
はじめに
2021年11月パブリックプレビューとなった「Azure Chaos Studio」2022年12月現在、まだGAされていませんが、今回は聞きなじみのない「カオスエンジニアリング」について3回に分けて、概要や必要な背景や進め方をご紹介したのち、Azure Chaos Studio を使って実際にカオスエンジニアリングを進めてみます。
カオスエンジニアリングとは
カオスエンジニアリングとは、正常に稼働している本番環境において疑似的に障害を発生させることでアプリケーションやサービスの回復性や耐障害性を確認・検証する手法です。
仮想マシンのシャットダウンや通信制限、強制フェイルオーバーを発生させ、アプリケーションがエラーを適切に処理できるかを確認します。
カオスエンジニアリングはなぜ必要なの?
今まで利用されてきた「モノリシック」なサービスでは「いかに障害を起こさず運用できるのか?」ということが良いこととされてきましたが、昨今話題となっているサービス指向アーキテクチャやマイクロサービスで用いられるさまざまな技術では「自動回復可能なアーキテクチャ」として設計されていることが多くなります。
サービスを構成するための技術の変化に伴い、発生する障害の質も変化し、リカバリー範囲の特定なども非常に難しいケースも増えています。
このような障害を早期に発見するため、カオスエンジニアリングを早期から回帰的に実施し、被害を最小限に抑えることを目的とした取り組みです。
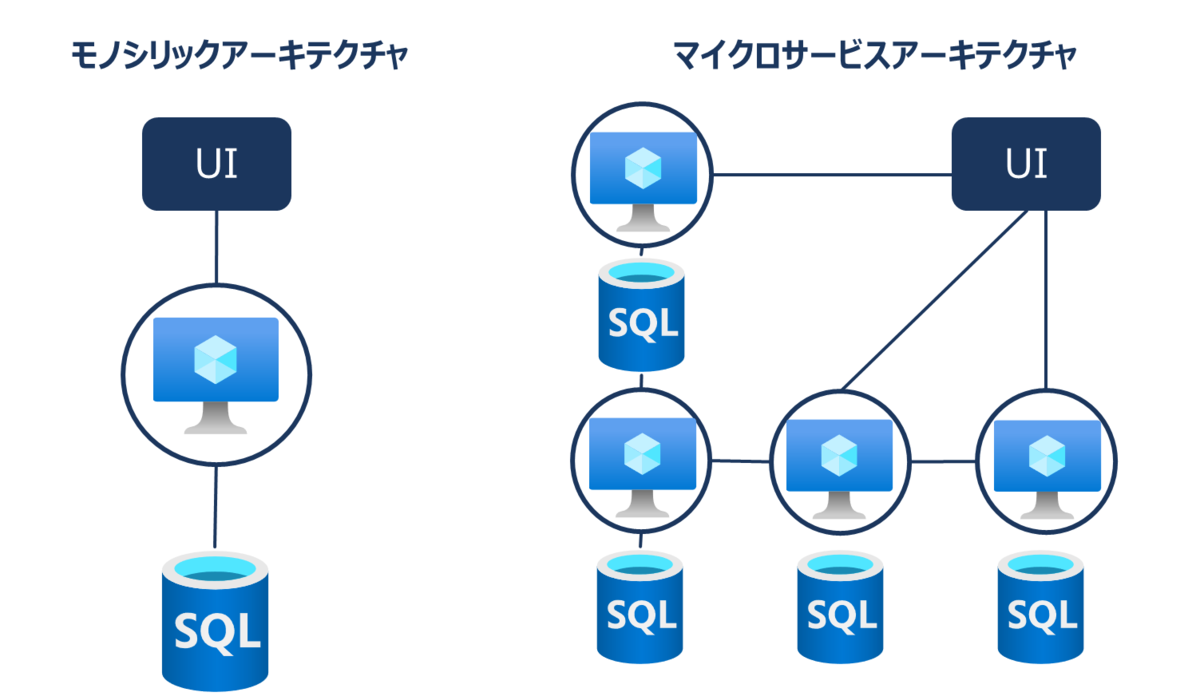
