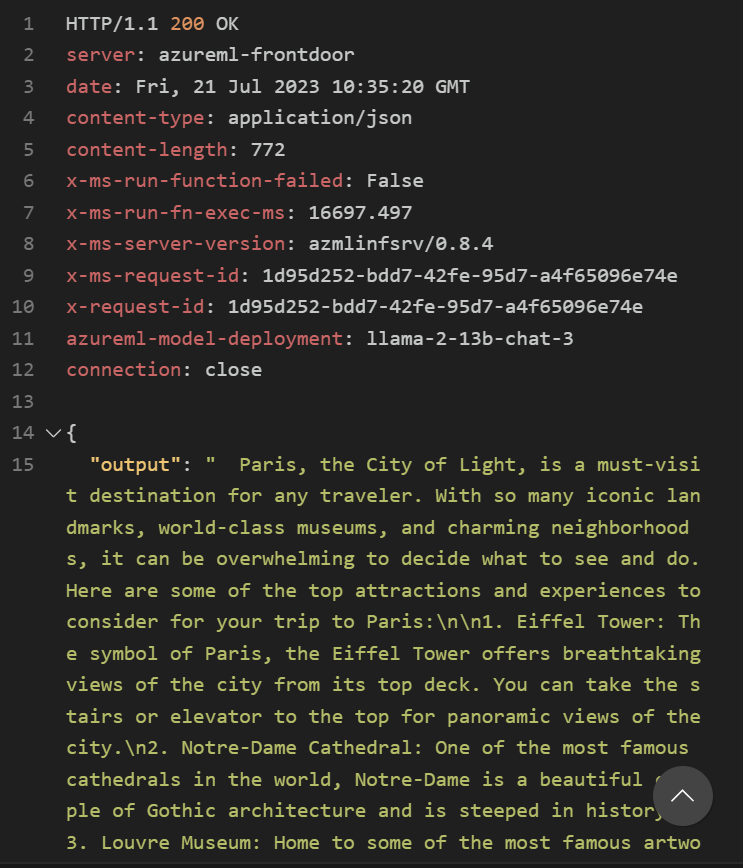
エンドポイントの削除
動かしたままにしておくと$12.24/hがかかるので、作成したエンドポイントを選択して削除します。
削除を選択します。
削除されるとエンドポイントが消えます。
また機械学習オンラインエンドポイントと機械学習オンラインデプロイのリソースも削除されます。
まとめ
メリット
- AzureOpenAIに比べて監査がないので、利用データを完全に内部でコントロールすることができる
- 自身でエンドポイントが作れるのでコンピュートリソースが確保できる
デメリット
- 利用料金が高い($12.24/h)
- レスポンスが遅い(早いと20秒だが、平均すると40秒から1分程度)
- 日本語が少し怪しい
まとめると上記になりますが、使用感としては英語であればChatGPTモデルと同等に近いと感じました。その性能のモデルがオープンソースかつ商用利用可なのはかなりすごいことかと感じています。

上田 英治(日本ビジネスシステムズ株式会社)
エンジニアとしてインフラ構築、システム開発やIoT基盤構築等を経験し、現在はクラウドアーキテクトとして先端技術の活用提案や新規サービスの立ち上げを担当。
担当記事一覧