マイクロサービスではモノシリックに比べて拡張性などが良くなる反面、障害点が増加します。
カオスエンジニアリングを実施している有名な企業ではNetflix社があります。カオスエンジニアリングのための専用ツールである「Chaos Monkey」を開発しました。
当初は注目を浴びていなかったのですが、クラウドサービスで大規模な障害が発生した際、アメリカのウェブサイトやWeb Serviceが大きく影響を受ける中、被害の中にNetflix社がはいっていなかったことから、カオスエンジニアリングが注目され始めたとされています。
カオスエンジニアリングの進め方
カオスエンジニアリングは「カオスエンジニアリングの原則」を参考に実施します。
1.定常状態における振る舞いの仮説を立てる
2.実世界の事象は多様である
3.本番環境で検証を実行する
4.継続的に実行する検証の自動化
5.影響範囲を局所化する
(引用: カオスエンジニアリングの原則)
カオスエンジニアリングの原則の詳細は上記リンクをご覧ください。
カオスエンジニアリングの原則は継続的にサイクルを適用するのが理想とされています。
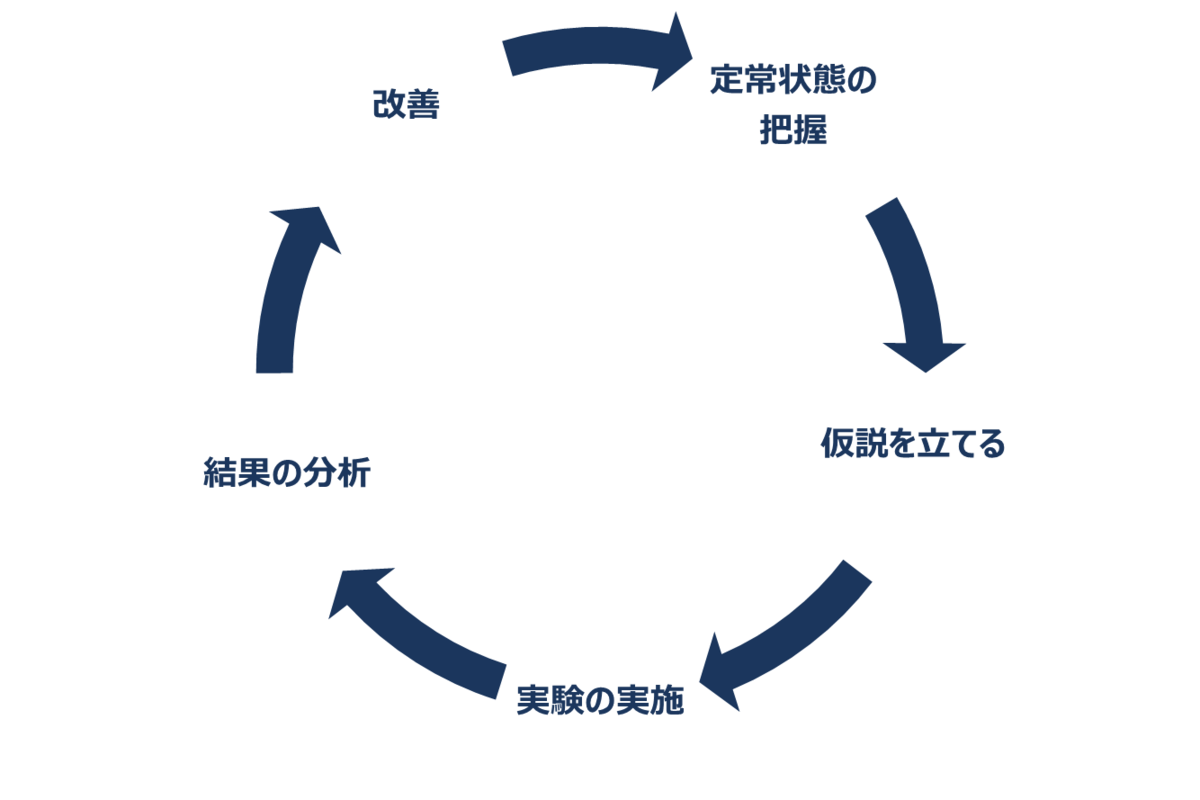
ソフトウェアとハードウェアを実行する環境では常に変更が行われているので監視することが重要です。
まとめ
今回はカオスエンジニアリングの概要について説明しました。
次回はAzure Chaos Studioを使用する為の準備編です。
